

Quelles sont les contraintes de MySQL ?

1. Présentation
Concept : Les contraintes sont des règles qui agissent sur les champs d'une table pour limiter les données stockées dans la table.
Objectif : Assurer l'exactitude, la validité et l'intégrité des données de la base de données.
Catégorie :

Remarque : Les contraintes sont appliquées aux champs du tableau, et des contraintes peuvent être ajoutées lors de la création/modification du tableau.
2. Démonstration de contraintes
Nous avons introduit les contraintes courantes dans la base de données et les mots-clés impliqués dans les contraintes. Alors, comment spécifier ces contraintes lors de la création et de la modification de tables ? Ensuite, nous allons passer une démonstration avec un cas ? .
Exigences du cas : Complétez la création de la structure de la table selon les exigences. Les exigences sont les suivantes :
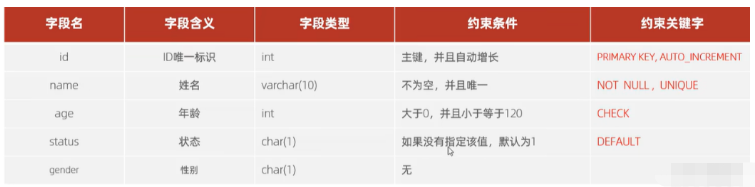
L'instruction de création de table correspondante est :
CREATE TABLE tb_user ( id INT AUTO_INCREMENT PRIMARY KEY COMMENT 'ID唯一标识', NAME VARCHAR ( 10 ) NOT NULL UNIQUE COMMENT '姓名', age INT CHECK ( age > 0 && age <= 120 ) COMMENT '年龄', STATUS CHAR ( 1 ) DEFAULT '1' COMMENT '状态', gender CHAR ( 1 ) COMMENT '性别' );
Lors de l'ajout de contraintes aux champs, il suffit d'ajouter le mot-clé de la contrainte après le champ, et nous devons faire attention à sa syntaxe.
Nous exécutons le SQL ci-dessus pour créer la structure de la table, puis nous pouvons la tester via un ensemble de données pour vérifier si les contraintes peuvent prendre effet.
(1) Tout d'abord, trois éléments de données ont été ajoutés
insert into tb_user(name,age,status,gender) values ('Tom1',19,'1','男'),('Tom2',25,'0','男'); insert into tb_user(name,age,status,gender) values ('Tom3',19,'1','男');
Il a fallu 21 secondes pour ajouter trois éléments de données. Que se passe-t-il ?
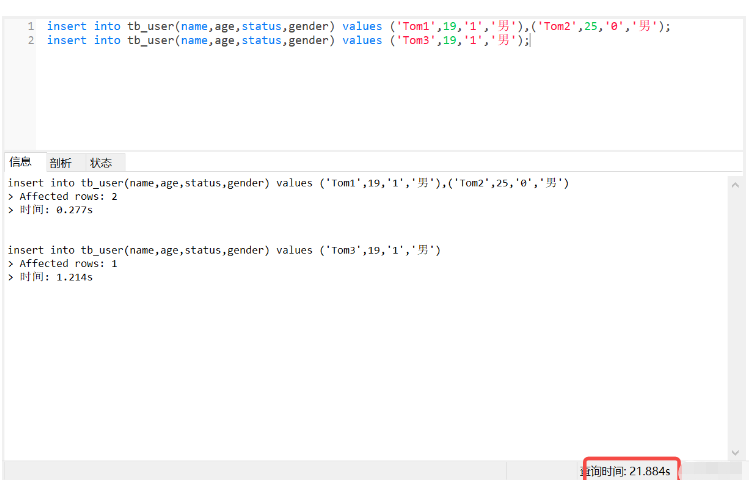
À l'origine, je pensais que l'ajout de ces contraintes provoquait la lenteur des nouvelles données, mais ce n'était pas le cas, car il s'agit du serveur Linux d'Alibaba, puis j'ai connecté MySQL via le client sous Linux pour exécuter le nouvel ajout, qui était de 0,01 seconde, indiquant que c'est le temps nécessaire à Navicat pour se connecter à l'hôte distant.
