
 base de données
tutoriel mysql
Quelle est la différence entre binlog/redolog/undolog dans MySQL ?
base de données
tutoriel mysql
Quelle est la différence entre binlog/redolog/undolog dans MySQL ?
Quelle est la différence entre binlog/redolog/undolog dans MySQL ?

Quelle est la différence entre MySQL binlog/redolog/undolog ?
Je veux vous parler du mécanisme de verrouillage dans InnoDB, donc cela impliquera inévitablement le système de log MySQL, binlog, redo log, undo log, etc. J'ai vu que ces trois logs résumés par certains amis ne sont pas mauvais, donc dépêchez-vous de les récupérer. Venez le partager avec vos amis.
Le journal est une partie importante de la base de données mysql, enregistrant diverses informations d'état pendant le fonctionnement de la base de données. Les journaux mysql incluent principalement les journaux d'erreurs, les journaux de requêtes, les journaux de requêtes lentes, les journaux de transactions et les journaux binaires. mysql数据库的重要组成部分,记录着数据库运行期间各种状态信息。mysql日志主要包括错误日志、查询日志、慢查询日志、事务日志、二进制日志几大类。
作为开发,我们重点需要关注的是二进制日志(binlog)和事务日志(包括redo log和undo log),本文接下来会详细介绍这三种日志。
bin log
binlog用于记录数据库执行的写入性操作(不包括查询)信息,以二进制的形式保存在磁盘中。binlog是mysql的逻辑日志,并且由Server层进行记录,使用任何存储引擎的mysql数据库都会记录binlog日志。
逻辑日志:可以理解为记录的就是sql语句.
物理日志:
mysql数据最终是保存在数据页中的,物理日志记录的就是数据页变更 。
binlog是通过追加的方式进行写入的,可以通过max_binlog_size参数设置每个binlog文件的大小,当文件大小达到给定值之后,会生成新的文件来保存日志。
在实际应用中,binlog的主要使用场景有两个,分别是主从复制和数据恢复。
主从复制:在
Master端开启binlog,然后将binlog发送到各个Slave端,Slave端重放binlog从而达到主从数据一致。数据恢复:通过使用
mysqlbinlog工具来恢复数据。
binlog刷盘时机
对于InnoDB存储引擎而言,只有在事务提交时才会记录biglog,此时记录还在内存中,那么biglog是什么时候刷到磁盘中的呢?
mysql通过sync_binlog参数控制biglog的刷盘时机,取值范围是0-N:
0:不去强制要求,由系统自行判断何时写入磁盘;
1:每次
commit的时候都要将binlog写入磁盘;N:每N个事务,才会将
binlog写入磁盘。
从上面可以看出,sync_binlog最安全的是设置是1,这也是MySQL 5.7.7之后版本的默认值。但是设置一个大一些的值可以提升数据库性能,因此实际情况下也可以将值适当调大,牺牲一定的一致性来获取更好的性能。
binlog日志格式
binlog日志有三种格式,分别为STATMENT、ROW和MIXED。
在MySQL 5.7.7之前,默认的格式是STATEMENT,MySQL 5.7.7之后,默认值是ROW。日志格式通过binlog-format指定。
STATMENT:基于SQL语句的复制(statement-based replication, SBR),每一条会修改数据的sql语句会记录到binlog中 。ROW:基于行的复制(row-based replication, RBR),不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了 。MIXED:基于STATMENT和ROW两种模式的混合复制(mixed-based replication, MBR),一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog
redo log
为什么需要redo log
我们都知道,事务的四大特性里面有一个是持久性,具体来说就是只要事务提交成功,那么对数据库做的修改就被永久保存下来了,不可能因为任何原因再回到原来的状态。
那么
En tant que développeur, nous devons nous concentrer sur le journal binaire (mysqlbinlog) et le journal des transactions (y compris leredo loget leundo log). Cet article Ces trois types de journaux seront présentés en détail ensuite. bin log🎜🎜binlogest utilisé pour enregistrer les informations sur les opérations d'écriture (hors requêtes) effectuées par la base de données et est enregistrée sous forme binaire sur le disque.binlogest le journal logique demysqlet est enregistré par la coucheServeurToute base de donnéesmysqlutilisant n'importe quel moteur de stockage. enregistrera le journalbinlog. 🎜🎜
- 🎜Journal logique : on peut comprendre que ce qui est enregistré est l'instruction sql.🎜
- 🎜Journal physique :
mysql data Il est finalement enregistré dans la page de données et le journal physique enregistre les modifications de la page de données. 🎜binlogest écrit en ajoutant, et chaquebinlogpeut être défini via le paramètremax_binlog_sizeLa taille de le fichier. Lorsque la taille du fichier atteint la valeur donnée, un nouveau fichier sera généré pour enregistrer le journal. 🎜🎜Dans les applications pratiques, il existe deux principaux scénarios d'utilisation debinlog, à savoir la réplication maître-esclave et la récupération de données. 🎜
