
 Périphériques technologiques
IA
L'inférence LLM est 3 fois plus rapide ! Microsoft lance LLM Accelerator : utiliser un texte de référence pour obtenir une accélération sans perte
Périphériques technologiques
IA
L'inférence LLM est 3 fois plus rapide ! Microsoft lance LLM Accelerator : utiliser un texte de référence pour obtenir une accélération sans perte
L'inférence LLM est 3 fois plus rapide ! Microsoft lance LLM Accelerator : utiliser un texte de référence pour obtenir une accélération sans perte

Avec le développement rapide de la technologie de l'intelligence artificielle, de nouveaux produits et technologies tels que ChatGPT, New Bing et GPT-4 ont été lancés les uns après les autres et joueront un rôle de plus en plus important dans de nombreuses applications.
La plupart des grands modèles linguistiques actuels sont des modèles autorégressifs. L'autorégression signifie que le modèle utilise souvent une sortie mot par mot lors de la sortie, c'est-à-dire que lors de la sortie de chaque mot, le modèle doit utiliser les mots précédemment générés comme entrée. Ce mode autorégressif restreint généralement la pleine utilisation des accélérateurs parallèles pendant la sortie.
Dans de nombreux scénarios d'application, la sortie d'un grand modèle présente souvent une grande similitude avec certains textes de référence, comme dans les trois scénarios courants suivants :
1. Génération améliorée par récupération
Quand. les applications de recherche telles que New Bing répondent aux entrées de l'utilisateur, elles renverront d'abord certaines informations liées à l'entrée de l'utilisateur, puis utiliseront un modèle de langage pour résumer les informations récupérées, puis répondront à l'entrée de l'utilisateur. Dans ce scénario, la sortie du modèle contient souvent un grand nombre de fragments de texte issus des résultats de recherche.
2. Utiliser la génération en cache
Dans le processus de déploiement à grande échelle de modèles de langage, les entrées et sorties historiques seront mises en cache. Lors du traitement d'une nouvelle entrée, l'application de récupération recherche une entrée similaire dans le cache. Par conséquent, la sortie du modèle est souvent très similaire à la sortie correspondante dans le cache.
3. Génération dans des conversations à plusieurs tours
Lors de l'utilisation d'applications telles que ChatGPT, les utilisateurs font souvent des demandes de modifications répétées en fonction de la sortie du modèle. Dans ce scénario de dialogue à plusieurs tours, les multiples résultats du modèle ne comportent souvent qu'un faible degré de changement et un degré élevé de répétition.
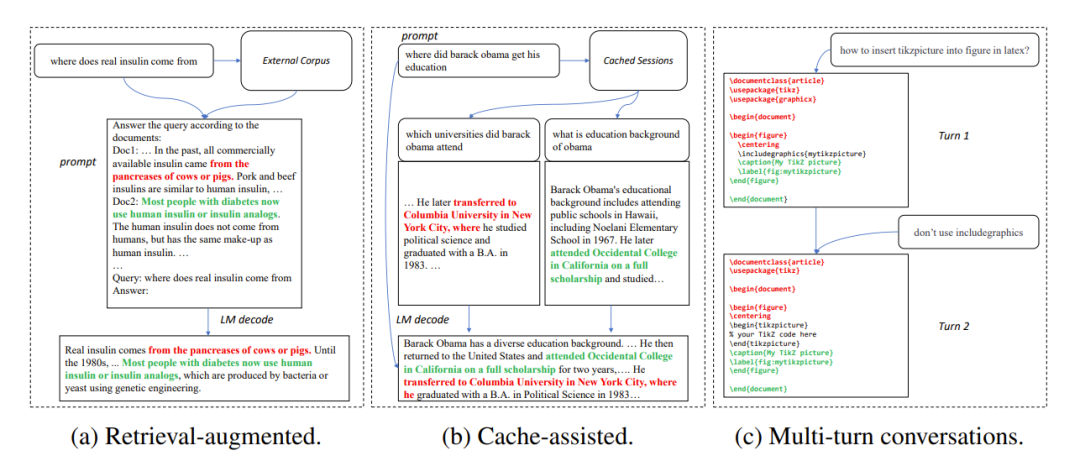
Figure 1 : Scénarios courants dans lesquels la sortie d'un grand modèle est similaire au texte de référence
Sur la base des observations ci-dessus, les chercheurs ont utilisé la répétabilité du texte de référence et du modèle la sortie comme une percée dans l'autorégression En nous concentrant sur le goulot d'étranglement, nous espérons améliorer l'utilisation des accélérateurs parallèles et accélérer le raisonnement sur de grands modèles de langage, puis proposer une méthode LLM Accelerator qui utilise la répétition de la sortie et du texte de référence pour produire plusieurs mots en une seule étape .
