
 base de données
tutoriel mysql
Quelles sont les règles de syntaxe pour les sous-requêtes dans la base de données MySQL ?
base de données
tutoriel mysql
Quelles sont les règles de syntaxe pour les sous-requêtes dans la base de données MySQL ?
Quelles sont les règles de syntaxe pour les sous-requêtes dans la base de données MySQL ?


Étant donné que nous sommes confrontés à de nombreuses données inconnues avec des dépendances lors de l'extraction des données, nous devons imbriquer une sous-requête dans l'instruction de requête. Nous devons d’abord récupérer un ensemble de données et utiliser ses résultats comme objet pour la requête suivante. Dans le "Chapitre sur les connexions de tables", nous avons déjà parlé du problème de la faible efficacité des sous-requêtes. En fait, toutes les sous-requêtes ne sont pas inefficaces. La sous-requête "WHERE" doit être exécutée à plusieurs reprises lors de la correspondance des enregistrements. recommandé ; mais si vous utilisez le jeu de résultats de la requête comme table et établissez une connexion avec d'autres tables, il s'agit d'une sous-requête de la clause "FROM". Cette méthode de sous-requête est toujours recommandée.
Introduction à la sous-requête
Une sous-requête est une instruction qui imbrique une requête dans une instruction de requête
Les instructions de requête ordinaires sont divisées en sous-requête "SELECT" , sous-requête "FROM", sous-requête "WHERE" ; (il est fortement recommandé d'utiliser la sous-requête "'FROM'")
Des exemples de sous-requêtes sont les suivants :
Requête de base salaire Informations sur les employés dont le salaire dépasse le salaire de base moyen de l'entreprise. Dans ce cas, nous l'avons déjà implémenté via des jointures de tables. Voyons maintenant comment l'implémenter à l'aide de sous-requêtes. )