- 🎜Réplication maître-esclave : ouvrez
binlogdu côtéMaître, puisbinlogEnvoyer à chaque extrémité <code>Esclave, et l'extrémitéEsclaverelit lebinlogpour obtenir la cohérence des données maître-esclave. 🎜- 🎜Récupération de données : récupérez les données à l'aide de l'outil
mysqlbinlog. 🎜synchronisation du vidage du binlog
🎜Pour le moteur de stockageInnoDB, lebiglogsera enregistré uniquement lorsque la transaction est validée. >, l'enregistrement est toujours en mémoire à ce moment-là, alors quandbigloga-t-il été vidé sur le disque ? 🎜🎜mysqlcontrôle le timing de vidage debiglogvia le paramètresync_binlogLa plage de valeurs est0-N: 🎜🎜Comme le montre ce qui précède, le paramètre le plus sûr pour
- 🎜0 : Aucune exigence obligatoire, le système décidera quand écrire sur le disque 🎜
- 🎜1 : Chaque
commit ;,binlogdoit être écrit sur le disque ; 🎜- 🎜N :
binlogsera écrit tous les N transactions sur le disque. 🎜sync_binlogest1, qui est égalementMySQL 5.7.7La valeur par défaut pour les versions après code>. Toutefois, la définition d'une valeur plus élevée peut améliorer les performances de la base de données. Par conséquent, dans des situations réelles, vous pouvez également augmenter la valeur de manière appropriée et sacrifier un certain degré de cohérence pour obtenir de meilleures performances. 🎜format du journal binlog
🎜binlogLe journal a trois formats, à savoirSTATMENT,ROWetMIXED. 🎜🎜Avant <code>MySQL 5.7.7, le format par défaut estSTATEMENT, et aprèsMySQL 5.7.7, la valeur par défaut estROW . Le format du journal est spécifié via <code>binlog-format. 🎜), général la copie utilise le mode
- 🎜
STATMENT: Réplication basée sur des instructionsSQL(réplication basée sur des instructions, SBR code> code> ), chaque instruction SQL qui modifie les données sera enregistrée dans <code>binlog. 🎜- 🎜
ROW: Réplication basée sur les lignes (réplication basée sur les lignes, RBR), qui n'enregistre pas les informations de contexte de chaque instruction SQL, Enregistrez uniquement quelle donnée a été modifiée. 🎜- 🎜
MIXED: Réplication mixte basée surSTATMENTetROW, MBRSTATEMENTpour enregistrer lebinlog, et pour les opérations qui ne peuvent pas être copiées en modeSTATEMENT, utilisez le modèleROWsauvegarde dubinlog🎜🎜redo log🎜Pourquoi le redo log est-il nécessaire
🎜Nous savons tous que les quatre transactions majeures sont l'une des fonctionnalités est la persistance. Plus précisément, tant que la transaction est soumise avec succès, les modifications apportées à la base de données sont enregistrées de manière permanente et il est impossible de revenir à l'état d'origine pour quelque raison que ce soit. 🎜🎜Alors, commentmysqlassure-t-il la cohérence ? 🎜🎜Le moyen le plus simple consiste à vider toutes les pages de données impliquées dans les modifications sur le disque à chaque fois qu'une transaction est validée. Cependant, cela entraînerait de sérieux problèmes de performances, qui se reflètent principalement sous deux aspects : 🎜
Parce que
Innodbeffectue une interaction avec le disque en unités depage, et qu'une transaction ne peut modifier que quelques octets dans une page de données à ce stade, ce sera le cas. la page de données complète est vidée sur le disque, ce sera un gaspillage de ressources !Innodb是以页为单位进行磁盘交互的,而一个事务很可能只修改一个数据页里面的几个字节,这个时候将完整的数据页刷到磁盘的话,太浪费资源了!一个事务可能涉及修改多个数据页,并且这些数据页在物理上并不连续,使用随机IO写入性能太差!