Même si ces nouvelles contraintes sont ajoutées, les nouvelles données seront lentes, ce qui ne peut être clairement remarqué que par lots. Elles sont fondamentalement invisibles pour une seule donnée.
(2) Nom du test NON NULL
insert into tb_user(name,age,status,gender) values (null,19,'1','男');

(3) Nom du test UNIQUE (uniquement)
Les données ajoutées ci-dessus ont déjà Tom3, si vous l'ajoutez à nouveau, une erreur sera signalée directement .
insert into tb_user(name,age,status,gender) values ('Tom3',19,'1','男');

Bien qu'une erreur soit signalée, nous découvrirons un phénomène lorsque nous ajouterons une autre donnée à ce moment-là.
insert into tb_user(name,age,status,gender) values ('Tom4',80,'1','男');
Il s'agit évidemment d'un identifiant auto-croissant, mais il n'y a pas de 4. La raison en est que UNIQUE est prêt à être mis dans la base de données après avoir demandé l'identifiant auto-croissant. Ensuite, à ce moment-là, il vérifiera d'abord si. il y en a un avec le même nom dans la valeur de la base de données, s'il y en a un, le nouvel ajout échoue. Bien que le nouvel ajout échoue, l'ID d'incrémentation automatique a été demandé !
Au contraire, lorsque nous venons de tester le nom nul, il n'a pas demandé d'identifiant, car il l'avait déjà jugé vide au début et n'avait pas encore atteint l'étape de demande d'identifiant.
Déterminez s'il est vide -》 Demander un identifiant d'incrémentation automatique -》 Déterminez s'il existe déjà une valeur existante
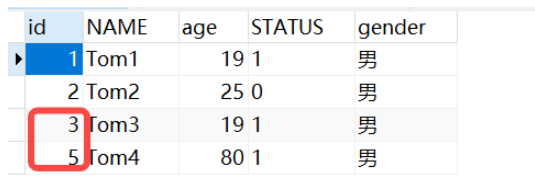
Résumé : Lorsque le nom nouvellement ajouté n'est pas vide, mais contient les mêmes données que le précédent, le nouvel ajout échouera à ce moment-là, mais il s'appliquera à l'identifiant de clé primaire.
(4) Test CHECK
Ce que nous avons défini, c'est que l'âge doit être supérieur à 0 et inférieur ou égal à 120, sinon la sauvegarde échouera !
age int check (age > 0 && age <= 120) COMMENT '年龄' ,
insert into tb_user(name,age,status,gender) values ('Tom5',-1,'1','男'); insert into tb_user(name,age,status,gender) values ('Tom5',121,'1','男');
(5) Test DEFAULT ‘1’ Valeur par défaut
STATUS CHAR ( 1 ) DEFAULT '1' COMMENT '状态',
insert into tb_user(name,age,gender) values ('Tom5',120,'男');
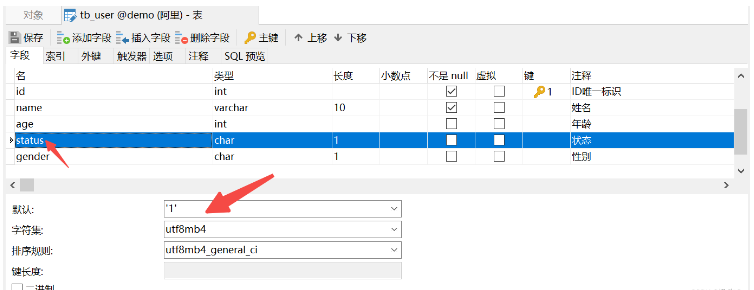
(6) Ci-dessus, nous complétons la spécification des contraintes en écrivant des instructions SQL. Et si nous sommes un client Navicat ?
