

Quelles sont les syntaxes de base pour l'injection xPath ?

Tout d'abord, qu'est-ce que xPath : xPath est un langage permettant de rechercher des informations en XML
xPath contient sept types de nœuds : éléments, attributs, texte, espaces de noms, instructions de traitement, commentaires et nœuds racine du document. Les documents XML sont analysés selon la structure de l'arborescence des documents. La racine de l'arborescence des documents est appelée nœud de document ou nœud racine.

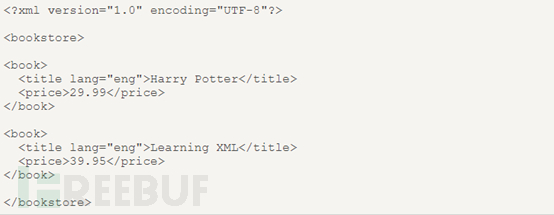
Il s'agit du code source d'un document XML de base. À partir de ce code source XML, nous pouvons voir que la librairie est le nœud du document (nœud racine) et que le livre, le titre, l'auteur, l'année et le prix sont des éléments. nœuds. Le nœud livre a quatre nœuds d'éléments enfants : titre, auteur, année, prix, et le nœud titre a trois frères et sœurs : auteur, année, prix. Le nœud d'élément de titre a un attribut et un nœud de texte. Le nœud d'attribut est lang et sa valeur est en. La valeur du nœud de texte est HarryPotter.
Vous trouverez également ci-dessous quelques descriptions des relations entre les nœuds XML (semblables aux arbres dans les structures de données) :
Parent : le parent du nœud de livre est la librairie et le nœud de livre est le parent du titre, de l'auteur, de l'année et nœuds de prix. (Chaque nœud ne peut avoir qu'un seul parent).
Enfant : le livre est l'enfant de la librairie et l'enfant du nœud du livre est l'enfant du titre, de l'auteur, de l'année et du prix.
(Le nœud élément peut avoir zéro, un ou plusieurs enfants).
Les éléments frères du titre incluent l'auteur, l'année et le prix. Ces éléments ont le même nœud parent, similaire aux nœuds frères dans une structure arborescente. (Les nœuds peuvent avoir zéro, un ou plusieurs frères et sœurs).
Ancêtres : le parent du nœud, le parent du parent, le parent du parent (boucle infinie), les ancêtres du nœud de l'élément titre sont livre et librairie.
Descendants : enfants de nœuds, enfants d'enfants, enfants d'enfants (boucle infinie), les descendants des nœuds de documents de librairie sont livre, titre, auteur, année, prix, langue.
Il ne suffit pas de connaître les relations entre les nœuds du XML, vous devez également savoir comment il est interrogé. xPath utilise des expressions de chemin pour sélectionner des nœuds ou des ensembles de nœuds dans le document. Les nœuds sont sélectionnés le long de chemins ou d'étapes.
XPath utilise des expressions de chemin pour sélectionner des nœuds dans les documents XML. Les nœuds sont sélectionnés en suivant un chemin ou une étape. Les expressions de chemin les plus utiles sont répertoriées ci-dessous :
nodename : sélectionne tous les nœuds de ce nœud
/ : sélectionne à partir du nœud racine
// : sélectionne les nœuds du document à partir du nœud actuel qui correspondent à la sélection, quel que soit leur positions
.: Sélectionnez le nœud actuel
..: Sélectionnez le nœud parent du nœud actuel
@: Sélectionnez les attributs
Interrogons directement en utilisant la syntaxe de requête XPath via js
Écrivons d'abord un article sur les appels XPath html ( le code appelant est écrit dans le modèle de fichier js), puis préparez un fichier XML pour la requête.
Le code source du modèle js est le suivant :
https://www.runoob.com/try/try.php?filename=try_xpath_select_cdnodes
Regardez le code js dans ce fichier html un par un (car il n'y a que du code js)
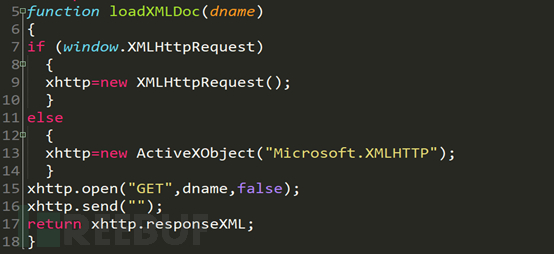
Il s'agit d'une fonction d'appel asynchrone de js. Les codes importants se trouvent aux lignes 15 et 17. La fonction dname transmise par la fonction à la ligne 15 est le chemin du XML et la ligne. 17 renvoie le fichier XML obtenu.
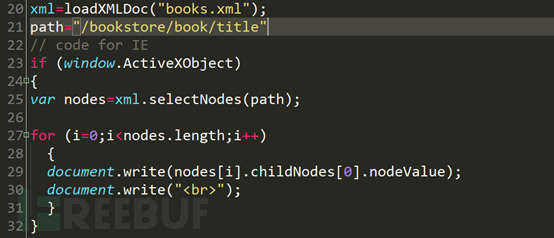
Veuillez vous référer à la ligne 20. La variable xml obtient le fichier XML obtenu après l'exécution de la fonction loadXMLDOC. La variable path à la ligne 21 est la syntaxe de requête de XPath. La première instruction if détermine s'il s'agit d'un navigateur de IE6 ou inférieur, s'il s'agit d'un navigateur de IE6 ou inférieur, après avoir obtenu le tableau de nœuds de la requête correspondante, les valeurs du tableau sont parcourues et affichées sur la page.
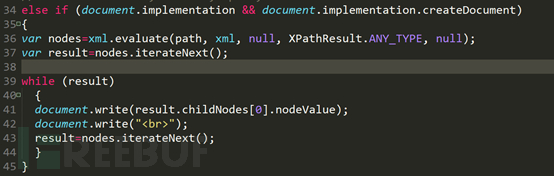
Pour les navigateurs non-IE6 et inférieurs, le processus d'exécution de la deuxième instruction if est le même, mais la syntaxe est légèrement différente pour les requêtes des navigateurs non-IE6 et inférieurs via la fonction d'évaluation, et le format est fondamentalement différent. corrigé. Pratiquez ce que vous venez de dire Plusieurs grammaires.
Pour remplacer la syntaxe de la requête, il vous suffit de modifier la valeur du chemin.