因此
mysql设计了redo log,具体来说就是只记录事务对数据页做了哪些修改,这样就能完美地解决性能问题了(相对而言文件更小并且是顺序IO)。redo log基本概念
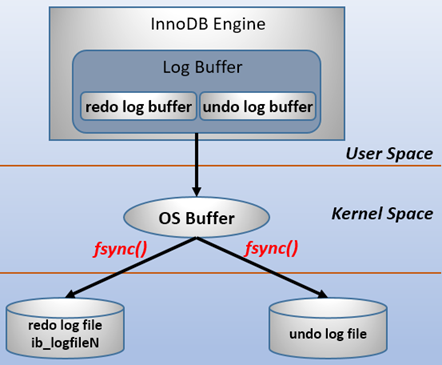
redo log包括两部分:一个是内存中的日志缓冲(redo log buffer),另一个是磁盘上的日志文件(redo logfile)。
mysql每执行一条DML语句,先将记录写入redo log buffer,后续某个时间点再一次性将多个操作记录写到redo log file。这种先写日志,再写磁盘的技术就是MySQL
里经常说到的WAL(Write-Ahead Logging)技术。在计算机操作系统中,用户空间(
user space)下的缓冲区数据一般情况下是无法直接写入磁盘的,中间必须经过操作系统内核空间(kernel space)缓冲区(OS Buffer)。因此,
redo log buffer写入redo logfile实际上是先写入OS Buffer,然后再通过系统调用fsync()将其刷到redo log file
中,过程如下:
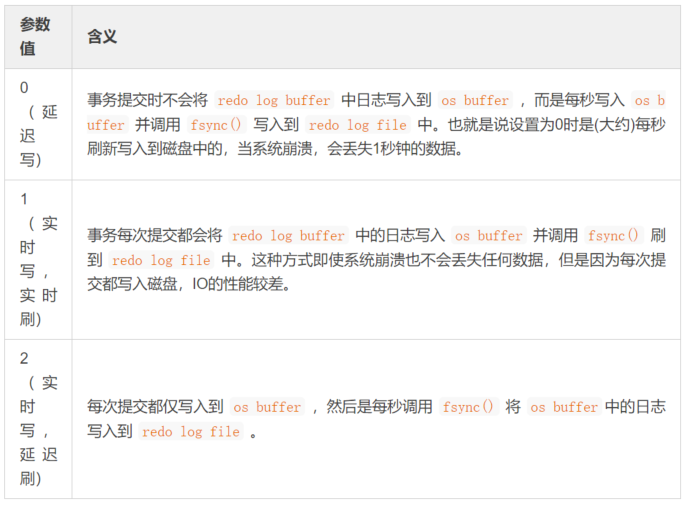
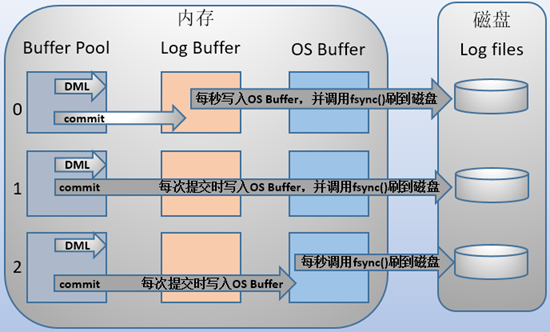
mysql支持三种将redo log buffer写入redo log file的时机,可以通过innodb_flush_log_at_trx_commit参数配置,各参数值含义如下:
redo log记录形式
前面说过,
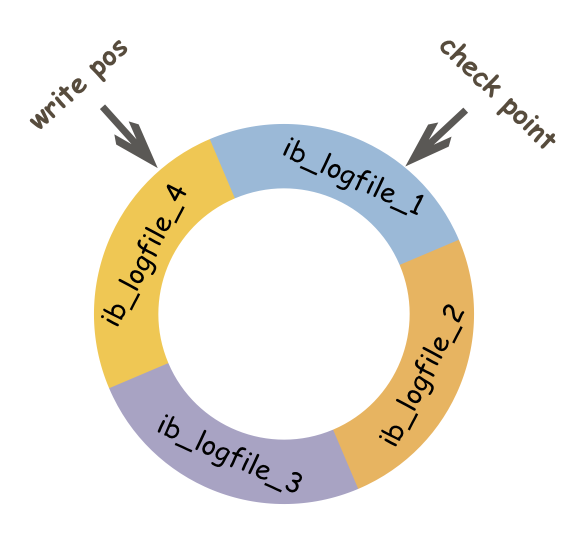
redo log实际上记录数据页的变更,而这种变更记录是没必要全部保存,因此redo log实现上采用了大小固定,循环写入的方式,当写到结尾时,会回到开头循环写日志。如下图:
同时我们很容易得知, 在innodb中,既有
redo log需要刷盘,还有数据页也需要刷盘,redo log存在的意义主要就是降低对数据页刷盘的要求 ** 。在上图中,
write pos表示redo log当前记录的LSN(逻辑序列号)位置,check point表示数据页更改记录刷盘后对应redo log所处的LSN(逻辑序列号)位置。
write pos到check point之间的部分是redo log空着的部分,用于记录新的记录;check point到write pos之间是redo log待落盘的数据页更改记录。当write pos追上check point时,会先推动check point向前移动,空出位置再记录新的日志。启动
innodb的时候,不管上次是正常关闭还是异常关闭,总是会进行恢复操作。因为redo log记录的是数据页的物理变化,因此恢复的时候速度比逻辑日志(如binlog)要快很多。重启
innodb时,首先会检查磁盘中数据页的LSN,如果数据页的LSN小于日志中的LSN,则会从checkpoint开始恢复。还有一种情况,在宕机前正处于
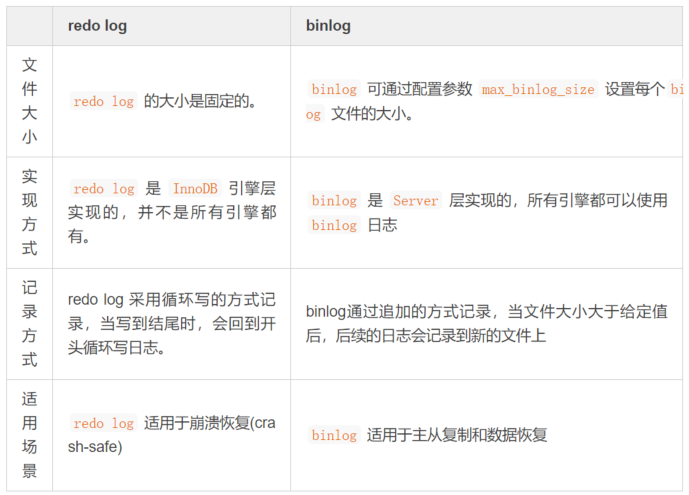
checkpoint的刷盘过程,且数据页的刷盘进度超过了日志页的刷盘进度,此时会出现数据页中记录的LSN大于日志中的LSN,这时超出日志进度的部分将不会重做,因为这本身就表示已经做过的事情,无需再重做。redo log与binlog区别
由
🎜Une transaction peut impliquer la modification de plusieurs pages de données, et ces pages de données ne sont pas physiquement continues. Les performances de l'utilisation de l'écriture d'E/S aléatoires sont trop médiocres ! 🎜binlog和redo log的区别可知:binlog日志只用于归档,只依靠binlog是没有crash-safe🎜Ainsi,mysqla conçu leredo logPlus précisément, il enregistre uniquement les modifications apportées à la page de données par la transaction, donc. Il peut parfaitement résoudre le problème de performances (relativement parlant, le fichier est plus petit et il s'agit d'E/S séquentielles). 🎜🎜Concept de base du redo log
🎜redo logcomprend deux parties : l'une est le tampon de journal en mémoire (redo log buffer), et la l'autre est le fichier journal sur le disque (redo logfile). 🎜🎜mysqlChaque fois qu'une instructionDMLest exécutée, l'enregistrement est d'abord écrit dans letampon de journalisation, puis plusieurs enregistrements sont écrits dans letampon de journalisationà un moment ultérieur. Les enregistrements d'opération sont écrits dans lefichier de journalisation. Cette technologie consistant à écrire d'abord des journaux puis à écrire sur le disque est la technologieWAL (Write-Ahead Logging)souvent mentionnée dansMySQL