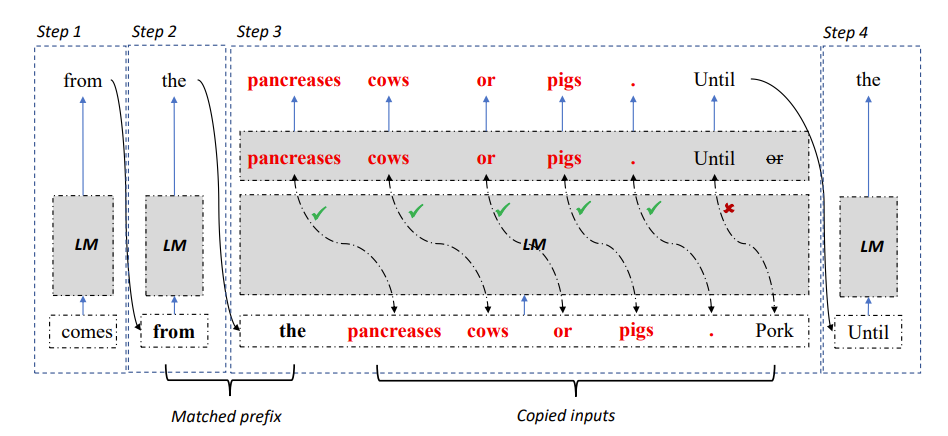
Figure 2 : Algorithme de décodage de l'accélérateur LLM
Plus précisément, à chaque étape de décodage, laissez le modèle correspondre d'abord aux résultats de sortie existants et au texte de référence si une référence est trouvée Si le texte. correspond à la sortie existante, le modèle continuera probablement à générer le texte de référence existant.
Par conséquent, les chercheurs ont ajouté les mots suivants du texte de référence comme entrée au modèle, de sorte qu'une étape de décodage puisse produire plusieurs mots.
Afin de garantir l'exactitude des entrées et des sorties, les chercheurs ont ensuite comparé les mots produits par le modèle avec les mots entrés dans le document de référence. Si les deux sont incohérents, les résultats d’entrée et de sortie incorrects seront ignorés.
La méthode ci-dessus peut garantir que les résultats de décodage sont complètement cohérents avec la méthode de base et peut augmenter le nombre de mots de sortie dans chaque étape de décodage, obtenant ainsi une accélération sans perte de l'inférence de grand modèle.
LLM Accelerator ne nécessite pas de modèles auxiliaires supplémentaires, est simple à utiliser et peut être facilement déployé dans divers scénarios d'application.
Lien papier : https://arxiv.org/pdf/2304.04487.pdf
Lien du projet : https://github.com/microsoft/LMOps
Utilisation de LLM Accelerator, Il y a deux hyperparamètres qui doivent être réglés.
Premièrement, le nombre de mots correspondants entre la sortie requise pour déclencher le mécanisme de correspondance et le texte de référence : plus le nombre de mots correspondants est long, plus il est précis, ce qui peut mieux garantir que les mots copiés à partir du texte de référence sont sortie correcte, réduisant les déclenchements et calculs inutiles ; correspondances plus courtes, moins d'étapes de décodage, accélération potentiellement plus rapide.
Le deuxième est le nombre de mots copiés à chaque fois : plus il y a de mots copiés, plus le potentiel d'accélération est grand, mais cela peut également entraîner la suppression d'un plus grand nombre de résultats incorrects, ce qui gaspille des ressources informatiques. Les chercheurs ont découvert grâce à des expériences que des stratégies plus agressives (faire correspondre des déclencheurs d'un seul mot, copier 15 à 20 mots à la fois) peuvent souvent atteindre de meilleurs taux d'accélération.
Afin de vérifier l'efficacité de LLM Accelerator, les chercheurs ont mené des expériences sur l'amélioration de la récupération et la génération assistée par cache, et ont construit des échantillons expérimentaux à l'aide de l'ensemble de données de récupération de paragraphe MS-MARCO.
