

Un blocage s'est produit dans l'environnement de production. En regardant le journal des blocages, j'ai vu que le blocage était causé par deux instructions de mise à jour identiques (seules les valeurs dans les conditions Where étaient différentes),
comme suit. :
UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx1' AND `status` = 0; UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx2' AND `status` = 0;
一C'était un peu déroutant au début. Après de nombreuses recherches et études, j'ai analysé les principes spécifiques de la formation des impasses. J'aimerais le partager avec vous dans l'espoir que cela puisse aider les amis qui rencontrent le problème. même problème.
Parce que MySQL a beaucoup de points de connaissances, de nombreux noms ne seront pas trop introduits ici. Les amis intéressés peuvent poursuivre avec une étude approfondie spéciale. MySQL知识点较多,这里对很多名词不进行过多介绍,有兴趣的朋友,可以后续进行专项深入学习。
*** (1) TRANSACTION: TRANSACTION 791913819, ACTIVE 0 sec starting index read, thread declared inside InnoDB 4999 mysql tables in use 3, locked 3 LOCK WAIT 4 lock struct(s), heap size 1184, 3 row lock(s) MySQL thread id 462005230, OS thread handle 0x7f55d5da3700, query id 2621313306 x.x.x.x test_user Searching rows for update UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx1' AND `status` = 0; *** (1) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 110 page no 39167 n bits 1056 index `idx_status` of table `test`.`test_table` trx id 791913819 lock_mode X waiting Record lock, heap no 495 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 *** (2) TRANSACTION: TRANSACTION 791913818, ACTIVE 0 sec starting index read, thread declared inside InnoDB 4999 mysql tables in use 3, locked 3 5 lock struct(s), heap size 1184, 4 row lock(s) MySQL thread id 462005231, OS thread handle 0x7f55cee63700, query id 2621313305 x.x.x.x test_user Searching rows for update UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx2' AND `status` = 0; *** (2) HOLDS THE LOCK(S): RECORD LOCKS space id 110 page no 39167 n bits 1056 index `idx_status` of table `test`.`test_table` trx id 791913818 lock_mode X Record lock, heap no 495 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 *** (2) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 110 page no 41569 n bits 88 index `PRIMARY` of table `test`.`test_table` trx id 791913818 lock_mode X locks rec but not gap waiting Record lock, heap no 14 PHYSICAL RECORD: n_fields 30; compact format; info bits 0 *** WE ROLL BACK TRANSACTION (1)
简要分析下上边的死锁日志:
1、第一块内容(第1行到第9行)中,第6行为事务(1)执行的SQL语句,第7和第8行意思为事务(1)在等待 idx_status 索引上的X锁;
2、第二块内容(第11行到第19行)中,第16行为事务(2)执行的SQL语句,第17和第18行意思为事务(2)持有 idx_status 索引上的X锁;