Énumérez d'abord la syntaxe qui doit être interrogée :
Remarque : Si le chemin commence par une barre oblique (/), ce chemin représente toujours le chemin absolu vers un élément !
bookstore : sélectionnez tous les nœuds enfants de l'élément bookstore.
/librairie : Sélectionnez la librairie de l'élément racine.
bookstore/book : sélectionne tous les éléments de livre qui sont des éléments enfants de la librairie.
//book : Sélectionne tous les éléments enfants du livre quelle que soit leur position dans le document.
bookstore//book : sélectionne tous les éléments book qui descendent de l'élément bookstore, quel que soit leur emplacement sous bookstore :.
//@lang : Sélectionnez tous les attributs nommés lang.
L'utilisation de ces requêtes uniques peut ne pas obtenir les résultats attendus, vous devez les combiner avec d'autres instructions de requête. Voici une syntaxe qui doit être respectée :
Prédicat (utilisez des crochets pour obtenir des résultats de requête plus précis) :
Sélectionnez le chemin du premier sous-élément book de l'élément bookstore vers /bookstore/book [1].
/bookstore/book[last()] : Sélectionnez le dernier élément du livre qui est un élément enfant de la librairie.
/bookstore/book[last()-1] : Sélectionnez l'avant-dernier élément book qui est un élément enfant de bookstore.
/bookstore/book[position()
//title[@lang] : Sélectionnez tous les éléments de titre avec un attribut nommé lang.
//title[@lang='eng'] : sélectionne tous les éléments de titre qui ont un attribut lang avec une valeur de eng.
/bookstore/book[price>35.00] : Sélectionnez tous les éléments book de l'élément bookstore, et la valeur de l'élément price doit être supérieure à 35,00.
/bookstore/book[price>35.00]/title : Sélectionnez tous les éléments de titre de l'élément book dans l'élément bookstore, et la valeur de l'élément price doit être supérieure à 35,00.
Sélectionnez les nœuds inconnus :
* : faites correspondre n'importe quel nœud d'élément.
@* : fait correspondre n'importe quel nœud d'attribut.
node() : correspond à tout type de nœud.
Par exemple :
/bookstore/* : Sélectionnez tous les éléments enfants de l'élément bookstore.
//* : Sélectionnez tous les éléments du document.
//title[@*] : Sélectionnez tous les éléments de titre avec des attributs.
Sélectionnez plusieurs chemins :
//book/title | //book/price : Sélectionnez tous les éléments de titre et de prix de l'élément book.
//titre | //prix : Sélectionnez tous les éléments de titre et de prix dans le document.
/bookstore/book/title | //price : Sélectionnez tous les éléments de titre appartenant à l'élément book de l'élément bookstore, et tous les éléments de prix dans le document
Regardez quelques exemples de requête :
Interrogez le titre du deuxième livre Valeur : /bookstore/book[1]/title

