

Comment optimiser les instructions SQL dans MySQL

1. Présentation
Pendant le processus de développement du système d'application, en raison de la petite quantité initiale de données, les développeurs accordent plus d'attention à la mise en œuvre fonctionnelle lors de l'écriture des instructions SQL. officiellement lancé, avec l'augmentation rapide de la quantité de données de production, de nombreuses instructions SQL ont progressivement commencé à présenter des problèmes de performances, et leur impact sur l'environnement de production est devenu de plus en plus grand. À cette époque, ces instructions SQL problématiques sont devenues un goulot d'étranglement. de l'ensemble des performances du système, nous devons donc nous en occuper. Ils sont optimisés.
2. Comprenez la fréquence d'exécution de divers SQL via la commande show status
Une fois le client MySQL connecté, les informations sur l'état du serveur peuvent être fournies via la session show |global]status , ces messages peuvent également être obtenus à l'aide de la commande mysqladmin extended-status sur le système d'exploitation. show [session|global] status peut ajouter le paramètre "session" ou "global" selon les besoins pour afficher les résultats statistiques au niveau de la session (connexion actuelle) et les résultats statistiques au niveau global (depuis le dernier démarrage de la base de données ). S'il n'est pas écrit, le paramètre par défaut est "session".
La commande suivante affiche les valeurs de tous les paramètres statistiques de la session en cours :
-- 查看会话所有统计的值 SHOW STATUS LIKE 'Com_%'; Or SHOW SESSION STATUS LIKE 'Com_%';
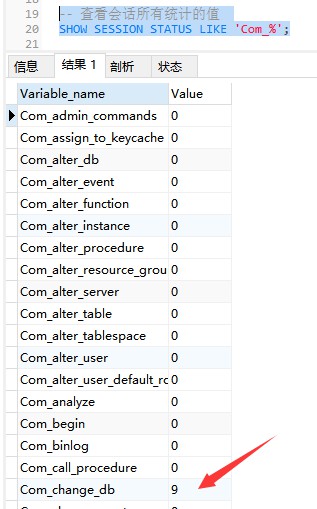
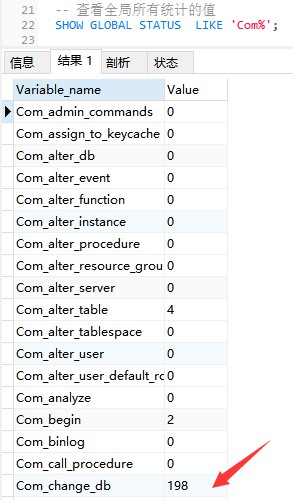
La commande suivante affiche le global actuel Les valeurs de tous les paramètres statistiques dans :
--Afficher les valeurs de toutes les statistiques globales
SHOW GLOBAL STATUS LIKE 'Com_%';
- Com_select : Le nombre de fois que l'opération SELECT est exécutée, un seul est accumulé pour une requête.
- Com_insert : Le nombre de fois où effectuer des opérations INSERT pour les opérations INSERT d'insertion par lots, il n'est accumulé qu'une seule fois.
- Com_update : Le nombre d'opérations de MISE À JOUR effectuées.
- Com_delete : Le nombre d'opérations DELETE effectuées.
- Innodb_rows_read : Le nombre de lignes renvoyées par la requête SELECT.
- Innodb_rows_inserted : Le nombre de lignes insérées par l'opération INSERT.
- Innodb_rows_updated : Le nombre de lignes mises à jour par l'opération UPDATE.
- Innodb_rows_deleted : Le nombre de lignes supprimées par l'opération DELETE.
- Connections : Le nombre de tentatives de connexion au serveur MySQL.
- Uptime : Temps de travail du serveur.
- Slow_queries : Le nombre de requêtes lentes.
- Localisez les instructions SQL avec une faible efficacité d'exécution via le journal des requêtes lentes. Lors du démarrage avec l'option --log-slow-queries[=file_name], mysqld écrit un. message contenant le fichier journal de toutes les instructions SQL dont l'exécution a pris plus de long_query_time secondes.
- Le journal des requêtes lentes est enregistré une fois la requête terminée, donc lorsque le système d'application reflète des problèmes d'efficacité d'exécution, l'interrogation du journal des requêtes lentes ne peut pas localiser le problème. utiliser show processlist La commande est utilisée pour afficher les threads MySQL actuels, y compris l'état du thread, s'il faut verrouiller la table, etc. Vous pouvez visualiser l'exécution de SQL en temps réel et optimiser certaines opérations de verrouillage de table.
EXPLAIN SELECT SUM(sp.Qty) FROM goods_stock AS s LEFT JOIN goods_stock_price AS sp ON s.ID=sp.GoodsStockID;
#🎜. 🎜# Comme le montre la figure ci-dessus, l'explication simple de chaque colonne est la suivante :
Comme le montre la figure ci-dessus, l'explication simple de chaque colonne est la suivante :
- select_type : Indique le type de SELECT valeurs communes . sont :
- PRIMARY (requête principale, c'est-à-dire la requête externe), UNION (la deuxième instruction de requête ou suivante dans UNION), ◎SUBQUERY (première sous-requête SELECT) etc.
type:表示表的连接类型,性能由好到差的连接类型为:
system(表中仅有一行,即常量表)。
const(单表中最多有一个匹配行,例如primary key或者unique index)。
eq_ref(对于前面的每一行,在此表中只查询一条记录,简单来说,就是多表连接中使用primary key或者unique index)。
ref(与eq_ref类似,区别在于不是使用primary key或者unique index,而是使用普通的索引)。
ref_or_null(与ref类似,区别在于条件中包含对NULL的查询)。
index_merge(索引合并优化)。
unique_subquery(in的后面是一个查询主键字段的子查询)。
index_subquery(与unique_subquery类似,区别在于in的后面是查询非唯一索引字段的子查询)。
range(单表中的范围查询)。
index(对于前面的每一行,都通过查询索引来得到数据)。
all(对于前面的每一行,都通过全表扫描来得到数据)。
possible_keys:表示查询时,可能使用的索引。
key:表示实际使用的索引。
key_len:索引字段的长度。
rows:扫描行的数量。
filtered:返回结果的行占需要读到的行(rows列的值)的百分比。
Extra:执行情况的说明和描述。
Using index(此值表示mysql将使用覆盖索引,以避免访问表)。
Using where(mysql 将在存储引擎检索行后再进行过滤,许多where条件里涉及索引中的列,当(并且如果)它读取索引时,就能被存储引擎检验,因此不是所有带where子句的查询都会显示“Using where”。“Using where”有时提示了一种可能性:查询可以从不同的索引中受益。
Using temporary(mysql 对查询结果排序时会使用临时表)。
MySQL will apply an external index sorting on the results instead of reading rows from the table in index order.。mysql有两种文件排序算法,这两种排序方式都可以在内存或者磁盘上完成,explain不会告诉你mysql将使用哪一种文件排序,也不会告诉你排序会在内存里还是磁盘上完成)。
Range checked for each record(index map: N) (没有好用的索引,新的索引将在联接的每一行上重新估算,N是显示在possible_keys列中索引的位图,并且是冗余的)。
- SIMPLE (table simple, c'est-à-dire sans utiliser de jointures de table ni de sous-requêtes).
5.确定问题并采取相应的优化措施
经过以上定位步骤,我们基本就可以分析到问题出现的原因。此时我们可以根据情况采取相应的改进措施,进行优化提高语句执行效率。
在上面的例子中,已经可以确认是goods_stock是走主键索引的,但是对goods_stock_price子表的进行了全表扫描导致效率的不理想,那么应该对goods_stock_price表的GoodsStockID字段创建索引,具体命令如下:
-- 创建索引 CREATE INDEX idx_stock_price_1 ON goods_stock_price (GoodsStockID); -- 附加删除跟查询索引语句 ALTER TABLE goods_stock_price DROP INDEX idx_stock_price_1; SHOW INDEX FROM goods_stock_price;
创建索引后,我们再看一下这条语句的执行计划,具体如下:
EXPLAIN SELECT SUM(sp.Qty) FROM goods_stock AS s LEFT JOIN goods_stock_price AS sp ON s.ID=sp.GoodsStockID;

