
 Périphériques technologiques
IA
AI Morning Post | Quelle est l'expérience de la génération mutuelle de texte, d'image, d'audio, de vidéo et de 3D ?
Périphériques technologiques
IA
AI Morning Post | Quelle est l'expérience de la génération mutuelle de texte, d'image, d'audio, de vidéo et de 3D ?
AI Morning Post | Quelle est l'expérience de la génération mutuelle de texte, d'image, d'audio, de vidéo et de 3D ?


Le 9 mai, heure locale, Meta a annoncé l'open source d'un nouveau modèle d'IA ImageBind qui peut couvrir 6 modalités différentes, notamment la vision (formes d'image et vidéo), la température (image infrarouge), le texte, l'audio et la profondeur. Informations, mouvement lectures (produites par une centrale inertielle ou IMU). Actuellement, le code source correspondant est hébergé sur GitHub.
Que signifie couvrir 6 modes ?
ImageBind prend la vision comme élément central et peut librement comprendre et convertir entre 6 modes. Meta a montré certains cas, comme entendre un chien aboyer et dessiner un chien, et donner en même temps la carte de profondeur correspondante et la description textuelle, comme saisir une image d'un oiseau + le bruit des vagues de l'océan et obtenir une image de ; un oiseau sur la plage.
Comparé aux générateurs d'images comme Midjourney, Stable Diffusion et DALL-E 2 qui associent du texte à des images, ImageBind ressemble davantage à un large réseau et peut connecter du texte, des images/vidéos, de l'audio, des mesures 3D (profondeur), des données de température (chaleur ) et les données de mouvement (de l'IMU), et il prédit directement les connexions entre les données sans formation préalable à chaque possibilité, de la même manière que les humains perçoivent ou imaginent leur environnement.

Les chercheurs affirment qu'ImageBind peut être initialisé à l'aide de modèles de langage visuel à grande échelle (tels que CLIP), exploitant ainsi les riches représentations d'images et de texte de ces modèles. Par conséquent, ImageBind peut être adapté à différentes modalités et tâches avec très peu de formation.
ImageBind fait partie de l'engagement de Meta à créer des systèmes d'IA multimodaux qui apprennent de tous les types de données pertinents. À mesure que le nombre de modalités augmente, ImageBind ouvre les vannes aux chercheurs pour tenter de développer de nouveaux systèmes holistiques, tels que la combinaison de capteurs 3D et IMU pour concevoir ou expérimenter des mondes virtuels immersifs. Il offre également un moyen riche d'explorer votre mémoire en utilisant une combinaison de texte, de vidéo et d'images pour rechercher des images, des vidéos, des fichiers audio ou des informations textuelles.
Ce modèle n'est actuellement qu'un projet de recherche et n'a pas d'application directe ni d'application pratique, mais il montre comment l'IA générative peut générer du contenu immersif et multisensoriel à l'avenir, et montre également que Meta travaille avec OpenAI, Google Wait pour que les concurrents adoptent des méthodes différentes et trouvent une voie qui appartient au grand modèle open source.
En fin de compte, Meta estime que la technologie ImageBind finira par transcender les six « sens » actuels, déclarant sur son blog : « Bien que nous ayons exploré six modes dans nos recherches actuelles, nous croyons en l'introduction d'une technologie qui connecte autant de sens que possible. – tels que le toucher, la parole, l’odorat et les signaux IRMf cérébraux – permettront des modèles d’IA plus riches centrés sur l’humain
.Objectif d'ImageBind
Si ChatGPT peut servir de moteur de recherche et de communauté de questions-réponses, et que Midjourney peut être utilisé comme outil de dessin, que pouvez-vous faire avec ImageBind ?
