

La séparation lecture-écriture des bases de données MySQL est l'une des méthodes courantes pour améliorer la qualité du service. En ce qui concerne les solutions techniques, il existe de nombreux frameworks ou solutions open source matures, tels que : sharding-jdbc, AbstractRoutingDatasource au printemps, MySQL-Router. , etc., et ReplicationConnection dans mysql-jdbc est également pris en charge.
Cet article ne fera pas trop d'analyse sur la sélection technique de la séparation lecture-écriture. Il explore uniquement les raisons de l'échec de la connexion lors de l'utilisation de Druid comme source de données et combiné avec ReplicationConnection pour la séparation lecture-écriture, et trouve une méthode simple et efficace. solution efficace.
Pour des raisons historiques, certains services ont connu des exceptions d'échec de connexion. Les principaux rapports d'erreurs sont les suivants :

On peut déduire du journal que cela est dû au fait que la connexion n'a pas interagi avec MySQL. serveur pendant une longue période, ce qui entraîne la fermeture de la connexion par le serveur, une situation typique d'échec de connexion.
configuration jdbc
jdbc:mysql:replication://master_host:port,slave_host:port/database_name
configuration druid
testWhileIdle=true (c.-à-d. allumé Vérification de la connexion inactive );
timeBetweenEvictionRunsMillis=6000L (c'est-à-dire que pour le scénario d'obtention d'une connexion, si une connexion est inactive pendant plus d'une minute, elle sera vérifiée, et si la connexion est invalide, elle sera rejetée et réacquis).
Pièce jointe : La
logique de traitement dans DruidDataSource.getConnectionDirect est la suivante :
if (testWhileIdle) {
final DruidConnectionHolder holder = poolableConnection.holder;
long currentTimeMillis = System.currentTimeMillis();
long lastActiveTimeMillis = holder.lastActiveTimeMillis;
long lastExecTimeMillis = holder.lastExecTimeMillis;
long lastKeepTimeMillis = holder.lastKeepTimeMillis;
if (checkExecuteTime
&& lastExecTimeMillis != lastActiveTimeMillis) {
lastActiveTimeMillis = lastExecTimeMillis;
}
if (lastKeepTimeMillis > lastActiveTimeMillis) {
lastActiveTimeMillis = lastKeepTimeMillis;
}
long idleMillis = currentTimeMillis - lastActiveTimeMillis;
long timeBetweenEvictionRunsMillis = this.timeBetweenEvictionRunsMillis;
if (timeBetweenEvictionRunsMillis <= 0) {
timeBetweenEvictionRunsMillis = DEFAULT_TIME_BETWEEN_EVICTION_RUNS_MILLIS;
}
if (idleMillis >= timeBetweenEvictionRunsMillis
|| idleMillis < 0 // unexcepted branch
) {
boolean validate = testConnectionInternal(poolableConnection.holder, poolableConnection.conn);
if (!validate) {
if (LOG.isDebugEnabled()) {
LOG.debug("skip not validate connection.");
}
discardConnection(poolableConnection.holder);
continue;
}
}
}configuration du paramètre de délai d'attente mysqlwait_timeout=3600 (3600 secondes, c'est-à-dire : si une connexion n'a pas interagi avec le serveur pendant plus d'un heure, la connexion sera Server kill). Évidemment, sur la base de la configuration ci-dessus, selon la compréhension conventionnelle, le problème « Le dernier paquet reçu avec succès du serveur remonte à xxx,xxx,xxx millisecondes » ne devrait pas se produire. (Bien entendu, la possibilité d’une intervention manuelle pour couper la connexion à la base de données était également exclue à cette époque).
Lorsque l’expérience « supposée » ne peut expliquer le problème, il est souvent nécessaire de sortir des contraintes de l’expérience superficielle et d’aller au fond des choses. Alors, quelle est la véritable cause de ce problème ?
Lorsque druid est utilisé pour gérer les sources de données et combiné avec la ReplicationConnection native dans mysql-jdbc pour la séparation en lecture-écriture, il existe en fait deux ensembles de connexions, maître et esclaves, dans l'objet proxy ReplicationConnection lorsque druid. effectue une détection de connexion, il ne peut détecter que Pour se connecter au maître, si une connexion esclave n'est pas utilisée pendant une longue période, cela provoquera un problème d'échec de connexion.