意思为:事务(2)正在等待在 PRIMARY 索引上获取 X 锁。(but not gap指不是间隙锁)
4、最后一句的意思即为,MySQL将事务(1)进行了回滚操作。
CREATE TABLE `test_table` ( `id` int(11) NOT NULL AUTO_INCREMENT, `trans_id` varchar(21) NOT NULL, `status` int(11) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `uniq_trans_id` (`trans_id`) USING BTREE, KEY `idx_status` (`status`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
通过表结构可以看出,trans_id 列上有一个唯一索引uniq_trans_id ,status 列上有一个普通索引idx_status ,id列为主键索引 PRIMARY 。
InnoDB引擎中有两种索引:
聚簇索引: 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据。
辅助索引: 辅助索引叶子节点存储的是主键值,也就是聚簇索引的键值。
主键索引 PRIMARY 就是聚簇索引,叶子节点中会保存行数据。uniq_trans_id 索引和idx_status 索引为辅助索引,叶子节点中保存的是主键值,也就是id列值。
当我们通过辅助索引查找行数据时,先通过辅助索引找到主键id,再通过主键索引进行二次查找(也叫回表),最终找到行数据。
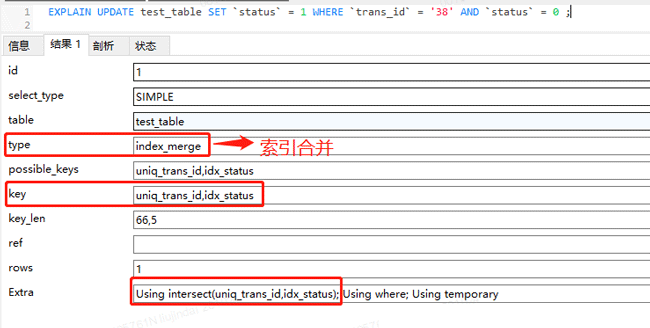
通过看执行计划,可以发现,update语句用到了索引合并,也就是这条语句既用到了 uniq_trans_id 索引,又用到了 idx_status 索引,Using intersect(uniq_trans_id,idx_status)的意思是通过两个索引获取交集。
MySQL5.0之前,一个表一次只能使用一个索引,无法同时使用多个索引分别进行条件扫描。但是从5.1开始,引入了 index merge 优化技术,对同一个表可以使用多个索引分别进行条件扫描。
如执行计划中的语句:
UPDATE test_table SET `status` = 1 WHERE `trans_id` = '38' AND `status` = 0 ;
MySQL会根据 trans_id = ‘38’这个条件,利用 uniq_trans_id 索引找到叶子节点中保存的id值;同时会根据 status = 0这个条件,利用 idx_status 索引找到叶子节点中保存的id值;然后将找到的两组id值取交集,最终通过交集后的id回表,也就是通过 PRIMARY 索引找到叶子节点中保存的行数据。
这里可能很多人会有疑问了,uniq_trans_id 已经是一个唯一索引了,通过这个索引最终只能找到最多一条数据,那MySQL优化器为啥还要用两个索引取交集,再回表进行查询呢,这样不是多了一次 idx_status 索引查找的过程么。我们来分析一下这两种情况执行过程。
第一种 只用uniq_trans_id索引 :
根据 trans_id = ‘38’查询条件,利用uniq_trans_id 索引找到叶子节点中保存的id值;
通过找到的id值,利用PRIMARY索引找到叶子节点中保存的行数据;
再通过 status = 0 条件对找到的行数据进行过滤。
第二种 用到索引合并 Using intersect(uniq_trans_id,idx_status):
根据 trans_id = ‘38’ 查询条件,利用 uniq_trans_id 索引找到叶子节点中保存的id值;
根据 status = 0 查询条件,利用 idx_status
uniq_trans_id sur la colonne trans_id , status idx_status sur la colonne /code>, et la colonne id est l'index de clé primaire PRIMARY . 🎜🎜🎜Il existe deux types d'index dans le moteur InnoDB : 🎜🎜PRIMARY est un index clusterisé et les données de ligne seront stockées dans des nœuds feuilles. L'index uniq_trans_id et l'index idx_status sont des index auxiliaires, et les nœuds feuilles stockent la valeur de la clé primaire, qui est la valeur de la colonne id. 🎜🎜Lorsque nous recherchons des données de ligne via l'index auxiliaire, nous trouvons d'abord l'identifiant de clé primaire via l'index auxiliaire, puis effectuons une recherche secondaire via l'index de clé primaire (également rappelé à la table), et enfin trouvons les données de ligne . 🎜🎜Plan d'exécution🎜🎜🎜🎜En regardant le plan d'exécution, vous pouvez constater que l'instruction update utilise la fusion d'index, c'est-à-dire que cette instruction utilise à la fois l'index uniq_trans_id et l'index idx_status , Utiliser intersect(uniq_trans_id,idx_status) signifie obtenir l'intersection via deux index. 