

Que se passera-t-il si la mémoire Redis est trop grande ?

La base de données principale est en panne maître". Plus précisément, il sélectionne une bibliothèque esclave parmi les bibliothèques esclaves restantes du cluster et la met à niveau vers la bibliothèque maître. Une fois la bibliothèque esclave mise à niveau vers la bibliothèque maître, les bibliothèques esclaves restantes sont montées sous celle-ci pour devenir sa bibliothèque esclave, et enfin. l'intégralité de la base de données maître-esclave est restaurée.
Ce qui précède est un processus complet de reprise après sinistre, et le processus le plus coûteux est le remontage de la bibliothèque esclave, et non le changement de la bibliothèque principale.
En effet, Redis ne peut pas continuer à synchroniser les données de la nouvelle base de données principale après les modifications de la base de données principale en fonction de points de synchronisation tels que mysql et mongodb. Une fois que la base de données esclave change de maître dans le cluster Redis, l'approche de Redis consiste à effacer la base de données esclave de la base de données maître remplacée, puis à synchroniser complètement une copie des données de la nouvelle base de données maître avant de reprendre le transfert. L'ensemble du processus de restauration de la bibliothèque esclave est le suivant :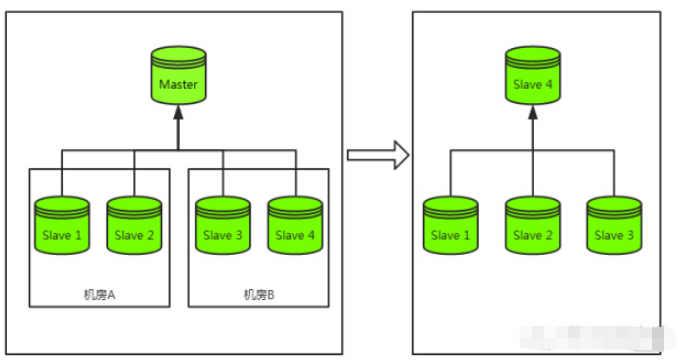
La bibliothèque principale enregistre ses propres données sur le disque
La bibliothèque principale envoie le fichier rdb à la bibliothèque esclave
- Démarrez le chargement à partir de la bibliothèque
- Démarrer après le chargement Reprendre le téléchargement et commencer à fournir des services en même temps
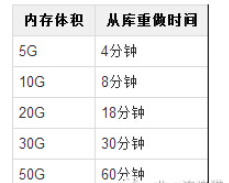
- Évidemment, plus la taille de la mémoire de Redis est grande au cours de ce processus, le temps de chacune des étapes ci-dessus sera allongé. les données de test sont les suivantes (nous pensons que les performances de notre machine sont meilleures) :
- Vous pouvez voir que lorsque les données atteignent 20G, le temps de récupération d'une base de données esclave a été prolongé à près de 20 minutes. bases de données esclaves, la restauration séquentielle prendra au total 200 minutes, et si la bibliothèque esclave est responsable d'un grand nombre de demandes de lecture à ce moment-là, pouvez-vous tolérer un temps de récupération aussi long En voyant cela, vous le ferez certainement ? demandez : Pourquoi toutes les bibliothèques esclaves ne peuvent-elles pas être refaites en même temps ? En effet, si toutes les bibliothèques esclaves le sont en même temps, si vous demandez un fichier RDB à la bibliothèque principale, la carte réseau de la bibliothèque principale sera immédiatement pleine. et entrer dans un état où les services ne peuvent pas être fournis normalement. À ce moment-là, la bibliothèque principale meurt à nouveau, ce qui ne fait qu'ajouter l'insulte à l'injure.
 L'opération d'écriture de la bibliothèque principale Redis sera stockée dans cette zone puis envoyée à la bibliothèque esclave. Si les étapes 1, 2 et 3 ci-dessus prennent trop de temps, il est probable que le tampon de synchronisation soit écrasé. cela fonctionnera-t-il lorsque la bibliothèque esclave ne trouvera pas l'emplacement de reprise correspondant ? La réponse est de refaire les étapes 1, 2 et 3
L'opération d'écriture de la bibliothèque principale Redis sera stockée dans cette zone puis envoyée à la bibliothèque esclave. Si les étapes 1, 2 et 3 ci-dessus prennent trop de temps, il est probable que le tampon de synchronisation soit écrasé. cela fonctionnera-t-il lorsque la bibliothèque esclave ne trouvera pas l'emplacement de reprise correspondant ? La réponse est de refaire les étapes 1, 2 et 3
Mais comme nous ne pouvons pas résoudre les étapes chronophages 1, 2 et 3, la bibliothèque esclave le fera ! entrez pour toujours. Cercle vicieux : demande constante de données complètes à la base de données principale, ce qui entraîne un impact sérieux sur la carte réseau de la base de données principale.
2 Problème d'expansion de la capacitéIl arrive souvent qu'il y ait une augmentation soudaine du trafic. Habituellement, avant que la cause ne soit trouvée, notre réponse d'urgence consiste à augmenter la capacité.
Selon le tableau du scénario 1, il faut près de 20 minutes pour étendre une base de données esclave Redis de 20 Go. L'activité de 20 minutes peut-elle être tolérée à ce moment critique ?