. 🎜🎜Dans les systèmes d'exploitation informatiques, les données du tampon dans l'espace utilisateur (espace utilisateur) ne peuvent généralement pas être écrites directement sur le disque et doivent passer par l'espace noyau du système d'exploitation (espace noyau ) tampon (<code>Tampon du système d'exploitation). 🎜🎜 Par conséquent, écrireredo log bufferdansredo logfileécrit en fait d'abordOS Buffer, puis appellefsync via le système ()Flashez-le dans lefichier redo log
. Le processus est le suivant : 🎜🎜🎜🎜
mysqlprend en charge trois types detampon de journalisationLe moment de l'écriture duredo log filepeut être configuré via le paramètreinnodb_flush_log_at_trx_commit. La signification de chaque valeur de paramètre est la suivante : 🎜🎜format d'enregistrement du journal redo
🎜Comme mentionné précédemment, leredo logEn fait, les modifications dans les pages de données sont enregistrées, et il n'est pas nécessaire de sauvegarder tous ces enregistrements de modifications. Par conséquent, la mise en œuvre duredo log. Adopte une taille fixe et une méthode d'écriture cyclique. Lors de l'écriture jusqu'à la fin, il reviendra au début pour écrire les journaux en boucle. Comme indiqué ci-dessous : 🎜🎜🎜🎜En même temps, nous pouvons facilement savoir que dans innodb, à la fois leredo logdoit être actualisé, et lapage de donnéeségalement doit être actualisé.redo logest de réduire la nécessité de vider lapage de données**. 🎜🎜Dans l'image ci-dessus,write posreprésente la positionLSN(numéro de séquence logique) actuellement enregistrée dans leredo log, etcheck point indique la position <code>LSN(numéro de séquence logique) duredo logcorrespondant après que l'enregistrement de modification de la page de données ait été vidé. 🎜🎜La partie entrewrite posetcheck pointest la partie vide duredo log, qui est utilisée pour enregistrer de nouveaux enregistrements; Entre le point de contrôleetwrite posse trouve l'enregistrement de modification de la page de donnéesredo logà écrire sur le disque. Lorsquewrite posrattraperacheck point, il poussera d'abordcheck pointvers l'avant pour faire de la place pour de nouveaux journaux. 🎜🎜Lors du démarrage deinnodb, peu importe s'il a été arrêté normalement ou anormalement la dernière fois, une opération de récupération sera toujours effectuée. Étant donné que leredo logenregistre les modifications physiques dans les pages de données, la récupération est beaucoup plus rapide que les journaux logiques (tels quebinlog). 🎜🎜Lors du redémarrage deinnodb, il vérifiera d'abord leLSNde la page de données sur le disque si leLSNde la page de données est inférieur. que leLSN dans le journal, la récupération démarrera à partir ducheckpoint. 