
 base de données
tutoriel mysql
Analyse des transactions MySQL et des instances de moteur de stockage
base de données
tutoriel mysql
Analyse des transactions MySQL et des instances de moteur de stockage
Analyse des transactions MySQL et des instances de moteur de stockage

1. Transaction MySQL
1. Le concept de transaction
(1) Une transaction est un mécanisme, une séquence d'opérations, qui comprend un ensemble de commandes de fonctionnement de la base de données, et toutes les commandes sont soumises ou révoquées au système dans son ensemble. .Requête, c'est-à-dire que soit tous cet ensemble de commandes de base de données seront exécutés, soit aucune d'entre elles ne sera exécutée.
(2) Une transaction est une unité de travail logique indivisible lors de l'exécution d'opérations simultanées sur un système de base de données, une transaction est la plus petite unité de contrôle.
(3) Scénarios de systèmes de bases de données exploités par plusieurs utilisateurs en même temps, tels que les banques, les compagnies d'assurance, les systèmes de négociation de titres, etc., adaptés au traitement des transactions. (4) Les transactions garantissent la cohérence des données grâce à l'intégrité des transactions.
2. Caractéristiques ACID des transactions
Remarque : ACID fait référence aux quatre caractéristiques qu'une transaction doit avoir dans un système de gestion de base de données (SGBD) fiable : atomicité, cohérence et isolement et durabilité. Ce sont plusieurs caractéristiques que devrait avoir une base de données fiable.
(1) Les transactions sont atomiques, c'est-à-dire que les opérations de la transaction sont soit toutes exécutées, soit pas exécutées du tout, et sont indivisibles. a. Une transaction est une opération complète et les éléments de la transaction sont indissociables.
b. Tous les éléments de la transaction doivent être validés ou annulés dans leur ensemble.
c. Si un élément de la transaction échoue, la transaction entière échouera.
(2) Cohérence : signifie que les contraintes d'intégrité de la base de données ne sont pas violées avant le début de la transaction et après la fin de la transaction.
a. Lorsque la transaction est terminée, les données doivent être dans un état cohérent.
b. Avant le début de la transaction, les données stockées dans la base de données sont dans un état cohérent.
c. Lors des transactions en cours, les données peuvent être dans un état incohérent.
d. Lorsque la transaction se termine avec succès, les données doivent à nouveau revenir à un état cohérent connu.
(3) Isolation : lorsque plusieurs transactions exploitent les mêmes données en même temps, dans un environnement simultané, chaque transaction peut utiliser sa propre zone de données complète et indépendante. Toutes les transactions simultanées qui modifient les données sont isolées les unes des autres, ce qui indique qu'une transaction doit être indépendante et qu'elle ne doit en aucun cas dépendre ou affecter d'autres transactions. Une transaction qui modifie les données peut accéder aux données avant le début d’une autre transaction utilisant les mêmes données ou après la fin d’une autre transaction utilisant les mêmes données.
(4) Persistance : une fois la transaction terminée, les modifications apportées à la base de données par la transaction sont conservées dans la base de données et ne seront pas annulées.
a signifie que, que le système échoue ou non, les résultats du traitement des transactions sont permanents.
b. Une fois qu'une transaction est validée, les effets de la transaction seront conservés en permanence dans la base de données.
Résumé : Dans la gestion des transactions, l'atomicité est le fondement, l'isolement est le moyen, la cohérence est le but et la durabilité est le résultat.
3. L'influence mutuelle entre les choses
(1) Lecture sale : une transaction lit les données non validées d'une autre transaction, et ces données peuvent être annulées.
L'exécution continue de deux requêtes identiques dans une transaction mais l'obtention de résultats différents est appelée une lecture non répétable. Cela est dû à la validation des modifications par d'autres transactions dans le système au moment de la requête.
