1. Type d'index
Les indices peuvent être divisés en index B-Tree et en index de hachage en fonction de l'implémentation sous-jacente. La plupart d'entre eux Nous utilisons toujours les index B-Tree en raison de leurs bonnes performances et de leurs fonctionnalités, qui sont plus adaptées à la construction de systèmes à haute concurrence.
Divisé selon la méthode de stockage de l'index, l'index peut être divisé en index clusterisé et index non clusterisé. Les nœuds feuilles d'un index non clusterisé contiennent uniquement tous les champs et ID de clé primaire, tandis que les nœuds feuilles d'un index clusterisé contiennent des lignes d'enregistrement complètes.
Selon l'index clusterisé et l'index non clusterisé, il peut être divisé en index ordinaire, couvrant l'index, l'index unique et l'index conjoint.
2. Index clusterisé et index non clusterisé
L'index clusterisé est également appelé index clusterisé. Il ne s'agit pas en fait d'un type d'index distinct, mais d'une méthode de stockage de données, la feuille. les nœuds de l'index clusterisé enregistrent toutes les informations de colonne d'une ligne d'enregistrements. En d’autres termes, le nœud feuille de l’index clusterisé contient une ligne d’enregistrement complète.
L'index non clusterisé est également appelé index auxiliaire et index ordinaire. Ses nœuds feuilles ne contiennent qu'une seule valeur de clé primaire. Pour rechercher des enregistrements via un index non clusterisé, vous devez d'abord trouver la clé primaire, et puis accédez au cluster via la clé primaire. La ligne d'enregistrement correspondante se trouve dans l'index. Ce processus est appelé retour de table.
Par exemple, une table de données contenant les noms et âges des utilisateurs, en supposant que la clé primaire est l'ID utilisateur, la structure de l'index clusterisé est (l'orange représente l'identifiant, le vert est le pointeur vers le nœud enfant) : #🎜 🎜#
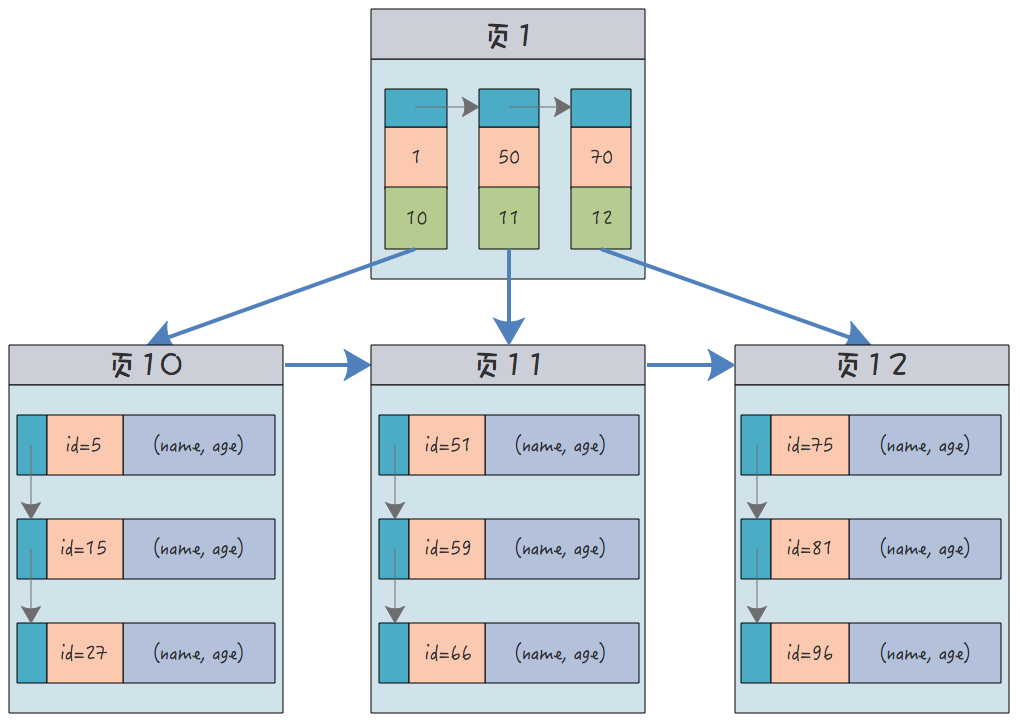
Dans les nœuds feuilles, afin de mettre en valeur les enregistrements,
sont séparés. En fait, ils sont reliés entre eux. un record dans l'ensemble. (id, name, age)
La structure d'un index non clusterisé (avec l'âge comme index) est :
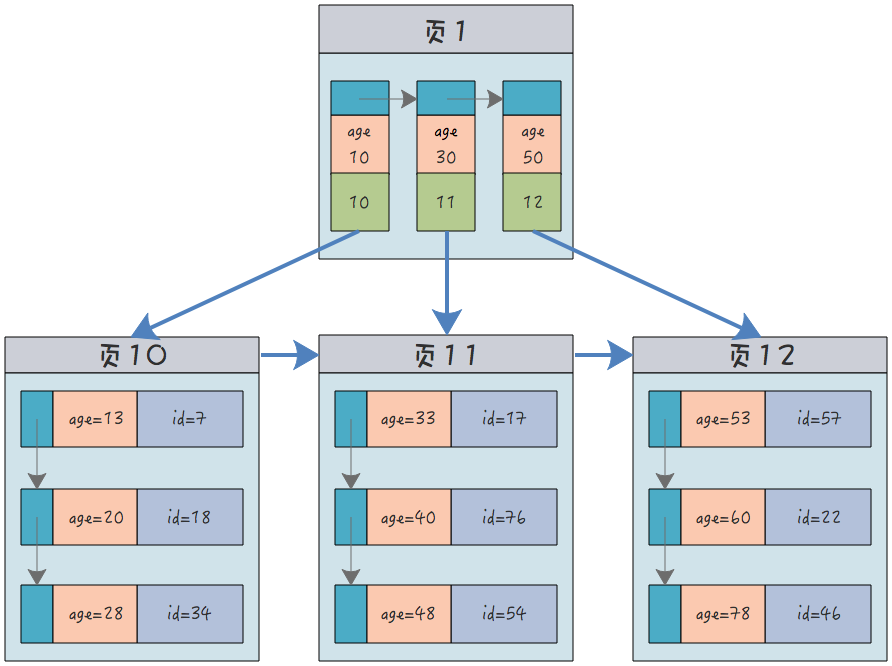
