
 Périphériques technologiques
IA
La formation des grands modèles fait attention à « l'énergie » ! Tao Dacheng dirige l'équipe : Toutes les solutions de « formation efficace » sont couvertes dans un seul article, arrêtez de dire que le matériel est le seul goulot d'étranglement
Périphériques technologiques
IA
La formation des grands modèles fait attention à « l'énergie » ! Tao Dacheng dirige l'équipe : Toutes les solutions de « formation efficace » sont couvertes dans un seul article, arrêtez de dire que le matériel est le seul goulot d'étranglement
La formation des grands modèles fait attention à « l'énergie » ! Tao Dacheng dirige l'équipe : Toutes les solutions de « formation efficace » sont couvertes dans un seul article, arrêtez de dire que le matériel est le seul goulot d'étranglement

Le domaine de l'apprentissage profond a réalisé des progrès significatifs, notamment dans des aspects tels que la vision par ordinateur, le traitement du langage naturel et la parole. Les modèles à grande échelle formés à l'aide du Big Data sont importants pour des applications pratiques, améliorant la productivité industrielle et. Les perspectives de promotion du développement social sont immenses.
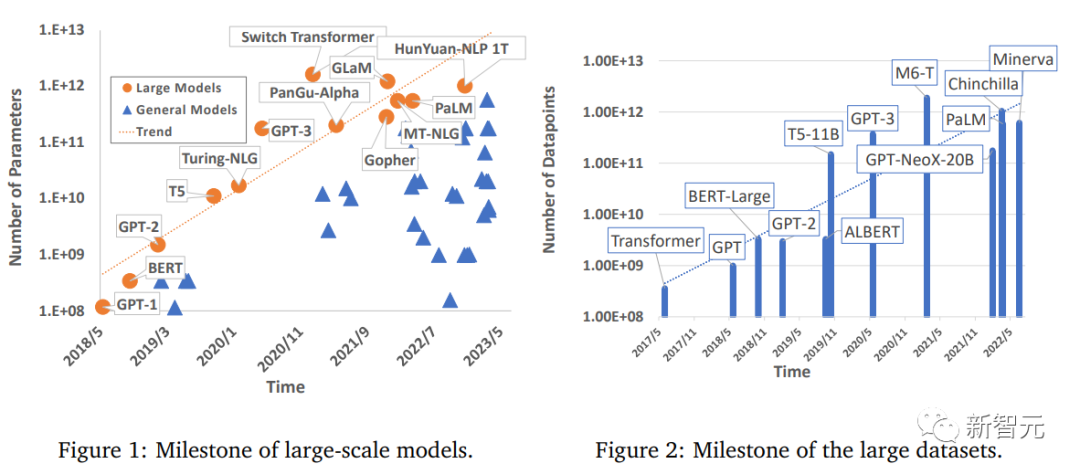
Cependant, les grands modèles nécessitent également beaucoup de puissance de calcul pour s'entraîner, Ainsi, avec l'amélioration continue des besoins des gens en matière de puissance de calcul, bien qu'il y ait eu de nombreuses études explorant des méthodes de formation efficaces, il n'existe toujours pas d'examen complet de la technologie d'accélération des modèles d'apprentissage en profondeur.
Récemment, des chercheurs de l'Université de Sydney, de l'Université des sciences et technologies de Chine et d'autres institutions ont publié une étude résumant de manière exhaustive les techniques de formation efficaces pour l'apprentissage profond à grande échelle. Il montre le mécanisme commun à chaque composante du processus de formation.