Auto-incrémentation de clé primaire
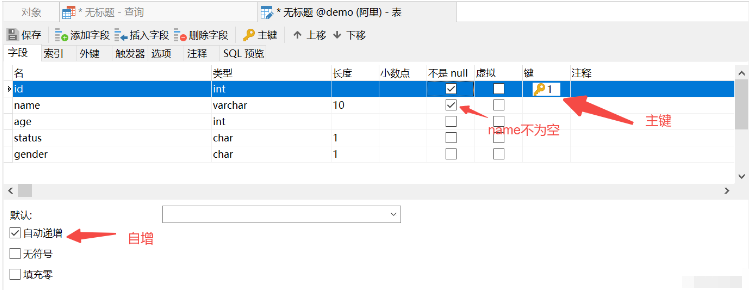
contrainte unique de nom

le statut par défaut est 1
3. Contraintes de clé étrangère
1. Que sont les contraintes de clé étrangère
Clé étrangère : utilisation Pour établir une connexion entre les données des deux tables afin d'assurer la cohérence et l'intégrité des données.
Regardons un exemple :
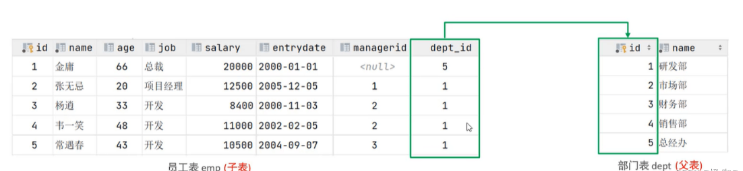
La table emp à gauche est la table des employés, qui stocke les informations de base des employés, y compris l'identifiant de l'employé, son nom, son âge, son poste, son salaire, son adhésion. date et ID du superviseur, ID du service. Ce qui est stocké dans les informations sur l'employé est l'ID du service dept_id, et l'ID de ce service est l'identifiant de clé primaire de la table de département associée. Ensuite, le dept_id de la table emp est la clé étrangère. , et il est associé à la clé primaire d'une autre table .
2、 不使用外键有什么影响
通过上面的示例,我们分别来演示 添加外键 和不添加外键的区别,首先来看不添加 外键 对数据有什么影响:
准备数据:
CREATE TABLE dept ( id INT auto_increment COMMENT 'ID' PRIMARY KEY, NAME VARCHAR ( 50 ) NOT NULL COMMENT '部门名称' ) COMMENT '部门表'; INSERT INTO dept (id, name) VALUES (1, '研发部'), (2, '市场部'),(3, '财务部'), (4, '销售部'), (5, '总经办'); CREATE TABLE emp ( id INT auto_increment COMMENT 'ID' PRIMARY KEY, NAME VARCHAR ( 50 ) NOT NULL COMMENT '姓名', age INT COMMENT '年龄', job VARCHAR ( 20 ) COMMENT '职位', salary INT COMMENT '薪资', entrydate date COMMENT '入职时间', managerid INT COMMENT '直属领导ID', dept_id INT COMMENT '部门ID' ) COMMENT '员工表'; INSERT INTO emp (id, name, age, job,salary, entrydate, managerid, dept_id) VALUES (1, '金庸', 66, '总裁',20000, '2000-01-01', null,5), (2, '张无忌', 20, '项目经理',12500, '2005-12-05', 1,1), (3, '杨逍', 33, '开发', 8400,'2000-11-03', 2,1), (4, '韦一笑', 48, '开 发',11000, '2002-02-05', 2,1), (5, '常遇春', 43, '开发',10500, '2004-09-07', 3,1), (6, '小昭', 19, '程 序员鼓励师',6600, '2004-10-12', 2,1);
