

Quels sont les concepts de contraintes et d'index MySQL

1. Règles de conception de bases de données relationnelles
Suivez le modèle ER et les trois paradigmes
E entité représente l'entité correspondant à la base de données Une des tables
R relation signifie relation
Trois formes normales :
# 🎜🎜#1. Les colonnes ne peuvent pas être divisées 2. Identifiant unique 3. Clé primaire de référence de relation Incarnation concrète#. 🎜🎜#
- Mettez les données dans le tableau, puis placez le tableau dans la bibliothèque.
- Il peut y avoir plusieurs tables dans une base de données, et chaque table a un nom pour s'identifier. Les noms de tables sont uniques.
- Les tables ont certaines caractéristiques qui définissent la façon dont les données sont stockées dans la table, similaires à la conception des « classes » en Java et Python.
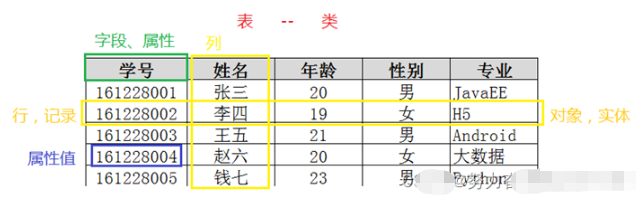
- Les tableaux sont constitués de colonnes, que l'on appelle aussi des champs. La conception du tableau de données est en fait la conception et la description de la signification de chaque champ. Lors de la création d'une table de données, vous devez spécifier le type de données pour chaque champ, définir la longueur des données et leur nom. Chaque champ est similaire à un "attribut d'instance" en Java ou Python.
- Les données du tableau sont stockées en lignes, et une ligne est un enregistrement. Chaque ligne est similaire à un "objet" en Java ou Python.
 2. La notion d'intégrité des données et les contraintes et index
2. La notion d'intégrité des données et les contraintes et index
1. L'intégrité (intégrité des données) fait référence à l'exactitude (précision) et à la fiabilité (fiabilité) des données. Ce point vise à empêcher l'existence de données non conformes aux réglementations sémantiques dans la base de données, et en même temps à éviter des opérations ou des erreurs invalides. causée par la saisie et la sortie d'informations incorrectes.
L'intégrité des données doit être considérée sous les quatre aspects suivants :
- Entité. Intégrité : Par exemple, le même Dans le tableau, il ne peut pas y avoir deux enregistrements identiques et indiscernables
- Intégrité du domaine (Intégrité du domaine) : Par exemple : tranche d'âge 0-120 , tranche de genre "masculin/féminin"
- Intégrité Référentielle : Par exemple : le service où se trouve le salarié, ce service doit se retrouver dans la table des départements #🎜🎜 #
- # 🎜🎜#
Intégrité définie par l'utilisateur : Par exemple : le nom d'utilisateur est unique, le mot de passe ne peut pas être vide, etc. Le salaire du responsable de ce département ne doit pas être supérieur à 5 fois le salaire moyen des employés de ce département # 🎜🎜#
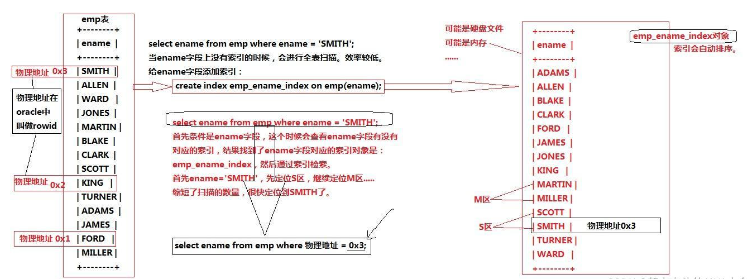
- 2 LES CONTRAINTESLes contraintes sont utilisées pour mettre en œuvre et maintenir la portée des règles métier des données. et l'intégrité des données. Uniquement dans la base de données actuelle, les contraintes peuvent être traitées comme des objets de base de données. Elles ont des noms et des modèles associés, et sont des contraintes logiques. 🎜🎜#L'index est une structure de base de données physique distincte stockée sur la page de données. Il s'agit d'une collection d'une ou plusieurs valeurs de colonne dans le tableau et de la logique correspondante de la page de données d'identification physique qui pointe vers la valeur des données dans la liste de pointeurs (similaire à la page d'index du répertoire du dictionnaire Xinhua) L'existence de l'index augmentera l'espace de stockage de la base de données et augmentera également le coût en temps d'insertion et de modification des données (car lors de l'insertion et de la modification des données). , l'index changera également), mais peut améliorer considérablement la vitesse des requêtes. Par conséquent, les index doivent être créés sur des colonnes clés ou d'autres colonnes fréquemment interrogées, triées et recherchées par plage. Pour les colonnes rarement utilisées et référencées dans les requêtes, ou des colonnes modifiées très fréquemment, les index ne doivent pas être créés sur des colonnes avec peu de valeurs (par exemple, le sexe est uniquement masculin et féminin). Un index est automatiquement créé sur la colonne clé. Si d'autres colonnes doivent être indexées, ils doivent être créés manuellement.