SELECT
empno, ename, sal
FROM
t_emp
WHERE
sal >= (SELECT AVG(sal) FROM t_emp);
-- 正常情况下,将聚合函数作为 WHERE 子句的条件是不可以的,但是这里利用子查询与聚合函数先将平均底薪查询出来,这就变成具体的数据了
-- 这种情况下,作为 WHERE 子句的条件,就可以被使用了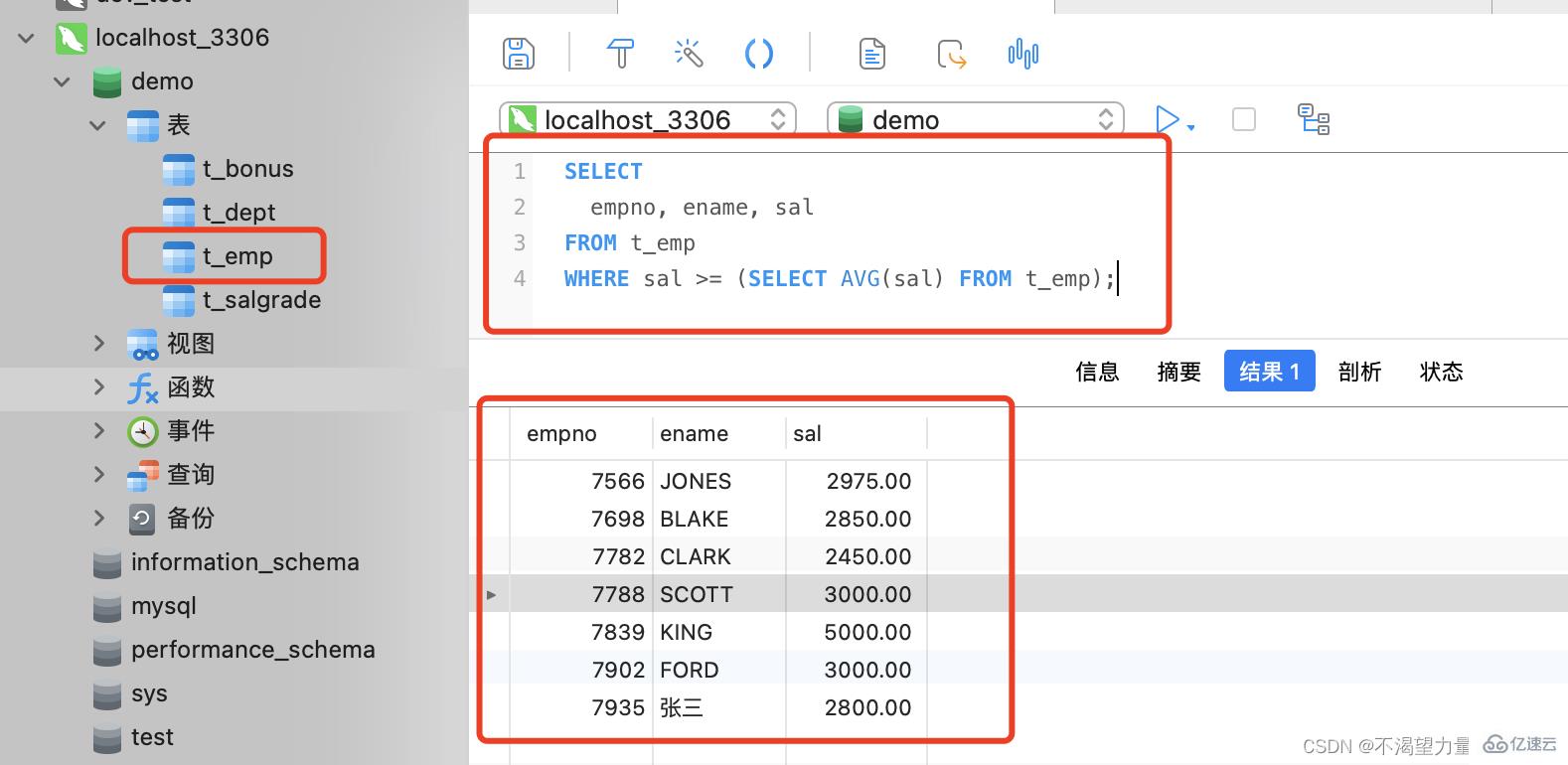
WHERE sous-requête
Lors de l'écriture d'une instruction SQL, la sous-requête WHERE la requête est la plus conforme à notre logique de pensée humaine
Bien que ce type de sous-requête soit le plus simple et le plus facile à comprendre, c'est une sous-requête très inefficace
Basé sur la requête juste démontré Parlons des salariés dont le salaire dépasse le salaire de base moyen de l’entreprise. Lorsque la clause "WHERE" compare chaque enregistrement d'employé avec la sous-requête "SELECT", la sous-requête doit être réexécutée. Si la table des employés contient 10 000 enregistrements, la sous-requête doit être exécutée 10 000 fois. Une exécution répétée autant de fois est extrêmement inefficace.

Dans l'instruction de requête, la sous-requête interrogée à plusieurs reprises est appelée "sous-requête corrélée", et la sous-requête "WHERE" appartient ici à " Sous-requête corrélée " Ce type de sous-requête doit être évité.
FROM sous-requête
Dans l'instruction de requête, la sous-requête "FROM" ne sera exécutée qu'une seule fois, ce qui est différent du "WHERE" sous-requête Au contraire, l'efficacité des requêtes est très élevée.
Prenons également comme exemple la requête d'informations sur les employés dont le salaire de base dépasse le salaire de base moyen de l'entreprise pour voir comment la sous-requête « DE » est implémentée.