Dans l'expérience d'amélioration de la récupération, les chercheurs ont utilisé le modèle de récupération pour renvoyer les 10 documents les plus pertinents pour chaque requête, puis les ont intégrés à la requête comme entrée du modèle, en utilisant ces 10 documents comme texte de référence.
Dans l'expérience de génération assistée par cache, chaque requête génère quatre requêtes similaires, puis utilise le modèle pour générer la requête correspondante comme texte de référence.
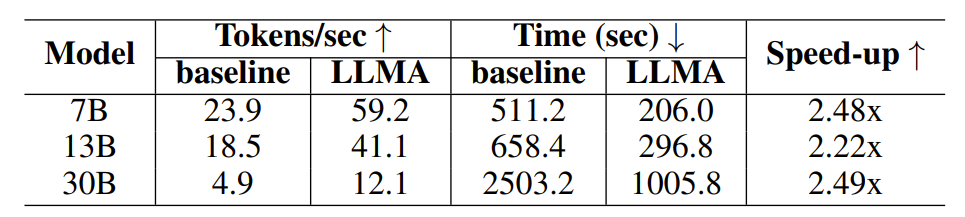
Tableau 1 : Comparaison temporelle dans le scénario de génération améliorée par récupération
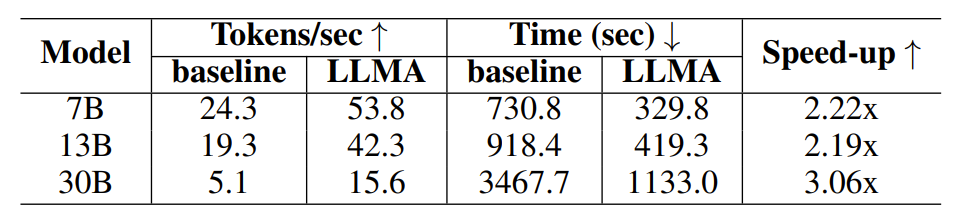
Tableau 2 : Comparaison temporelle dans le scénario de génération utilisant le cache
Le les chercheurs ont utilisé la sortie du modèle Davinci-003 obtenue via l'interface OpenAI comme sortie cible pour obtenir une sortie de haute qualité. Après avoir obtenu les entrées, sorties et textes de référence requis, les chercheurs ont mené des expériences sur le modèle de langage open source LLaMA.
Étant donné que la sortie du modèle LLaMA est incompatible avec la sortie Davinci-003, les chercheurs ont utilisé une méthode de décodage orientée objectif pour tester le rapport d'accélération sous la sortie idéale (résultat du modèle Davinci-003).
Les chercheurs ont utilisé l'algorithme 2 pour obtenir les étapes de décodage nécessaires pour générer la sortie cible lors du décodage gourmand, et ont forcé le modèle LLaMA à décoder en fonction des étapes de décodage obtenues.

Figure 3 : Utilisation de l'algorithme 2 pour obtenir les étapes de décodage requises pour générer la sortie cible lors du décodage gourmand
Pour les modèles avec des quantités de paramètres de 7B et 13B, les chercheurs ont utilisé un seul Les expériences NVIDIA 32G sont menées sur le GPU V100 ; pour un modèle avec une taille de paramètre de 30 B, les expériences sont menées sur quatre GPU identiques. Toutes les expériences utilisent des nombres à virgule flottante demi-précision, le décodage est un décodage gourmand et la taille du lot est de 1.
Les résultats expérimentaux montrent que LLM Accelerator a atteint deux à trois fois le taux d'accélération dans différentes tailles de modèle (7B, 13B, 30B) et différents scénarios d'application (amélioration de la récupération, assistance au cache).
Une analyse expérimentale plus approfondie a révélé que LLM Accelertator peut réduire considérablement les étapes de décodage requises et que le taux d'accélération est positivement corrélé au taux de réduction des étapes de décodage.
D'une part, moins d'étapes de décodage signifie que chaque étape de décodage génère plus de mots de sortie, ce qui peut améliorer l'efficacité des calculs GPU, d'autre part, pour le modèle 30B qui nécessite un parallélisme multi-cartes, cela signifie ; plus Moins de cartes multiples peuvent être synchronisées pour obtenir une amélioration plus rapide de la vitesse.