Interroger la valeur du titre de tous les livres : /bookstore/book//title

Interroger la valeur de tous les titres avec le attribut lang : /bookstore /book//title[@lang]

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP en action : extraire des données de documents XML à l'aide de XPath
Jun 13, 2023 pm 10:03 PM
PHP en action : extraire des données de documents XML à l'aide de XPath
Jun 13, 2023 pm 10:03 PM
XPath est un outil très utile lorsque vous travaillez avec des données XML à l'aide de PHP. XPath est un langage permettant de localiser des éléments dans des documents XML. Il aide les développeurs à extraire rapidement et facilement les données requises des documents XML. Dans cet article, nous présenterons les concepts de base de XPath et expliquerons en détail comment utiliser XPath en PHP. Nous montrerons comment utiliser XPath pour extraire des données d'un document XML et créer un simple
 Comment analyser le contenu HTML à l'aide de PHP et XPath
Jun 17, 2023 am 11:17 AM
Comment analyser le contenu HTML à l'aide de PHP et XPath
Jun 17, 2023 am 11:17 AM
À mesure que la technologie Web continue de se développer, le contenu des pages Web devient de plus en plus complexe. Nous avons souvent besoin d'extraire des informations des pages HTML pour un traitement et une analyse ultérieurs, tels que des robots d'exploration, l'exploration de données, etc. Cet article explique comment utiliser PHP et XPath pour analyser le contenu HTML et obtenir les informations dont nous avons besoin rapidement et facilement. PHPSimpleHTMLDOMParserPHPSimpleHTMLDOMParser est un logiciel open source
 Explication détaillée de l'utilisation de la fonction PHP XPath : XPath fournit des fonctions de recherche et de requête pour les fichiers XML et HTML.
Jun 27, 2023 pm 01:04 PM
Explication détaillée de l'utilisation de la fonction PHP XPath : XPath fournit des fonctions de recherche et de requête pour les fichiers XML et HTML.
Jun 27, 2023 pm 01:04 PM
XPath est un langage permettant d'interroger et de localiser des nœuds spécifiques dans les documents XML et HTML. En tant que langage d'expression de chemin, XPath est largement utilisé dans de nombreux langages de programmation, dont PHP. Dans cet article, nous examinerons en profondeur l'utilisation des fonctions PHPXPath afin que vous puissiez facilement utiliser XPath dans vos projets pour rechercher et interroger des fichiers XML et HTML. Qu’est-ce que XPath ? XPath est un langage permettant d'interroger et de localiser des nœuds spécifiques dans les documents XML et HTML.
 Quelles sont les syntaxes de base pour l'injection xPath ?
May 26, 2023 pm 12:01 PM
Quelles sont les syntaxes de base pour l'injection xPath ?
May 26, 2023 pm 12:01 PM
Tout d'abord, qu'est-ce que xPath : xPath est un langage permettant de rechercher des informations en XML. Dans xPath, il existe sept éléments de nœuds : éléments, attributs, texte, espaces de noms, instructions de traitement, commentaires et documents (nœuds racine). Les documents XML sont analysés sous forme d'arborescences de documents et la racine de l'arborescence est appelée nœud de document ou nœud racine. Il s'agit du code source d'un document XML de base. Comme le montre ce code source XML, la librairie est le nœud du document (nœud racine), et le livre, le titre, l'auteur, l'année et le prix sont les nœuds d'élément. Le nœud livre a quatre nœuds d'éléments enfants : titre, auteur, année, prix, et le nœud titre a trois frères et sœurs : au
