
 base de données
tutoriel mysql
Que sont les journaux MySQL Binlog et la réplication maître-esclave ?
base de données
tutoriel mysql
Que sont les journaux MySQL Binlog et la réplication maître-esclave ?
Que sont les journaux MySQL Binlog et la réplication maître-esclave ?

1. Introduction au journal Binlog
Binlog est l'abréviation de Binary log, c'est-à-dire journal binaire. Les trois fonctions principales de Binlog incluent la conversion des E/S aléatoires en E/S séquentielles pour la persistance, la réalisation de la réplication maître-esclave et la prise en charge de la récupération des données. Cet article se concentre sur les problèmes liés à la réplication maître-esclave.
Le journal Binlog se compose d'un fichier d'index et de nombreux fichiers journaux. Chaque fichier journal se compose d'un nombre magique et d'un événement. Chaque fichier journal se termine par un événement de type Rotate.
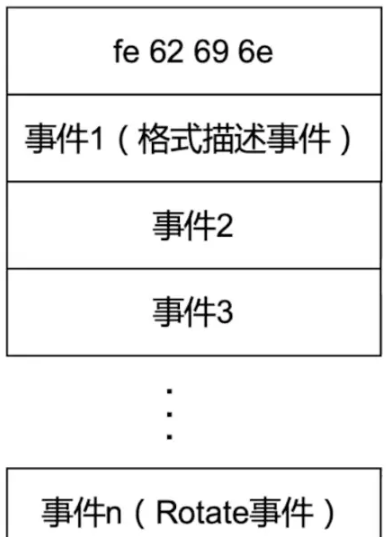
Pour chaque événement, il peut être divisé en deux parties : l'en-tête de l'événement et le corps de l'événement :
La structure de l'en-tête de l'événement est la suivante :

La structure du corps de l'événement comprend une taille fixe et une taille amovible. Changez la taille en deux parties.
En ce qui concerne le format des journaux Binlog, il vous suffit d'avoir une compréhension simple. Les étudiants intéressés peuvent apprendre en profondeur.
2. Réplication maître-esclave
2.1 Le processus de réplication maître-esclave
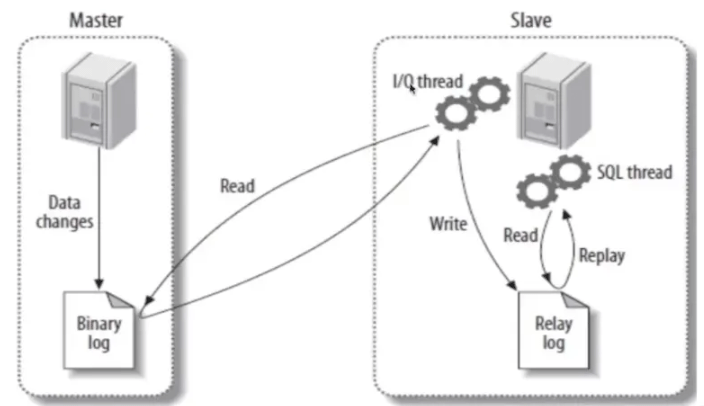
Le processus de réplication maître-esclave MySQL est à peu près le suivant :
La bibliothèque maître synchronise son propre journal Binlog à la bibliothèque esclave
Slave Le thread IO de la bibliothèque écrit le contenu du journal Binlog dans le journal de relais
Le thread SQL de la bibliothèque prend le journal de relais et le lit dans la base de données
2.2 GTID
GTID fait référence à l'indicateur de transaction global, utilisé pour marquer la situation de synchronisation maître-esclave.
Lorsque le nœud maître valide une transaction, le GTID sera généré et enregistré dans le journal Binlog. Lorsque le thread IO de la bibliothèque esclave lit le journal Binlog, il le stockera dans son propre Relaylog et définira cette valeur sur gtid_next, qui est le prochain GTID à lire. Lors de la lecture de ce gtid_next à partir de la bibliothèque, il comparera s'il existe. est ce GTID dans votre log Binlog :
S'il y a cet enregistrement, cela signifie que la transaction avec ce GTID a été exécutée et peut être ignorée (idempotente).
S'il n'y a pas un tel enregistrement, l'esclave exécutera la transaction GTID et l'enregistrera dans son propre journal Binlog.
2.3 Modèle de réplication
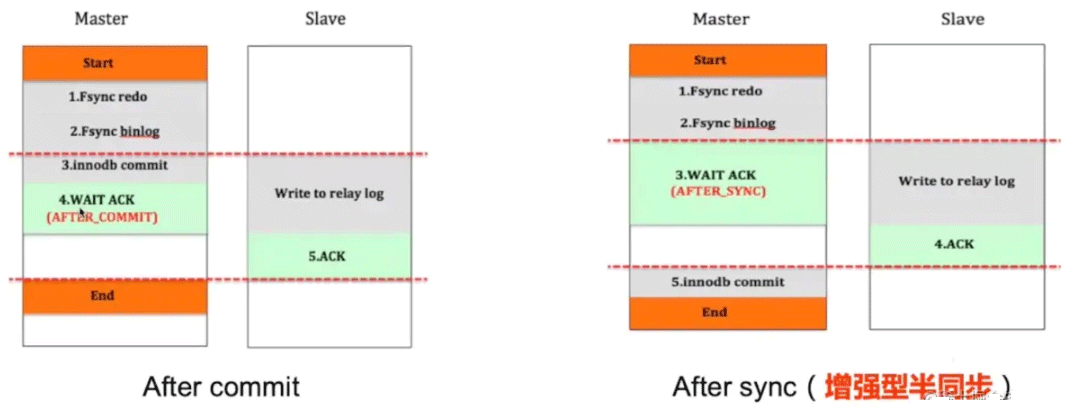
Réplication asynchrone : le maître transmet le journal Binlog à l'esclave. Le maître n'a pas besoin d'attendre que l'esclave mette à jour avec succès les données dans le journal Relay. la transaction. Ce mode sacrifie la cohérence des données.