#查看某个表的约束 SELECT * FROM information_schema.table_constraints WHERE table_name = '表名称'; 或 SHOW CREATE TABLE 表名; #查看某个表的索引 SHOW INDEX FROM 表名称;
 2. La clé primaire est divisée en clé primaire à colonne unique et clé primaire composite (la clé primaire composite n'est pas recommandée car la clé primaire composite viole les trois paradigmes. ) :
2. La clé primaire est divisée en clé primaire à colonne unique et clé primaire composite (la clé primaire composite n'est pas recommandée car la clé primaire composite viole les trois paradigmes. ) : #单个字段设置主键
create table t_user(
id int primary key,
username varchar(20),
password varchar(20)
);
create table t_user(
id int,
username varchar(20),
password varchar(20),
primary key(id)
);
#多个字段设置联合主键
drop table t_user;
create table t_user(
id int,
username varchar(20),
password varchar(20),
primary key(id,username)
);
#了解
#在建表后指定主键约束
alter table 表名称 add primary key (主键字段列表);
#删除主键约束
alter table 表名称 drop primary key;Caractéristiques des clés primaires :
1 Il ne peut y avoir qu'une seule clé primaire dans une table
#🎜. 🎜##🎜 🎜#2. La valeur du champ défini comme clé primaire est unique et non vide
3. se compose de plusieurs champs, le champ ne peut pas être utilisé pour le moment. Pour définir la clé primaire plus tard, vous devez utiliser "clé primaire (champ, champ)" après que tous les champs puissent être répétés individuellement, mais ne peuvent pas être répétés en même temps.
5. La création d'une clé primaire créera automatiquement un index correspondant, et la suppression de la clé primaire supprimera également l'index correspondant.
- 3. Contrainte d'auto-incrémentation : auto_increment
create table t_user( id int primary key auto_increment, username varchar(20), password varchar(20) ); #建表后指定自增长列 alter table [数据库.]表名 modify 自增字段名 数据类型 auto_increment; #删除自增约束 alter table 表名 modify 自增字段名 数据类型;Copier après la connexionLes caractéristiques de la contrainte d'auto-incrémentation :
Requiert une table Il n'existe qu'un seul champ dont la clé primaire est de type auto-incrémenté. Ce champ doit être un entier et ne peut pas être vide. Habituellement, les contraintes de clé ne sont définies que sur la clé primaire, telles que les contraintes de clé primaire, les contraintes de clé unique et les contraintes de clé étrangère2、设置为自增的字段,从1开始自增;每次添加数据,都会在该字段最大值的基础上+1
3、使字段自增的方式:
如果是空或者0,则实际插入的将是自动增长后的值。
a> insert into t_user(username,password) values(‘admin’,‘123456’);
b> insert into t_user values(null,‘root’,‘123456’); (推荐使用)
c> insert into t_user values(0,‘root’,‘123456’);
4、唯一键约束:unique key
create table t_user( id int primary key auto_increment, username varchar(20) unique key, password varchar(20) unique key ); create table t_user( id int primary key auto_increment, username varchar(20), password varchar(20), unique key(username,password) ); #在建表后增加唯一键约束 alter table 表名称 add 【constraint 约束名】 unique key (字段名列表); #如果没有指定约束名,(字段名列表)中只有一个字段的,默认是该字段名,如果是多个字段的默认是字段名列表的第1个字段名。也可以通过show index from 表名;来查看 #删除唯一键约束 ALTER TABLE 表名称 DROP INDEX 唯一性约束名; #注意:如果忘记名称,可以通过“show index from 表名称;”查看Copier après la connexion唯一键约束的特点:
1、设置唯一键约束的字段值唯一,但是可以为null
2、一张表可以设置多个唯一键约束,也可以设置联合唯一键,即多个字段设置一个唯一约束,但是不能使用"unique key"写在字段后设置,必须写在所有字段后,使用"unique key(字段,字段)"
3、联合唯一键要求组成唯一约束的字段可以单独重复,不能同时重复
4、 MySQL会给唯一约束的列上默认创建一个唯一索引。
5、删除唯一键只能通过删除对应索引的方式删除,删除时需要指定唯一键索引名
5、非空约束:not null
