
 Périphériques technologiques
IA
13 948 questions, couvrant 52 sujets tels que le calcul et la génération de lignes, ont été soumises à l'Université Tsinghua pour réaliser un ensemble de tests pour le grand modèle chinois.
Périphériques technologiques
IA
13 948 questions, couvrant 52 sujets tels que le calcul et la génération de lignes, ont été soumises à l'Université Tsinghua pour réaliser un ensemble de tests pour le grand modèle chinois.
13 948 questions, couvrant 52 sujets tels que le calcul et la génération de lignes, ont été soumises à l'Université Tsinghua pour réaliser un ensemble de tests pour le grand modèle chinois.

L'émergence de ChatGPT a fait prendre conscience à la communauté chinoise de l'écart avec le premier niveau international. Récemment, le développement de grands modèles chinois bat son plein, mais il existe très peu de références d'évaluation chinoises.
Dans le processus de développement de la série OpenAI GPT/de la série Google PaLM/de la série DeepMind Chinchilla/de la série Anthropic Claude, les trois ensembles de données MMLU/MATH/BBH ont joué un rôle crucial car ils couvrent de manière plus complète les capacités dans chaque dimension de le modèle. Le plus remarquable est l’ensemble de données MMLU, qui prend en compte les capacités globales de connaissances de 57 disciplines, des sciences humaines aux sciences sociales en passant par les sciences et l’ingénierie. Les modèles Gopher et Chinchilla de DeepMind ne prennent en compte que les scores MMLU. Nous souhaitons donc construire une liste de référence chinoise, suffisamment différenciée et multidisciplinaire pour aider les développeurs à développer de grands modèles chinois.
Nous avons passé environ trois mois à construire un programme couvrant quatre grandes directions : sciences humaines, sciences sociales, sciences et ingénierie, et autres spécialités, et 52 matières (calcul, génération de lignes...), du collège au diplômé universitaire. étudiants et examen professionnel, un total de 13948 questions de tests de connaissances et de raisonnement chinois, nous l'appelons C-Eval pour aider la communauté chinoise à développer de grands modèles.
Cet article enregistre notre processus de construction de C-Eval et partage notre réflexion et nos priorités de R&D de notre point de vue avec les développeurs. Notre objectif le plus important est d'aider au développement du modèle, et non de faire des classements . La poursuite aveugle d'un classement élevé sur la liste entraînera de nombreuses conséquences néfastes, mais si C-Eval peut être utilisé scientifiquement pour aider à modéliser l'itération, C-Eval peut être maximisé. Par conséquent, nous recommandons de traiter l'ensemble de données et la liste C-Eval du point de vue du développement du modèle.
- Site Web : https://cevalbenchmark.com/
- Github : https://github.com/SJTU-LIT/ce
- Article : https://arxiv.org/abs/2305.08322
Table des matières

1 - Indicateurs de base de la force du modèle
Tout d'abord, ajustez un modèle Il n'est pas difficile de devenir un robot conversationnel. Il existe déjà des robots conversationnels comme Alpaca, Vicuna et RWKV dans le monde open source. Cela fait du bien de discuter avec eux avec désinvolture. Mais si vous voulez vraiment que ces modèles deviennent productifs, il suffit de le faire. discuter avec désinvolture ne suffit pas. Par conséquent, le premier problème dans la construction d’un référentiel d’évaluation est de trouver le degré de différenciation et de déterminer quel type de capacité est l’indicateur de base qui distingue la force d’un modèle. Nous considérons les deux noyaux de la connaissance et du raisonnement.
1.1 - Connaissance
Pourquoi la capacité de connaissance est-elle la capacité de base ? Il y a plusieurs arguments comme suit :
- Nous espérons que le modèle pourra être universel et contribuer à la productivité dans différents domaines, ce qui nécessite naturellement que le modèle connaisse la connaissance de chaque domaine.
- Nous espérons également que le modèle ne dira pas de bêtises et ne saura pas ce qu'il ne sait pas. Cela nécessite également d'élargir les connaissances du modèle pour qu'il puisse dire qu'il ne sait pas moins souvent.
- Dans la liste d'évaluation HELM English de Stanford, une conclusion importante est que la taille du modèle est significativement positivement corrélée à l'exécution de tâches à forte intensité de connaissances, car le nombre de paramètres du modèle peut être utilisé pour stocker des connaissances.