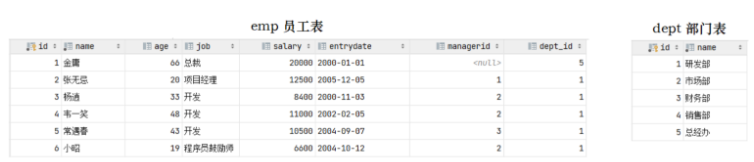
接下来,我们可以做一个测试,删除id为1的部门信息。
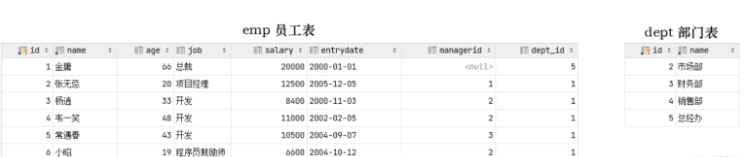
结果,我们看到删除成功,而删除成功之后,部门表不存在id为1的部门,而在emp表中还有很多的员工,关联的为id为1的部门,此时就出现了数据的不完整性。 而要想解决这个问题就得通过数据库的外键约束。
正常开发当中有时候会通过业务代码来控制数据的不完整性,例如删除部门的时候会先根据部门id去查看一下有没有对应的员工表,如果有则删除失败,没有则删除成功。
3、 添加外键的语法
可以在创建表的时候直接添加外键,也可以对现已存在的表添加外键。
(1)方式一
CREATE TABLE 表名( 字段名 数据类型, ... [CONSTRAINT] [外键名称] FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名) );
使用示例:
CREATE TABLE emp ( id INT auto_increment COMMENT 'ID' PRIMARY KEY, NAME VARCHAR ( 50 ) NOT NULL COMMENT '姓名', age INT COMMENT '年龄', job VARCHAR ( 20 ) COMMENT '职位', salary INT COMMENT '薪资', entrydate date COMMENT '入职时间', managerid INT COMMENT '直属领导ID', dept_id INT COMMENT '部门ID', CONSTRAINT fk_emp_dept_id FOREIGN KEY (dept_id) REFERENCES dept (id) ) COMMENT '员工表';
也可以省略掉CONSTRAINT fk_emp_dept_id 这样mysql就会自动给我们起外键名称。
方式二:对现存在的表添加外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名) ;
使用示例:
alter table emp add constraint fk_emp_dept_id FOREIGN KEY (dept_id) REFERENCES dept(id);
方式三:Navicat添加外键

删除外键:
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
使用示例:
alter table emp drop foreign key fk_emp_dept_id;
4、 删除/更新行为
我们将在父表数据删除时发生的限制行为称为删除/更新行为,此行为是在添加外键之后发生的。具体的删除/更新行为有以下几种:

默认的MySQL 8.0.27版本中,RESTRICT是用于删除和更新行的行为!但是,不同的版本可能会有不同的行为

具体语法为:
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段) REFERENCES 主表名 (主表字段名) ON UPDATE CASCADE ON DELETE CASCADE;
就是比原先添加外键后面多了这些ON UPDATE CASCADE ON DELETE CASCADE,代表的是更新时采用CASCADE ,删除时也采用CASCADE
5、 演示删除/更新行为
(1)演示RESTRICT
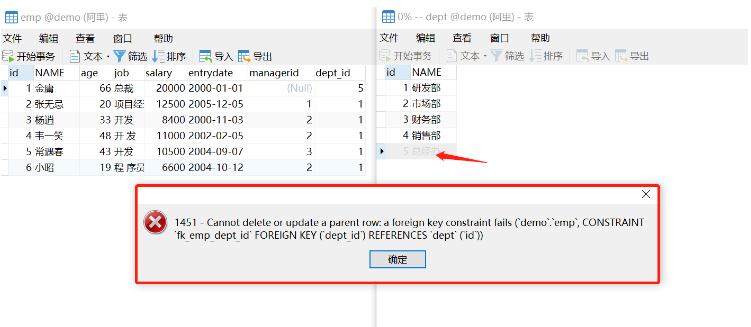
在对父表中的记录进行删除或更新操作时,需要先检查该记录是否存在关联的外键,如果存在,则不允许执行删除或更新操作。 (与 NO ACTION 一致) 默认行为
首先要添加外键,默认是RESTRICT行为!
alter table emp add constraint fk_emp_dept_id FOREIGN KEY (dept_id) REFERENCES dept(id);
删除父表中id为5的记录时,会因为emp表中的dept_id存在5而报错。假如要更新id也同样会报错的!
