
 base de données
Redis
Comment réaliser l'identification et l'échange de données chaudes et froides dans Redis
base de données
Redis
Comment réaliser l'identification et l'échange de données chaudes et froides dans Redis
Comment réaliser l'identification et l'échange de données chaudes et froides dans Redis

Background
Le produit de stockage hybride Redis est un produit de stockage hybride développé indépendamment par Alibaba Cloud qui est entièrement compatible avec le protocole et les fonctionnalités Redis.
En stockant une partie des données froides sur le disque, cela réduit considérablement les coûts d'utilisation et dépasse la limite de mémoire sur le volume de données d'une instance unique Redis tout en garantissant que la plupart des performances d'accès ne diminuent pas.
Parmi elles, l'identification et l'échange de données chaudes et froides sont des facteurs clés dans la performance des produits de stockage hybrides.
Définition des données chaudes et froides
Dans le stockage hybride Redis, le rapport mémoire/disque est librement sélectionnable par l'utilisateur :
#🎜🎜 # 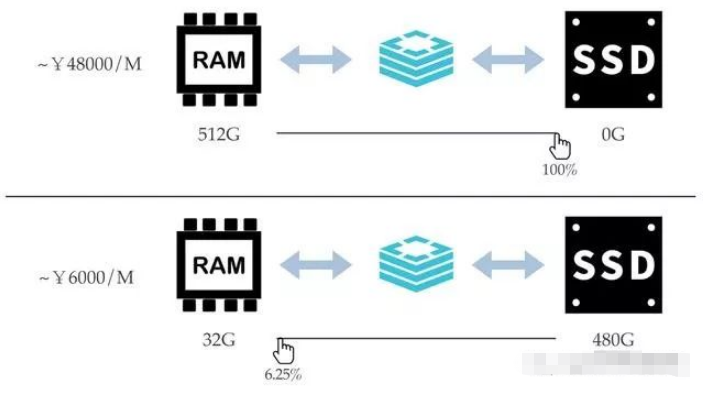
- # 🎜🎜#Key est consulté beaucoup plus fréquemment que Value.
- En tant que base de données KV, les demandes d'accès normales doivent d'abord rechercher la clé pour confirmer si la clé existe. Pour confirmer qu'une clé n'existe pas, vous devez. vérifiez toutes les clés sous une forme ou une autre. Une collection de clés. Conserver toutes les valeurs clés des structures de données en mémoire peut garantir que la vitesse de recherche est exactement la même que celle des structures de données en mémoire pure.
- Le ratio de taille de clé est très faible.
- Dans un modèle économique général, même s'il s'agit d'un type de chaîne ordinaire, sa valeur est généralement plusieurs fois supérieure à la clé. Pour les objets de collection tels que Set, List, Hash, etc., la valeur composée de tous les membres additionnés est plusieurs ordres de grandeur supérieure à la clé.
- Par conséquent, il existe deux principaux scénarios applicables pour les instances de stockage hybride Redis :
- Aucun accès aux données de manière uniforme , il y a des points chauds
- La mémoire n'est pas suffisante pour stocker toutes les données, et la valeur est grande (par rapport à la clé)
- #🎜🎜 ##🎜 🎜#
Identification des données chaudes et froides
Lorsque la mémoire est insuffisante, l'instance calculera le poids de la valeur en fonction de l'heure d'accès récente, de la fréquence d'accès, de la taille de la valeur et d'autres dimensions et attribuer le poids le plus bas. La valeur est stockée sur le disque et supprimée de la mémoire.
Le pseudo code est le suivant :
Dans le cas le plus idéal, on aimerait pouvoir calculer avec précision la valeur la plus basse actuelle. Cependant, le degré chaud et froid d'une valeur change dynamiquement en fonction de la situation d'accès, et le temps nécessaire pour recalculer les poids chauds et froids de toutes les valeurs à chaque fois est totalement inacceptable. Lorsque la mémoire est pleine, Redis lui-même éliminera les données selon la stratégie d'élimination définie par l'utilisateur, et l'écriture de données chaudes de la mémoire sur le disque peut également être considérée comme un processus « d'élimination ». Compte tenu des performances, de la précision et de la compréhension de l'utilisateur, nous utilisons des méthodes de calcul approximatives similaires à celles de Redis pour identifier les données chaudes et froides. Nous prenons en charge plusieurs stratégies et réduisons la consommation de processeur et de mémoire en échantillonnant de manière aléatoire une petite partie des données et en utilisant l'échantillonnage via le pool d'expulsion. .Informations historiques pour aider à améliorer la précision.
Lorsque la mémoire est pleine, Redis lui-même éliminera les données selon la stratégie d'élimination définie par l'utilisateur, et l'écriture de données chaudes de la mémoire sur le disque peut également être considérée comme un processus « d'élimination ». Compte tenu des performances, de la précision et de la compréhension de l'utilisateur, nous utilisons des méthodes de calcul approximatives similaires à celles de Redis pour identifier les données chaudes et froides. Nous prenons en charge plusieurs stratégies et réduisons la consommation de processeur et de mémoire en échantillonnant de manière aléatoire une petite partie des données et en utilisant l'échantillonnage via le pool d'expulsion. .Informations historiques pour aider à améliorer la précision.
Le diagramme schématique du taux de réussite de l'algorithme d'élimination approximative de Redis est présenté sous différentes versions et configurations avec différents nombres d'échantillons d'échantillonnage. Les points de données qui ont été éliminés sont en gris clair, les points de données qui n'ont pas été éliminés sont en gris et les points de données ajoutés pendant le test sont en vert.
Échange de données chaudes et froides
Le processus d'échange de données chaudes et froides de stockage mixte Redis est terminé dans le thread IO en arrière-plan.
Hot data->cold dataMéthode asynchrone :
Lorsque la mémoire est proche de la valeur maximale, le thread principal génère une série de tâches d'échange de données ;
Le thread d'arrière-plan exécute ces tâches d'échange de données et informe le thread principal après l'achèvement ; # 🎜🎜#
- Le thread principal met à jour et libère la valeur dans la mémoire, et met à jour la valeur dans le dictionnaire de données dans la mémoire en une simple méta-information ; 🎜🎜#
#🎜🎜 #
Méthode de synchronisation : - Lorsque le trafic d'écriture est trop important, la méthode asynchrone ne peut pas échanger les données dans le temps, ce qui peut amener la mémoire à dépasser la spécification maximale. Le thread principal exécutera directement la tâche d'échange de données pour atteindre l'objectif de limitation de courant déguisé.
Cold data->Hot data
Avant d'exécuter la commande, le thread principal détermine d'abord si les valeurs impliquées dans la commande sont en mémoire ;
Sinon, générez une tâche de chargement de données, suspendez la client et principal Le thread continue de traiter les autres demandes du client ;- Le thread d'arrière-plan effectue la tâche de chargement des données et informe le thread principal une fois terminé ; 🎜🎜#
- Le thread principal met à jour la valeur dans le dictionnaire de données en mémoire, réveille le client précédemment suspendu et traite sa demande.
- Méthode de synchronisation :
- Dans le script Lua, lors de la phase spécifique d'exécution de la commande, si une valeur se trouve stocké dans Sur le disque, le thread principal effectuera directement la tâche de chargement des données, garantissant que la sémantique des scripts et des commandes Lua reste inchangée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Pour afficher toutes les touches dans Redis, il existe trois façons: utilisez la commande Keys pour retourner toutes les clés qui correspondent au modèle spécifié; Utilisez la commande SCAN pour itérer les touches et renvoyez un ensemble de clés; Utilisez la commande info pour obtenir le nombre total de clés.