Selon la démo officielle, il peut générer de l'audio directement à partir d'images :
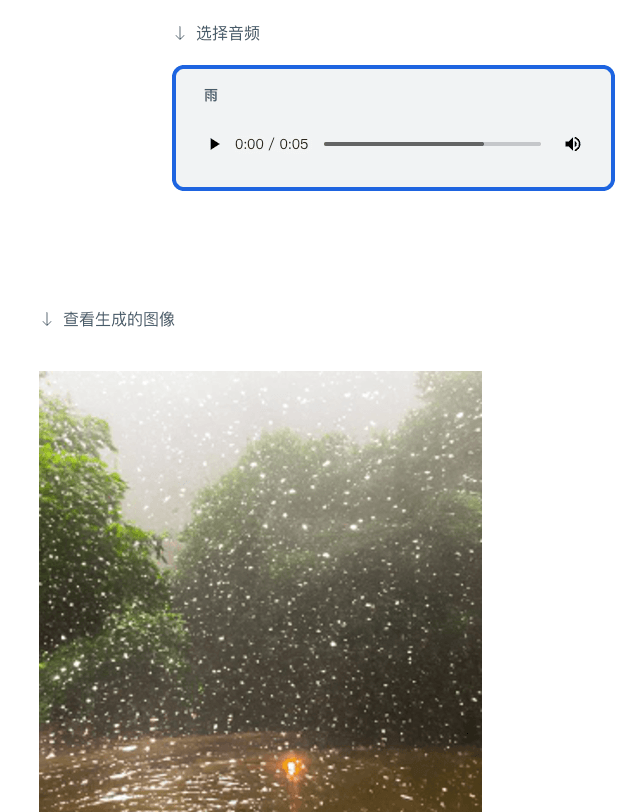
Vous pouvez également générer des images à partir de l'audio :
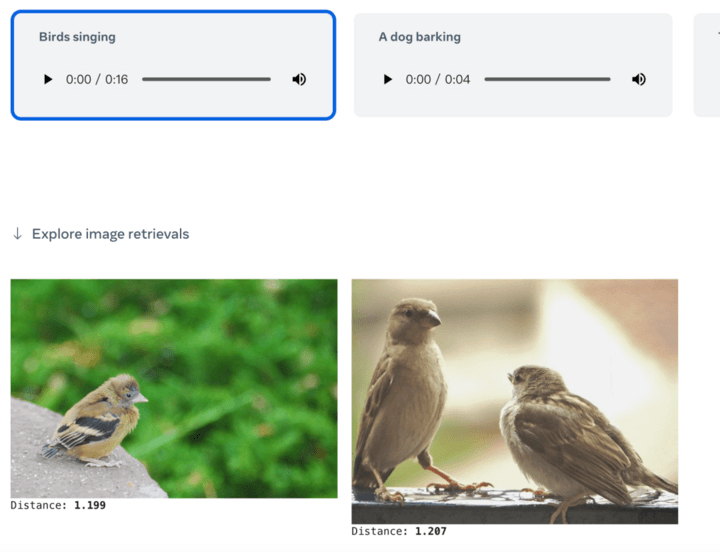
Ou donnez simplement un texte pour récupérer des images ou du contenu audio associé :
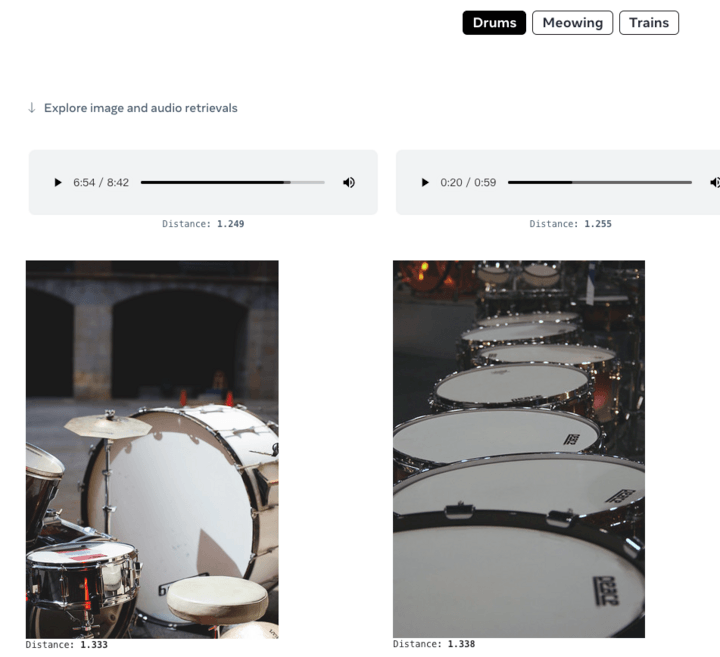
Vous pouvez également donner de l'audio et générer des images correspondantes :
Comme mentionné ci-dessus, ImageBind permet aux futurs systèmes d'IA générative d'être présentés sous plusieurs modalités, et en même temps, combinés avec la réalité virtuelle interne de Meta, la réalité mixte, le métaverse et d'autres technologies et scénarios. L'utilisation d'outils comme ImageBind ouvrira de nouvelles portes dans les espaces accessibles, par exemple en générant des descriptions multimédias en temps réel pour aider les personnes malvoyantes ou malentendantes à mieux percevoir leur environnement immédiat.