Lien papier : https://arxiv.org /pdf/2304.03589.pdf
Les chercheurs ont examiné la formule de mise à jour du poids la plus élémentaire et ont divisé ses composants de base en cinq aspects principaux : # 🎜🎜#
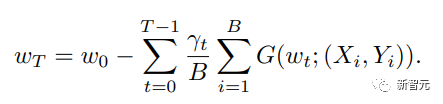
1, data-centric ) , y compris la régularisation des ensembles de données, des techniques d'échantillonnage de données et d'apprentissage de cours centrées sur les données, qui peuvent réduire considérablement la complexité informatique des échantillons de données
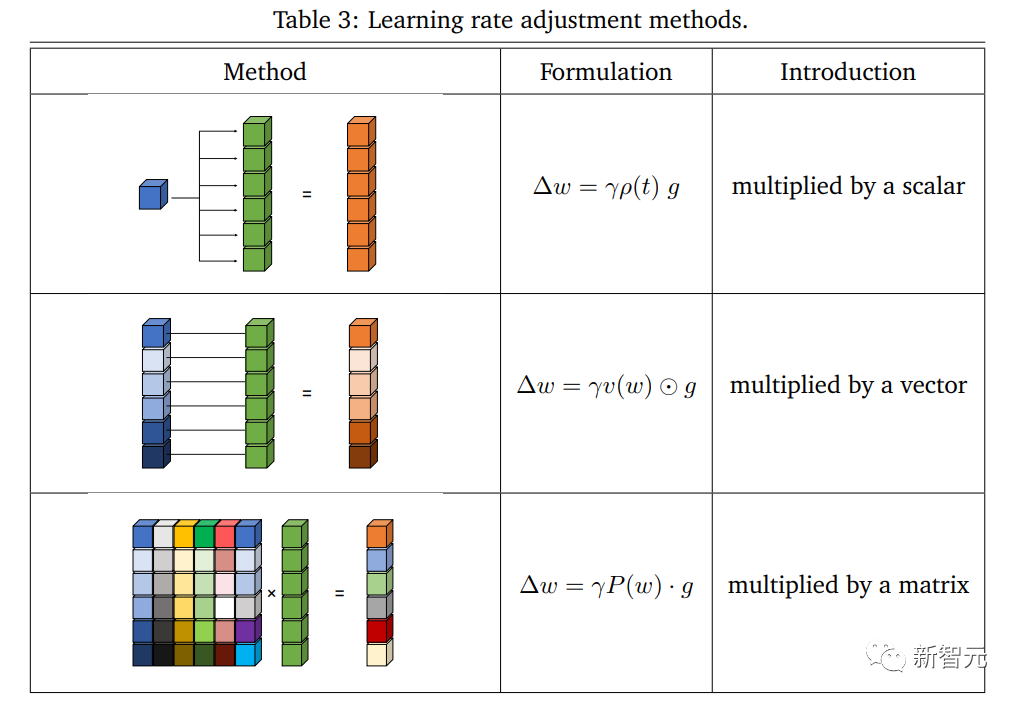
2. Centrée sur le modèle ; , y compris l'accélération des modules de base, la formation à la compression, l'initialisation du modèle et la technologie d'apprentissage de cours centrée sur le modèle, en se concentrant sur l'accélération de la formation en réduisant les calculs de paramètres ; centré sur l'optimisation, y compris le choix du taux d'apprentissage, l'utilisation de lots de grande taille et des objectifs efficaces. Conception des fonctions, technologie moyenne pondérée des modèles, etc. ; se concentrer sur les stratégies de formation pour améliorer la polyvalence des modèles à grande échelle ;
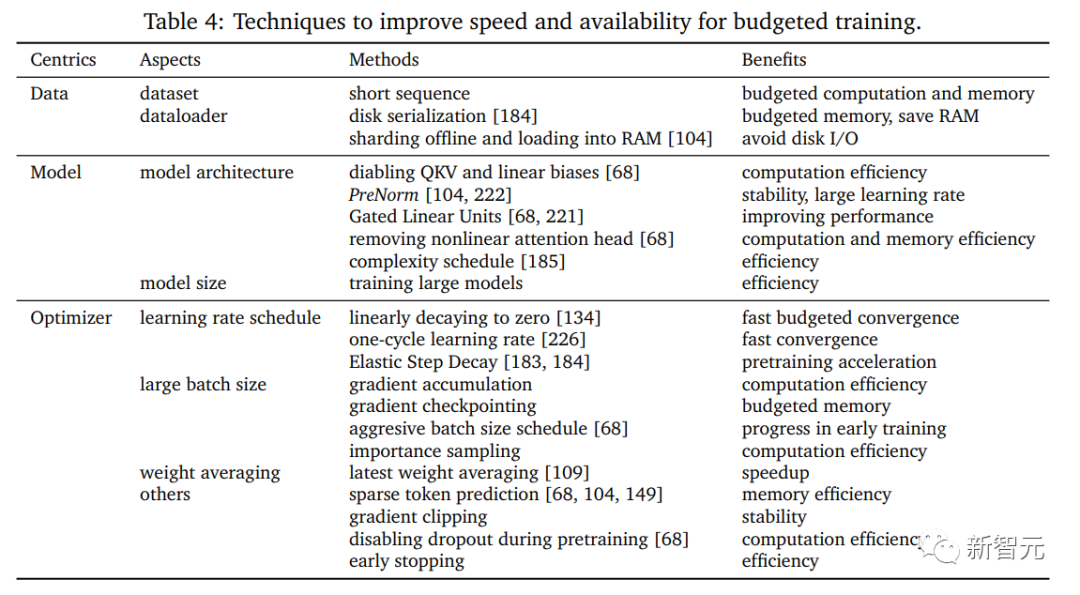
4, formation budgétisée ) , y compris certaines technologies d'accélération utilisées lorsque le matériel est limité
#🎜 ; 🎜#5, centré sur le système), comprenant des frameworks distribués efficaces et des bibliothèques open source, fournissant un support matériel suffisant pour la mise en œuvre d'algorithmes accélérés.
Formation centrée sur les données et efficaceRécemment, les progrès des modèles à grande échelle ont été fulgurants, mais leurs exigences en matière de jeux de données ont pas une augmentation spectaculaire. D'énormes échantillons de données sont utilisés pour piloter le processus de formation et obtenir d'excellentes performances. Par conséquent, la recherche centrée sur les données est essentielle à une véritable accélération.