Dans l'expérience d'ablation, les résultats de l'analyse des hyperparamètres de LLM Accelertator sur l'ensemble de développement ont montré que lors de la correspondance d'un seul mot (c'est-à-dire en déclenchant le mécanisme de copie), le taux d'accélération peut atteindre le maximum lors de la copie de 15 à 20 mots à la fois (illustré dans la figure 4).
Dans la figure 5, nous pouvons voir que le nombre de mots correspondants est de 1, ce qui peut déclencher davantage le mécanisme de copie, et à mesure que la longueur de la copie augmente, les mots de sortie acceptés par chaque étape de décodage augmentent et les étapes de décodage diminuent, ainsi atteindre un taux d'accélération plus élevé.
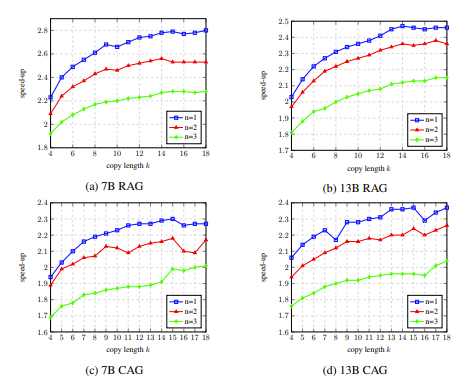
Figure 4 : Dans l'expérience d'ablation, les résultats de l'analyse des hyperparamètres de l'accélérateur LLM sur l'ensemble de développement
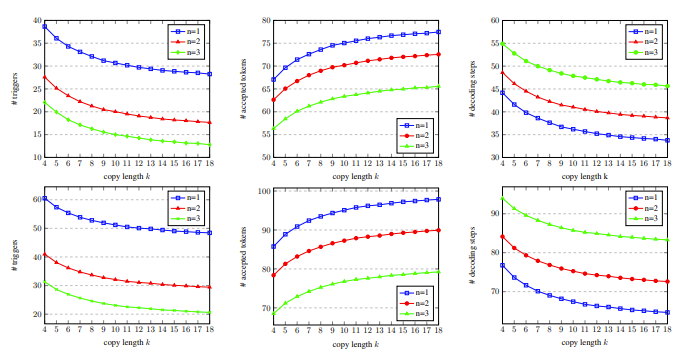
Figure 5 : Sur l'ensemble de développement , avec des données statistiques sur les étapes de décodage pour différents nombres de mots correspondants n et nombre de mots copiés k
LLM Accelertator fait partie de la série de travaux du Microsoft Research Asia Natural Language Computing Group sur l'accélération des grands modèles de langage. les chercheurs continueront d'étudier les questions connexes. Explorez plus en profondeur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Adresse d'entrée de la version internationale de Microsoft Bing (entrée du moteur de recherche Bing)
Mar 14, 2024 pm 01:37 PM
Adresse d'entrée de la version internationale de Microsoft Bing (entrée du moteur de recherche Bing)
Mar 14, 2024 pm 01:37 PM
Bing est un moteur de recherche en ligne lancé par Microsoft. La fonction de recherche est très puissante et comporte deux entrées : la version nationale et la version internationale. Où sont les entrées de ces deux versions ? Comment accéder à la version internationale ? Jetons un coup d'œil aux détails ci-dessous. Entrée du site Web de la version chinoise de Bing : https://cn.bing.com/ Entrée du site Web de la version internationale de Bing : https://global.bing.com/ Comment accéder à la version internationale de Bing ? 1. Entrez d'abord l'URL pour ouvrir Bing : https://www.bing.com/ 2. Vous pouvez voir qu'il existe des options pour les versions nationales et internationales. Il suffit de sélectionner la version internationale et de saisir les mots-clés.
 Microsoft publie la mise à jour cumulative Win11 août : amélioration de la sécurité, optimisation de l'écran de verrouillage, etc.
Aug 14, 2024 am 10:39 AM
Microsoft publie la mise à jour cumulative Win11 août : amélioration de la sécurité, optimisation de l'écran de verrouillage, etc.