- Comme mentionné ci-dessus, les modèles importants existants, tels que Gopher/Chinchilla de DeepMind, ne prennent presque en compte que MMLU lors de l'évaluation. Le cœur de MMLU est de mesurer la couverture des connaissances du modèle.
- Dans le blog de sortie de GPT-4, la première chose est de répertorier les performances du modèle sur divers examens de matières comme mesure de la capacité du modèle.
Ainsi, les capacités basées sur les connaissances sont une bonne mesure du potentiel du modèle de base.
1.2 - Raisonnement
La capacité de raisonnement est la capacité de s'améliorer davantage sur la base des connaissances. Elle indique si le modèle peut faire des choses très difficiles et complexes. Pour qu’un modèle soit solide, il a d’abord besoin de connaissances approfondies, puis il fait des déductions basées sur ces connaissances.
L'argument important pour raisonner est :
- Dans le blog de publication de GPT-4, OpenAI a clairement écrit "La différence apparaît lorsque la complexité de la tâche atteint un seuil suffisant" (GPT-3.5 et GPT La différence de -4 n'apparaît qu'une fois que la tâche devient complexe à un certain niveau). Cela montre que les modèles forts ont des capacités d’inférence significatives, tandis que les modèles plus faibles n’ont pas beaucoup de capacités.
- Dans le rapport technique de PaLM-2, les deux ensembles de données d'inférence BBH et MATH sont spécialement répertoriés pour discussion et concentration.
- Si vous souhaitez que le modèle devienne une nouvelle génération de plate-forme informatique et y crée un nouvel écosystème d'applications, vous devez rendre le modèle suffisamment solide pour accomplir des tâches complexes.
Ici, nous devons également clarifier la relation entre le raisonnement et la connaissance :
- Les capacités basées sur la connaissance sont la base des capacités du modèle, et les capacités de raisonnement sont une sublimation supplémentaire - le raisonnement du modèle est également basé sur l'existant. graphe de connaissances.
- Sur la liste des tâches basées sur les connaissances, la taille du modèle et le score du modèle changent généralement continuellement. Il est peu probable qu'il y ait un déclin abrupt simplement parce que le modèle est petit - de ce point de vue, les tâches basées sur les connaissances. sont plus différenciés.
- Sur la liste des tâches de raisonnement, il peut y avoir un changement de phase entre la taille du modèle et le score du modèle uniquement lorsque le modèle est suffisamment grand dans une certaine mesure (probablement 50B et plus, c'est-à-dire le niveau de LLaMA). 65B), la capacité de raisonnement du modèle apparaîtra.
- Pour les tâches basées sur la connaissance, les effets des invites de chaîne de pensée (CoT) et de réponse seule (AO) sont presque les mêmes ; pour les tâches de raisonnement, CoT est nettement meilleur que AO.
- Vous devez donc vous rappeler ici que CoT n'ajoute que des effets de raisonnement mais pas des effets de connaissance. Nous avons également observé ce phénomène dans l'ensemble de données C-Eval.
2 - L'objectif de C-Eval
Avec l'explication ci-dessus des connaissances et du raisonnement, nous avons décidé de partir de la tâche basée sur les connaissances et de construire un ensemble de données pour tester la capacité de connaissance du modèle, qui est équivalent à l'analyse comparative de l'ensemble de données MMLU ; en même temps, nous espérons également apporter du contenu lié au raisonnement pour mesurer davantage les capacités d'ordre élevé du modèle, nous avons donc spécialement extrait les sujets qui nécessitent un raisonnement fort dans C-Eval ( calcul, algèbre linéaire, probabilités...) et les a nommés C-Eval Le sous-ensemble Hard est utilisé pour mesurer la capacité de raisonnement du modèle, ce qui équivaut à une analyse comparative de l'ensemble de données MATH.
Sur C-Eval Hard, le modèle doit d'abord avoir des connaissances liées aux mathématiques, puis doit avoir une idée de résolution de problème étape par étape, puis doit appeler Wolfram Alpha/Mathematica/Matlab pour les données numériques. et symbolique/différenciation et intégration pendant le processus de résolution de problèmes. La capacité de calculer et d'exprimer le processus de calcul et les résultats au format Latex. Cette partie de la question est très difficile.