create table t_user( id int primary key auto_increment, username varchar(20) unique key not null, password varchar(20) ); #在建表后指定某个字段非空 ALTER TABLE 表名称 MODIFY 字段名 数据类型 NOT NULL 【default 默认值】; #如果该字段原来设置了默认值约束,要跟着一起再写一遍,否则默认值约束会丢失 #取消某个字段非空 ALTER TABLE 表名称 MODIFY 字段名 数据类型 【default 默认值】; #如果该字段原来设置了默认值约束,要跟着一起再写一遍,否则默认值约束会丢失Copier après la connexion非空约束的特点:
设置为非空约束的字段的值不能为null
6、默认值约束:default
create table t_user( id int primary key auto_increment, username varchar(20) unique key not null, password varchar(20), gender char not null default '男' );Copier après la connexion添加数据时使用默认值的方式:
不为该字段赋值或使用关键字default
insert into t_user(username,password) values(‘root’,‘123’);
insert into t_user values(null,‘admin123’,‘123’,default);
insert into t_user values(null,‘admin’,‘123’,null); //此方式不可以,会为该字段赋值为null
7、外键约束:foreign key
表关系:
1、一对一
2、多对一,在多的一方引用一的主键
student(sid,sname,age,sex,cid)–clazz(cid,cname,location)
3、一对多,在多的一方引用一的主键
clazz(cid,cname,location)–student(sid,sname,age,sex,cid)
4、多对多
user(uid,username,password)
order(oid,create_time,total_count,total_amount,status,user_id)
order_goods(id,oid,gid)
goods(gid,gname,price,sales,stock)
create table t_dept( id int primary key auto_increment, name varchar(20) ); create table t_emp( id int primary key auto_increment, name varchar(20), age int, gender char, dept_id int, foreign key(dept_id) references t_dept(id) #外键只能在所有字段列表后面单独指定 ); #在建表后指定外键约束 alter table 从表名称 add 【constraint 外键约束名】 foreign key (从表字段名) references 主表名(主表被参照字段名) 【on update xx】[on delete xx]; #删除外键约束 ALTER TABLE 表名称 DROP FOREIGN KEY 外键约束名; #查看某个表的约束名 SELECT * FROM information_schema.table_constraints WHERE table_name = '表名称'; 或 SHOW CREATE TABLE 表名; #删除外键约束不会删除对应的索引,如果需要删除索引,需要用ALTER TABLE 表名称 DROP INDEX 索引名; #查看索引名 show index from 表名称;Copier après la connexion(1)外键特点
外键约束是保证一个或两个表之间的参照完整性,外键是构建于一个表的两个字段或是两个表的两个字段之间的参照关系。
在创建外键约束时,如果不给外键约束名称,默认名不是列名,而是自动产生一个外键名(例如 student_ibfk_1;),也可以指定外键约束名。
当创建外键约束时,系统默认会在所在的列上建立对应的普通索引。但是索引名是列名,不是外键的约束名。
删除外键时,关于外键列上的普通索引需要单独删除。
(2)要求
在从表上建立外键,而且主表要先存在。
一个表可以建立多个外键约束
从表的外键列,在主表中引用的只能是键列(主键,唯一键,外键),推荐引用主表的主键。
从表的外键列与主表被参照的列名字可以不相同,但是数据类型必须一样
(3)约束关系:约束是针对双方的
添加了外键约束后,主表的修改和删除数据受约束
添加了外键约束后,从表的添加和修改数据受约束
在从表上建立外键,要求主表必须存在
删除主表时,要求从表先删除,或将从表中外键引用该主表的关系先删除
(4)5个约束等级
Cascade方式:在父表上update/delete记录时,同步update/delete掉子表的匹配记录
Set null方式:在父表上update/delete记录时,将子表上匹配记录的列设为null,但是要注意子表的外键列不能为not null
No action方式:如果子表中有匹配的记录,则不允许对父表对应候选键进行update/delete操作
Restrict方式:同no action, 都是立即检查外键约束
Set default方式(在可视化工具SQLyog中可能显示空白):父表有变更时,子表将外键列设置成一个默认的值,但Innodb不能识别
如果没有指定等级,就相当于Restrict方式
8、检查约束:check
检查约束,mysql暂不支持
create table stu( sid int primary key, sname varchar(20), gender char check ('男'or'女') ); insert into stu values(1,'张三','男'); insert into stu values(2,'李四','妖'); 使用枚举类型解决如上问题: create table stu( sid int primary key, sname varchar(20), gender enum ('男','女') );
Copier après la connexionCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
Dans la base de données MySQL, la relation entre l'utilisateur et la base de données est définie par les autorisations et les tables. L'utilisateur a un nom d'utilisateur et un mot de passe pour accéder à la base de données. Les autorisations sont accordées par la commande Grant, tandis que le tableau est créé par la commande Create Table. Pour établir une relation entre un utilisateur et une base de données, vous devez créer une base de données, créer un utilisateur, puis accorder des autorisations.
 MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL convient aux débutants car il est simple à installer, puissant et facile à gérer les données. 1. Installation et configuration simples, adaptées à une variété de systèmes d'exploitation. 2. Prise en charge des opérations de base telles que la création de bases de données et de tables, d'insertion, d'interrogation, de mise à jour et de suppression de données. 3. Fournir des fonctions avancées telles que les opérations de jointure et les sous-questionnaires. 4. Les performances peuvent être améliorées par l'indexation, l'optimisation des requêtes et le partitionnement de la table. 5. Prise en charge des mesures de sauvegarde, de récupération et de sécurité pour garantir la sécurité et la cohérence des données.
 Intégration RDS MySQL avec Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Intégration RDS MySQL avec Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Simplification de l'intégration des données: AmazonrDSMysQL et l'intégration Zero ETL de Redshift, l'intégration des données est au cœur d'une organisation basée sur les données. Les processus traditionnels ETL (extrait, converti, charge) sont complexes et prennent du temps, en particulier lors de l'intégration de bases de données (telles que AmazonrDSMysQL) avec des entrepôts de données (tels que Redshift). Cependant, AWS fournit des solutions d'intégration ETL Zero qui ont complètement changé cette situation, fournissant une solution simplifiée et à temps proche pour la migration des données de RDSMySQL à Redshift. Cet article plongera dans l'intégration RDSMYSQL ZERO ETL avec Redshift, expliquant comment il fonctionne et les avantages qu'il apporte aux ingénieurs de données et aux développeurs.
 Comment remplir le nom d'utilisateur MySQL et le mot de passe
Apr 08, 2025 pm 07:09 PM
Comment remplir le nom d'utilisateur MySQL et le mot de passe
Apr 08, 2025 pm 07:09 PM
Pour remplir le nom d'utilisateur et le mot de passe MySQL: 1. Déterminez le nom d'utilisateur et le mot de passe; 2. Connectez-vous à la base de données; 3. Utilisez le nom d'utilisateur et le mot de passe pour exécuter des requêtes et des commandes.
 L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
1. Utilisez l'index correct pour accélérer la récupération des données en réduisant la quantité de données numérisées SELECT * FROMMLOYEESEESHWHERELAST_NAME = 'SMITH'; Si vous recherchez plusieurs fois une colonne d'une table, créez un index pour cette colonne. If you or your app needs data from multiple columns according to the criteria, create a composite index 2. Avoid select * only those required columns, if you select all unwanted columns, this will only consume more server memory and cause the server to slow down at high load or frequency times For example, your table contains columns such as created_at and updated_at and timestamps, and then avoid selecting * because they do not require inefficient query se
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Navicat lui-même ne stocke pas le mot de passe de la base de données et ne peut récupérer que le mot de passe chiffré. Solution: 1. Vérifiez le gestionnaire de mots de passe; 2. Vérifiez la fonction "Remember Motway" de Navicat; 3. Réinitialisez le mot de passe de la base de données; 4. Contactez l'administrateur de la base de données.
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
