

Comment créer un cluster Redis sous Centos

Outils essentiels :
redis-3.0.0.tar
redis-3.0.0.gem (interface ruby et redis)
Analyse :
Tout d'abord, le nombre de clusters nécessite une base. Voici un cluster Redis simple configuré (6 instances Redis regroupées).
Fonctionne sur un seul serveur, donc seulement 6 numéros de port différents sont requis. Ce sont : 7001, 7002, 7003, 7004, 7005, 7006.
Étapes :
1. Téléchargez redis-3.0.0.tar sur le serveur (spécifiez votre propre répertoire de logiciels) et décompressez redis-3.0.0.tar.
2. Installez l'environnement de langage C (après avoir installé Centos, il est fourni avec l'environnement de langage C)
yum install gcc-c++
3 Entrez dans le répertoire redis-3.0.0
make
4 Installez Redis dans /usr/local/redis. répertoire
make install prefix=/usr/local/redis
5. Vérifiez si l'installation a réussi (le répertoire bin apparaîtra)

6. Démarrez redis sur le front-end (entrez le répertoire bin dans l'image ci-dessus)
./redis-server ( open)
./redis-cli shutdown (Fermer)

7. Démarrage du backend
Vous devez copier le fichier redis.conf dans le package de code source décompressé redis (sous le répertoire redis-3.0.0) dans le répertoire bin
Modifiez le fichier redis.conf Pour changer démoniser en oui, vous devez d'abord utiliser vim redis.conf
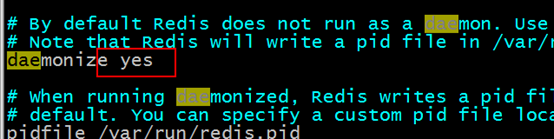
Utilisez le backend de commande pour démarrer redis
Exécuter dans le répertoire bin./redis- serveur redis.conf
Vérifiez si le démarrage a réussi

Après la fermeture Comment démarrer le terminal :
./redis-cli shutdown
Ce qui précède est une installation redis distincte, puis créez un cluster !
Installez ruby
yum install ruby yum install rubygems
Téléchargez les fichiers suivants sur le système Linux
redis-3.0.0.gem (interface ruby et redis)
Entrez dans le répertoire et exécutez : gem install redis-3.0.0. gem
Copiez les fichiers suivants dans le répertoire src sous le package redis-3.0.0 dans /usr/local/redis/redis-cluster/
Prérequis : créez d'abord un nouveau répertoire redis-cluster

C'est au moins nécessaire pour construire un cluster 3 hôtes Si chaque hôte est configuré avec une machine esclave, au moins 6 machines sont requises.
La conception du port est la suivante : 7001-7006
Étape 1 : Copiez une machine 7001
Entrez le répertoire /usr/local/redis/ et exécutez cp bin ./redis-cluster/7001 –r
Étape 2 : S'il y a un fichier persistant, supprimez-le
rm -rf appendonly.aof dump.rdb
La troisième étape : Définir les paramètres du cluster