C-Eval espère comparer MMLU dans son ensemble (cet ensemble de données est utilisé pour le développement de GPT-3.5, GPT-4, PaLM, PaLM-2, Gopher, Chinchilla), et espère comparer la partie dure. MATH (cet ensemble de données est utilisé dans le développement de GPT-4, PaLM-2, Minerva, Galactica).
Il convient de noter ici que notre objectif le plus important est de aider au développement du modèle, et non de lister . Rechercher aveuglément un classement élevé sur la liste entraînera de nombreuses conséquences néfastes, que nous expliquerons sous peu, mais si vous pouvez utiliser C-Eval de manière scientifique pour aider à modéliser l'itération, vous obtiendrez d'énormes avantages ; Nous recommandons de traiter l'ensemble de données et la liste C-Eval du point de vue du développement du modèle.
2.1 - L'objectif est d'aider au développement de modèles
Dans le processus de recherche et développement actuel, nous avons souvent besoin de connaître la qualité d'une certaine solution ou la qualité d'un certain modèle. cette fois, nous avons besoin d'un ensemble de données pour nous aider à tester. Voici deux scènes classiques :
- Scénario 1, recherche d'hyperparamètres auxiliaires : Nous avons plusieurs schémas de mélange de données de pré-entraînement, et nous ne savons pas lequel est le meilleur, nous les comparons donc les uns aux autres sur C-Eval pour déterminer le données de pré-entraînement optimales.
- Scénario 2, comparant la phase d'entraînement du modèle : J'ai un point de contrôle pré-entraîné et un point de contrôle réglé par les instructions, puis je veux mesurer l'effet de mon réglage des instructions, afin que je peut combiner les deux. Les points de contrôle sont comparés entre eux sur C-Eval pour mesurer la qualité relative de la pré-formation et du réglage des instructions.
2.2 - Le classement n'est pas l'objectif
Nous devons souligner pourquoi le classement sur la liste ne devrait pas être l'objectif :
- Si vous faites du classement de la liste votre objectif, ce sera facile à ignorer pour des scores élevés. S'adapter à la liste, mais perdre en polyvalence - c'est une leçon importante que la communauté universitaire de la PNL a apprise en peaufinant Bert avant GPT-3.5.
- La liste elle-même ne mesure que le potentiel du modèle, pas la véritable expérience utilisateur - si le modèle est vraiment apprécié par les utilisateurs, il nécessite encore beaucoup d'évaluation manuelle
- Si l'objectif est le classement, c'est il est facile de prendre des raccourcis pour obtenir des scores élevés. La qualité et l’esprit d’une recherche scientifique solide ont été perdus.
Par conséquent, si C-Eval est utilisé comme un outil d'aide au développement, son rôle positif peut être maximisé, mais s'il est utilisé comme classement de liste, il y aura une énorme utilisation abusive des risques de C-Eval, et il y a de fortes chances qu’il n’y ait pas de bons résultats au final.
Encore une fois, nous recommandons de traiter l'ensemble de données et la liste C-Eval du point de vue du développement du modèle.
2.3 - Itération continue à partir des commentaires des développeurs
Parce que nous espérons que le modèle pourra soutenir les développeurs au maximum, nous choisissons de communiquer directement avec les développeurs et de continuer à apprendre et à itérer à partir des commentaires des développeurs - Ceci nous a également permis d'apprendre beaucoup ; tout comme le grand modèle est l'apprentissage par renforcement à partir des commentaires humains, l'équipe de développement de C-Eval continue d'apprendre à partir des commentaires des développeurs.
Plus précisément, au cours de notre processus de recherche et développement, a invité ByteDance. , SenseTime, Shenyan et d'autres sociétés pour intégrer C-Eval dans leurs propres flux de travail de test, puis ont communiqué entre elles sur les points difficiles du processus de test. Ce processus nous a permis d'apprendre beaucoup de choses auxquelles nous ne nous attendions pas au début :
- De nombreuses équipes de tests, même au sein d'une même entreprise, ne peuvent connaître aucune information pertinente sur le modèle testé (test boîte noire), ou même savoir si le modèle a subi un réglage des instructions, nous devons donc prendre en charge à la fois l'apprentissage en contexte et les invites zéro tir.
- Parce que certains modèles sont des tests en boîte noire, il n'y a aucun moyen d'obtenir des logits, mais il est plus difficile de déterminer si les petits modèles n’ont pas de réponse logits, nous devons donc déterminer un ensemble de petits modèles pour déterminer la réponse.