En plus de l'âge champ lui-même, dans le nœud feuille de ce nœud, seul l'ID de clé primaire de l'enregistrement actuel est inclus et les informations de l'enregistrement complet ne sont pas incluses. Vous devez interroger l'index clusterisé via le numéro d'identification pour obtenir la ligne entière de données d'enregistrement.
Dans InnoDB, chaque table doit avoir un index clusterisé, qui est créé par défaut en fonction de la clé primaire. S'il n'y a pas de clé primaire dans la table, InnoDB sélectionnera une colonne appropriée comme index clusterisé. Si aucune colonne appropriée n'est trouvée, une colonne cachée DB_ROW_ID sera utilisée comme index clusterisé.
3. Index de couverture
Étant donné que l'index non clusterisé ne contient pas d'informations complètes sur les données, la recherche d'enregistrements de données complets nécessite un retour à la table. à faire Deux requêtes d'index. Si chaque requête d'index doit être exécutée deux fois pour obtenir le résultat, cela entraînera inévitablement une perte d'efficacité, car si vous pouvez réduire la requête de un, vous devez la réduire de un.
Prenons l'exemple de l'index d'âge ci-dessus. Il s'agit d'un index non clusterisé. Si je souhaite interroger l'identifiant de l'utilisateur par âge, j'exécute l'instruction suivante :
. #🎜 🎜#
1 | sélectionnez l'identifiant dans les informations utilisateur où âge = 10 ; #🎜 🎜# |
Est-il encore nécessaire de restituer la montre dans ce cas ? Parce que je n'ai besoin que de la valeur de l'identifiant, je peux déjà obtenir l'identifiant via l'index d'âge. Si je reviens encore une fois à la table, ne serait-ce pas une opération inutile ? En fait, ce n’est pas nécessaire. Lorsque l'index auxiliaire contient déjà toutes les informations nécessaires à la requête, l'opération de retour de table peut être évitée dans la requête d'index. Il s'agit d'un index de couverture.
4. Index conjoint
L'index conjoint fait référence à un index créé sur plusieurs colonnes en même temps. Après avoir créé un index commun, les nœuds feuilles contiendront la valeur de chaque colonne d'index en même temps et seront triés en fonction. sur plusieurs colonnes en même temps. Ce tri est le même que ce que nous faisons. L'ordre lexicographique de compréhension est similaire.
