

Qu'est-ce que la classification de texte ?

Traducteur | Li Rui
Réviseur | Sun Shujuan
Qu'est-ce que la classification de texte ?
La classification de texte est le processus de classification du texte dans une ou plusieurs catégories différentes pour organiser, structurer et filtrer selon n'importe quel paramètre. Par exemple, la classification de texte est utilisée dans les documents juridiques, les études et documents médicaux, ou simplement dans les critiques de produits. Les données sont plus importantes que jamais ; de nombreuses entreprises dépensent d’énormes sommes d’argent pour essayer d’obtenir le plus d’informations possible.
Les données texte/document devenant beaucoup plus riches que les autres types de données, l'utilisation de nouvelles méthodes est impérative. Étant donné que les données sont par nature non structurées et extrêmement riches, les organiser de manière facile à comprendre pour leur donner un sens peut augmenter considérablement leur valeur. Utilisez la classification de texte et l'apprentissage automatique pour créer automatiquement des textes pertinents, plus rapidement et de manière plus rentable.
Ce qui suit définira la classification de texte, son fonctionnement, certains des algorithmes les plus connus et fournira des ensembles de données qui peuvent être utiles pour commencer votre parcours de classification de texte.
Pourquoi utiliser l'apprentissage automatique pour la classification de textes ?
- Échelle : la saisie, l'analyse et l'organisation manuelles des données sont fastidieuses et lentes. L'apprentissage automatique permet une analyse automatisée quelle que soit la taille de l'ensemble de données.
- Cohérence : une erreur humaine se produit en raison de la fatigue du personnel et de l'insensibilité au contenu de l'ensemble de données. L'apprentissage automatique améliore l'évolutivité et améliore considérablement la précision grâce à la nature impartiale et cohérente de l'algorithme.
- Vitesse : Parfois, vous devrez peut-être accéder et organiser les données rapidement. Les algorithmes d'apprentissage automatique peuvent analyser les données et fournir des informations d'une manière facile à comprendre.
6 Étapes générales

Certaines méthodes de base peuvent classer différents documents texte dans une certaine mesure, mais la méthode la plus courante utilise l'apprentissage automatique. Les modèles de classification de texte passent par six étapes de base avant de pouvoir être déployés.
1. Fournir des ensembles de données de haute qualité
Un ensemble de données est un bloc de données brutes utilisé comme source de données pour le modèle. Dans le cas de la classification de texte, des algorithmes d'apprentissage automatique supervisé sont utilisés, fournissant des données étiquetées au modèle d'apprentissage automatique. Les données étiquetées sont des données prédéfinies pour un algorithme et étiquetées avec des informations.
2. Filtrer et traiter les données
Étant donné que les modèles d'apprentissage automatique ne peuvent comprendre que des valeurs numériques, le texte fourni doit être tokenisé et intégré afin que le modèle puisse identifier correctement les données.
La tokenisation est le processus de division d'un document texte en parties plus petites appelées jetons. Les jetons peuvent être représentés sous forme de mots entiers, de sous-mots ou de caractères individuels. Par exemple, vous pouvez étiqueter votre travail de manière plus intelligente comme ceci :
- Mot d'étiquette : Smarter
- Sous-mot d'étiquette : Smart-er
- Caractère d'étiquette : S-m-a-r-t-e-r
Pourquoi la tokenisation est-elle importante ? Parce que les modèles de classification de texte ne peuvent traiter les données qu'à un niveau basé sur des jetons et ne peuvent pas comprendre et traiter des phrases complètes. Le modèle nécessite un traitement plus approfondi de l'ensemble de données brutes donné pour digérer facilement les données fournies. Supprimez les fonctionnalités inutiles, filtrez les valeurs nulles et infinies, et bien plus encore. La réorganisation de l'ensemble des données permettra d'éviter tout biais pendant la phase de formation.
3. Divisez l'ensemble de données en ensembles de données d'entraînement et de test
J'espère entraîner les données sur 80 % de l'ensemble de données tout en conservant 20 % de l'ensemble de données pour tester l'exactitude de l'algorithme.