SELECT
e.empno, e.ename, e.sal, t.avg
FROM t_emp e
JOIN (SELECT deptno, AVG(sal) AS avg FROM t_emp GROUP BY deptno) t
ON e.deptno = t.deptno
AND e.sal >= t.avg;
-- 首先,按照每一个部门编号去分组,然后统计部门标号与该部门对应的平均月薪。将这个结果集作为一张临时的表与员工的表做连接。
-- 连接的条件为 "员工表" 的 "部门编号" = "结果集" 的 "部门编号",并且员工的月薪大于部门的平均月薪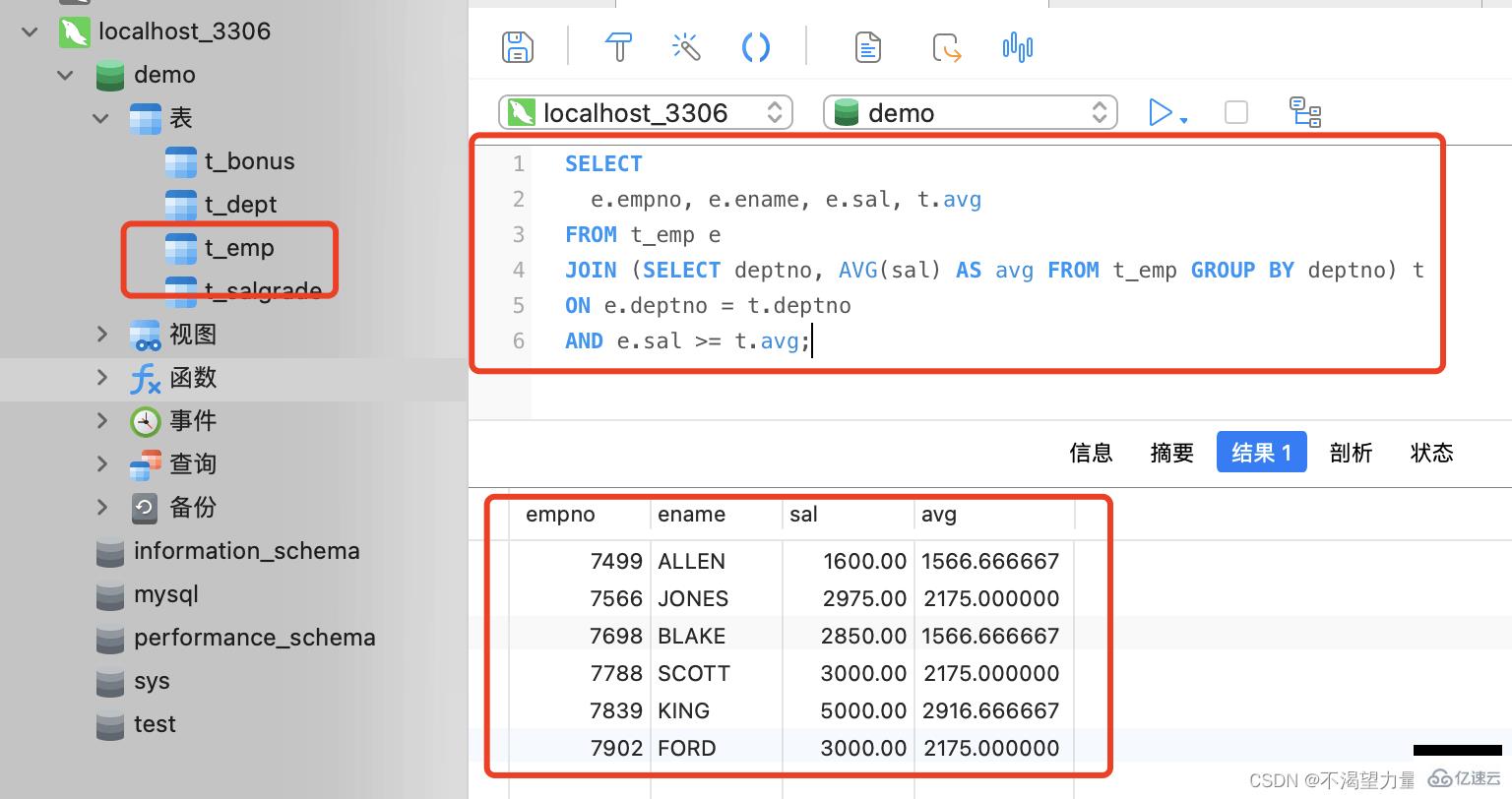
Cette question peut donc être facilement implémentée en utilisant la sous-requête "FROM", et il n'est pas nécessaire d'utiliser la sous-requête "WHERE". Étant donné que la sous-requête « FROM » n'est pas une sous-requête corrélée, ce type de sous-requête doit être limité lors de la résolution de certains problèmes.