La fonction de base du traitement des données est d'augmenter efficacement la diversité des échantillons de données sans augmenter le coût de l'étiquetage en raison du coût de l'étiquetage des données. C'est souvent trop cher ; et ne peut pas être financé par certaines institutions de développement, ce qui souligne également l'importance de la recherche dans les domaines centrés sur les données ; dans le même temps, le traitement des données se concentre également sur l'amélioration de l'efficacité du chargement parallèle des échantillons de données ;
Les chercheurs appellent tout ce traitement efficace des données une approche « centrée sur les données », qui peut améliorer considérablement l'efficacité de la formation des modèles à grande échelle.
Cet article passe en revue et étudie la technologie sous les aspects suivants :
#🎜🎜 #dataregularizationData Regularization
La régularisation des données est une technique de prétraitement qui améliore les données d'origine grâce à une série de transformations de données. La diversité des échantillons peut améliorer la représentation équivalente des échantillons d'entraînement dans l'espace des fonctionnalités sans nécessiter d'informations d'étiquette supplémentaires. Des méthodes efficaces de régularisation des données sont largement utilisées dans le processus de formation et peuvent améliorer considérablement les performances de généralisation des modèles à grande échelle. Échantillonnage de données 🎜#L'échantillonnage de données est également une méthode efficace. Sélectionnez un sous-ensemble parmi un grand lot d'échantillons pour mettre à jour le dégradé. Son avantage est que sous la forme d'une formation en petits lots, il peut réduire ceux qui sont sans importance ou sans importance dans le lot actuel. L'impact des mauvais échantillons.