Combiné avec le code source com.mysql.jdbc.Driver, il n'est pas difficile de voir que le processus principal d'obtention d'une connexion dans mysql-jdbc est la suivante :

Pour l'url jdbc configurée commençant par "jdbc:mysql:replication://", la connexion obtenue via mysql-jdbc, est en fait un objet proxy de ReplicationConnection par défaut, après "jdbc. :mysql:replication://" Le premier hôte et le premier port correspondent à la connexion maître, et les hôtes et ports suivants correspondent aux connexions esclaves. Pour les scénarios où il existe plusieurs configurations esclaves, la politique aléatoire est utilisée par défaut pour l'équilibrage de charge. .
L'objet proxy ReplicationConnection est généré à l'aide du proxy dynamique JDK. L'implémentation spécifique d'InvocationHandler est ReplicationConnectionProxy. Le code clé est le suivant :
public static ReplicationConnection createProxyInstance(List<String> masterHostList, Properties masterProperties, List<String> slaveHostList,
Properties slaveProperties) throws SQLException {
ReplicationConnectionProxy connProxy = new ReplicationConnectionProxy(masterHostList, masterProperties, slaveHostList, slaveProperties);
return (ReplicationConnection) java.lang.reflect.Proxy.newProxyInstance(ReplicationConnection.class.getClassLoader(), INTERFACES_TO_PROXY, connProxy);
}À propos du proxy de connexion à la base de données, les principaux composants de ReplicationConnectionProxy sont les suivants. :
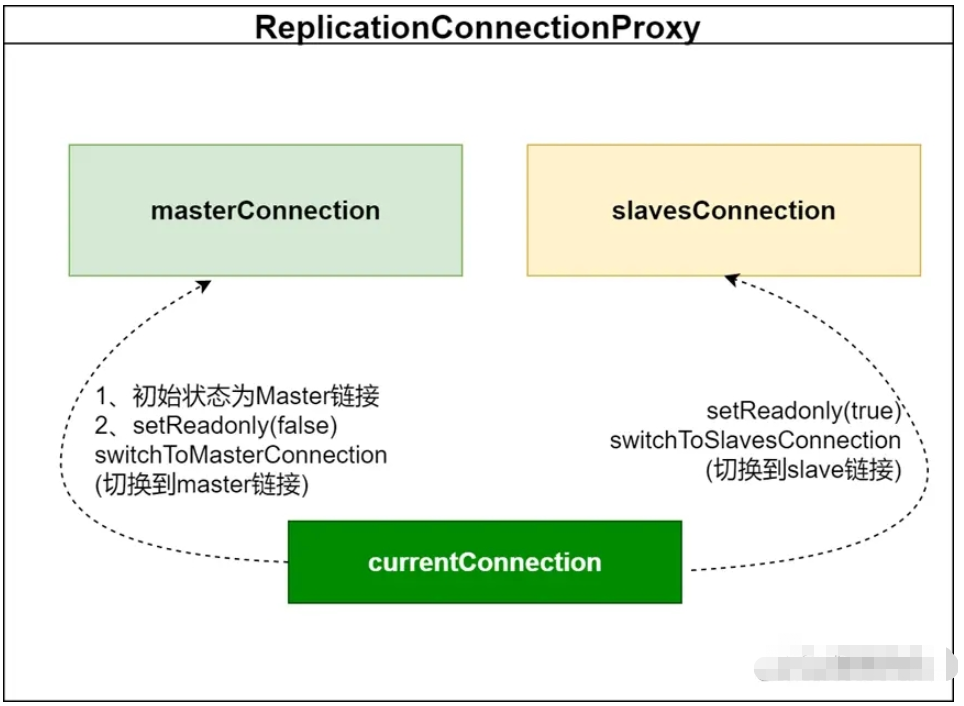
ReplicationConnectionProxy a deux objets de connexion réels : masterConnection et slavesConnection. currentConnection (connexion actuelle) peut être commuté sur masterConnection ou slavesConnection. La méthode de commutation peut être obtenue en définissant readOnly.
