
 base de données
tutoriel mysql
Analyse d'un exemple de processus de persistance des données MySQL
base de données
tutoriel mysql
Analyse d'un exemple de processus de persistance des données MySQL
Analyse d'un exemple de processus de persistance des données MySQL

1. Brève description du processus
Comprendre le processus de persistance des données MySQL peut nous aider à approfondir notre compréhension de MySQL sous-jacent. Dans cet article, nous allons trier ce processus de manière populaire pour aider tout le monde à établir une compréhension préliminaire, si vous êtes intéressé, vous pouvez étudier et rechercher ce processus en profondeur.
Le stockage des données MySQL peut généralement être divisé en deux parties, les procédures stockées en mémoire et le stockage persistant sur le disque dur. Ici, il s'agit de buffer poll et de redo log en mémoire. code> et <code>Journal des transactions et Structure de la table sur le disque. Dans cet article, nous n'expliquerons pas la conception spécifique de chaque partie en détail, mais nous vous donnerons simplement une compréhension conceptuelle : buffer poll和redo log以及磁盘上的事务日志和表结构,在本文中,我们不具体解释每一部分的具体设计,只是给大家一个概念型的认识:
buffer poll是InnoDB引擎缓存池的一部分,我们这里可以简单理解为数据库从磁盘读进内存的内存块的缓存;redo log是内存中的逻辑日志,记录了事务的变更操作事务日志是磁盘上的食物逻辑日志表结构是真正存储数据的结构
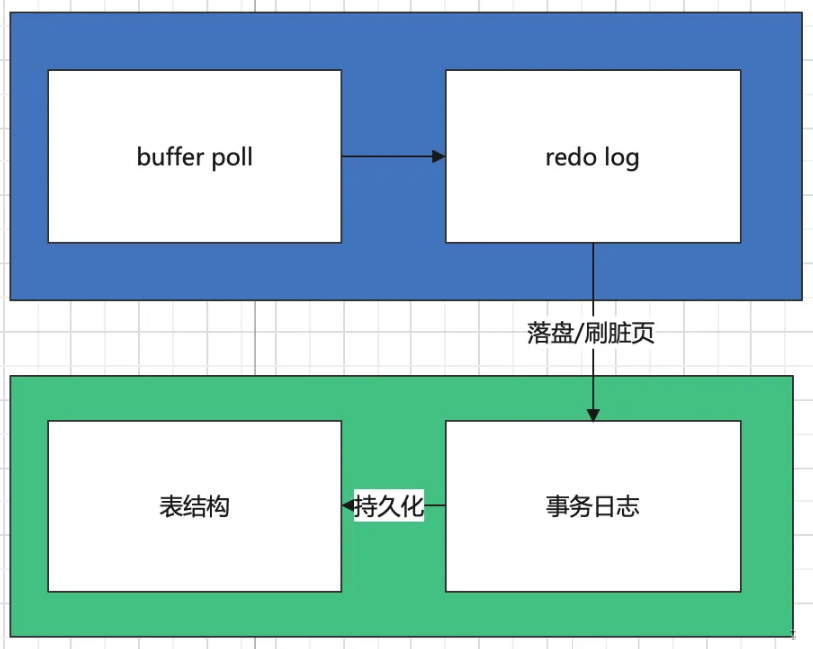
2. 内存中的操作
buffer poll中有对于读入内存的数据的缓存,在查询命令执行时,会优先在缓存中查看是否命中,未命中就会从磁盘中将需要的数据读进来,缓存的管理使用的是改良的LRU算法,这里不做深入地介绍了。
当一条修改指令运行的时候,首先进行的是对于buffer poll中缓存的修改,被修改后的数据会被标记为脏页,同时,修改的操作也会记录在redo log中,我们常说的MVCC中的版本链就是借助redo log实现的。
需要注意的是,脏页不是立刻落到磁盘的,而是有可以设置的刷盘控制机制,例如,一个事务执行结算后立刻落盘,按照一定时间定期落盘等等。
在内存中的操作都是非持久化的,如果这时发生了意料之外的问题导致系统宕机,数据是还没有持久化的,所以理论上也不会对数据库造成破坏性的影响。
3. 磁盘的持久化
3.1 事务日志的作用
InnoDB在磁盘的持久化分为两步,第一步是逻辑日志的存储,之后再将日志中的数据刷进磁盘空间。
在讨论为什么要使用逻辑日志之前,我们需要简单理解随机IO与顺序IO的区别:
寻址过程是磁盘IO中的一个重要瓶颈,因为它需要将探针移动到需要读取的位置来读取磁盘数据。
顺序IO是指寻址的空间是连续的,移动距离很短,随机IO是指我们需要寻找的地址分布在各处,需要移动很长的距离。
所以,我们能很明晰的得出结论:将随机IO替换为顺序IO
-
buffer pollfait partie du pool de cache du moteur InnoDB On peut simplement le comprendre ici comme le cache des blocs de mémoire que la base de données. lit du disque vers la mémoire. ; -
redo logest un journal logique en mémoire, enregistrant les opérations de modification des transactions -
Journal des transactions.C'est le journal logique des aliments sur le disque -
La structure de la tableest la structure qui stocke réellement les données
 2. Opérations en mémoire🎜🎜buffer poll Il y a un cache pour les données lues dans la mémoire dans code> Lorsque la commande de requête est exécutée, elle vérifiera d'abord s'il y a un hit dans le cache. Si elle n'atteint pas, les données requises. sera lu à partir du disque. La gestion du cache est améliorée. L'algorithme LRU ne sera pas présenté en profondeur ici. 🎜🎜Lorsqu'une instruction de modification est exécutée, la première chose à faire est de modifier le cache dans
2. Opérations en mémoire🎜🎜buffer poll Il y a un cache pour les données lues dans la mémoire dans code> Lorsque la commande de requête est exécutée, elle vérifiera d'abord s'il y a un hit dans le cache. Si elle n'atteint pas, les données requises. sera lu à partir du disque. La gestion du cache est améliorée. L'algorithme LRU ne sera pas présenté en profondeur ici. 🎜🎜Lorsqu'une instruction de modification est exécutée, la première chose à faire est de modifier le cache dans buffer poll Les données modifiées seront marquées comme dirty page. À ce moment-là, les opérations de modification seront également enregistrées dans le redo log. La chaîne de versions dans MVCC dont nous disons souvent qu'elle est implémentée à l'aide du redo log. 