(2)演示CASCADE
当在父表中删除/更新对应记录时,首先检查该记录是否有对应外键,如果有,则
也删除/更新外键在子表中的记录。
删除外键的语法:
ALTER TABLE 表名 DROP FOREIGN KEY 外键约束名;
删除外键的示例:
alter table emp drop foreign key fk_emp_dept_id;
指定外键的删除更新行为为cascade
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update cascade on delete cascade ;
修改父表id为1的记录,将id修改为6

我们发现,原来在子表中dept_id值为1的记录,现在也变为6了,这就是cascade级联的效果。
在一般的业务系统中,不会修改一张表的主键值。
删除父表id为6的记录

我们发现,父表的数据删除成功了,但是子表中关联的记录也被级联删除了。
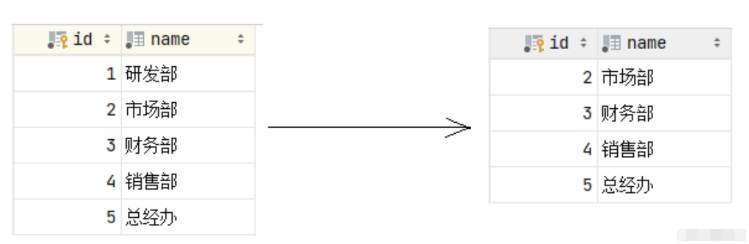
(3)演示SET NULL
当在父表中删除对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(这就要求该外键允许取null)。
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update set null on delete set null ;
在执行测试之前,我们需要先移除已创建的外键 fk_emp_dept_id。然后再通过数据脚本,将emp、dept表的数据恢复了。
接下来,我们删除id为1的数据,看看会发生什么样的现象。
我们发现父表的记录是可以正常的删除的,父表的数据删除之后,再打开子表 emp,我们发现子表emp的dept_id字段,原来dept_id为1的数据,现在都被置为NULL了。
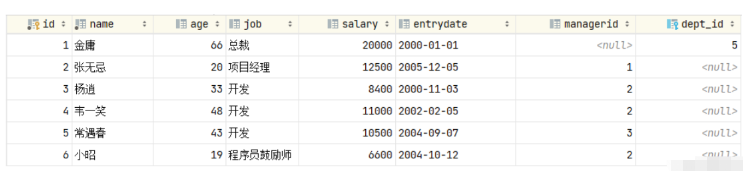
C'est l'effet du comportement de suppression/mise à jour de SET NULL.
4. Est-il préférable d'utiliser l'incrémentation automatique ou l'uuid comme identifiant de clé primaire ?
Lors de la conception de tables dans MySQL, MySQL recommande officiellement de ne pas utiliser d'identifiant de flocon de neige uuid ou discontinu et non répétitif (de forme longue et unique) , mais recommande une incrémentation automatique continue. La recommandation officielle pour augmenter l'identifiant de clé primaire est auto_increment, alors pourquoi n'est-il pas recommandé d'utiliser uuid ?