Par exemple, la structure d'index créée pour les noms et âges ci-dessus en même temps :
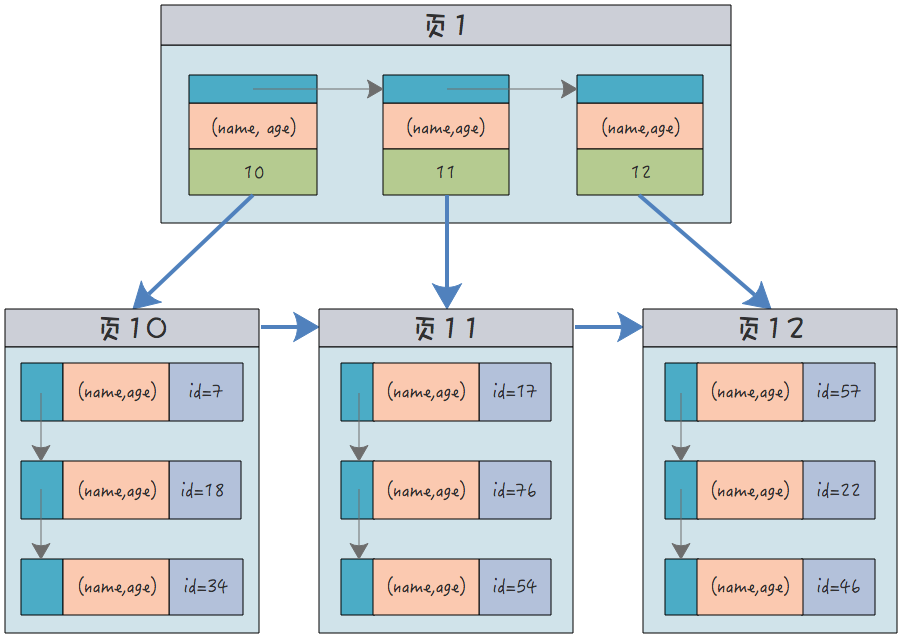
(name, age) sont toutes des abréviations, et je n'arrive pas à penser à plus d'une douzaine de noms.
Chaque nœud feuille enregistre toutes les colonnes d'index en même temps. De plus, il ne contient toujours que l'identifiant de la clé primaire.
Principe de correspondance des préfixes les plus à gauche
Lorsqu'un index est créé pour plusieurs colonnes, l'index ne peut pas être utilisé tant qu'il contient les colonnes pour lesquelles l'index a été créé. L'utilisation de l'index doit suivre le principe de correspondance des préfixes les plus à gauche.
Supposons que vous créiez un index sur les colonnes (A, B, C), alors seuls les scénarios suivants peuvent utiliser l'index :
Requête sur les colonnes (A, B, C)/(A, C) ou (A , B) Correspondra à l'index, l'index ne peut pas être utilisé pour (C, A) ou (B, C).
Les caractères génériques ne peuvent utiliser que le formulaire LIKE 'val%', et non LIKE '%VAL%', ce qui entraînera une analyse complète de la table.
La colonne d'index ne peut pas être utilisée. Par exemple, WHERE A + 1 = 5 entraînera l'échec de l'index.
Les colonnes d'index ne peuvent pas contenir de requêtes de valeurs de plage, telles que LIKE/BETWEEN/>/
Les colonnes d'index ne peuvent pas contenir de valeurs NULL.
Index pushdown
La nouvelle version de MySQL (5.6 et supérieure) a introduit un mécanisme de pushdown d'index : pendant le processus de traversée de l'index, les champs inclus dans l'index peuvent être jugés en premier, et les champs qui ne répondent pas aux Les conditions peuvent être directement filtrées. Enregistrez et réduisez le nombre de retours de table.
Par exemple, effectuez un index conjoint sur (nom, âge) dans le tableau ci-dessus. La logique de requête dans des circonstances normales est la suivante :
Cette approche entraînera de nombreux retours de table inutiles. Par exemple, il y a deux enregistrements (Zhang San, 10) et (Zhang San, 15) dans la table en ce moment. le dossier de (Zhang San, 20 ans) doit être interrogé. Lors de l'interrogation, localisez d'abord tous les ID de clé primaire qui remplissent les conditions via Zhang San, puis parcourez les lignes qui remplissent les conditions dans l'index clusterisé pour voir s'il existe des enregistrements correspondant à age = 20. Dans les situations réelles, aucun enregistrement ne remplit les conditions, ce processus de retour de table peut donc être considéré comme une démarche futile.
La fonction principale du pushdown d'index est d'améliorer cela. Dans l'index conjoint, les enregistrements qui n'ont pas besoin d'être renvoyés dans la table sont filtrés par nom et par âge, puis l'index est renvoyé dans la table pour réduire le nombre. des retours de table.
5. Index unique
Un index unique est un index qui n'autorise pas la même valeur d'index. Le système vérifie s'il existe des valeurs de clé en double lors de la création de l'index. Ceci est vérifié à chaque fois qu'un enregistrement est mis à jour ou ajouté. . L'index de clé primaire est l'index unique.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