3 Un mauvais réseau entraîne la refonte de la bibliothèque esclave et finit par déclencher une avalancheLe plus gros problème dans ce scénario est que la synchronisation entre la bibliothèque maître et la bibliothèque esclave est interrompue, et à ce moment il est très probable que le La bibliothèque esclave accepte toujours les demandes d'écriture, puis une fois le temps d'interruption trop long, le tampon de synchronisation risque d'être écrasé. À ce moment-là, la dernière position de synchronisation de la bibliothèque esclave a été perdue. Après la restauration du réseau, bien que la bibliothèque maître n'ait pas changé, la position de synchronisation de la bibliothèque esclave étant perdue, la bibliothèque esclave doit être refaite, ce qui est le cas. 1, 2 et 3 à la question 1. 4 étapes. Si la taille de la mémoire de la bibliothèque principale est trop grande à ce moment-là, la vitesse de rétablissement de la bibliothèque esclave sera très lente et les requêtes de lecture envoyées à la bibliothèque esclave seront en même temps sérieusement affectées, car la taille de. le fichier RDB transféré est trop volumineux, la carte réseau de la bibliothèque principale sera gravement affectée pendant longtemps.
4 Plus la mémoire est grande, plus l'opération qui déclenche la persistance bloque le thread principal.Redis est une base de données en mémoire à thread unique Lorsque Redis doit effectuer des opérations fastidieuses, il en créera une nouvelle. processus pour le faire, tel que bgsave, bgrewriteaof. Lors du fork d'un nouveau processus, bien que le contenu des données partageables n'ait pas besoin d'être copié, la table des pages mémoire de l'espace de processus précédent sera copiée par le thread principal et bloquera toutes les opérations de lecture et d'écriture. l'utilisation de la mémoire augmente, plus cela prend de temps. Par exemple : pour Redis avec 20 Go de mémoire, bgsave prend environ 750 ms pour copier la table des pages mémoire, et le thread principal Redis sera également bloqué pendant 750 ms.
SolutionLa solution est bien sûr de réduire autant que possible l'utilisation de la mémoire. Dans des circonstances normales, nous procédons comme suit :
1 Définir le délai d'expirationDéfinir le délai d'expiration pour les clés sensibles au temps. . La propre stratégie de nettoyage des clés expirées de Redis peut être utilisée pour réduire l'utilisation de la mémoire des clés expirées. Elle peut également réduire les problèmes commerciaux et éliminer le besoin d'un nettoyage régulier.
2 Ne stockez pas de déchets dans Redis.C'est tout simplement absurde, mais y a-t-il quelqu'un qui ressent la même chose que nous ?
3 Nettoyer les données inutiles à temps
Par exemple, un redis transporte les données de 3 entreprises, et après un certain temps, 2 les entreprises se déconnectent, puis nettoyez simplement les données pertinentes de ces deux entreprises
4 Essayez de compresser les données autant que possible
Par exemple, certaines données de texte longues, la compression peut réduire considérablement l'utilisation de la mémoire
5 Payer faites attention à la croissance de la mémoire et localisez les clés de grande capacité
Que vous soyez un administrateur de base de données ou un développeur, si vous utilisez Redis, vous devez faire attention à la mémoire, sinon vous êtes en fait incompétent. Ici, vous pouvez analyser quelles clés sont dans Redis. Les instances sont relativement grandes pour aider l'entreprise à localiser rapidement les clés anormales (non-) Les clés qui devraient croître sont souvent la source de problèmes)
6 pika
Si vous ne voulez vraiment pas être si fatigué, alors migrez l'entreprise vers le nouveau pika open source, afin que vous n'ayez pas à prêter trop d'attention à la mémoire, la mémoire redis l'est aussi. Les problèmes causés par celle-ci ne sont plus un problème.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Utilisez l'outil de ligne de commande redis (Redis-CLI) pour gérer et utiliser Redis via les étapes suivantes: Connectez-vous au serveur, spécifiez l'adresse et le port. Envoyez des commandes au serveur à l'aide du nom et des paramètres de commande. Utilisez la commande d'aide pour afficher les informations d'aide pour une commande spécifique. Utilisez la commande QUIT pour quitter l'outil de ligne de commande.
 Comment configurer le temps d'exécution du script LUA dans Centos Redis
Apr 14, 2025 pm 02:12 PM
Comment configurer le temps d'exécution du script LUA dans Centos Redis
Apr 14, 2025 pm 02:12 PM
Sur CentOS Systems, vous pouvez limiter le temps d'exécution des scripts LUA en modifiant les fichiers de configuration Redis ou en utilisant des commandes Redis pour empêcher les scripts malveillants de consommer trop de ressources. Méthode 1: Modifiez le fichier de configuration Redis et localisez le fichier de configuration Redis: le fichier de configuration redis est généralement situé dans /etc/redis/redis.conf. Edit Fichier de configuration: Ouvrez le fichier de configuration à l'aide d'un éditeur de texte (tel que VI ou NANO): Sudovi / etc / redis / redis.conf Définissez le délai d'exécution du script LUA: Ajouter ou modifier les lignes suivantes dans le fichier de configuration pour définir le temps d'exécution maximal du script LUA (unité: millisecondes)