1. Testez l'uuid, l'identifiant d'auto-incrémentation et l'efficacité de l'insertion de nombres aléatoires
Tout d'abord, créez trois tables user_auto_key représente la table d'auto-incrémentation, user_uuid représente l'uuid du stockage de l'identifiant et random_key représente l'identifiant de la table. est l'identifiant du flocon de neige. Ensuite, les résultats du test d'insertion de données par lots en se connectant à jdbc sont les suivants :
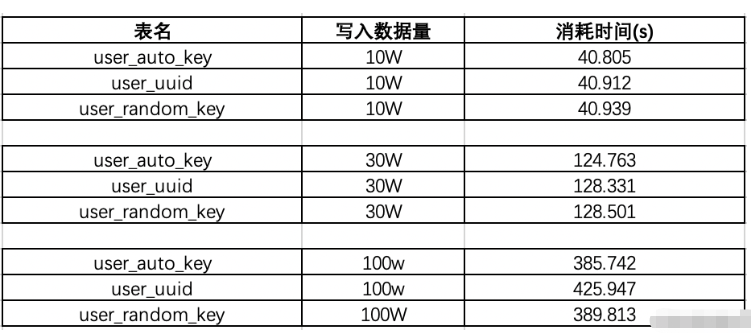
Lorsque le volume de données existant est de 130 W : Testons à nouveau l'insertion de données de 10 w pour voir quels seront les résultats :

Cela peut être vu Lorsque la quantité de données est d'environ 100 W, l'efficacité d'insertion de uuid est au plus bas, et lorsque 130 W de données sont ajoutés dans la séquence suivante, le temps d'uudi chute à nouveau. Le classement global de l'efficacité de l'utilisation du temps est le suivant : auto_key>random_key>uuid, uuid a l'efficacité la plus faible
2 Inconvénients de l'utilisation d'identifiants à croissance automatique
1 Une fois que d'autres ont exploré votre base de données, ils peuvent l'obtenir en fonction de l'ID à croissance automatique. de la base de données Avec les informations sur la croissance de votre entreprise, il est facile d'analyser votre situation opérationnelle
2. Pour les charges à haute concurrence, innodb provoquera un conflit de verrouillage évident lors de l'insertion par clé primaire, et la limite supérieure de la clé primaire deviendra une valeur de base de données. conflit Hotspot, parce que toutes les insertions se produisent ici, l'insertion simultanée provoquera une concurrence de verrouillage d'espacement
3. Le mécanisme de verrouillage Auto_Increment entraînera la saisie de verrous à incrémentation automatique, et il y aura une certaine perte de performances
4. L'incrémentation d'ID implique la migration des données. C'est assez gênant !
5. Et lorsqu'il s'agit de sous-bases de données et de sous-tables, il est assez gênant d'auto-incrémenter les identifiants !
3. Inconvénients de l'utilisation de uuid
Étant donné que uuid n'a pas de règles par rapport aux ID séquentiels à incrémentation automatique, la valeur de la nouvelle ligne n'est pas nécessairement supérieure à la valeur de la clé primaire précédente, donc innodb ne peut pas le faire à la place. Au lieu d'insérer toujours de nouvelles lignes à la fin de l'index, vous devez trouver un nouvel emplacement approprié pour la nouvelle ligne afin d'allouer un nouvel espace. Ce processus nécessite d'effectuer plusieurs opérations supplémentaires, et le désordre des données peut entraîner leur dispersion, entraînant les problèmes suivants :
1 La page cible écrite est susceptible d'avoir été vidée sur le disque et supprimée du cache, ou n'a pas non plus été chargé dans le cache, innodb doit trouver et lire la page cible du disque dans la mémoire avant de l'insérer, ce qui entraînera de nombreuses E/S aléatoires
2. Parce que les écritures sont dans le désordre, innodb doit le faire. Effectuez fréquemment des opérations de fractionnement de page pour allouer de l'espace pour de nouvelles lignes. Le fractionnement de page entraîne le déplacement d'une grande quantité de données. Au moins trois pages doivent être modifiées pour une insertion
3. En raison du fractionnement fréquent des pages, les pages deviendront clairsemées et irrégulières. . Le remplissage finira par entraîner une fragmentation des données
des problèmes de fractionnement et de fragmentation des pages. uuid causera effectivement ce problème, mais l'algorithme Snowflake est naturellement séquentiel. L'ID nouvellement inséré doit être le plus grand, donc je pense. Utiliser l’algorithme du flocon de neige est un très bon choix !
