

Quels sont les scénarios d'utilisation de Redis ?

Résumé des commandes couramment utilisées dans Redis : y compris un résumé de la complexité temporelle et des structures de données utilisées dans Redis pour des types de données spécifiques ;
Fonctionnalités avancées de Redis : y compris la persistance, la réplication, les sentinelles et l'introduction du cluster ;
Comprendre Redis : comprendre la mémoire ; et blocage ;Cette partie est très importante. Tout ce qui a été présenté précédemment peut être utilisé comme technique, et cela devrait appartenir à la partie Tao
Compétences de développement : il s'agit principalement d'un résumé de certains développements pratiques, y compris la conception du cache et les pièges courants ;
Commençons la première partie et jetons un autre regard sur Redis.
Le contenu de cette série est basé sur : redis-3.2.12
Redis n'est pas une panacée
Lors des entretiens, on me demande souvent de comparer les avantages et les inconvénients de Redis et Memcache. J'ai personnellement l'impression que les deux le sont. ne convient pas pour la comparaison. Il existe une bonne et une mauvaise relation. Une base de données peut non seulement faire de la mise en cache, mais aussi faire d'autres choses. L'une n'est utilisée que pour la mise en cache. Redis est souvent utilisé comme cache, c'est la principale raison pour laquelle nous le comparons souvent à d'autres technologies. Alors, que peut faire Redis ? Qu'est-ce que tu ne peux pas faire ?
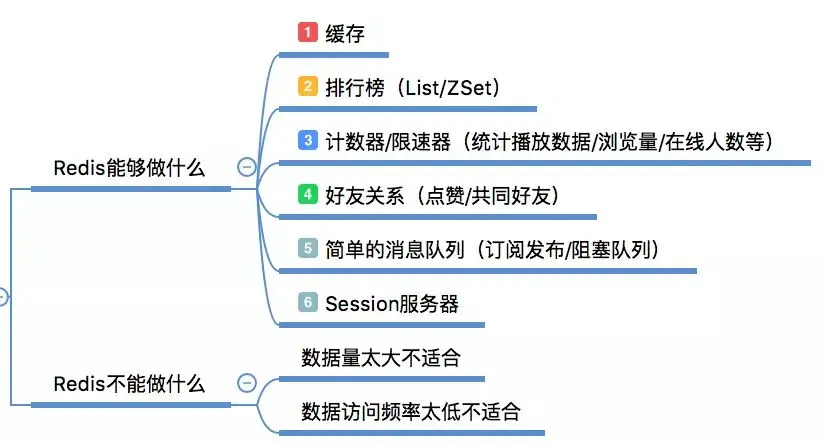
Redis peut tout faire
mettre en cache Il ne fait aucun doute qu'il s'agit du scénario d'utilisation le plus connu de Redis aujourd'hui. C'est très efficace pour améliorer les performances du serveur ;
Liste de classement. Si vous utilisez une base de données relationnelle traditionnelle pour ce faire, ce sera très gênant, mais utiliser la structure de données SortSet de Redis peut être très pratique ; , en utilisant l'opération d'auto-incrémentation atomique dans Redis, nous pouvons compter le nombre de likes d'utilisateurs, de visites d'utilisateurs, etc. Si MySQL est utilisé pour de telles opérations, une lecture et une écriture fréquentes exerceront une pression considérable sur le limiteur de vitesse, ce qui est plus typique. Le scénario consiste à limiter la fréquence d'accès d'un utilisateur à une certaine API. Les API couramment utilisées incluent les achats de panique pour éviter la pression inutile des clics fous des utilisateurs.
Relations amicales, en utilisant certaines commandes de la collection, telles que l'intersection, l'union, la différence ; Définir etc. Il peut facilement gérer des fonctions telles que les amis communs et les passe-temps communs ;
File d'attente de messages simple, en plus du mode de publication/abonnement de Redis, nous pouvons également utiliser List pour implémenter un mécanisme de file d'attente, tel que : notification d'arrivée, envoi d'e-mails, etc. . La demande ne nécessite pas une grande fiabilité, mais cela entraînera beaucoup de pression sur la base de données. La liste peut être utilisée pour compléter le découplage asynchrone.