🎜🎜Pourquoi index_merge est-il utilisé ? 🎜🎜Avant MySQL 5.0, une table ne pouvait utiliser qu'un seul index à la fois, et il n'était pas possible d'utiliser plusieurs index en même temps pour une analyse conditionnelle. Cependant, à partir de la version 5.1, la technologie d'optimisation fusion d'index a été introduite, et plusieurs index peuvent être utilisés pour effectuer des analyses conditionnelles sur la même table. 🎜🎜🎜Par exemple, l'instruction dans le plan d'exécution : 🎜🎜rrreee🎜MySQL utilisera l'index uniq_trans_id pour trouver l'identifiant enregistré dans le nœud feuille en fonction de la condition de trans_id = &lsquo ;38’ ; en même temps, en fonction de la condition status = 0, l'index idx_status sera utilisé pour trouver la valeur d'identifiant enregistrée dans le nœud feuille ; puis les deux valeurs d'identifiant trouvées seront croisées et finalement transmises. L'ID après l'intersection est renvoyé à la table, c'est-à-dire que les données de ligne enregistrées dans le nœud feuille sont trouvées via l'index PRIMAIRE. 🎜🎜Beaucoup de gens peuvent avoir des questions ici. uniq_trans_id est déjà un index unique. Une seule donnée peut être trouvée via cet index. Alors pourquoi l'optimiseur MySQL utilise-t-il deux index pour récupérer les données ? puis revenez à la table pour la requête. Cela n'ajoute-t-il pas un autre processus de recherche d'index idx_status ? Analysons le processus d'exécution de ces deux situations. 🎜🎜🎜Le premier utilise uniquement l'index uniq_trans_id : 🎜🎜trans_id = ‘38’, utilisez L'index uniq_trans_id trouve la valeur d'identifiant enregistrée dans le nœud feuille ; 🎜status = 0. 🎜Using intersect(uniq_trans_id,idx_status) : 🎜trans_id = ‘38’ Conditions de requête, utilisez l'index uniq_trans_id pour trouver la valeur d'identifiant enregistrée dans le nœud feuille 🎜status = 0 Conditions de requête, utilisez l'index idx_status pour trouver la valeur d'identifiant enregistrée dans le nœud feuille 🎜 ;Intersectez les valeurs d'identifiant trouvées dans 1/2, puis utilisez l'index PRIMARY pour trouver les données de ligne enregistrées dans le nœud feuille
La principale différence entre les deux cas ci-dessus est que le premier est de passez d'abord les données via un index Après l'avoir trouvé, utilisez d'autres conditions de requête pour filtrer ; la deuxième méthode consiste à obtenir d'abord l'intersection des valeurs d'identifiant trouvées par les deux index. Si la valeur d'identifiant existe toujours après l'intersection, alors. revenez à la table pour récupérer les données.