La quatrième étape : Modifier le port
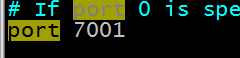
La cinquième étape : Copier la machine 7002-7006
Donnez-moi le système de bureau La structure des répertoires ci-dessous :
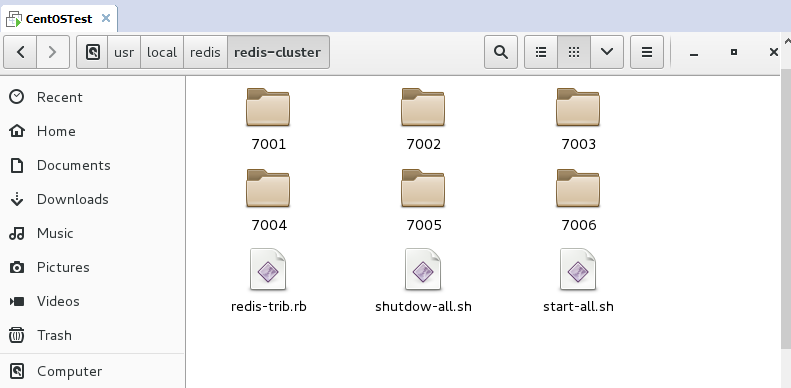
Ensuite, configurez en un clic pour démarrer tous les redis ou fermez le groupe redis :
Tout d'abord, créez un nouveau fichier. Vous pouvez utiliser vim pour ouvrir un fichier. cela n’existe pas, puis enregistrez-le et il existera. (Les start-all.sh et shutdown-all.sh dans l'image ci-dessus sont les nouveaux que j'ai créés)
start-all.sh:
cd 7001 ./redis-server redis.conf cd .. cd 7002 ./redis-server redis.conf cd .. cd 7003 ./redis-server redis.conf cd .. cd 7004 ./redis-server redis.conf cd .. cd 7005 ./redis-server redis.conf cd .. cd 7006 ./redis-server redis.conf cd ..
shutdow-all.sh:
cd 7001 ./redis-cli -p 7001 shutdown cd .. cd 7002 ./redis-cli -p 7002 shutdown cd .. cd 7003 ./redis-cli -p 7003 shutdown cd .. cd 7004 ./redis-cli -p 7004 shutdown cd .. cd 7005 ./redis-cli -p 7005 shutdown cd .. cd 7006 ./redis-cli -p 7006 shutdown cd ..
Ensuite, modifiez les autorisations de les deux fichiers et définissez-les. C'est un fichier de script démarrable
chmod u+x start-all.sh chmod u+x shutdown-all.sh
Ensuite, utilisez Ruby pour connecter ces clusters et les gérer
/redis-trib.rb create --replicas 1 192.168.78.133:7001 192.168.78.133 : 7002 192.168.78.133:7003 192.168.78.133:7004 192.168.78.133:7005 192.168.78.133:7006
apparaît :
connecting to node 192.168.242.137:7001: ok connecting to node 192.168.242.137:7002: ok connecting to node 192.168.242.137:7003: ok connecting to node 192.168.242.137:7004: ok connecting to node 192.168.242.137:7005: ok connecting to node 192.168.242.137:7006: ok >>> performing hash slots allocation on 6 nodes... using 3 masters: 192.168.242.137:7001 192.168.242.137:7002 192.168.242.137:7003 adding replica 192.168.242.137:7004 to 192.168.242.137:7001 adding replica 192.168.242.137:7005 to 192.168.242.137:7002 adding replica 192.168.242.137:7006 to 192.168.242.137:7003 m: 8240cd0fe6d6f842faa42b0174fe7c5ddcf7ae24 192.168.242.137:7001 slots:0-5460 (5461 slots) master m: 4f52a974f64343fd9f1ee0388490b3c0647a4db7 192.168.242.137:7002 slots:5461-10922 (5462 slots) master m: cb7c5def8f61df2016b38972396a8d1f349208c2 192.168.242.137:7003 slots:10923-16383 (5461 slots) master s: 66adf006fed43b3b5e499ce2ff1949a756504a16 192.168.242.137:7004 replicates 8240cd0fe6d6f842faa42b0174fe7c5ddcf7ae24 s: cbb0c9bc4b27dd85511a7ef2d01bec90e692793b 192.168.242.137:7005 replicates 4f52a974f64343fd9f1ee0388490b3c0647a4db7 s: a908736eadd1cd06e86fdff8b2749a6f46b38c00 192.168.242.137:7006 replicates cb7c5def8f61df2016b38972396a8d1f349208c2 can i set the above configuration? (type 'yes' to accept): yes >>> nodes configuration updated >>> assign a different config epoch to each node >>> sending cluster meet messages to join the cluster waiting for the cluster to join.. >>> performing cluster check (using node 192.168.242.137:7001) m: 8240cd0fe6d6f842faa42b0174fe7c5ddcf7ae24 192.168.242.137:7001 slots:0-5460 (5461 slots) master m: 4f52a974f64343fd9f1ee0388490b3c0647a4db7 192.168.242.137:7002 slots:5461-10922 (5462 slots) master m: cb7c5def8f61df2016b38972396a8d1f349208c2 192.168.242.137:7003 slots:10923-16383 (5461 slots) master m: 66adf006fed43b3b5e499ce2ff1949a756504a16 192.168.242.137:7004 slots: (0 slots) master replicates 8240cd0fe6d6f842faa42b0174fe7c5ddcf7ae24 m: cbb0c9bc4b27dd85511a7ef2d01bec90e692793b 192.168.242.137:7005 slots: (0 slots) master replicates 4f52a974f64343fd9f1ee0388490b3c0647a4db7 m: a908736eadd1cd06e86fdff8b2749a6f46b38c00 192.168.242.137:7006 slots: (0 slots) master replicates cb7c5def8f61df2016b38972396a8d1f349208c2 [ok] all nodes agree about slots configuration. >>> check for open slots... >>> check slots coverage... [ok] all 16384 slots covered.