Partage de session, en prenant PHP comme exemple, la session par défaut est enregistrée dans le fichier du serveur ; Pour les services de cluster, le même utilisateur peut atterrir sur différentes machines, ce qui obligera les utilisateurs à se connecter fréquemment. Après avoir utilisé Redis pour enregistrer la session, les informations de session correspondantes peuvent être obtenues quelle que soit la machine sur laquelle l'utilisateur atterrit.
Ce que Redis ne peut pas faire
Bien que Redis soit riche en fonctions, il n'est pas tout-puissant, il est adapté à ses domaines spécifiques et peut obtenir le double du résultat avec la moitié de l'effort. En cas d'abus, cela peut entraîner une instabilité du système, une augmentation des coûts et d'autres problèmes.
Par exemple, Redis est utilisé pour enregistrer les informations utilisateur de base. Bien qu'il puisse prendre en charge la persistance, sa solution de persistance ne peut pas garantir l'atterrissage absolu des données et peut également entraîner une diminution des performances de Redis, car la persistance augmentera trop fréquemment. sur le service Redis.
Un résumé simple est que les entreprises avec des quantités de données trop importantes et une fréquence d'accès aux données très faible ne sont pas adaptées à l'utilisation de Redis. Des données trop volumineuses augmenteront les coûts et la fréquence d'accès est trop faible. ressources.
 Vous devez toujours trouver une raison pour votre choix
Vous devez toujours trouver une raison pour votre choix
Certains scénarios d'utilisation de Redis sont mentionnés ci-dessus. Il existe donc de nombreuses autres options pour résoudre ces scénarios, telles que la mise en cache à l'aide de Memcache, le partage de session à l'aide de MySql et files d'attente de messages Vous pouvez utiliser RabbitMQ, pourquoi devons-nous utiliser Redis ?
Vitesse rapide, entièrement basée sur la mémoire, implémentée en langage C, la couche réseau utilise epoll pour résoudre les problèmes de concurrence élevée, le modèle monothread évite les changements de contexte inutiles et les conditions de concurrence. Remarque : le monothread fait uniquement référence à la requête réseau ; module Utilisez une requête pour traiter la requête du client. Comme la persistance, il rouvrira un thread/processus pour le traitement