 Technologie DOM et XPath en PHP
May 11, 2023 pm 04:04 PM
Technologie DOM et XPath en PHP
May 11, 2023 pm 04:04 PM
Ces dernières années, avec le développement continu d’Internet, la technologie de développement Web a également été continuellement mise à jour et réitérée. Parmi eux, le langage PHP est largement utilisé dans le domaine du développement Web en raison de sa facilité d’apprentissage et d’utilisation, de sa vitesse d’exécution rapide et de ses caractéristiques multiplateformes. En PHP, les technologies DOM et XPath sont des technologies couramment utilisées lors du développement d'applications Web. Cet article présentera en détail les connaissances de base et les scénarios d'application de ces deux technologies. 1. Technologie DOM DOM (Document Object Model, DocumentObjectModel) est un moyen de traiter du XML ou du HTM
 Comment utiliser Python pour XPath, JsonPath et bs4 ?
May 09, 2023 pm 09:04 PM
Comment utiliser Python pour XPath, JsonPath et bs4 ?
May 09, 2023 pm 09:04 PM
1.xpath1.1xpath Utilisez Google pour installer le plug-in XPath à l'avance. Appuyez sur ctrl+shift+x et une petite boîte noire apparaîtra pour installer la bibliothèque lxml pipinstalllxml-ihttps://pypi.douban.com/simple Import. lxml.etreefromlxmlimportetreeetree.parse() pour analyser le fichier local html_tree =etree.parse('XX.html')etree.HTML() fichier de réponses du serveur html_tree=etree.HTML(respon
 Utilisez XPATH pour rechercher du texte contenant
Sep 10, 2023 am 11:33 AM
Utilisez XPATH pour rechercher du texte contenant
Sep 10, 2023 am 11:33 AM
Nous pouvons utiliser le localisateur XPath pour identifier les éléments dont le texte de recherche est avec ou des espaces. Vérifions d'abord le code HTML d'un élément Web pour les espaces de fin et de début. Dans l'image ci-dessous, le texte JAVABASICS comporte des espaces comme le reflète le code HTML, le nom de balise Strong. Si l'élément a des espaces dans son texte ou dans la valeur d'un attribut, alors pour créer un XPath pour un tel élément, nous devons utiliser la fonction d'espace normalisé. Il supprime tous les espaces de fin et de début de la chaîne. Il supprime également chaque nouvelle balise ou ligne existante dans la chaîne. Syntaxe//tagname[normalize-space (@attribute/functio)
 Un examen approfondi des types et des utilisations des sélecteurs JavaScript
Dec 26, 2023 pm 12:38 PM
Un examen approfondi des types et des utilisations des sélecteurs JavaScript
Dec 26, 2023 pm 12:38 PM
Une exploration approfondie des différents types et utilisations des sélecteurs JavaScript Introduction : JavaScript est un langage de script puissant largement utilisé dans le développement Web. Au cours du processus de développement, nous devons souvent obtenir ou manipuler des éléments HTML via des sélecteurs. JavaScript fournit différents types de sélecteurs pour répondre à différents besoins. Cet article explorera en profondeur les différents types et utilisations des sélecteurs JavaScript et fournira des exemples de code concrets. 1. sélection getElementById