可以发现建立索引后对goods_stock_price子表需要扫描的行数明显减少(从 3 行减少到1行),可见索引的使用可以大大提高数据库的访问速度,尤其在表很庞大的时候这种优势更为明显。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Le rôle principal de MySQL dans les applications Web est de stocker et de gérer les données. 1.MySQL traite efficacement les informations utilisateur, les catalogues de produits, les enregistrements de transaction et autres données. 2. Grâce à SQL Query, les développeurs peuvent extraire des informations de la base de données pour générer du contenu dynamique. 3.MySQL fonctionne basé sur le modèle client-serveur pour assurer une vitesse de requête acceptable.
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Exemple d'introduction de Laravel
Apr 18, 2025 pm 12:45 PM
Exemple d'introduction de Laravel
Apr 18, 2025 pm 12:45 PM
Laravel est un cadre PHP pour la création facile des applications Web. Il fournit une gamme de fonctionnalités puissantes, notamment: Installation: Installez le Laravel CLI globalement avec Composer et créez des applications dans le répertoire du projet. Routage: définissez la relation entre l'URL et le gestionnaire dans Routes / web.php. Voir: Créez une vue dans les ressources / vues pour rendre l'interface de l'application. Intégration de la base de données: fournit une intégration prête à l'emploi avec des bases de données telles que MySQL et utilise la migration pour créer et modifier des tables. Modèle et contrôleur: le modèle représente l'entité de la base de données et le contrôleur traite les demandes HTTP.