5. Utilisez le moins possible les clés étrangères dans le développement réel
Les clés primaires et les index sont indispensables. Non seulement ils peuvent optimiser la vitesse de récupération des données, mais les développeurs peuvent également économiser d'autres travaux.
Focus du conflit : si la conception de la base de données nécessite des clés étrangères. Il y a ici deux questions :
La première est de savoir comment garantir l'intégrité et la cohérence des données de la base de données
La seconde est l'impact de la première sur les performances ;
Ici sont divisés en deux points de vue, pour et contre, pour référence !
1. Point de vue positif
1. La base de données elle-même garantit la cohérence, l'intégrité des données et est plus fiable, car il est difficile pour le programme de garantir l'intégrité des données à 100 %, et en utilisant des clés étrangères même si le serveur de base de données des pannes ou d'autres problèmes surviennent. Lorsque des problèmes surviennent, la cohérence et l'intégrité des données peuvent être garanties dans la plus grande mesure.
2. La conception de bases de données avec des clés primaires et étrangères peut augmenter la lisibilité du diagramme ER, ce qui est très important dans la conception de bases de données.
3. La logique métier expliquée dans une certaine mesure par les clés étrangères rendra la conception réfléchie, spécifique et complète.
Il existe une relation un-à-plusieurs entre la base de données et l'application. L'application A conservera l'intégrité de sa partie des données. Lorsque le système devient plus grand, les applications A et B peuvent être développées par des développements différents. équipes. Comment se coordonner pour garantir l'intégrité des données, et si une nouvelle application C est ajoutée après un an, comment y faire face ?
2. Vues opposées
1. Des déclencheurs ou des applications peuvent être utilisés pour garantir l'intégrité des données
2. Une trop grande importance ou l'utilisation de clés primaires/clés étrangères augmentera la difficulté de développement et entraînera des problèmes tels qu'un trop grand nombre de tables
3. Lorsqu'aucune clé étrangère n'est utilisée, la gestion des données est simple, le fonctionnement est pratique et les performances sont élevées (les opérations telles que l'importation et l'exportation sont plus rapides lors de l'insertion, de la mise à jour et de la suppression de données)
Ne pensez même pas aux clés étrangères dans une base de données massive. Imaginez, un programme doit insérer des millions d'enregistrements chaque jour. Lorsqu'il y a des contraintes de clé étrangère, il doit vérifier si l'enregistrement est qualifié à chaque fois. est plus d'un champ. Avec les clés étrangères, le nombre d'analyses augmente de façon exponentielle ! Un de mes programmes a été réalisé en 3 heures si des clés étrangères étaient ajoutées, cela prendrait 28 heures !
3. Conclusion
1. Dans les grands systèmes (faibles exigences de performances, exigences de sécurité élevées), utilisez des clés étrangères ; dans les grands systèmes (exigences de performances élevées, contrôle de sécurité par vous-même), aucune clé étrangère n'est nécessaire ; quoi qu'il en soit, il est préférable d'utiliser des clés étrangères.
2. Utilisez les clés étrangères de manière appropriée et n'en faites pas trop.
Afin de garantir la cohérence et l'intégrité des données, vous pouvez les contrôler via des programmes sans utiliser de clés étrangères. À ce stade, une couche doit être écrite pour mettre en œuvre la protection des données, puis diverses applications de la base de données sont accessibles via cette couche.
Remarque :
MySQL autorise l'utilisation de clés étrangères, mais à des fins de vérification de l'intégrité, cette fonctionnalité est ignorée dans tous les types de tables, à l'exception des types de tables InnoDB. Cela peut paraître étrange, mais c'est en fait tout à fait normal : effectuer une vérification d'intégrité après chaque insertion, mise à jour et suppression de toutes les clés étrangères dans une base de données est un processus long et consommateur de ressources qui peut avoir un impact sur les performances, en particulier lors du traitement de clés étrangères complexes ou complexes. le nombre de connexions d'enroulement. Par conséquent, les utilisateurs peuvent choisir celui qui correspond à leurs besoins spécifiques sur la base du tableau.