SELECT sous-requête
Pour être honnête, je n'ai jamais vu ce genre de sous-requête dans tous les projets que j'ai vécus jusqu'à présent.
La raison est que la sous-requête "SELECT" est également une sous-requête associée. Elle sera exécutée à plusieurs reprises dans l'instruction SQL et l'efficacité de la requête est très faible.
Ici, nous allons donner un exemple : Par exemple, si nous voulons interroger les informations sur le service de chaque employé,
SELECT
e.empno,
e.ename,
(SELECT dname FROM t_dept WHERE deptno = e.deptno) AS 部门名称
FROM t_emp e;
-- 先试用 "SELECT" 子查询查询出 "部门表" 中的部门名称,约束条件为 "部门表"中的 "部门编号" 与 "员工表"中的 "部门编号" 一致
-- 将 "SELECT" 子查询得到的 "部门名称" 作为SQL语句中的一个字段进行输出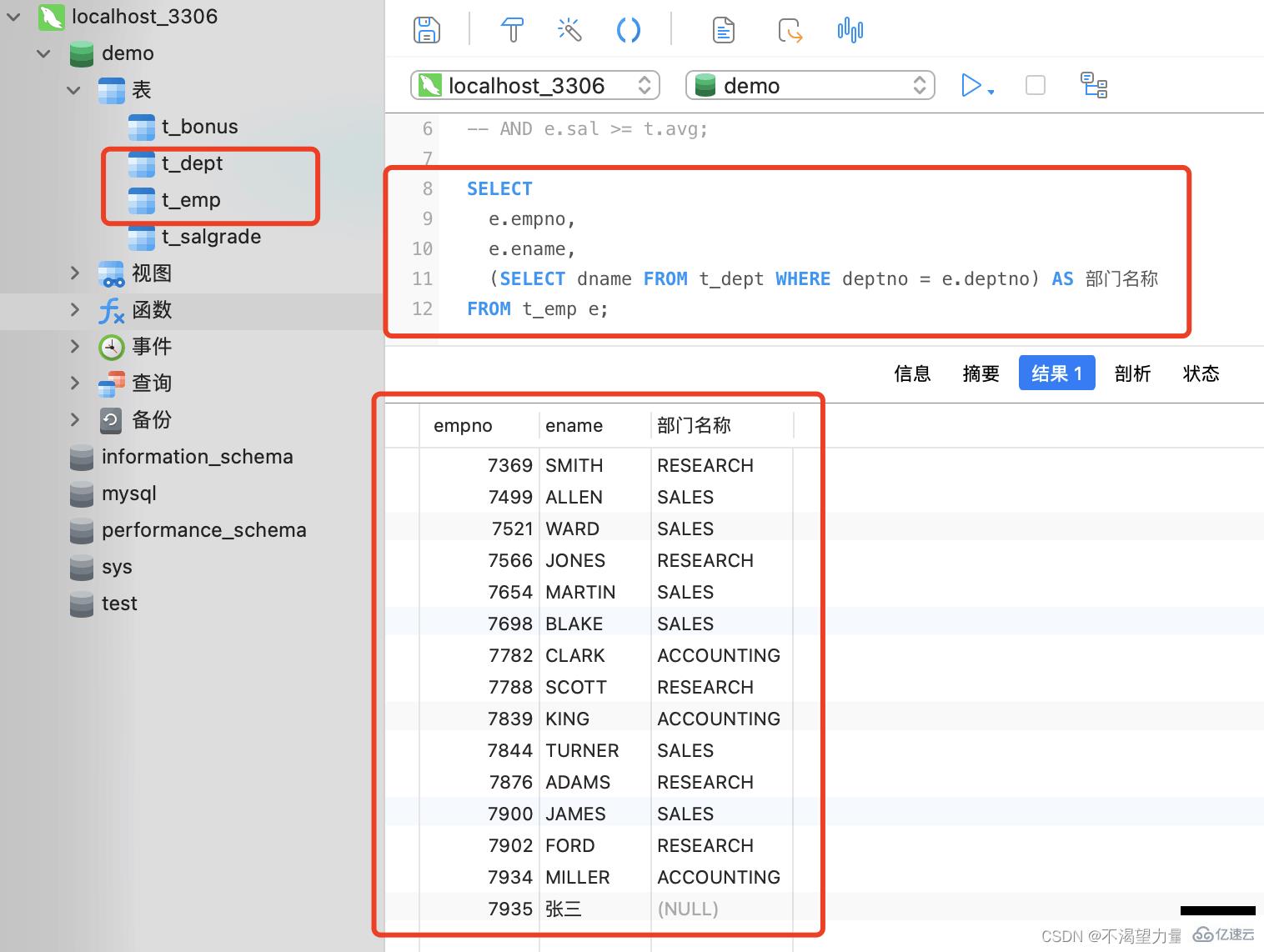
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
Dans la base de données MySQL, la relation entre l'utilisateur et la base de données est définie par les autorisations et les tables. L'utilisateur a un nom d'utilisateur et un mot de passe pour accéder à la base de données. Les autorisations sont accordées par la commande Grant, tandis que le tableau est créé par la commande Create Table. Pour établir une relation entre un utilisateur et une base de données, vous devez créer une base de données, créer un utilisateur, puis accorder des autorisations.
 MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL convient aux débutants car il est simple à installer, puissant et facile à gérer les données. 1. Installation et configuration simples, adaptées à une variété de systèmes d'exploitation. 2. Prise en charge des opérations de base telles que la création de bases de données et de tables, d'insertion, d'interrogation, de mise à jour et de suppression de données. 3. Fournir des fonctions avancées telles que les opérations de jointure et les sous-questionnaires. 4. Les performances peuvent être améliorées par l'indexation, l'optimisation des requêtes et le partitionnement de la table. 5. Prise en charge des mesures de sauvegarde, de récupération et de sécurité pour garantir la sécurité et la cohérence des données.
 Intégration RDS MySQL avec Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Intégration RDS MySQL avec Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Simplification de l'intégration des données: AmazonrDSMysQL et l'intégration Zero ETL de Redshift, l'intégration des données est au cœur d'une organisation basée sur les données. Les processus traditionnels ETL (extrait, converti, charge) sont complexes et prennent du temps, en particulier lors de l'intégration de bases de données (telles que AmazonrDSMysQL) avec des entrepôts de données (tels que Redshift). Cependant, AWS fournit des solutions d'intégration ETL Zero qui ont complètement changé cette situation, fournissant une solution simplifiée et à temps proche pour la migration des données de RDSMySQL à Redshift. Cet article plongera dans l'intégration RDSMYSQL ZERO ETL avec Redshift, expliquant comment il fonctionne et les avantages qu'il apporte aux ingénieurs de données et aux développeurs.
 Comment remplir le nom d'utilisateur MySQL et le mot de passe
Apr 08, 2025 pm 07:09 PM
Comment remplir le nom d'utilisateur MySQL et le mot de passe
Apr 08, 2025 pm 07:09 PM
Pour remplir le nom d'utilisateur et le mot de passe MySQL: 1. Déterminez le nom d'utilisateur et le mot de passe; 2. Connectez-vous à la base de données; 3. Utilisez le nom d'utilisateur et le mot de passe pour exécuter des requêtes et des commandes.
 L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
1. Utilisez l'index correct pour accélérer la récupération des données en réduisant la quantité de données numérisées SELECT * FROMMLOYEESEESHWHERELAST_NAME = 'SMITH'; Si vous recherchez plusieurs fois une colonne d'une table, créez un index pour cette colonne. If you or your app needs data from multiple columns according to the criteria, create a composite index 2. Avoid select * only those required columns, if you select all unwanted columns, this will only consume more server memory and cause the server to slow down at high load or frequency times For example, your table contains columns such as created_at and updated_at and timestamps, and then avoid selecting * because they do not require inefficient query se
 Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Navicat lui-même ne stocke pas le mot de passe de la base de données et ne peut récupérer que le mot de passe chiffré. Solution: 1. Vérifiez le gestionnaire de mots de passe; 2. Vérifiez la fonction "Remember Motway" de Navicat; 3. Réinitialisez le mot de passe de la base de données; 4. Contactez l'administrateur de la base de données.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