🎜🎜Il existe également une situation où le processus de brossage du disque ducheckpointest en cours avant l'arrêt, et la progression du brossage du disque de la page de données dépasse la progression du brossage du disque de la page de journal à ce moment. , un enregistrement dans la page de données apparaîtra. LeLSNest supérieur auLSNdans le journal. À ce moment, la partie qui dépasse la progression du journal ne sera pas. être refait, car cela représente en soi ce qui a été fait et n'a pas besoin d'être refait. 🎜La différence entre redo log et binlog
🎜binlogetredo lognous pouvons savoir :binloglog est uniquement utilisé pour l'archivage et s'appuie uniquement surbinloget n'a pas la capacitécrash-safe. 🎜Mais seul le
redo logne fonctionnera pas, car leredo logest unique àInnoDB, et les enregistrements du journal seront écrasés après avoir été écrits. sur le disque. Par conséquent,binlogetredo logdoivent être enregistrés en même temps pour garantir que lorsque la base de données est arrêtée et redémarrée, les données ne seront pas perdues.redo log也不行,因为redo log是InnoDB特有的,且日志上的记录落盘后会被覆盖掉。因此需要binlog和redo log二者同时记录,才能保证当数据库发生宕机重启时,数据不会丢失。undo log
数据库事务四大特性中有一个是原子性,具体来说就是原子性是指对数据库的一系列操作,要么全部成功,要么全部失败,不可能出现部分成功的情况。
实际上,原子性底层就是通过
undo log实现的。undo log主要记录了数据的逻辑变化,比如一条INSERT语句,对应一条DELETE的undo log,对于每个UPDATE语句,对应一条相反的UPDATE的undo log,这样在发生错误时,就能回滚到事务之前的数据状态。同时,
undo log也是MVCCannuler le journal
L'une des quatre caractéristiques majeures des transactions de base de données est l'atomicité. Plus précisément, l'atomicité fait référence à une série d'opérations sur la base de données, soit toutes réussissent, soit toutes échouent, et les opérations partielles sont impossibles. situation. 🎜🎜En fait, la couche inférieure de l'atomicité est obtenue viaundo log. Leundo logenregistre principalement les modifications logiques des données. Par exemple, une instructionINSERTcorrespond auundo logd'unDELETEcode> Pour chaque instruction <code>UPDATE, il existe unundo logcorrespondant duUPDATEopposé, de sorte que lorsqu'une erreur se produit, vous pouvez lancer. revenir à la transaction précédente. 🎜🎜Dans le même temps, leundo logest également la clé de la mise en œuvre deMVCC(contrôle de concurrence multi-version). 🎜
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
La construction d'une base de données SQL comprend 10 étapes: sélectionner des SGBD; Installation de SGBD; créer une base de données; créer une table; insérer des données; récupération de données; Mise à jour des données; supprimer des données; gérer les utilisateurs; sauvegarde de la base de données.