Il reste encore beaucoup à découvrir sur l’apprentissage multimodal. Actuellement, le domaine de l’intelligence artificielle n’a pas quantifié efficacement les comportements de mise à l’échelle qui n’apparaissent que dans des modèles plus grands ni compris leurs applications. ImageBind est une étape vers l'évaluation et la démonstration de nouvelles applications pour la génération et la récupération d'images de manière rigoureuse.
Auteur : Ballade
Source : Premier Réseau Électrique (www.d1ev.com)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 J'ai essayé le codage d'ambiance avec Cursor Ai et c'est incroyable!
Mar 20, 2025 pm 03:34 PM
J'ai essayé le codage d'ambiance avec Cursor Ai et c'est incroyable!
Mar 20, 2025 pm 03:34 PM
Le codage des ambiances est de remodeler le monde du développement de logiciels en nous permettant de créer des applications en utilisant le langage naturel au lieu de lignes de code sans fin. Inspirée par des visionnaires comme Andrej Karpathy, cette approche innovante permet de dev
 Comment utiliser Dall-E 3: Conseils, exemples et fonctionnalités
Mar 09, 2025 pm 01:00 PM
Comment utiliser Dall-E 3: Conseils, exemples et fonctionnalités
Mar 09, 2025 pm 01:00 PM
Dall-E 3: Un outil de création d'images génératifs AI L'IA générative révolutionne la création de contenu, et Dall-E 3, le dernier modèle de génération d'images d'Openai, est à l'avant. Sorti en octobre 2023, il s'appuie sur ses prédécesseurs, Dall-E et Dall-E 2
 Top 5 Genai Lunets de février 2025: GPT-4.5, Grok-3 et plus!
Mar 22, 2025 am 10:58 AM
Top 5 Genai Lunets de février 2025: GPT-4.5, Grok-3 et plus!
Mar 22, 2025 am 10:58 AM
Février 2025 a été un autre mois qui change la donne pour une IA générative, nous apportant certaines des mises à niveau des modèles les plus attendues et de nouvelles fonctionnalités révolutionnaires. De Xai's Grok 3 et Anthropic's Claude 3.7 Sonnet, à Openai's G
 Comment utiliser YOLO V12 pour la détection d'objets?
Mar 22, 2025 am 11:07 AM
Comment utiliser YOLO V12 pour la détection d'objets?
Mar 22, 2025 am 11:07 AM
Yolo (vous ne regardez qu'une seule fois) a été un cadre de détection d'objets en temps réel de premier plan, chaque itération améliorant les versions précédentes. La dernière version Yolo V12 introduit des progrès qui améliorent considérablement la précision
 Elon Musk et Sam Altman s'affrontent plus de 500 milliards de dollars Stargate Project
Mar 08, 2025 am 11:15 AM
Elon Musk et Sam Altman s'affrontent plus de 500 milliards de dollars Stargate Project
Mar 08, 2025 am 11:15 AM
Le projet de 500 milliards de dollars Stargate IA, soutenu par des géants de la technologie comme Openai, Softbank, Oracle et Nvidia, et soutenu par le gouvernement américain, vise à consolider la direction de l'IA américaine. Cette entreprise ambitieuse promet un avenir façonné par AI Advanceme
 Sora vs Veo 2: Laquelle crée des vidéos plus réalistes?
Mar 10, 2025 pm 12:22 PM
Sora vs Veo 2: Laquelle crée des vidéos plus réalistes?
Mar 10, 2025 pm 12:22 PM
Veo 2 de Google et Sora d'Openai: Quel générateur de vidéos AI règne en suprême? Les deux plates-formes génèrent des vidéos d'IA impressionnantes, mais leurs forces se trouvent dans différents domaines. Cette comparaison, en utilisant diverses invites, révèle quel outil répond le mieux à vos besoins. T
 Google & # 039; s Gencast: Prévision météorologique avec Mini démo Gencast
Mar 16, 2025 pm 01:46 PM
Google & # 039; s Gencast: Prévision météorologique avec Mini démo Gencast
Mar 16, 2025 pm 01:46 PM
Gencast de Google Deepmind: une IA révolutionnaire pour les prévisions météorologiques Les prévisions météorologiques ont subi une transformation spectaculaire, passant des observations rudimentaires aux prédictions sophistiquées alimentées par l'IA. Gencast de Google Deepmind, un terreau
 Quelle IA est la meilleure que Chatgpt?
Mar 18, 2025 pm 06:05 PM
Quelle IA est la meilleure que Chatgpt?
Mar 18, 2025 pm 06:05 PM
L'article traite des modèles d'IA dépassant Chatgpt, comme Lamda, Llama et Grok, mettant en évidence leurs avantages en matière de précision, de compréhension et d'impact de l'industrie. (159 caractères)