🎜🎜Il convient de noter que les pages sales ne sont pas immédiatement déposées sur le disque, mais il existe un mécanisme de contrôle de vidage qui peut être défini. Par exemple, une transaction est déposée sur le disque immédiatement après le règlement, périodiquement déposée sur le disque en fonction. une certaine heure, etc. 🎜🎜Toutes les opérations en mémoire sont non persistantes. Si un problème inattendu survient et que le système plante, les données n'ont pas été conservées, donc théoriquement elles n'auront pas d'impact destructeur sur la base de données. 🎜🎜3. Persistance du disque🎜🎜3.1 Le rôle du journal des transactions🎜🎜La persistance d'InnoDB sur le disque est divisée en deux étapes. La première étape consiste à stocker le journal logique, puis à vider les données du journal dans l'espace disque. 🎜🎜Avant d'expliquer pourquoi nous devrions utiliser des journaux logiques, nous devons comprendre brièvement la différence entre les E/S aléatoires et les E/S séquentielles :🎜🎜L'adressage Le processus constitue un goulot d'étranglement important dans les E/S du disque car il nécessite de déplacer la sonde là où elle doit être lue pour lire les données du disque. 🎜🎜E/S séquentielles signifie que l'espace adressé est continu et la distance de déplacement est très courte. E/S aléatoires signifie que l'adresse que nous devons trouver est distribuée partout et doit l'être. déplacé très rapidement sur de longues distances. 🎜🎜Nous pouvons donc clairement tirer la conclusion : remplacer Random IO par Sequential IO peut améliorer efficacement l'efficacité des entrées/sorties du disque. C'est exactement le rôle des journaux logiques, puisque. les fichiers journaux sont continus sur le disque, l'efficacité des E/S peut être beaucoup plus élevée par rapport aux informations des tables de données distribuées partout. 🎜🎜Tant que nous mettons complètement à jour l'opération dans le journal des transactions, la transaction a été conservée avec succès et un thread dédié stockera les informations du journal dans la structure de la table. 🎜🎜3.2 Stockage en deux étapes de la structure de la table🎜🎜Le processus de stockage des informations du journal dans la structure de la table est divisé en deux étapes. Premièrement, les données seront mises à jour dans la zone de cache de l'en-tête de la table. terminée, les données seront mises à jour dans la structure Actualiser la table correspondante. 🎜🎜Le but du stockage en deux étapes est d'assurer une forte cohérence du stockage des données et d'éviter que les données ne soient incomplètes en raison d'un temps d'arrêt de la base de données pendant le processus de flashage sur le disque. 🎜🎜La zone de cache de l'en-tête du tableau et le bloc de stockage de la structure du tableau ont des codes de contrôle pour vérifier l'intégrité des données. Si le premier est complet et le second est incomplet, il suffit de reflasher les anciennes données dans le. ce dernier pour résoudre le problème. Si le premier est incomplet, cela signifie que le processus de vidage du journal a échoué, il suffit de le vider à nouveau. 🎜Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1209
24
52
1209
24

 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Rôle de MySQL: Bases de données dans les applications Web
Apr 17, 2025 am 12:23 AM
Le rôle principal de MySQL dans les applications Web est de stocker et de gérer les données. 1.MySQL traite efficacement les informations utilisateur, les catalogues de produits, les enregistrements de transaction et autres données. 2. Grâce à SQL Query, les développeurs peuvent extraire des informations de la base de données pour générer du contenu dynamique. 3.MySQL fonctionne basé sur le modèle client-serveur pour assurer une vitesse de requête acceptable.
