

L'index clusterisé est la structure d'index basée sur la clé primaire créée par innodb par défaut, et les données de la table sont directement placées dans l'index clusterisé en tant que page de données du nœud feuille : #🎜 🎜#
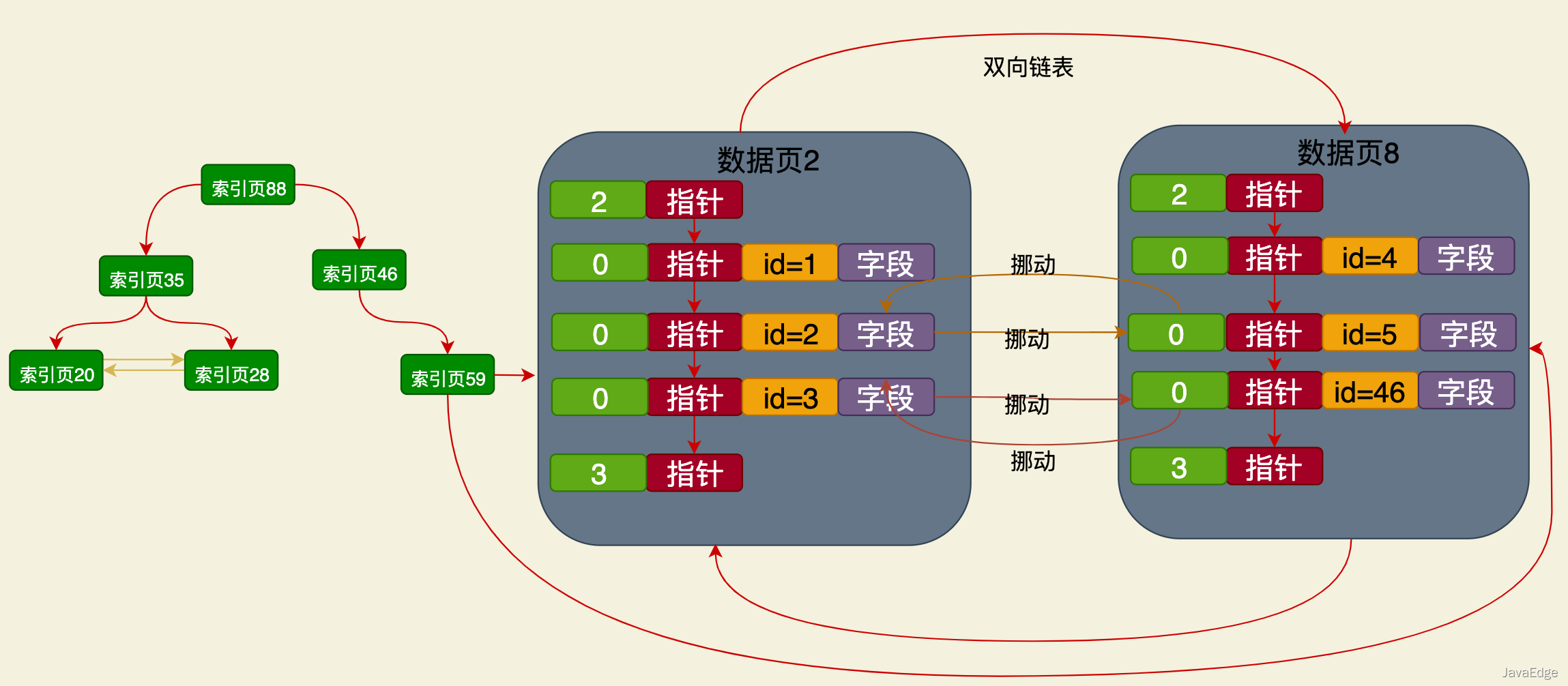
#🎜🎜 #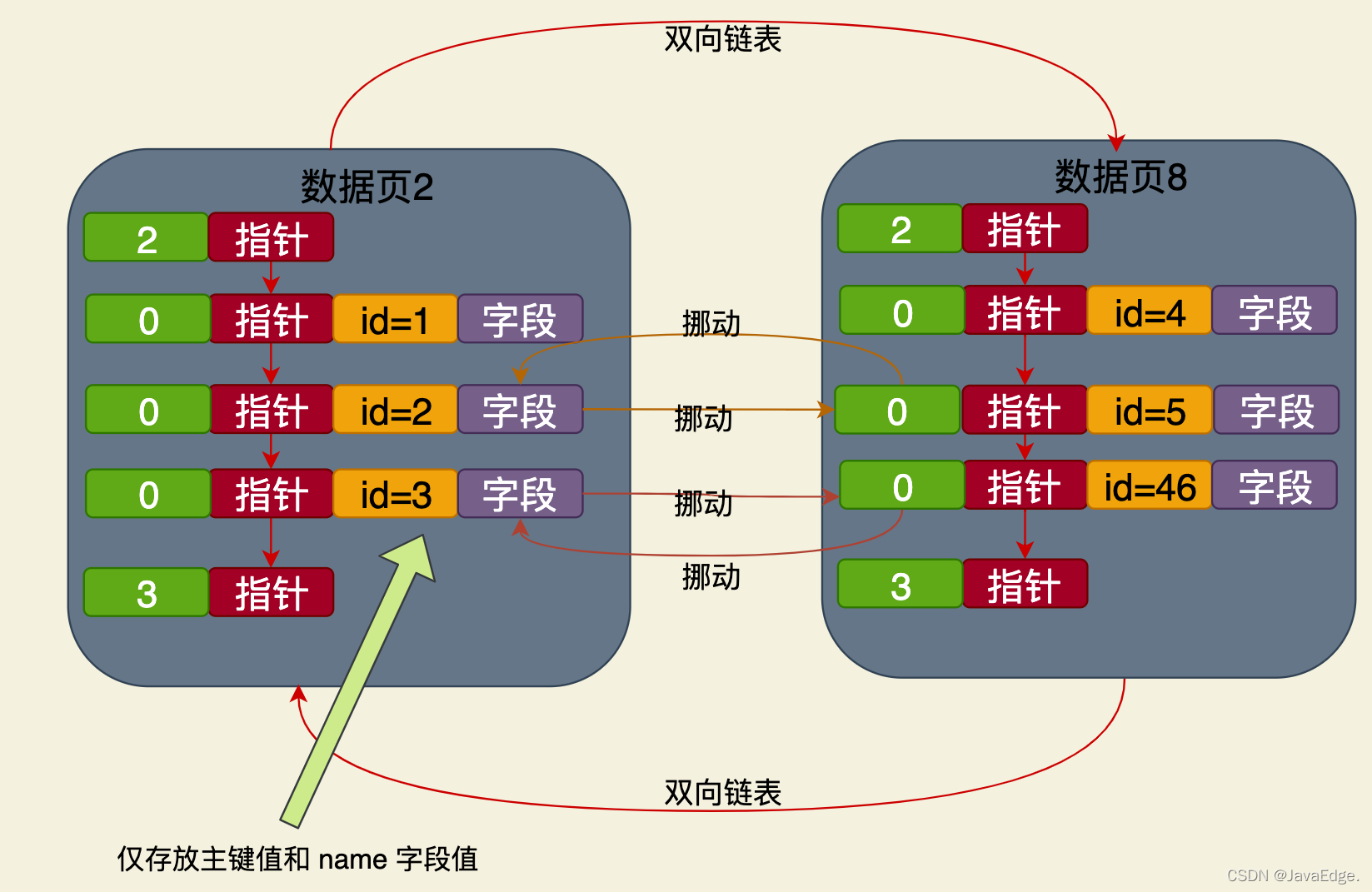 Il s'agit d'une structure d'index basée sur l'arborescence B+ dont le champ de nom est indépendant de l'index clusterisé. Les données stockées dans ses nœuds feuilles. contient uniquement les valeurs de la clé primaire et du champ nom.
Il s'agit d'une structure d'index basée sur l'arborescence B+ dont le champ de nom est indépendant de l'index clusterisé. Les données stockées dans ses nœuds feuilles. contient uniquement les valeurs de la clé primaire et du champ nom.
Les règles de tri globales sont les mêmes que les règles de tri de l'index clusterisé selon la clé primaire, soit :
# 🎜🎜#
L'arbre d'index B+ du champ nom construira également une page d'index multi-niveaux. La page d'index stocke :Numéro de page de niveau suivant# 🎜🎜#
select * from t where name='xx'
peuvent être supprimées.
Joint Index
Par exemple, nom+âge, le processus en cours est le même et un arbre B+ indépendant est établi après que la page de données du nœud feuille stocke l'identifiant. +nom+âge, la valeur par défaut est Trier par nom, le même nom est trié par âge, il en va de même pour le tri des valeurs nom+âge entre différentes pages de données. select *
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