Types de données riches. Bien sûr, les types de données couramment utilisés sont String, Hash, List et Set. , SortSet, ces 5 types, ils organisent tous les données en fonction de la valeur clé. Chaque type de données fournit un ensemble très riche de commandes d'opération, qui peuvent répondre à la plupart des besoins, vous pouvez également créer vous-même de nouvelles commandes via des scripts Lua (avec atomicité)
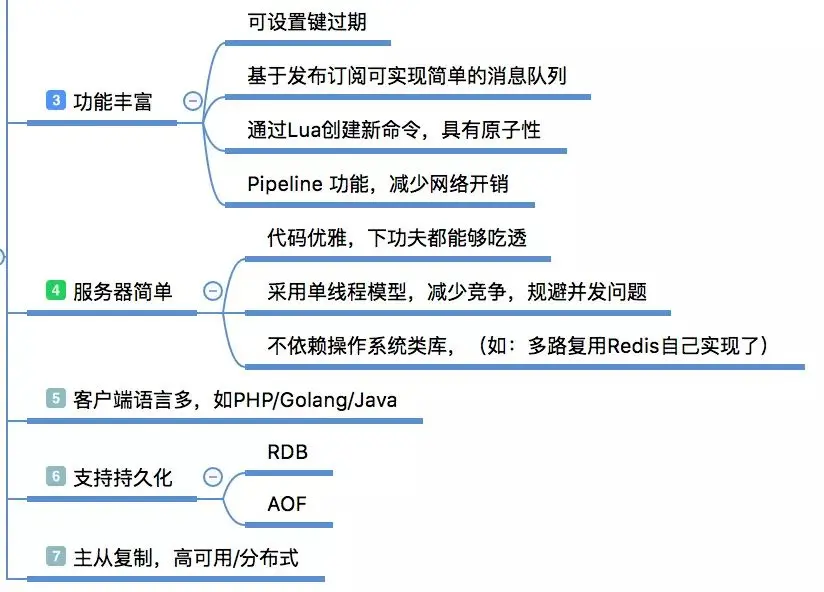
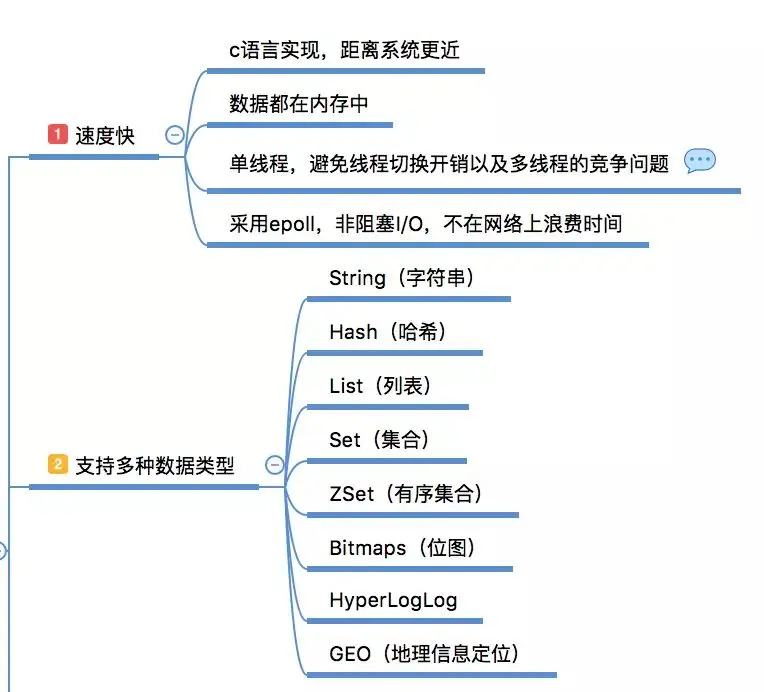 En plus des riches fournies. Types de données, Redis fournit également des fonctions personnalisées telles que l'analyse de requêtes lentes, les tests de performances, le pipeline, les transactions, les commandes personnalisées Lua, les Bitmaps, HyperLogLog, la publication/abonnement, Geo, etc.
En plus des riches fournies. Types de données, Redis fournit également des fonctions personnalisées telles que l'analyse de requêtes lentes, les tests de performances, le pipeline, les transactions, les commandes personnalisées Lua, les Bitmaps, HyperLogLog, la publication/abonnement, Geo, etc.
Le code de Redis est open source sur GitHub. Le code est très simple et élégant, et tout le monde peut comprendre son code source ; sa compilation et son installation sont également très simples, sans aucune dépendance système ; support linguistique du client Il est également très complet. De plus, il prend également en charge les transactions (pas encore essayées), la persistance, la réplication maître-esclave et d'autres fonctions, réalisant la faisabilité d'une haute disponibilité et d'un traitement distribué.
En tant que développeur, les choses que nous utilisons ne peuvent pas devenir une boîte noire. Nous devrions l'approfondir et devenir plus compréhensifs et familiers avec elle.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Redis, en tant que Message Middleware, prend en charge les modèles de consommation de production, peut persister des messages et assurer une livraison fiable. L'utilisation de Redis comme Message Middleware permet une faible latence, une messagerie fiable et évolutive.
 Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Les étapes pour démarrer un serveur Redis incluent: Installez Redis en fonction du système d'exploitation. Démarrez le service Redis via Redis-Server (Linux / MacOS) ou Redis-Server.exe (Windows). Utilisez la commande redis-Cli Ping (Linux / MacOS) ou redis-Cli.exe Ping (Windows) pour vérifier l'état du service. Utilisez un client redis, tel que redis-cli, python ou node.js pour accéder au serveur.