Re-narration : la lecture fantôme fait référence au moment où une transaction modifie certaines lignes de données dans une table, mais qu'une autre transaction insère plusieurs lignes de nouvelles données en même temps, ce qui oblige la première transaction à trouver plusieurs lignes de données supplémentaires lors de l'interrogation. Au même moment, une autre transaction a modifié la table et inséré une nouvelle ligne de données. Les utilisateurs qui ont opéré sur la transaction précédente seront surpris de constater qu'il y a encore des lignes de données non modifiées dans le tableau, comme s'ils hallucinaient.
(4). Mise à jour perdue : deux transactions lisent le même enregistrement en même temps. A modifie d'abord l'enregistrement, et B modifie également l'enregistrement (B ne sait pas que A l'a modifié après que B ait soumis les données). Le résultat de la modification de B écrase le résultat de la modification de A.
2. Mysql et niveau d'isolement des transactions
(1), lecture non validée : lecture de données non validées, ne résout pas les lectures sales
(2), lecture validée : lecture de données validées, peut résoudre les lectures sales
(3), lecture répétable : relecture, peut résoudre les lectures sales et les lectures non répétables-------------mysql par défaut
(4), sérialisable : sérialisation, peut résoudre les lectures sales, les lectures non répétables et virtuelles read---------------- équivalent à lock table Remarque : le niveau de traitement des transactions par défaut de MySQL est une lecture répétable, tandis qu'Oracle et SQL Server sont validés en lecture
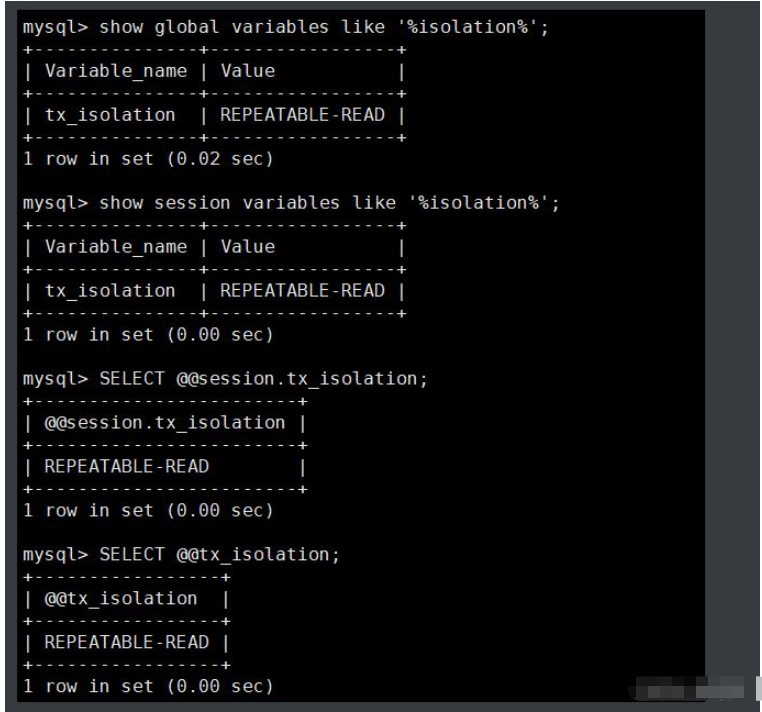
1. Interrogez le niveau d'isolation global des transactions
show global variables like '%isolation%'; 或 select @@global.tx_isolation;

2. Interrogez le niveau d'isolement des transactions de session
show session variables like '%isolation%'; SELECT @@session.tx_isolation; SELECT @@tx_isolation;
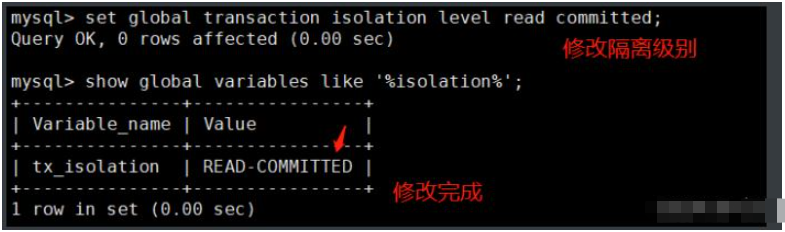
3. Définissez le niveau d'isolement des transactions global