Aug 14, 2024 am 10:39 AM
Selon les informations de ce site du 14 août, lors de la journée d'événement Patch Tuesday d'aujourd'hui, Microsoft a publié des mises à jour cumulatives pour les systèmes Windows 11, notamment la mise à jour KB5041585 pour 22H2 et 23H2 et la mise à jour KB5041592 pour 21H2. Après l'installation de l'équipement mentionné ci-dessus avec la mise à jour cumulative d'août, les changements de numéro de version attachés à ce site sont les suivants : Après l'installation de l'équipement 21H2, le numéro de version est passé à Build22000.314722H2. le numéro de version est passé à Build22621.403723H2. Après l'installation de l'équipement, le numéro de version est passé à Build22631.4037. Le contenu principal de la mise à jour KB5041585 pour Windows 1121H2 est le suivant : Amélioration : Amélioré.
 Mise à niveau de Microsoft Edge : la fonction de sauvegarde automatique du mot de passe interdite ? ! Les utilisateurs ont été choqués !
Apr 19, 2024 am 08:13 AM
Mise à niveau de Microsoft Edge : la fonction de sauvegarde automatique du mot de passe interdite ? ! Les utilisateurs ont été choqués !
Apr 19, 2024 am 08:13 AM
Actualités du 18 avril : Récemment, certains utilisateurs du navigateur Microsoft Edge utilisant le canal Canary ont signalé qu'après la mise à niveau vers la dernière version, ils avaient constaté que l'option d'enregistrement automatique des mots de passe était désactivée. Après enquête, il a été constaté qu'il s'agissait d'un ajustement mineur après la mise à niveau du navigateur, plutôt que d'une suppression de fonctionnalités. Avant d'utiliser le navigateur Edge pour accéder à un site Web, les utilisateurs ont signalé que le navigateur ouvrait une fenêtre leur demandant s'ils souhaitaient enregistrer le mot de passe de connexion au site Web. Après avoir choisi d'enregistrer, Edge remplira automatiquement le numéro de compte et le mot de passe enregistrés lors de votre prochaine connexion, offrant ainsi aux utilisateurs une grande commodité. Mais la dernière mise à jour ressemble à un ajustement, modifiant les paramètres par défaut. Les utilisateurs doivent choisir d'enregistrer le mot de passe, puis activer manuellement le remplissage automatique du compte et du mot de passe enregistrés dans les paramètres.
 La fenêtre contextuelle plein écran de Microsoft exhorte les utilisateurs de Windows 10 à se dépêcher et à passer à Windows 11
Jun 06, 2024 am 11:35 AM
La fenêtre contextuelle plein écran de Microsoft exhorte les utilisateurs de Windows 10 à se dépêcher et à passer à Windows 11
Jun 06, 2024 am 11:35 AM
Selon l'actualité du 3 juin, Microsoft envoie activement des notifications en plein écran à tous les utilisateurs de Windows 10 pour les encourager à passer au système d'exploitation Windows 11. Ce déplacement concerne les appareils dont les configurations matérielles ne prennent pas en charge le nouveau système. Depuis 2015, Windows 10 occupe près de 70 % des parts de marché, établissant ainsi sa domination en tant que système d'exploitation Windows. Cependant, la part de marché dépasse largement la part de marché de 82 %, et la part de marché dépasse largement celle de Windows 11, qui sortira en 2021. Même si Windows 11 est lancé depuis près de trois ans, sa pénétration sur le marché est encore lente. Microsoft a annoncé qu'il mettrait fin au support technique de Windows 10 après le 14 octobre 2025 afin de se concentrer davantage sur
 La fonction de compression des fichiers 7z et TAR de Microsoft Win11 a été rétrogradée des versions 24H2 aux versions 23H2/22H2
Apr 28, 2024 am 09:19 AM
La fonction de compression des fichiers 7z et TAR de Microsoft Win11 a été rétrogradée des versions 24H2 aux versions 23H2/22H2
Apr 28, 2024 am 09:19 AM
Selon les informations de ce site le 27 avril, Microsoft a publié la mise à jour de la version préliminaire de Windows 11 Build 26100 sur les canaux Canary et Dev plus tôt ce mois-ci, qui devrait devenir une version RTM candidate de la mise à jour Windows 1124H2. Les principaux changements de la nouvelle version sont l'explorateur de fichiers, l'intégration de Copilot, l'édition des métadonnées des fichiers PNG, la création de fichiers compressés TAR et 7z, etc. @PhantomOfEarth a découvert que Microsoft a délégué certaines fonctions de la version 24H2 (Germanium) à la version 23H2/22H2 (Nickel), comme la création de fichiers compressés TAR et 7z. Comme le montre le schéma, Windows 11 prendra en charge la création native de TAR