Apprentissage curriculaire centré sur les données #🎜 🎜#Le cours étudie la formation progressive paramètres à différentes étapes du processus de formation pour réduire le coût de calcul global. Au début, utilisez des ensembles de données de faible qualité pour l'entraînement qui sont suffisants pour apprendre des fonctionnalités de bas niveau, puis utilisez des ensembles de données de haute qualité (méthodes d'augmentation et de prétraitement plus complexes ; ) aident progressivement à apprendre des fonctionnalités complexes et à atteindre la même précision qu'en utilisant l'ensemble de la formation. Formation efficace centrée sur le modèle Concevoir une architecture de modèle efficace est toujours l'une des recherches les plus importantes dans le domaine du deep learning, un excellent Le modèle doit être un extracteur de fonctionnalités efficace qui peut être projeté en fonctionnalités de haut niveau facilement séparées. Presque tous les modèles à grande échelle sont composés de petits modules ou couches, de sorte que l'étude des modèles peut fournir des conseils pour une formation efficace des modèles à grande échelle, principalement des chercheurs. sous les aspects suivants :
Architecture Efficiency Avec l'augmentation rapide du nombre de paramètres dans les modèles profonds, cela entraîne également une énorme consommation de calcul. Par conséquent, il est nécessaire de mettre en œuvre une alternative efficace pour se rapprocher des performances de la version originale de l'architecture du modèle. Attirant également progressivement l'attention de la communauté universitaire, ce remplacement n'est pas seulement une approximation des calculs numériques, mais inclut également une simplification structurelle et une fusion dans des modèles profonds. Les chercheurs différencient les techniques d'accélération existantes en fonction de différentes architectures et présentent quelques observations et conclusions. Efficacité de l'entraînement en compression #🎜 🎜 La #Compression a toujours été un des axes de recherche en accélération du calcul et joue un rôle clé dans le traitement du signal numérique (informatique multimédia/traitement d'images). La compression traditionnelle comprend deux branches principales : la quantification et la parcimonie. L'article détaille leurs réalisations existantes et leurs contributions à l'entraînement approfondi. Efficacité d'initialisation # 🎜 🎜# L'initialisation des paramètres du modèle est un facteur très important dans l'analyse théorique et les scénarios pratiques existants. Un mauvais état d'initialisation peut même provoquer l'effondrement et la stagnation de l'ensemble de la formation au début de la formation, tandis qu'un bon état d'initialisation aidera en douceur à accélérer le convergence complète dans la plage de perte, cet article étudie principalement l'évaluation et la conception d'algorithmes du point de vue de l'initialisation du modèle.
D'un point de vue centré sur le modèle, l'apprentissage du cours commence généralement par la formation avec un petit modèle ou des paramètres partiels dans un modèle à grande échelle, puis revient progressivement à l'ensemble de l'architecture présentée dans le processus de formation accéléré avec ; De grands avantages et aucun effet négatif évident, l'article passe en revue la mise en œuvre et l'efficacité de cette méthode dans le processus de formation. Le schéma d'accélération des méthodes d'optimisation a toujours été une direction de recherche importante dans le domaine de l'apprentissage automatique. la complexité tout en optimisant les conditions a toujours été un objectif poursuivi par la communauté universitaire. Ces dernières années, des méthodes d'optimisation efficaces et puissantes ont fait des percées importantes dans la formation des réseaux de neurones profonds. En tant qu'optimiseurs de base largement utilisés dans l'apprentissage automatique, l'optimiseur de type SGD a réussi. aide les modèles profonds à réaliser diverses applications pratiques. Cependant, à mesure que le problème devient de plus en plus complexe, SGD est plus susceptible de tomber dans les minima locaux et ne peut pas se généraliser de manière stable. Afin de résoudre ces difficultés, Adam et ses variantes ont été proposées pour introduire l'adaptabilité dans les mises à jour. Cette approche a obtenu de bons résultats dans la formation en réseau à grande échelle. appliqué dans les modèles BERT, Transformer et ViT, par exemple. En plus des propres performances de l'optimiseur conçu, la combinaison de techniques de formation accélérées est également importante. Dans