set global transaction isolation level read committed; show global variables like '%isolation%';
4.三、事务控制语句
1、相关语句
begin; 开启事务
commit; 提交事务,使已对数据库进行的所有修改变为永久性的
rollback; 回滚事务,撤销正在进行的所有未提交的修改
savepoint s1; 建立回滚点,s1为回滚点名称,一个事务中可以有多个
rollback to s1; 回滚到s1回滚点
2、案例
begin; 开启事务
commit; 提交事务,使已对数据库进行的所有修改变为永久性的
rollback; 回滚事务,撤销正在进行的所有未提交的修改
savepoint s1; 建立回滚点,s1为回滚点名称,一个事务中可以有多个
rollback to s1; 回滚到s1回滚点
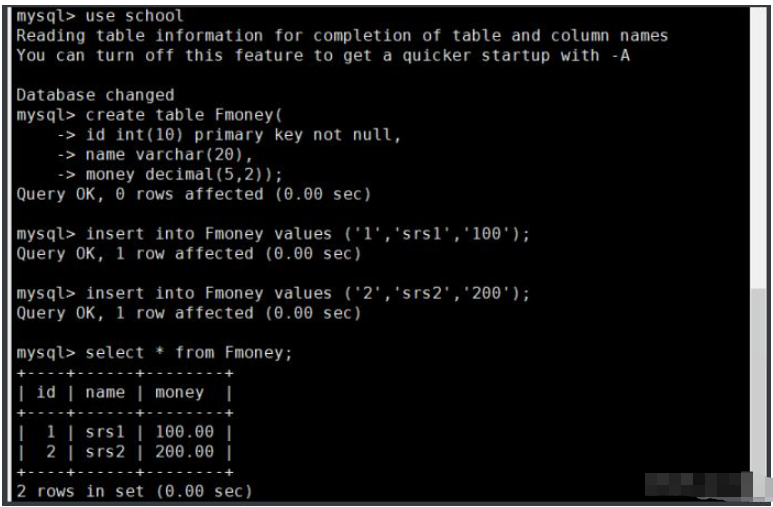
①、创建表
create database school; use school; create table Fmoney( id int(10) primary key not null, name varchar(20), money decimal(5,2)); insert into Fmoney values ('1','srs1','100'); insert into Fmoney values ('2','srs2','200'); select * from Fmoney;
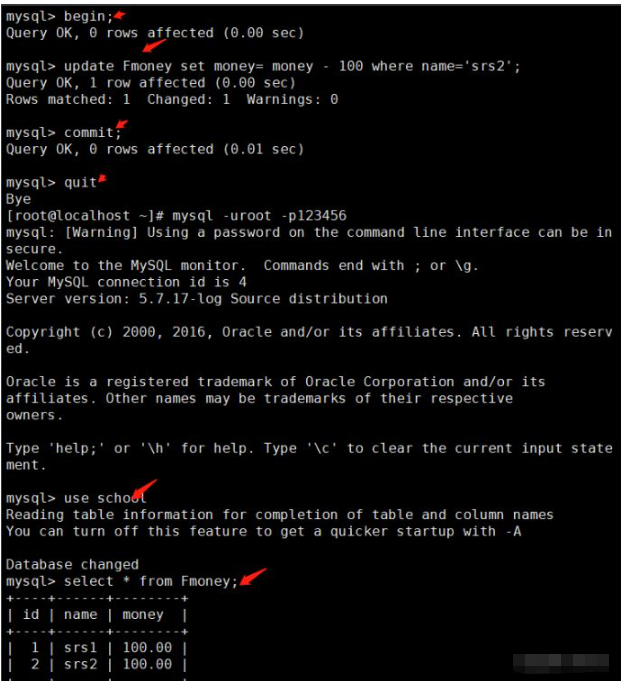
②、测试提交事务
begin; update Fmoney set money= money - 100 where name='srs2'; commit; quit mysql -u root -p use school; select * from Fmoney;
③、测试回滚事务
begin; update Fmoney set money= money + 100 where name='srs2'; select * from Fmoney; rollback; select * from Fmoney;