Dans la logique métier, le cœur de la réalisation de la séparation lecture-écriture est également là. Pour le dire simplement : lorsque vous utilisez ReplicationConnection pour la séparation lecture-écriture, il vous suffit de faire un aop qui "définit l'attribut readOnly de la connexion".
Basé sur ReplicationConnectionProxy, l'objet proxy de connexion obtenu dans la logique métier, quelle est la logique principale lors de l'accès à la base de données ?
Pour la logique métier, l'instance de connexion obtenue est un objet proxy ReplicationConnection. Cet objet proxy coopère entre eux via ReplicationConnectionProxy et ReplicationMySQLConnection pour terminer le traitement de l'accès à la base de données en même temps. Il joue également le rôle de gestion des connexions. La logique de base est la suivante :
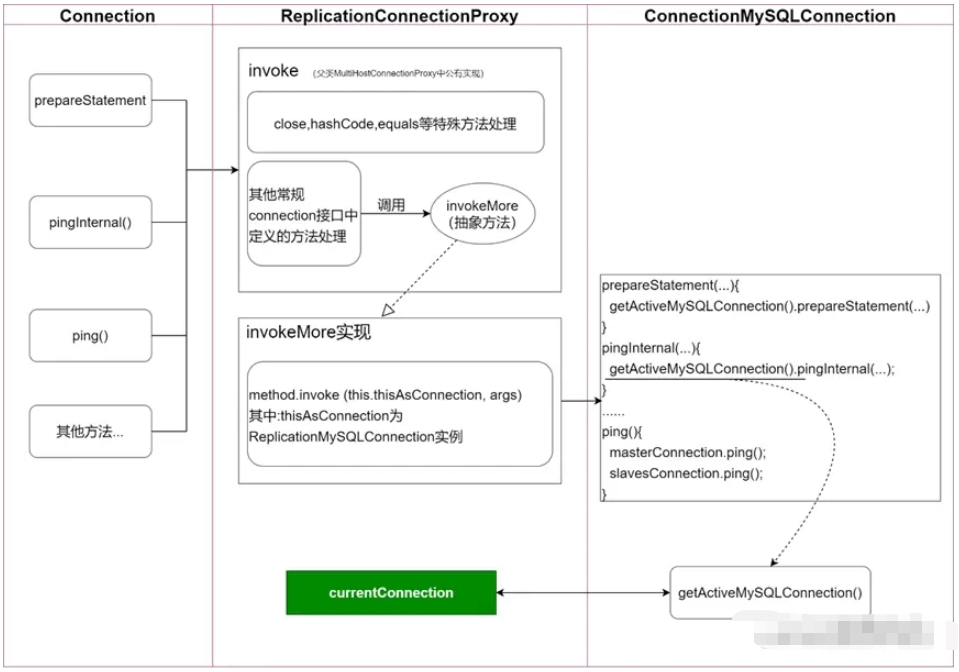
对于prepareStatement等常规逻辑,ConnectionMySQConnection获取到当前连接进行处理(普通的读写分离的处理的重点正是在此);此时,重点提及pingInternal方法,其处理方式也是获取当前连接,然后执行pingInternal逻辑。
对于ping()这个特殊逻辑,图中描述相对简单,但主体含义不变,即:对master连接和sleves连接都要进行ping()的处理。
图中,pingInternal流程和druid的MySQ连接检查有关,而ping的特殊处理,也正是解决问题的关键。
druid中对MySQL连接检查的默认实现类是MySqlValidConnectionChecker,其中核心逻辑如下:
public boolean isValidConnection(Connection conn, String validateQuery, int validationQueryTimeout) throws Exception {
if (conn.isClosed()) {
return false;
}
if (usePingMethod) {
if (conn instanceof DruidPooledConnection) {
conn = ((DruidPooledConnection) conn).getConnection();
}
if (conn instanceof ConnectionProxy) {
conn = ((ConnectionProxy) conn).getRawObject();
}
if (clazz.isAssignableFrom(conn.getClass())) {
if (validationQueryTimeout <= 0) {
validationQueryTimeout = DEFAULT_VALIDATION_QUERY_TIMEOUT;
}
try {
ping.invoke(conn, true, validationQueryTimeout * 1000);
} catch (InvocationTargetException e) {
Throwable cause = e.getCause();
if (cause instanceof SQLException) {
throw (SQLException) cause;
}
throw e;
}
return true;
}
}
String query = validateQuery;
if (validateQuery == null || validateQuery.isEmpty()) {
query = DEFAULT_VALIDATION_QUERY;
}
Statement stmt = null;
ResultSet rs = null;
try {
stmt = conn.createStatement();
if (validationQueryTimeout > 0) {
stmt.setQueryTimeout(validationQueryTimeout);
}
rs = stmt.executeQuery(query);
return true;
} finally {
JdbcUtils.close(rs);
JdbcUtils.close(stmt);
}
}对应服务中使用的mysql-jdbc(5.1.45版),在未设置“druid.mysql.usePingMethod”系统属性的情况下,默认usePingMethod为true,如下:
public MySqlValidConnectionChecker(){
try {
clazz = Utils.loadClass("com.mysql.jdbc.MySQLConnection");
if (clazz == null) {