 Mise à jour du navigateur Microsoft Edge : ajout de la fonction 'zoomer sur l'image' pour améliorer l'expérience utilisateur
Mar 21, 2024 pm 01:40 PM
Mise à jour du navigateur Microsoft Edge : ajout de la fonction 'zoomer sur l'image' pour améliorer l'expérience utilisateur
Mar 21, 2024 pm 01:40 PM
Selon l'actualité du 21 mars, Microsoft a récemment mis à jour son navigateur Microsoft Edge et ajouté une fonction pratique « agrandir l'image ». Désormais, lorsqu'ils utilisent le navigateur Edge, les utilisateurs peuvent facilement trouver cette nouvelle fonctionnalité dans le menu contextuel en cliquant simplement avec le bouton droit sur l'image. Ce qui est plus pratique, c'est que les utilisateurs peuvent également passer le curseur sur l'image, puis double-cliquer sur la touche Ctrl pour appeler rapidement la fonction de zoom avant sur l'image. Selon la compréhension de l'éditeur, le nouveau navigateur Microsoft Edge a été testé pour les nouvelles fonctionnalités du canal Canary. La version stable du navigateur a également officiellement lancé la fonction pratique « agrandir l'image », offrant aux utilisateurs une expérience de navigation d'images plus pratique. Les médias scientifiques et technologiques étrangers y ont également prêté attention.
 Microsoft prévoit de supprimer progressivement NTLM dans Windows 11 au second semestre 2024 et de passer entièrement à l'authentification Kerberos
Jun 09, 2024 pm 04:17 PM
Microsoft prévoit de supprimer progressivement NTLM dans Windows 11 au second semestre 2024 et de passer entièrement à l'authentification Kerberos
Jun 09, 2024 pm 04:17 PM
Au second semestre 2024, le blog officiel de sécurité Microsoft a publié un message en réponse à l'appel de la communauté de la sécurité. La société prévoit d'éliminer le protocole d'authentification NTLAN Manager (NTLM) dans Windows 11, publié au second semestre 2024, pour améliorer la sécurité. Selon des explications précédentes, Microsoft a déjà pris des mesures similaires auparavant. Le 12 octobre dernier, Microsoft a proposé un plan de transition dans un communiqué de presse officiel visant à supprimer progressivement les méthodes d'authentification NTLM et à inciter davantage d'entreprises et d'utilisateurs à passer à Kerberos. Pour aider les entreprises susceptibles de rencontrer des problèmes avec les applications et services câblés après avoir désactivé l'authentification NTLM, Microsoft fournit IAKerb et
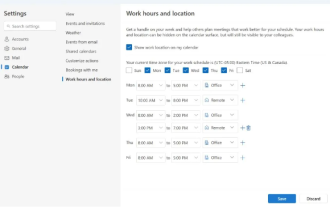 Microsoft lance une nouvelle version d'Outlook pour Windows : mise à niveau complète des fonctions de calendrier
Apr 27, 2024 pm 03:44 PM
Microsoft lance une nouvelle version d'Outlook pour Windows : mise à niveau complète des fonctions de calendrier
Apr 27, 2024 pm 03:44 PM
Dans l'actualité du 27 avril, Microsoft a annoncé qu'il publierait bientôt un test d'une nouvelle version du client Outlook pour Windows. Cette mise à jour se concentre principalement sur l’optimisation de la fonction de calendrier, dans le but d’améliorer l’efficacité du travail des utilisateurs et de simplifier davantage le flux de travail quotidien. L'amélioration de la nouvelle version du client Outlook pour Windows réside dans sa fonction de gestion de calendrier plus puissante. Désormais, les utilisateurs peuvent partager plus facilement leurs horaires de travail personnels et leurs informations de localisation, ce qui rend la planification des réunions plus efficace. En outre, Outlook a également ajouté des paramètres conviviaux, permettant aux utilisateurs de configurer les réunions pour qu'elles se terminent automatiquement plus tôt ou commencent plus tard, offrant ainsi aux utilisateurs plus de flexibilité, qu'ils souhaitent changer de salle de réunion, faire une pause ou prendre une tasse de café. . selon