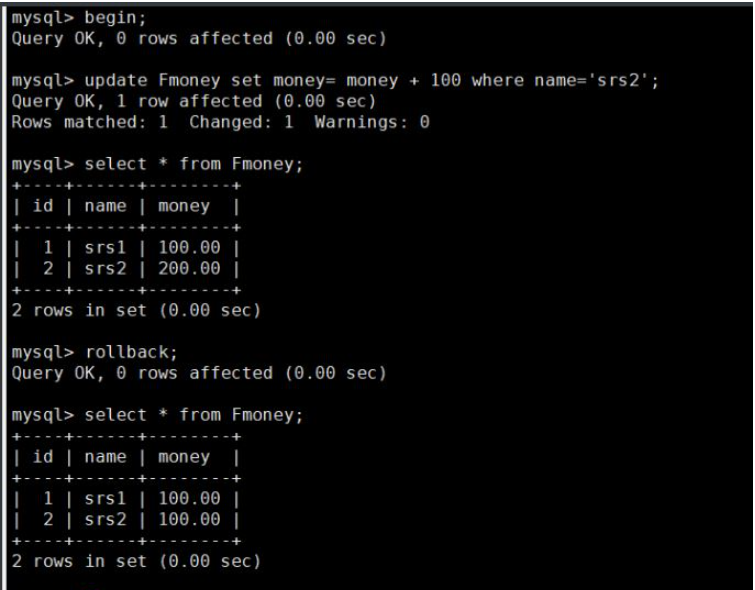
④、测试多点回滚
begin; update Fmoney set money= money + 100 where name='srs2'; select * from Fmoney; savepoint a; update Fmoney set money= money + 100 where name='srs1'; select * from Fmoney; savepoint b; insert into Fmoney values ('3','srs3','300'); select * from Fmoney; rollback to b; select * from Fmoney;
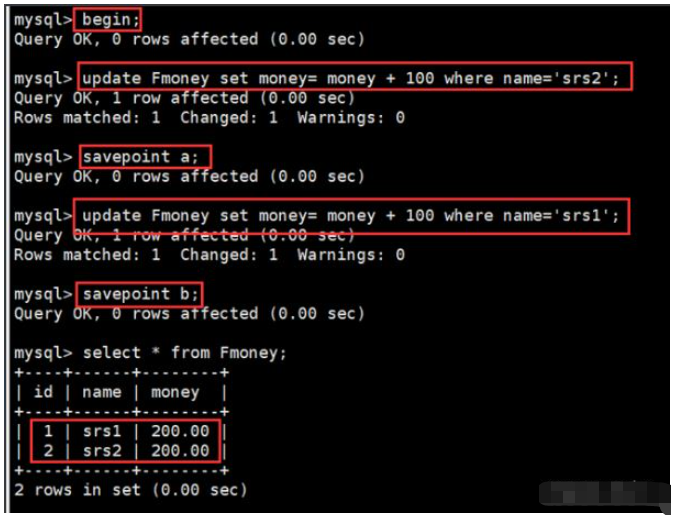
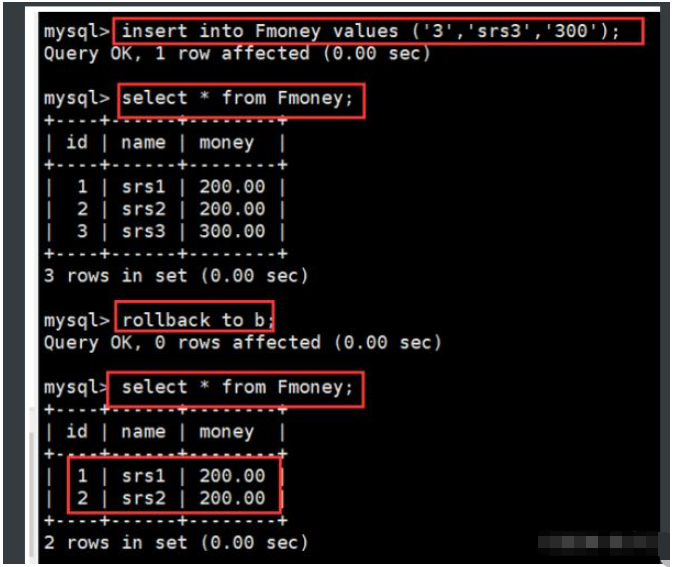
3、使用 set 设置控制事务
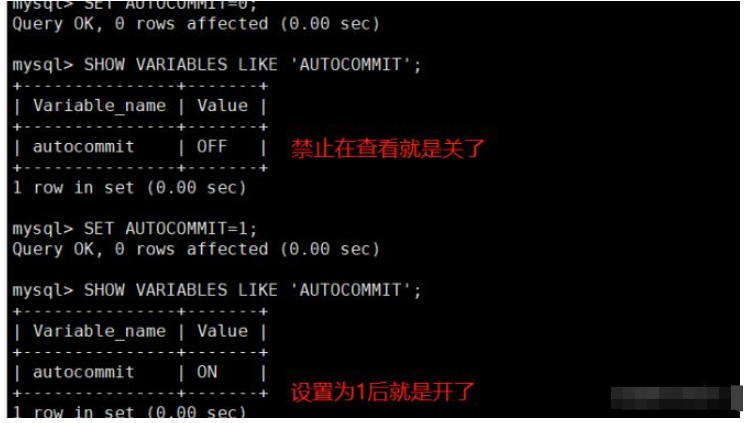
SET AUTOCOMMIT=0; #禁止自动提交 SET AUTOCOMMIT=1; #开启自动提交,Mysql默认为1 SHOW VARIABLES LIKE 'AUTOCOMMIT'; #查看Mysql中的AUTOCOMMIT值
如果没有开启自动提交,当前会话连接的mysql的所有操作都会当成一个事务直到你输入rollback|commit;当前事务才算结束。当前事务结束前新的mysql连接时无法读取到任何当前会话的操作结果。
如果开起了自动提交,mysql会把每个sql语句当成一个事务,然后自动的commit。
当然无论开启与否,begin; commit|rollback; 都是独立的事务。
四、MySQL 存储引擎
1、存储引擎概念介绍
(1)MySQL中的数据用各种不同的技术存储在文件中,每一种技术都使用不同的存储机制、索引技巧、锁定水平,并最终提供不同的功能和能力,这些不同的技术以及配套的功能在MySQL中称为存储引擎。
(2)存储引擎是MySQL将数据存储在文件系统中的存储方式或者存储格式
(3)MySQL 常用的存储引擎有: a、MylSAM b、InnoDB
(4)MySQL数据库中的组件,负责执行实际的数据I/O操作