- Il existe de nombreux types de modèles de test de modèles, tels que l'apprentissage en contexte et les invites à tir nul ; il existe de nombreux formats d'invite, tels que les modèles à réponse seule et à chaîne de pensée ; , tels que le point de contrôle pré-entraîné et le point de contrôle affiné par les instructions, nous devons donc clarifier l'impact et l'interaction respectifs de ces facteurs.
- Le modèle est très sensible aux invites, à savoir si une ingénierie rapide est nécessaire et si une ingénierie rapide nuit à l'équité.
- L'ingénierie rapide de GPT-3.5 / GPT-4 / Claude / PaLM doit être effectuée, puis apprendre de leur expérience.
Les problèmes ci-dessus ont été découverts grâce aux commentaires des développeurs lors de nos interactions avec eux. Ces problèmes ont été résolus dans la documentation et le code github de la version publique actuelle de C-Eval.
Les processus ci-dessus prouvent également que traiter l'ensemble de données et la liste C-Eval du point de vue du développement de modèles peut très bien aider tout le monde à développer de grands modèles chinois.
Nous invitons tous les développeurs à soumettre des problèmes et des pull request à notre GitHub pour nous faire savoir comment mieux vous aider, nous espérons mieux vous aider :)
3 - Comment garantir la qualité
Dans ce chapitre, nous discutons les méthodes que nous avons utilisées pour garantir la qualité de l’ensemble de données pendant le processus de production. Nos références les plus importantes ici sont les deux ensembles de données MMLU et MATH. Parce que les quatre grandes équipes de modèles les plus importantes, OpenAI, Google, DeepMind et Anthropic, se concentrent toutes sur MMLU et MATH, nous espérons donc pouvoir contribuer à ces deux-là. Ensembles de données mis en ligne. Après nos recherches préliminaires et une série de discussions, nous avons pris deux décisions importantes. L'une était de créer manuellement l'ensemble de données à partir de zéro, et l'autre était de nous concentrer sur empêcher la question d'être le robot d'exploration. rampe dans l'ensemble d'entraînement .
3.1 - Fait main
Une inspiration importante dans le processus de développement de GPT est que dans le domaine de l'intelligence artificielle, il y a autant d'intelligence qu'il y a d'intelligence artificielle. C'est également très bon dans le processus. de la construction de C-Eval. Plus précisément, à partir de la source des questions :
- La plupart des questions de C-Eval sont dérivées de fichiers aux formats pdf et word. De telles questions nécessitent un traitement supplémentaire et un nettoyage (manuel) avant d'être traitées. peut être utilisé. En effet, il y a trop de questions diverses sur Internet. Les questions qui existent directement sous forme de texte de page Web ont probablement été utilisées dans la pré-formation du modèle. Ensuite, il y a les questions de traitement :
. Après avoir collecté les questions, effectuez d'abord l'OCR pour convertir électroniquement le fichier pdf, puis unifiez le format en Markdown, et la partie mathématique est unifiée au format Latex. Le traitement des formules est une chose gênante : premièrement, l'OCR peut ne pas être en mesure. pour le reconnaître correctement, et alors l'OCR ne peut pas être directement reconnu comme Latex ; notre approche ici est de le convertir automatiquement en Latex s'il peut être automatiquement converti. S'il ne peut pas être automatiquement converti, les étudiants le saisiront manuellement
- . Le résultat final est que tout le contenu lié aux symboles dans plus de 13 000 questions (y compris les formules mathématiques et les formules chimiques, telles que H2O) a été vérifié un par un par les étudiants de notre équipe de projet. Environ une douzaine de nos étudiants ont passé près de deux ans. semaines à faire ça
- Alors maintenant, notre sujet Il peut être très joliment présenté sous forme de démarque. Nous donnons ici un exemple de calcul. Cet exemple peut être vu directement dans la section explorer de notre site Web :
- .