Donc, si vous avez besoin de meilleures performances et n'avez pas besoin de vérification d'intégrité, vous pouvez choisir d'utiliser le type de table MyISAM. Si vous souhaitez créer une table basée sur l'intégrité référentielle dans MySQL et souhaitez maintenir de bonnes performances sur cette base, c'est le cas. Il est préférable de choisir une structure de table de type innoDB
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
Dans la base de données MySQL, la relation entre l'utilisateur et la base de données est définie par les autorisations et les tables. L'utilisateur a un nom d'utilisateur et un mot de passe pour accéder à la base de données. Les autorisations sont accordées par la commande Grant, tandis que le tableau est créé par la commande Create Table. Pour établir une relation entre un utilisateur et une base de données, vous devez créer une base de données, créer un utilisateur, puis accorder des autorisations.
 MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL convient aux débutants car il est simple à installer, puissant et facile à gérer les données. 1. Installation et configuration simples, adaptées à une variété de systèmes d'exploitation. 2. Prise en charge des opérations de base telles que la création de bases de données et de tables, d'insertion, d'interrogation, de mise à jour et de suppression de données. 3. Fournir des fonctions avancées telles que les opérations de jointure et les sous-questionnaires. 4. Les performances peuvent être améliorées par l'indexation, l'optimisation des requêtes et le partitionnement de la table. 5. Prise en charge des mesures de sauvegarde, de récupération et de sécurité pour garantir la sécurité et la cohérence des données.
 Intégration RDS MySQL avec Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Intégration RDS MySQL avec Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Simplification de l'intégration des données: AmazonrDSMysQL et l'intégration Zero ETL de Redshift, l'intégration des données est au cœur d'une organisation basée sur les données. Les processus traditionnels ETL (extrait, converti, charge) sont complexes et prennent du temps, en particulier lors de l'intégration de bases de données (telles que AmazonrDSMysQL) avec des entrepôts de données (tels que Redshift). Cependant, AWS fournit des solutions d'intégration ETL Zero qui ont complètement changé cette situation, fournissant une solution simplifiée et à temps proche pour la migration des données de RDSMySQL à Redshift. Cet article plongera dans l'intégration RDSMYSQL ZERO ETL avec Redshift, expliquant comment il fonctionne et les avantages qu'il apporte aux ingénieurs de données et aux développeurs.
 Comment remplir le nom d'utilisateur MySQL et le mot de passe
Apr 08, 2025 pm 07:09 PM
Comment remplir le nom d'utilisateur MySQL et le mot de passe
Apr 08, 2025 pm 07:09 PM
Pour remplir le nom d'utilisateur et le mot de passe MySQL: 1. Déterminez le nom d'utilisateur et le mot de passe; 2. Connectez-vous à la base de données; 3. Utilisez le nom d'utilisateur et le mot de passe pour exécuter des requêtes et des commandes.
 L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
1. Utilisez l'index correct pour accélérer la récupération des données en réduisant la quantité de données numérisées SELECT * FROMMLOYEESEESHWHERELAST_NAME = 'SMITH'; Si vous recherchez plusieurs fois une colonne d'une table, créez un index pour cette colonne. If you or your app needs data from multiple columns according to the criteria, create a composite index 2. Avoid select * only those required columns, if you select all unwanted columns, this will only consume more server memory and cause the server to slow down at high load or frequency times For example, your table contains columns such as created_at and updated_at and timestamps, and then avoid selecting * because they do not require inefficient query se
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Navicat lui-même ne stocke pas le mot de passe de la base de données et ne peut récupérer que le mot de passe chiffré. Solution: 1. Vérifiez le gestionnaire de mots de passe; 2. Vérifiez la fonction "Remember Motway" de Navicat; 3. Réinitialisez le mot de passe de la base de données; 4. Contactez l'administrateur de la base de données.
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