Réplication synchrone : Chaque fois que l'utilisateur opère, il faut s'assurer que le maître et l'esclave sont exécutés avec succès avant de le renvoyer à l'utilisateur.
Réplication semi-synchrone : Elle ne nécessite pas que l'esclave s'exécute avec succès, mais elle peut demander au maître de revenir après avoir reçu avec succès le journal du maître.
2.4 Mode MGR
Algorithme de consensus distribué Paxos. Un cluster de bases de données se compose d'au moins 3 nœuds ou plus. La soumission de transaction doit être approuvée par plus de la moitié des nœuds avant de pouvoir être soumise.
MGR est une solution de réplication sans partage, mise en œuvre sur la base du protocole paxos distribué. Chaque instance dispose d'une copie complète indépendante des données. Le cluster vérifie automatiquement les informations sur les nœuds et synchronise les données. Le mode mono-maître et le mode multi-maître sont fournis. Le mode multi-maître peut sélectionner automatiquement le maître après la panne de la base de données principale. Toutes les écritures sont effectuées sur le nœud maître. Le mode multi-maître prend en charge l'écriture multi-nœuds. Le cluster offre une tolérance aux pannes. Tant que la plupart des nœuds fonctionnent normalement, le cluster peut fournir des services normalement.
2.5 Lecture parallèle
La lecture des transactions est le processus d'exécution du journal de relais à partir du thread SQL de la bibliothèque. La lecture parallèle vise à améliorer l'efficacité de ce processus et à effectuer des transactions qui peuvent être effectuées en parallèle en même temps.
Lecture parallèle basée sur une horloge logique
Parce que les propres transactions de MySQL ont des caractéristiques ACID, les transactions synchronisées de la base de données maître à la base de données esclave, tant que l'heure logique de leur exécution se chevauche, alors les deux transactions seront Peut effectuer en toute sécurité une lecture parallèle.
Lecture parallèle basée sur writeSet
stocke l'ensemble de transactions sur une zone de bloc de données spécifique au cours d'une certaine période de temps dans un HashMap. Les conflits ne se produisent pas entre les transactions au sein du même groupe ou entre les transactions dont les horloges logiques se chevauchent. Dans le cas contraire, il est impossible de déterminer s'il existe un conflit.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL convient aux débutants car il est simple à installer, puissant et facile à gérer les données. 1. Installation et configuration simples, adaptées à une variété de systèmes d'exploitation. 2. Prise en charge des opérations de base telles que la création de bases de données et de tables, d'insertion, d'interrogation, de mise à jour et de suppression de données. 3. Fournir des fonctions avancées telles que les opérations de jointure et les sous-questionnaires. 4. Les performances peuvent être améliorées par l'indexation, l'optimisation des requêtes et le partitionnement de la table. 5. Prise en charge des mesures de sauvegarde, de récupération et de sécurité pour garantir la sécurité et la cohérence des données.
 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Créez une base de données à l'aide de NAVICAT Premium: Connectez-vous au serveur de base de données et entrez les paramètres de connexion. Cliquez avec le bouton droit sur le serveur et sélectionnez Créer une base de données. Entrez le nom de la nouvelle base de données et le jeu de caractères spécifié et la collation. Connectez-vous à la nouvelle base de données et créez le tableau dans le navigateur d'objet. Cliquez avec le bouton droit sur le tableau et sélectionnez Insérer des données pour insérer les données.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Vous pouvez créer une nouvelle connexion MySQL dans NAVICAT en suivant les étapes: ouvrez l'application et sélectionnez une nouvelle connexion (CTRL N). Sélectionnez "MySQL" comme type de connexion. Entrez l'adresse Hostname / IP, le port, le nom d'utilisateur et le mot de passe. (Facultatif) Configurer les options avancées. Enregistrez la connexion et entrez le nom de la connexion.
 Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
Comment récupérer les données après que SQL supprime les lignes
Apr 09, 2025 pm 12:21 PM
La récupération des lignes supprimées directement de la base de données est généralement impossible à moins qu'il n'y ait un mécanisme de sauvegarde ou de retour en arrière. Point clé: Rollback de la transaction: Exécutez Rollback avant que la transaction ne s'engage à récupérer les données. Sauvegarde: la sauvegarde régulière de la base de données peut être utilisée pour restaurer rapidement les données. Instantané de la base de données: vous pouvez créer une copie en lecture seule de la base de données et restaurer les données après la suppression des données accidentellement. Utilisez la déclaration de suppression avec prudence: vérifiez soigneusement les conditions pour éviter la suppression accidentelle de données. Utilisez la clause WHERE: Spécifiez explicitement les données à supprimer. Utilisez l'environnement de test: testez avant d'effectuer une opération de suppression.
 Comment exécuter SQL dans Navicat
Apr 08, 2025 pm 11:42 PM
Comment exécuter SQL dans Navicat
Apr 08, 2025 pm 11:42 PM
Étapes pour effectuer SQL dans NAVICAT: Connectez-vous à la base de données. Créez une fenêtre d'éditeur SQL. Écrivez des requêtes ou des scripts SQL. Cliquez sur le bouton Exécuter pour exécuter une requête ou un script. Affichez les résultats (si la requête est exécutée).