- La prochaine difficulté est de savoir comment construire l'invite officielle de chaîne de pensée. Le point clé ici est que nous devons nous assurer que notre CoT est correct. Notre approche initiale consistait à laisser GPT-4 générer une chaîne de pensée pour chaque exemple en contexte, mais nous avons constaté plus tard que cela n'était pas réalisable. Premièrement, celle générée était trop longue (plus de 2048 jetons). la longueur de certains modèles peut ne pas être prise en charge ; l'autre est que le taux d'erreur est trop élevé. Il est préférable de vérifier chacun par vous-même
 Donc, nos étudiants se basent sur le CoT généré par GPT-4, calcul, génération de lignes. , Probabilité, discrétisation de ces questions rapides (5 questions pour chaque sujet comme exemples contextuels), je l'ai vraiment fait moi-même. Voici un exemple :
Donc, nos étudiants se basent sur le CoT généré par GPT-4, calcul, génération de lignes. , Probabilité, discrétisation de ces questions rapides (5 questions pour chaque sujet comme exemples contextuels), je l'ai vraiment fait moi-même. Voici un exemple :
- L'élève de gauche l'a fait. il l'a fait lui-même, puis l'a écrit au format Markdown - Latex ; le côté droit est l'effet rendu

3.2 - Éviter que nos questions ne soient mélangées dans l'ensemble de formation
Dans un souci d'évaluation scientifique, nous avons envisagé une série de des mécanismes pour éviter que nos questions ne soient mélangées à l'ensemble de formation
- Tout d'abord, notre ensemble de tests ne divulgue que les questions mais pas les réponses. Vous pouvez utiliser votre propre modèle pour exécuter les réponses localement et les soumettre sur le site Web, puis le score sera donné en arrière-plan
- . Ensuite, toutes les questions du C-Eval sont toutes des questions de simulation. Nous n'avons pas utilisé de vraies questions du collège aux examens d'entrée de troisième cycle en passant par les examens professionnels. En effet, les vraies questions des examens nationaux sont largement disponibles en ligne et sont très simples. à intégrer dans l'ensemble de formation du modèle
Bien sûr, malgré nos efforts, il peut inévitablement arriver que des questions de la banque de questions puissent être recherchées sur une certaine page Web, mais nous pensons que cette situation devrait être rare. Et à en juger par les résultats dont nous disposons, les questions C-Eval sont encore suffisamment différenciées, notamment la partie Difficile.
4 - Méthodes pour améliorer le classement
Ensuite, nous analysons quelles méthodes peuvent être utilisées pour améliorer le classement du modèle. Nous listons d'abord pour vous les raccourcis, notamment l'utilisation de LLaMA, qui n'est pas disponible dans le commerce, et l'utilisation des données générées par GPT, ainsi que les inconvénients de ces méthodes ; puis nous discutons de la manière difficile mais correcte.
4.1 - Quels raccourcis puis-je prendre ?
Voici les raccourcis que vous pouvez prendre :
- Utilisez LLaMA comme modèle de base : Dans notre autre projet de révision de modèles anglais connexe Chain-of-thought Hub, nous avons souligné le Le modèle 65B LLaMA est un modèle de base légèrement plus faible que le GPT-3.5. Il a un grand potentiel s'il est entraîné avec des données chinoises, ses puissantes capacités en anglais peuvent être automatiquement transférées au chinois.
- Mais les inconvénients de ceci sont : Premièrement, la limite supérieure des capacités de R&D est verrouillée par LLaMA 65B, et il est impossible de dépasser GPT-3.5, sans parler de GPT-4 de l'autre. D'autre part, LLaMA n'est pas disponible dans le commerce, son utilisation pour la commercialisation violera directement la réglementation
- Utilisez les données générées par GPT-4 : Surtout la partie C-Eval Hard, laissez GPT-4 le faire directement, puis alimentez la réponse GPT-4 à Créez simplement votre propre modèle
- Mais les inconvénients de ceci sont que, premièrement, il s'agit d'une triche pure et simple, et les résultats obtenus ne peuvent pas être généralisés et ne peuvent pas représenter les véritables capacités du modèle ; , s'il est commercialisé, il viole directement l'utilisation de la réglementation OpenAI ; troisièmement, la distillation à partir de GPT-4 intensifiera le phénomène d'absurdité du modèle En effet, lorsque RLHF affine la capacité de rejet du modèle, il encourage le modèle. pour savoir ce qu'il sait et ce qu'il ne sait pas ; mais directement. Si vous copiez GPT-4, les autres modèles ne savent pas nécessairement ce que GPT-4 sait. Cela encouragera les modèles à dire des bêtises. Ce phénomène a été mis en évidence lors d'une récente conférence de John Schulman à Berkeley. Souvent, ce qui semble être un raccourci porte en réalité un prix secrètement indiqué.