une perspective d'optimisation, les chercheurs ont résumé la réflexion actuelle sur la formation accélérée selon les aspects suivants : # 🎜 🎜#Taux d'apprentissage Taux d'apprentissage Le taux d'apprentissage est un hyperparamètre important pour l'optimisation non convexe, est également crucial dans la formation actuelle des réseaux profonds, et les méthodes adaptatives comme Adam et ses variantes ont réalisé des progrès remarquables dans les modèles profonds. Certaines stratégies d'ajustement du taux d'apprentissage en fonction de gradients d'ordre élevé permettent également d'obtenir une formation accélérée et une diminution du taux d'apprentissage La mise en œuvre affectera également les performances pendant l’entraînement. Grande taille de lot
Objectif efficace 🎜🎜#La GRE la plus élémentaire joue un rôle clé dans la minimisation des problèmes, rendant de nombreuses tâches pratiques. Avec l'approfondissement des recherches sur les grands réseaux, certains travaux accordent plus d'attention à l'écart entre optimisation et généralisation, et proposent des objectifs efficaces pour réduire les erreurs de test provenant de différentes interprétations ; l'importance de la généralisation du point de vue de la formation et son optimisation conjointe pendant la formation peuvent considérablement accélérer la précision des tests. #🎜🎜 ##### 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#Poids moyens#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜 🎜#La moyenne pondérée est pratique technique qui peut améliorer la polyvalence du modèle, car elle prend en compte la moyenne pondérée des états historiques et dispose d'un ensemble de coefficients figés ou apprenables, ce qui peut considérablement accélérer le processus de formation. formation efficace au budget Ce type de problème est défini comme une formation budgétisée, c'est-à-dire que la formation est effectuée dans le cadre d'un budget donné (limite de coût mesurable) pour atteindre les performances les plus élevées du modèle. Afin d'envisager systématiquement le support matériel pour se rapprocher de la situation réelle, les chercheurs définissent la formation budgétaire comme une formation sur un appareil donné et dans un temps limité, par exemple une formation sur un seul serveur deep learning bas de gamme pendant une journée pour obtenir le meilleures performances Modèle le plus performant. La recherche sur la formation dans le cadre du budget peut éclairer la façon d'élaborer des recettes de formation pour une formation dans le cadre du budget, y compris les configurations qui déterminent la taille du modèle, la structure du modèle, la planification du taux d'apprentissage et plusieurs autres facteurs réglables qui affecter les performances, en plus de combiner des techniques de formation efficaces adaptées aux budgets disponibles, cet article passe principalement en revue plusieurs techniques avancées de formation budgétaire. La recherche centrée sur le système consiste à fournir des méthodes de mise en œuvre spécifiques pour les algorithmes conçus et à étudier l'exécution efficace et pratique du matériel qui peut réellement réaliser une formation efficace. Les chercheurs se concentrent sur la mise en œuvre de dispositifs informatiques à usage général, tels que les dispositifs CPU et GPU dans des clusters multi-nœuds, et la résolution des conflits potentiels dans les algorithmes de conception d'un point de vue matériel est au cœur des préoccupations. Cet article passe principalement en revue les technologies d'implémentation matérielle dans les frameworks existants et les bibliothèques tierces. Ces technologies prennent en charge efficacement le traitement des données, les modèles et l'optimisation, et présente certaines plates-formes open source existantes pour faciliter l'établissement et l'efficacité des modèles. Fournit un cadre solide pour la formation avec des données, la formation de précision mixte et la formation distribuée. Efficacité des données centrée sur le système Le traitement efficace des données et le parallélisme des données sont deux préoccupations importantes dans la mise en œuvre du système. Avec l'augmentation rapide du volume de données, le traitement inefficace des données est progressivement devenu un goulot d'étranglement pour l'efficacité de la formation, en particulier pour la formation à grande échelle sur plusieurs nœuds. La conception de méthodes informatiques et de parallélisation plus conviviales peut efficacement éviter la perte de temps en formation. . Efficacité du modèle centrée sur le système Avec l'expansion rapide