4. Algorithme de formation
En exécutant le modèle à l'aide de l'ensemble de données de formation, l'algorithme peut classer le texte fourni en différentes catégories en identifiant des modèles et des informations cachés.
5. Testez et vérifiez les performances du modèle
Ensuite, testez l'intégrité du modèle à l'aide de l'ensemble de données de test mentionné à l'étape 3. L'ensemble de données de test ne sera pas étiqueté pour tester l'exactitude du modèle par rapport aux résultats réels. Afin de tester avec précision le modèle, l'ensemble de données de test doit contenir de nouveaux cas de test (données différentes de l'ensemble de données d'entraînement précédent) pour éviter un surajustement du modèle.
6. Ajustement du modèle
Ajustez le modèle d'apprentissage automatique en ajustant différents hyperparamètres du modèle sans surajustement ni génération de variance élevée. Un hyperparamètre est un paramètre dont la valeur contrôle le processus d'apprentissage du modèle. Il est maintenant prêt à être déployé.
Comment fonctionne la classification de texte ?
Incorporation de mots
Pendant le processus de filtrage mentionné ci-dessus, les algorithmes d'apprentissage automatique et profond ne peuvent comprendre que les valeurs numériques, obligeant les développeurs à appliquer certaines techniques d'intégration de mots sur l'ensemble de données. L'intégration de mots est le processus de représentation des mots comme des vecteurs à valeur réelle qui codent la signification d'un mot donné.
- Word2Vec : Il s'agit d'une méthode d'intégration de mots non supervisée développée par Google. Il utilise des réseaux de neurones pour apprendre à partir de grands ensembles de données textuelles. Comme son nom l'indique, la méthode Word2Vec convertit chaque mot en un vecteur donné.
- GloVe : également connu sous le nom de vecteur global, il s'agit d'un modèle d'apprentissage automatique non supervisé utilisé pour obtenir des représentations vectorielles de mots. Semblable à la méthode Word2Vec, l'algorithme GloVe mappe les mots dans un espace significatif, où la distance entre les mots est liée à la similarité sémantique.
- TF-IDF : TF-IDF est l'abréviation de Term Frequency-Inverse Text Frequency, qui est un algorithme d'intégration de mots utilisé pour évaluer l'importance des mots dans un document donné. TF-IDF attribue à chaque mot un score donné pour représenter son importance dans un ensemble de documents.
Algorithmes de classification de texte
Voici trois des algorithmes de classification de texte les plus célèbres et les plus efficaces. Il est important de se rappeler qu’il existe des algorithmes plus définis intégrés à chaque méthode.
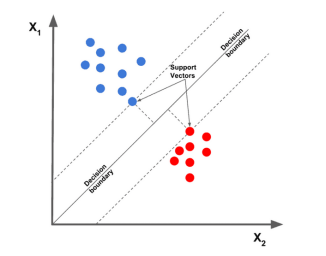
1. Machine à vecteurs de support linéaire
L'algorithme de la machine à vecteurs de support linéaire est considéré comme l'un des meilleurs algorithmes de classification de texte actuellement. Il dessine un point de données donné en fonction d'une caractéristique donnée, puis dessine une ligne la mieux ajustée, Split. et classer les données en différentes catégories.
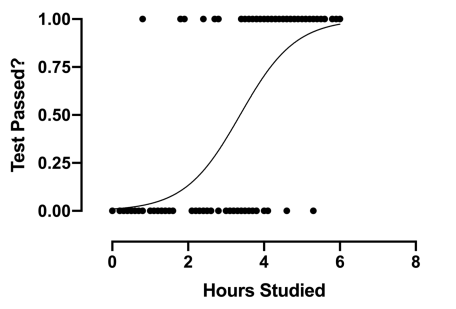
2. Régression logistique
La régression logistique est une sous-catégorie de régression, se concentrant principalement sur les problèmes de classification. Il utilise les limites de décision, la régression et la distance pour évaluer et classer les ensembles de données.