clazz = Utils.loadClass("com.mysql.cj.jdbc.ConnectionImpl");
}
if (clazz != null) {
ping = clazz.getMethod("pingInternal", boolean.class, int.class);
}
if (ping != null) {
usePingMethod = true;
}
} catch (Exception e) {
LOG.warn("Cannot resolve com.mysql.jdbc.Connection.ping method. Will use 'SELECT 1' instead.", e);
}
configFromProperties(System.getProperties());
}
@Override
public void configFromProperties(Properties properties) {
String property = properties.getProperty("druid.mysql.usePingMethod");
if ("true".equals(property)) {
setUsePingMethod(true);
} else if ("false".equals(property)) {
setUsePingMethod(false);
}
}同时,可以看出MySqlValidConnectionChecker中的ping方法使用的是MySQLConnection中的pingInternal方法,而该方法,结合上面对ReplicationConnection的分析,当调用pingInternal时,只是对当前连接进行检验。执行检验连接的时机是通过DrduiDatasource获取连接时,此时未设置readOnly属性,检查的连接,其实只是ReplicationConnectionProxy中的master连接。
此外,如果通过“druid.mysql.usePingMethod”属性设置usePingMeghod为false,其实也会导致连接失效的问题,因为:当通过valideQuery(例如“select 1”)进行连接校验时,会走到ReplicationConnection中的普通查询逻辑,此时对应的连接依然是master连接。
题外一问:ping方法为什么使用“pingInternal”,而不是常规的ping?
原因:pingInternal预留了超时时间等控制参数。
在服务中,使用的MySQL JDBC版本是5.1.45,并且使用的Druid版本是1.1.20。经过对其他高版本依赖的了解,依然存在该问题。
修改的工作量主要在于数据源配置和aop调整,但需要一定的整体回归验证成本,鉴于涉及该问题的服务重要性一般,暂不做大调整。
基于原有ReplicationConnection的功能,拓展pingInternal调整为普通的ping,集成原有Driver拓展新的Driver。方案可行,但修改成本不算小。
为简单高效解决问题,选择拓展MySqlValidConnectionChecker,并在druid数据源中加上对应配置即可。拓展如下:
public class MySqlReplicationCompatibleValidConnectionChecker extends MySqlValidConnectionChecker {
private static final Log LOG = LogFactory.getLog(MySqlValidConnectionChecker.class);
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public boolean isValidConnection(Connection conn, String validateQuery, int validationQueryTimeout) throws Exception {
if (conn.isClosed()) {
return false;
}
if (conn instanceof DruidPooledConnection) {
conn = ((DruidPooledConnection) conn).getConnection();
}
if (conn instanceof ConnectionProxy) {
conn = ((ConnectionProxy) conn).getRawObject();
}
if (conn instanceof ReplicationConnection) {
try {
((ReplicationConnection) conn).ping();
LOG.info("validate connection success: connection=" + conn.toString());
return true;
} catch (SQLException e) {
LOG.error("validate connection error: connection=" + conn.toString(), e);
throw e;
}
}
return super.isValidConnection(conn, validateQuery, validationQueryTimeout);
}
}ReplicatoinConnection.ping()的实现逻辑中,会对所有master和slaves连接进行ping操作,最终每个ping操作都会调用到LoadBalancedConnectionProxy.doPing进行处理,而此处,可在数据库配置url中设置loadBalancePingTimeout属性设置超时时间。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