du nombre de paramètres de modèle, du point de vue du modèle, l'efficacité du système est devenue l'un des goulots d'étranglement importants. L'efficacité du stockage et du calcul pose d'énormes défis au matériel. mise en œuvre. Cet article explique principalement comment obtenir des E/S de déploiement efficaces et une mise en œuvre rationalisée du parallélisme des modèles pour accélérer la formation réelle. Efficacité de l'optimisation centrée sur le système Le processus d'optimisation représente la rétropropagation et la mise à jour à chaque itération, et est également le calcul le plus long de la formation, il est donc basé sur la réalisation du système. l'optimisation du centre détermine directement l'efficacité de la formation. Afin d'interpréter clairement les caractéristiques de l'optimisation du système, l'article se concentre sur l'efficacité des différentes étapes de calcul et passe en revue les améliorations de chaque processus. Frameworks Open Source Des frameworks open source efficaces peuvent faciliter la formation et servir de pont entre la conception d'algorithmes de greffage et le support matériel. Les chercheurs ont étudié une série de frameworks open source et analysé les avantages et les inconvénients de ceux-ci. chaque conception. Différent des autres travaux qui accordent une attention particulière aux architectures de modèles efficaces et nouvelles, cet article accorde plus d'attention à l'équivalence des modules communs dans la recherche « centrée sur les modèles » qui permettent d'obtenir une efficacité de formation plus élevée dans des circonstances comparables.
Apprentissage efficace centré sur l'optimisation
Formation efficace centrée sur le système

Conclusion
Les chercheurs ont examiné les techniques courantes d'accélération de la formation pour former efficacement des modèles d'apprentissage profond à grande échelle, en tenant compte de tous les composants de la formule de mise à jour du gradient, couvrant l'ensemble du processus de formation dans le domaine de l'apprentissage profond.
L'article propose également une nouvelle taxonomie, qui résume ces technologies en cinq directions principales : centrée sur les données, centrée sur le modèle, centrée sur l'optimisation, formation budgétaire et centrée sur le système comme centre.
Les quatre premières parties mènent principalement des recherches approfondies du point de vue de la conception et de la méthodologie des algorithmes, tandis que dans la partie « formation efficace centrée sur le système », du point de vue du paradigme innovation et support matériel La perspective résume la mise en œuvre réelle.
L'article passe en revue et résume les technologies couramment utilisées ou nouvellement développées correspondant à chaque partie, les avantages et les compromis de chaque technologie, et discute des limites et des perspectives Orientations de recherche futures tout en fournissant une revue technique et des conseils complets, cette revue propose également les avancées et les goulots d'étranglement actuels en matière de formation efficace.
Les chercheurs espèrent aider les chercheurs à accélérer efficacement la formation générale et fournir des impacts significatifs et prometteurs sur le développement futur d'une formation efficace en plus d'un certain potentiel ; développements mentionnés à la fin de chaque section, les points de vue plus larges et prometteurs sont les suivants : Recherche de profil efficace
Une formation efficace peut être utilisée pour pré-concevoir le modèle du point de vue de la combinaison d'amélioration des données, de la structure du modèle, de la conception de l'optimiseur, etc. Certains progrès ont été réalisés dans la recherche connexe sur les stratégies de recherche de profil intégrées et personnalisables.
Une nouvelle architecture de modèle et un nouveau mode de compression, de nouvelles tâches de pré-formation et l'utilisation des connaissances « de pointe du modèle » méritent également d'être explorées.
2. Planificateur adaptatif 🎜# Il est possible d'obtenir de meilleures performances en utilisant un planificateur orienté vers des optimisations telles que le cours l'apprentissage, le taux d'apprentissage et la taille des lots ainsi que la complexité du modèle ; un planificateur soucieux du budget peut s'adapter dynamiquement au budget restant, réduisant ainsi le coût de la conception manuelle. et des situations pratiques, telles qu'une formation décentralisée à grande échelle dans des réseaux hétérogènes couvrant plusieurs régions et centres de données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