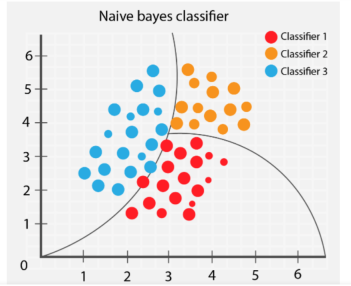
3. Naive Bayes
L'algorithme Naive Bayes classe différents objets en fonction des caractéristiques fournies par les objets. Les limites des groupes sont ensuite tracées pour déduire ces classifications de groupes en vue d'une résolution et d'une classification ultérieures.
Quels problèmes doivent être évités lors de la configuration de la classification de texte
1. Données d'entraînement surchargées
Fournir des données de mauvaise qualité à l'algorithme entraînera de mauvaises prédictions futures. Un problème courant pour les praticiens de l’apprentissage automatique est que les modèles de formation contiennent trop d’ensembles de données et incluent des fonctionnalités inutiles. Une utilisation excessive de données non pertinentes entraînera une diminution des performances du modèle. Et lorsqu’il s’agit de sélectionner et d’organiser des ensembles de données, moins c’est plus.
Un mauvais rapport entre les données d'entraînement et les données de test peut grandement affecter les performances du modèle et affecter le brassage et le filtrage des données. Les points de données précis ne seront pas interférés par d'autres facteurs indésirables et le modèle entraîné fonctionnera plus efficacement.
Lors de la formation d'un modèle, sélectionnez un ensemble de données qui répond aux exigences du modèle, filtrez les valeurs inutiles, mélangez l'ensemble de données et testez l'exactitude du modèle final. Les algorithmes plus simples nécessitent moins de temps et de ressources de calcul, et les meilleurs modèles sont les plus simples capables de résoudre des problèmes complexes.
2. Surapprentissage et sous-apprentissage
Lorsque l'entraînement atteint son apogée, la précision du modèle diminue progressivement à mesure que l'entraînement se poursuit. C'est ce qu'on appelle le surapprentissage ; car la formation dure trop longtemps, le modèle commence à apprendre des modèles inattendus. Soyez prudent lorsque vous obtenez une précision élevée sur l'ensemble d'entraînement, car l'objectif principal est de développer un modèle dont la précision est ancrée dans l'ensemble de test (données que le modèle n'a pas vues auparavant).
D'un autre côté, le sous-apprentissage signifie que le modèle entraîné a encore place à l'amélioration et n'a pas encore atteint son potentiel maximum. Les modèles mal formés proviennent de la durée de la formation ou d'une régularisation excessive de l'ensemble de données. Cela illustre ce que signifie disposer de données concises et précises.
Trouver le sweet spot est crucial lors de la formation de votre modèle. Diviser l'ensemble de données 80/20 est un bon début, mais l'ajustement des paramètres peut être ce dont un modèle particulier a besoin pour fonctionner de manière optimale.
3. Format de texte incorrect
Bien que cela ne soit pas mentionné en détail dans cet article, l'utilisation du format de texte correct pour les problèmes de classification de texte donnera de meilleurs résultats. Certaines méthodes de représentation des données textuelles incluent GloVe, Word2Vec et les modèles d'intégration.
L'utilisation du format de texte correct améliorera la façon dont le modèle lit et interprète l'ensemble de données, ce qui l'aidera à comprendre les modèles.
Application de classification de texte

- Filtrer le spam : les e-mails peuvent être classés comme utiles ou spam en recherchant certains mots-clés.
- Classification de texte : en utilisant la classification de texte, l'application peut classer différents éléments (articles et livres, etc.) dans différentes catégories en catégorisant le texte associé (tel que les noms et descriptions d'éléments, etc.). L'utilisation de ces techniques améliore l'expérience car elle facilite la navigation des utilisateurs dans la base de données.
- Identifier les discours de haine : certaines sociétés de médias sociaux utilisent la classification de texte pour détecter et interdire les commentaires ou les publications offensants.
- Marketing et publicité : les entreprises peuvent apporter des modifications spécifiques pour satisfaire leurs clients en comprenant comment les utilisateurs réagissent à certains produits. Il peut également recommander certains produits sur la base des avis des utilisateurs sur des produits similaires. Les algorithmes de classification de texte peuvent être utilisés conjointement avec les systèmes de recommandation, un autre algorithme d'apprentissage en profondeur utilisé par de nombreux sites Web en ligne pour fidéliser les clients.