(5)MySQL系统中,存储引擎处于文件系统之.上,在数据保存到数据文件之前会传输到存储引擎,之后按照各个存储引擎的存储格式进行存储。
2、查看系统支持的存储引擎
show engines;
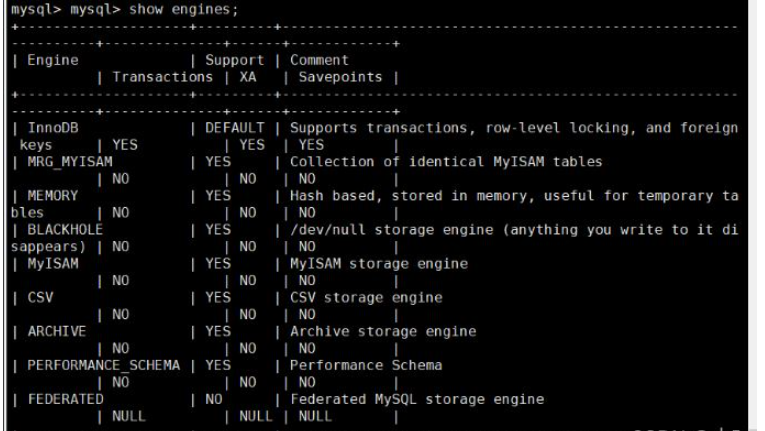
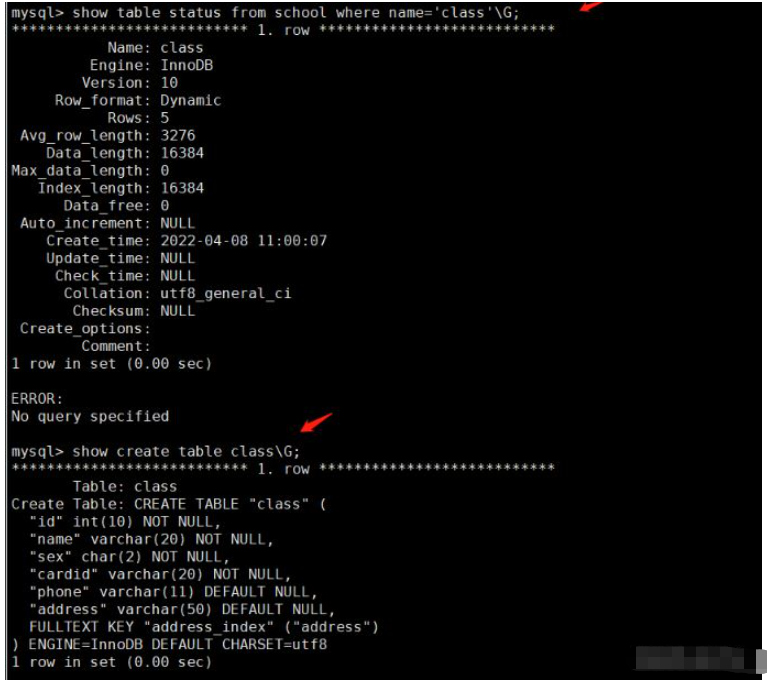
3、查看表使用的存储引擎
(1)方法一:直接查看 show table status from 库名 where name='表名'\G; 例: show table status from school where name='class'\G; (2)方法二:进入数据库查看 use 库名; show create table 表名\G; 例: use school; show create table class\G;
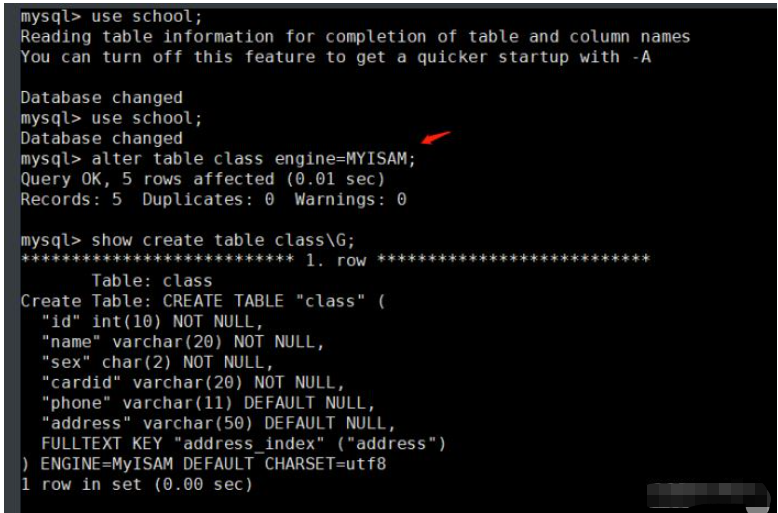
4、修改存储引擎
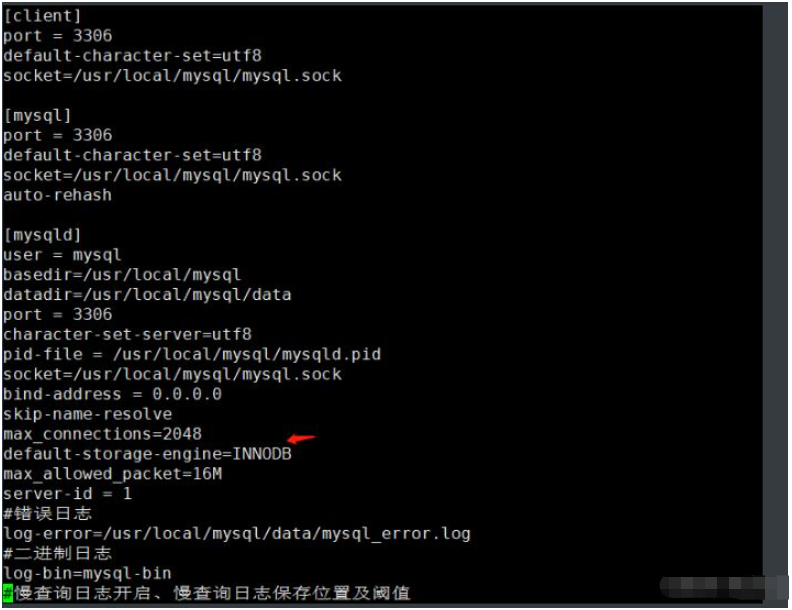
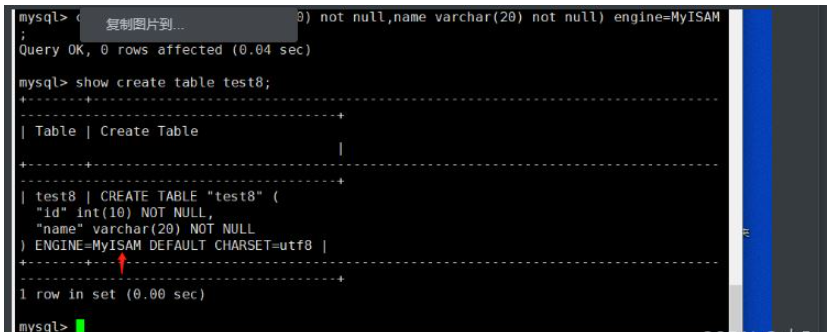
(1) 方法一:通过 alter table 修改 use 库名; alter table 表名 engine=MyISAM; 例: use school; alter table class engine=MYISAM; (2)方法二:通过修改 /etc/my.cnf 配置文件,指定默认存储引擎并重启服务 注意:此方法只对修改了配置文件并重启mysql服务后新创建的表有效,已经存在的表不会有变更。 vim /etc/my.cnf ...... [mysqld] ...... default-storage-engine=INNODB systemctl restart mysql.service (3)方法三:通过 create table 创建表时指定存储引擎 use 库名; create table 表名(字段1 数据类型,...) engine=MyISAM; 例: mysql -u root -p use school; create table test7(id int(10) not null,name varchar(20) not null) engine=MyISAM;
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Compétences de traitement de structures de données volumineuses de PHP
May 08, 2024 am 10:24 AM
Compétences de traitement de structures de données volumineuses de PHP
May 08, 2024 am 10:24 AM
Compétences en matière de traitement de la structure des Big Data : Chunking : décomposez l'ensemble de données et traitez-le en morceaux pour réduire la consommation de mémoire. Générateur : générez des éléments de données un par un sans charger l'intégralité de l'ensemble de données, adapté à des ensembles de données illimités. Streaming : lisez des fichiers ou interrogez les résultats ligne par ligne, adapté aux fichiers volumineux ou aux données distantes. Stockage externe : pour les ensembles de données très volumineux, stockez les données dans une base de données ou NoSQL.
 Comment optimiser les performances des requêtes MySQL en PHP ?
Jun 03, 2024 pm 08:11 PM
Comment optimiser les performances des requêtes MySQL en PHP ?