signifie succès !
Testez-le, entrez dans le répertoire 7001 et exécutez : ./redis-cli -h 192.168.242.137 -p 7001 –c
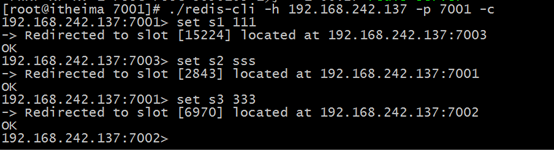
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment optimiser la configuration CentOS HDFS
Apr 14, 2025 pm 07:15 PM
Comment optimiser la configuration CentOS HDFS
Apr 14, 2025 pm 07:15 PM
Améliorer les performances HDFS sur CentOS: un guide d'optimisation complet pour optimiser les HDF (système de fichiers distribué Hadoop) sur CentOS nécessite une considération complète du matériel, de la configuration du système et des paramètres réseau. Cet article fournit une série de stratégies d'optimisation pour vous aider à améliorer les performances du HDFS. 1. Expansion de la mise à niveau matérielle et des ressources de sélection: augmentez autant que possible le CPU, la mémoire et la capacité de stockage du serveur. Matériel haute performance: adopte les cartes réseau et les commutateurs de réseau haute performance pour améliorer le débit du réseau. 2. Configuration du système Réglage des paramètres du noyau à réglage fin: Modifier /etc/sysctl.conf Fichier pour optimiser les paramètres du noyau tels que le numéro de connexion TCP, le numéro de manche de fichier et la gestion de la mémoire. Par exemple, ajustez l'état de la connexion TCP et la taille du tampon
 Centos arrête la maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos arrête la maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos sera fermé en 2024 parce que sa distribution en amont, Rhel 8, a été fermée. Cette fermeture affectera le système CentOS 8, l'empêchant de continuer à recevoir des mises à jour. Les utilisateurs doivent planifier la migration et les options recommandées incluent CentOS Stream, Almalinux et Rocky Linux pour garder le système en sécurité et stable.
 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Adresse IP de configuration CentOS
Apr 14, 2025 pm 09:06 PM
Adresse IP de configuration CentOS
Apr 14, 2025 pm 09:06 PM
Étapes pour configurer l'adresse IP dans CENTOS: Afficher la configuration du réseau actuel: IP ADDR Modifier le fichier de configuration du réseau: Sudo VI / etc.
 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Quelles étapes sont nécessaires pour configurer CentOS dans HDFS
Apr 14, 2025 pm 06:42 PM
Quelles étapes sont nécessaires pour configurer CentOS dans HDFS
Apr 14, 2025 pm 06:42 PM
La construction d'un système de fichiers distribué Hadoop (HDFS) sur un système CENTOS nécessite plusieurs étapes. Cet article fournit un bref guide de configuration. 1. Préparez-vous à installer JDK à la première étape: installez JavadeEvelopmentKit (JDK) sur tous les nœuds, et la version doit être compatible avec Hadoop. Le package d'installation peut être téléchargé à partir du site officiel d'Oracle. Configuration des variables d'environnement: Edit / etc / Profile File, définissez les variables d'environnement Java et Hadoop, afin que le système puisse trouver le chemin d'installation de JDK et Hadoop. 2. Configuration de sécurité: Connexion sans mot de passe SSH pour générer une clé SSH: Utilisez la commande SSH-Keygen sur chaque nœud
 Comment installer Redis dans CentOS7
Apr 14, 2025 pm 08:21 PM
Comment installer Redis dans CentOS7
Apr 14, 2025 pm 08:21 PM
Téléchargez le package de code source à partir de la source Redis officielle pour le compiler et l'installer pour assurer la version la plus récente et stable et peut être personnalisée de manière personnalisée. Les étapes spécifiques sont les suivantes: Mettez à jour la liste des packages logiciels et créez le répertoire redis Télécharger Reded Code source Package Décompressez le package de code source et compilez la configuration d'installation et modifiez la configuration redis pour démarrer Redis vérifiez l'état de démarrage