Ensembles de données de classification de texte populaires
Avec un grand nombre d'ensembles de données étiquetés et prêts à l'emploi, vous pouvez rechercher à tout moment l'ensemble de données parfait qui répond aux exigences de votre modèle.
Bien que vous puissiez avoir quelques difficultés à décider lequel utiliser, certains des ensembles de données les plus connus accessibles au public sont recommandés ci-dessous. Ensemble de données IMDB
- Kaggle etc. Le site Web contient divers ensembles de données couvrant tous les sujets. Vous pouvez essayer d'exécuter le modèle sur plusieurs des ensembles de données ci-dessus pour vous entraîner.
- Classification de textes dans l'apprentissage automatique
- L'apprentissage automatique ayant eu un impact énorme au cours de la dernière décennie, les entreprises essaient par tous les moyens possibles d'exploiter l'apprentissage automatique pour automatiser leurs processus. Les critiques, les articles, les revues et les documents sont tous d’une valeur inestimable dans le texte. Et en utilisant la classification de texte de diverses manières créatives pour extraire les informations et les modèles des utilisateurs, les entreprises peuvent prendre des décisions fondées sur des données ; les professionnels peuvent accéder et apprendre des informations précieuses plus rapidement que jamais.
- Titre original : Qu'est-ce que la classification de texte ?
- , auteur : Kevin Vu
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
 Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
Flash Attention est-il stable ? Meta et Harvard ont constaté que les écarts de poids de leur modèle fluctuaient de plusieurs ordres de grandeur.
May 30, 2024 pm 01:24 PM
MetaFAIR s'est associé à Harvard pour fournir un nouveau cadre de recherche permettant d'optimiser le biais de données généré lors de l'apprentissage automatique à grande échelle. On sait que la formation de grands modèles de langage prend souvent des mois et utilise des centaines, voire des milliers de GPU. En prenant comme exemple le modèle LLaMA270B, sa formation nécessite un total de 1 720 320 heures GPU. La formation de grands modèles présente des défis systémiques uniques en raison de l’ampleur et de la complexité de ces charges de travail. Récemment, de nombreuses institutions ont signalé une instabilité dans le processus de formation lors de la formation des modèles d'IA générative SOTA. Elles apparaissent généralement sous la forme de pics de pertes. Par exemple, le modèle PaLM de Google a connu jusqu'à 20 pics de pertes au cours du processus de formation. Le biais numérique est à l'origine de cette imprécision de la formation,
 Apprentissage automatique en C++ : un guide pour la mise en œuvre d'algorithmes d'apprentissage automatique courants en C++
Jun 03, 2024 pm 07:33 PM
Apprentissage automatique en C++ : un guide pour la mise en œuvre d'algorithmes d'apprentissage automatique courants en C++
Jun 03, 2024 pm 07:33 PM
En C++, la mise en œuvre d'algorithmes d'apprentissage automatique comprend : Régression linéaire : utilisée pour prédire des variables continues. Les étapes comprennent le chargement des données, le calcul des poids et des biais, la mise à jour des paramètres et la prédiction. Régression logistique : utilisée pour prédire des variables discrètes. Le processus est similaire à la régression linéaire, mais utilise la fonction sigmoïde pour la prédiction. Machine à vecteurs de support : un puissant algorithme de classification et de régression qui implique le calcul de vecteurs de support et la prédiction d'étiquettes.
 Perspectives sur les tendances futures de la technologie Golang dans l'apprentissage automatique
May 08, 2024 am 10:15 AM
Perspectives sur les tendances futures de la technologie Golang dans l'apprentissage automatique
May 08, 2024 am 10:15 AM
Le potentiel d'application du langage Go dans le domaine de l'apprentissage automatique est énorme. Ses avantages sont les suivants : Concurrence : il prend en charge la programmation parallèle et convient aux opérations intensives en calcul dans les tâches d'apprentissage automatique. Efficacité : les fonctionnalités du garbage collector et du langage garantissent l’efficacité du code, même lors du traitement de grands ensembles de données. Facilité d'utilisation : la syntaxe est concise, ce qui facilite l'apprentissage et l'écriture d'applications d'apprentissage automatique.