Lorsque l'optimiseur estime que le coût d'exécution du deuxième cas est inférieur à celui du premier cas, une fusion d'index se produira. (Il y a très peu de données dans la table de flux de l'environnement de production status = 0, ce qui est une des raisons pour lesquelles l'optimiseur considère le deuxième cas). status = 0 的数据非常少,这也是优化器考虑用第二种情况的原因之一)。
为什么用了 index_merge 就死锁了
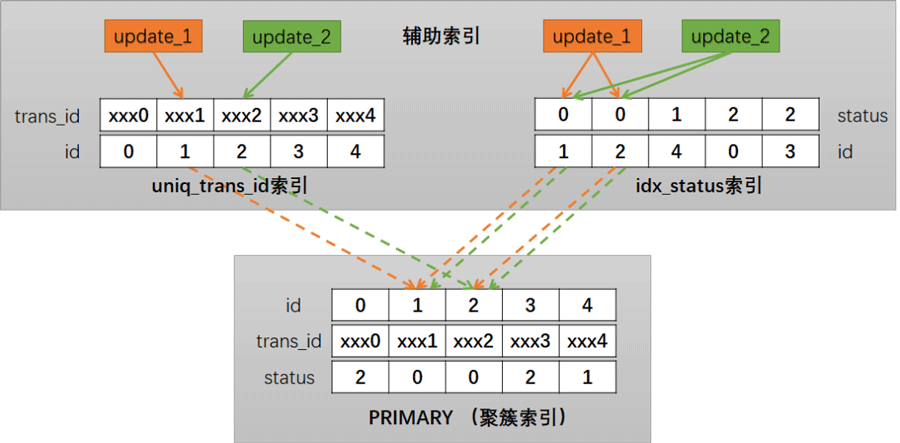
上面简要画了一下两个update事务加锁的过程,从图中可以看到,在idx_status 索引和 PRIMARY (聚簇索引) 上都存在重合交叉的部分,这样就为死锁造成了条件。
如,当遇到以下时序时,就会出现死锁:
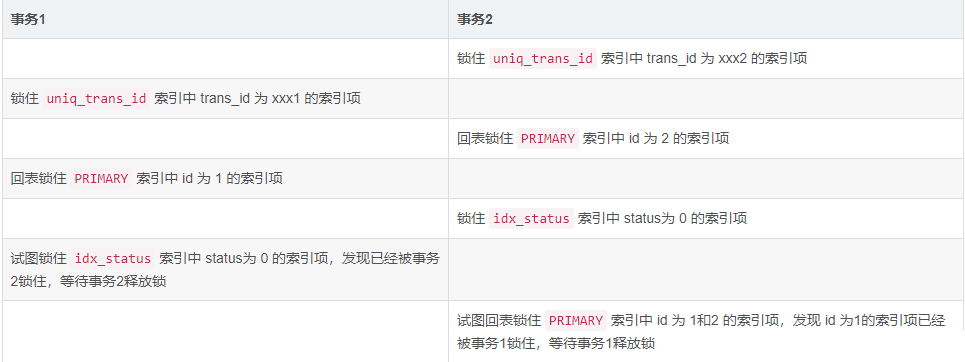
事务1等待事务2释放锁,事务2等待事务1释放锁,这样就造成了死锁。
MySQL检测到死锁后,会自动回滚代价更低的那个事务,如上边的时序图中,事务1持有的锁比事务2少,则MySQL就将事务1进行了回滚。
where 查询条件中,只传 trans_id ,将数据查询出来后,在代码层面判断 status 状态是否为0;
使用 force index(uniq_trans_id) 强制查询语句使用 uniq_trans_id 索引;
where 查询条件后边直接用 id 字段,通过主键去更新。
删除 idx_status 索引或者建一个包含这俩列的联合索引;
将MySQL优化器的index merge
index_merge
🎜🎜Ce qui précède décrit brièvement le processus de verrouillage des deux transactions de mise à jour. Comme le montre la figure, dans l'index idx_status et PRIMARY (Index clusterisés) ont des parties qui se chevauchent et se croisent, ce qui crée des conditions de blocage. 🎜🎜Par exemple, lorsque le timing suivant est rencontré, un blocage se produira :🎜🎜 🎜🎜La transaction 1 attend que la transaction 2 libère le verrou, et la transaction 2 attend que la transaction 1 libère le verrou, provoquant ainsi un impasse. 🎜🎜Une fois que MySQL a détecté un blocage, il annulera automatiquement la transaction avec le coût le plus faible. Par exemple, dans le chronogramme ci-dessus, la transaction 1 contient moins de verrous que la transaction 2, donc MySQL annule la transaction 1. 🎜
🎜🎜La transaction 1 attend que la transaction 2 libère le verrou, et la transaction 2 attend que la transaction 1 libère le verrou, provoquant ainsi un impasse. 🎜🎜Une fois que MySQL a détecté un blocage, il annulera automatiquement la transaction avec le coût le plus faible. Par exemple, dans le chronogramme ci-dessus, la transaction 1 contient moins de verrous que la transaction 2, donc MySQL annule la transaction 1. 🎜trans_id Après avoir interrogé les données, déterminez si le statut est 0 au niveau du code ; 🎜🎜🎜🎜Utilisez force index(uniq_trans_id) pour forcer l'instruction de requête à utiliser l'index uniq_trans_id. 🎜 🎜🎜🎜où utilisez le champ id directement après la condition de requête et mettez-le à jour via la clé primaire. 🎜🎜🎜idx_status ou créez un index commun contenant ces deux colonnes ; 🎜🎜🎜🎜Désactivez l'optimisation fusion d'index de l'optimiseur MySQL. 🎜🎜🎜Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