4.2 - Chemin difficile mais correct
Le meilleur moyen est d'être autonome et de se développer à partir de zéro. Cette chose est difficile, prend du temps et demande de la patience, mais c’est la bonne voie. Plus précisément, vous devez vous concentrer sur les articles des institutions suivantes
OpenAI - Il ne fait aucun doute que tous les articles doivent être mémorisés dans leur intégralité
- Anthropic - Ce qu'OpenAI ne fait pas je vous le dis, Anthropic vous le dira
- Google DeepMind - Google est plutôt une arnaque, vous indiquant honnêtement toutes les technologies, contrairement à OpenAI qui est caché et caché
- Si le lecteur est inexpérimenté, alors vous peut arrêter de lire des articles provenant d’autres endroits. Développez d’abord votre jugement, puis lisez des articles provenant d’autres endroits, afin de pouvoir faire la distinction entre le bien et le mal. Dans le monde universitaire, il est important de faire la distinction entre le bien et le mal plutôt que de simplement accepter sans jugement.
Pendant le processus de recherche et développement, il est recommandé de prêter attention au contenu suivant :
- Comment regrouper les données de pré-entraînement, telles que la méthode DoReMi
- Comment augmenter la stabilité du pré-entraînement, comme la méthode BLOOM
- Comment regrouper les données de réglage des instructions, telles que The Flan Collection
- Comment effectuer des réglages d'instructions, tels que l'auto-instruction
- Comment faire du RL, tels que l'IA constitutionnelle
- Comment augmenter les capacités de raisonnement, comme notre blog précédent
- Comment augmenter les capacités de codage, comme StarCoder
- Comment augmenter les outils La capacité d'utiliser (C-Eval Hard nécessite que le modèle puisse appeler des outils pour faire des calculs scientifiques), comme toolformer
4.3 - Ne vous inquiétez pas
Les grands modèles prennent du temps, c'est une clé de l'intelligence artificielle Un test complet des capacités industrielles :
- La série GPT d'OpenAI est passée de GPT-3 à GPT-4, de 2019 à 2023 , cela a pris au total quatre ans.
- Après la séparation de l'équipe d'origine d'Anthropic d'OpenAI, même avec l'expérience de GPT-3, il a fallu un an pour refaire Claude. L’équipe de
- LLaMA, même avec les leçons d’OPT et BLOOM, a mis six mois.
- GLM-130B a mis deux ans entre la création du projet et sa sortie.
- La partie alignement de MOSS, le contenu avant RL, a également pris près de six mois, et cela n'inclut toujours pas RL.
Par conséquent, il n'est pas nécessaire de se précipiter pour obtenir le classement, pas besoin de voir les résultats demain, pas besoin d'aller en ligne après-demain - prenez votre temps et faites-le étape par étape. Bien souvent, le chemin difficile mais correct est en réalité le chemin le plus rapide.
5 - Conclusion
Dans cet article, nous avons présenté les objectifs de développement, le processus et les considérations clés de C-Eval. Notre objectif est d'aider les développeurs à mieux développer de grands modèles chinois et de promouvoir l'utilisation scientifique de C-Eval dans le monde universitaire et industriel pour faciliter l'itération des modèles. Nous ne sommes pas pressés de voir les résultats, car les grands modèles eux-mêmes sont une chose très difficile. Nous connaissons les raccourcis que nous pouvons prendre, mais nous savons aussi que le chemin difficile mais correct est en réalité le chemin le plus rapide. Nous espérons que ce travail pourra promouvoir l'écosystème de R&D des grands modèles chinois et permettre aux gens de découvrir plus tôt la commodité apportée par cette technologie.