Jun 03, 2024 pm 08:11 PM
Les performances des requêtes MySQL peuvent être optimisées en créant des index qui réduisent le temps de recherche d'une complexité linéaire à une complexité logarithmique. Utilisez PreparedStatements pour empêcher l’injection SQL et améliorer les performances des requêtes. Limitez les résultats des requêtes et réduisez la quantité de données traitées par le serveur. Optimisez les requêtes de jointure, notamment en utilisant des types de jointure appropriés, en créant des index et en envisageant l'utilisation de sous-requêtes. Analyser les requêtes pour identifier les goulots d'étranglement ; utiliser la mise en cache pour réduire la charge de la base de données ; optimiser le code PHP afin de minimiser les frais généraux.
 Comment utiliser la sauvegarde et la restauration MySQL en PHP ?
Jun 03, 2024 pm 12:19 PM
Comment utiliser la sauvegarde et la restauration MySQL en PHP ?
Jun 03, 2024 pm 12:19 PM
La sauvegarde et la restauration d'une base de données MySQL en PHP peuvent être réalisées en suivant ces étapes : Sauvegarder la base de données : Utilisez la commande mysqldump pour vider la base de données dans un fichier SQL. Restaurer la base de données : utilisez la commande mysql pour restaurer la base de données à partir de fichiers SQL.
 Comment insérer des données dans une table MySQL en utilisant PHP ?
Jun 02, 2024 pm 02:26 PM
Comment insérer des données dans une table MySQL en utilisant PHP ?
Jun 02, 2024 pm 02:26 PM
Comment insérer des données dans une table MySQL ? Connectez-vous à la base de données : utilisez mysqli pour établir une connexion à la base de données. Préparez la requête SQL : Écrivez une instruction INSERT pour spécifier les colonnes et les valeurs à insérer. Exécuter la requête : utilisez la méthode query() pour exécuter la requête d'insertion en cas de succès, un message de confirmation sera généré.
 Comment corriger les erreurs mysql_native_password non chargé sur MySQL 8.4
Dec 09, 2024 am 11:42 AM
Comment corriger les erreurs mysql_native_password non chargé sur MySQL 8.4
Dec 09, 2024 am 11:42 AM
L'un des changements majeurs introduits dans MySQL 8.4 (la dernière version LTS en 2024) est que le plugin « MySQL Native Password » n'est plus activé par défaut. De plus, MySQL 9.0 supprime complètement ce plugin. Ce changement affecte PHP et d'autres applications
 Comment utiliser les procédures stockées MySQL en PHP ?
Jun 02, 2024 pm 02:13 PM
Comment utiliser les procédures stockées MySQL en PHP ?
Jun 02, 2024 pm 02:13 PM
Pour utiliser les procédures stockées MySQL en PHP : Utilisez PDO ou l'extension MySQLi pour vous connecter à une base de données MySQL. Préparez l'instruction pour appeler la procédure stockée. Exécutez la procédure stockée. Traitez le jeu de résultats (si la procédure stockée renvoie des résultats). Fermez la connexion à la base de données.
 Comment créer une table MySQL en utilisant PHP ?
Jun 04, 2024 pm 01:57 PM
Comment créer une table MySQL en utilisant PHP ?
Jun 04, 2024 pm 01:57 PM
La création d'une table MySQL à l'aide de PHP nécessite les étapes suivantes : Connectez-vous à la base de données. Créez la base de données si elle n'existe pas. Sélectionnez une base de données. Créer un tableau. Exécutez la requête. Fermez la connexion.
 La différence entre la base de données Oracle et MySQL
May 10, 2024 am 01:54 AM
La différence entre la base de données Oracle et MySQL
May 10, 2024 am 01:54 AM
La base de données Oracle et MySQL sont toutes deux des bases de données basées sur le modèle relationnel, mais Oracle est supérieur en termes de compatibilité, d'évolutivité, de types de données et de sécurité ; tandis que MySQL se concentre sur la vitesse et la flexibilité et est plus adapté aux ensembles de données de petite et moyenne taille. ① Oracle propose une large gamme de types de données, ② fournit des fonctionnalités de sécurité avancées, ③ convient aux applications de niveau entreprise ; ① MySQL prend en charge les types de données NoSQL, ② a moins de mesures de sécurité et ③ convient aux applications de petite et moyenne taille.