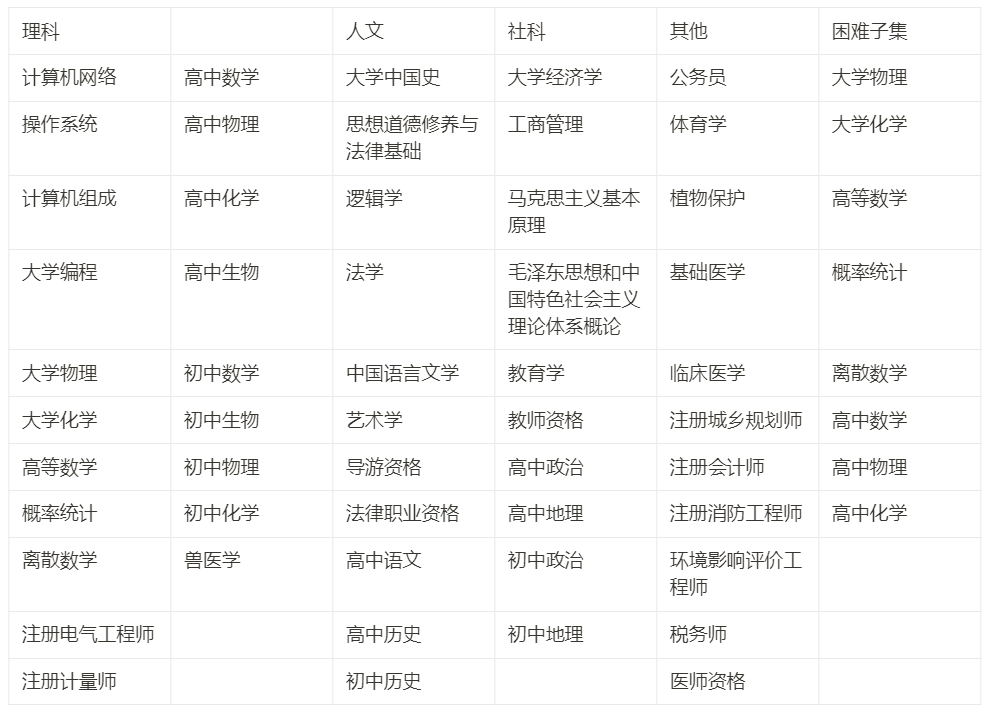
Annexe 1 : Sujets inclus dans C-Eval
Annexe 2 : Contributions des membres du projet

Remarque : Les papiers mentionnés dans le l'article peut trouver l'URL correspondante sur la page d'origine.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Le FP8 et la précision de quantification inférieure en virgule flottante ne sont plus le « brevet » du H100 ! Lao Huang voulait que tout le monde utilise INT8/INT4, et l'équipe Microsoft DeepSpeed a commencé à exécuter FP6 sur A100 sans le soutien officiel de NVIDIA. Les résultats des tests montrent que la quantification FP6 de la nouvelle méthode TC-FPx sur A100 est proche ou parfois plus rapide que celle de INT4, et a une précision supérieure à celle de cette dernière. En plus de cela, il existe également une prise en charge de bout en bout des grands modèles, qui ont été open source et intégrés dans des cadres d'inférence d'apprentissage profond tels que DeepSpeed. Ce résultat a également un effet immédiat sur l'accélération des grands modèles : dans ce cadre, en utilisant une seule carte pour exécuter Llama, le débit est 2,65 fois supérieur à celui des cartes doubles. un
 Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Lien du projet écrit devant : https://nianticlabs.github.io/mickey/ Étant donné deux images, la pose de la caméra entre elles peut être estimée en établissant la correspondance entre les images. En règle générale, ces correspondances sont 2D à 2D et nos poses estimées sont à échelle indéterminée. Certaines applications, telles que la réalité augmentée instantanée, à tout moment et en tout lieu, nécessitent une estimation de pose des métriques d'échelle, elles s'appuient donc sur des estimateurs de profondeur externes pour récupérer l'échelle. Cet article propose MicKey, un processus de correspondance de points clés capable de prédire les correspondances métriques dans l'espace d'une caméra 3D. En apprenant la correspondance des coordonnées 3D entre les images, nous sommes en mesure de déduire des métriques relatives.
 Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
À la pointe de la technologie logicielle, le groupe de l'UIUC Zhang Lingming, en collaboration avec des chercheurs de l'organisation BigCode, a récemment annoncé le modèle de grand code StarCoder2-15B-Instruct. Cette réalisation innovante a permis une percée significative dans les tâches de génération de code, dépassant avec succès CodeLlama-70B-Instruct et atteignant le sommet de la liste des performances de génération de code. Le caractère unique de StarCoder2-15B-Instruct réside dans sa stratégie d'auto-alignement pur. L'ensemble du processus de formation est ouvert, transparent et complètement autonome et contrôlable. Le modèle génère des milliers d'instructions via StarCoder2-15B en réponse au réglage fin du modèle de base StarCoder-15B sans recourir à des annotations manuelles coûteuses.
