
 base de données
tutoriel mysql
Quels sont les trois modes de réplication Mysql maître et esclave ?
base de données
tutoriel mysql
Quels sont les trois modes de réplication Mysql maître et esclave ?
Quels sont les trois modes de réplication Mysql maître et esclave ?

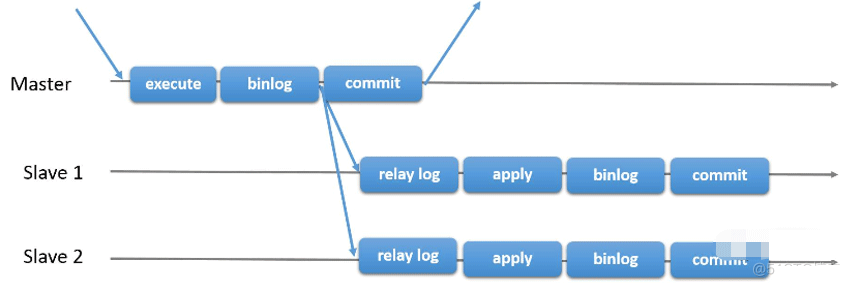
Réplication asynchrone MySQL
La réplication asynchrone MySQL est le mode de réplication par défaut pendant le processus de réplication maître-esclave. La réplication implique trois threads, dont le thread d'E/S maître, le thread d'E/S esclave et le thread SQL esclave. Puisqu'il s'agit d'une réplication asynchrone, la soumission de la transaction maître n'a pas besoin d'être confirmée par l'esclave. Autrement dit, une fois que le thread d'E/S maître a soumis la transaction, il n'a pas besoin d'attendre la réponse de l'esclave I. /O thread. Le maître ne garantit pas que le binlog sera écrit dans le relais dans le journal ; une fois que l'E/S esclave a écrit le binlog dans le journal du relais, il est exécuté de manière asynchrone par le thread SQL esclave et appliqué au mysql esclave. Les E/S esclaves ne nécessitent pas de confirmation de réponse de la part de SQL esclave et ne garantissent pas que le journal du relais est entièrement écrit dans MySQL.
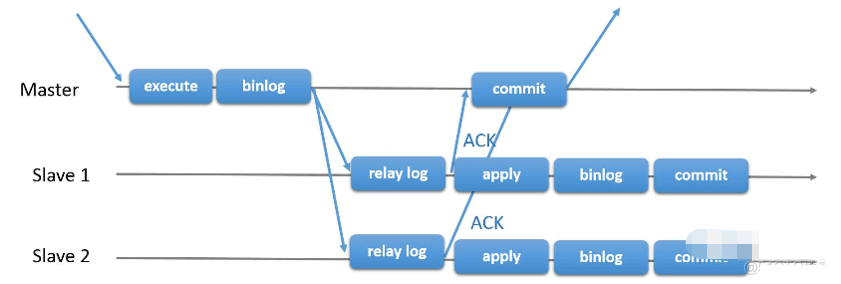
Réplication semi-synchrone
Afin de combler les lacunes de la réplication asynchrone traditionnelle, MySQL a introduit la réplication semi-synchrone dans la version 5.5, qui constitue une amélioration par rapport à la réplication asynchrone traditionnelle. Avant que la transaction maître ne soit validée, il faut s'assurer que le journal binlog a été écrit dans le journal de relais de l'esclave. Ce n'est qu'après avoir reçu la réponse de l'esclave au maître que la transaction peut être validée. Malgré cela, la seconde moitié du journal de relais sera toujours transmise au thread SQL pour une exécution asynchrone.
Réplication de groupe
Basé sur les défauts de la réplication asynchrone traditionnelle et de la réplication semi-synchrone - la cohérence des données ne peut pas être garantie, MySQL a officiellement lancé la réplication de groupe (MGR) dans la version 5.7.17.
Un groupe de réplication est composé de plusieurs nœuds. La soumission d'une transaction doit être résolue et approuvée par la majorité des nœuds du groupe (N/2 + 1) avant de pouvoir être soumise. Comme le montre la figure ci-dessus, un groupe de réplication se compose de 3 nœuds. La couche Consensus est la couche de protocole de cohérence. Pendant le processus de soumission de transaction, la communication entre les groupes n'a lieu que lorsque 2 nœuds résolvent (certifient) la transaction. être enfin résolu. Soumettez et répondez.
L'objectif principal de l'introduction de la réplication de groupe est de résoudre le problème d'incohérence des données causé par la réplication asynchrone traditionnelle ou la réplication semi-synchrone. La réplication de groupe s'appuie sur le protocole de cohérence distribuée (une variante du protocole Paxos) pour atteindre la cohérence ultime des données distribuées et fournir une véritable solution de haute disponibilité des données (la question de savoir si elle est réellement hautement disponible reste à discuter). La solution multi-écriture qu’elle propose nous donne l’espoir de parvenir à une solution multi-active.
Dans l'environnement MGR, le nombre de serveurs doit être supérieur à 3 et un nombre impair pour implémenter l'algorithme 2/n+1.
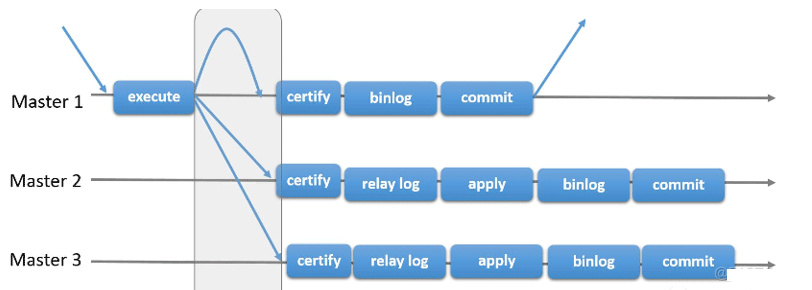
Un groupe de réplication se compose de plusieurs nœuds (instances de base de données). Chaque nœud du groupe conserve sa propre copie de données (Share Nothing) et implémente des messages atomiques et des messages ordonnés globaux via le protocole de cohérence pour implémenter des instances au sein du groupe. Cohérence des données.
Caractéristiques dont dispose désormais la solution MGR
Garantie de cohérence des données : Assurez-vous que la plupart des nœuds du cluster reçoivent les journaux
Prise en charge de l'écriture multi-nœuds : Tous les nœuds du cluster sont pris en charge en mode multi-écriture Écriture (mais en considérant des scénarios de simultanéité de 1 à élevée pour garantir une haute cohérence des données, la production ne choisit pas l'écriture multi-maître et utilise un cluster à maître unique)
Tolérance aux pannes : Assurez-vous que le système est toujours disponible en cas de panne (y compris split brain), la double écriture n'a aucun impact sur le système
L'impact actuel de la solution de MGR
ne prend en charge que les tables InnoDB, et chaque table doit avoir une clé primaire pour la détection des conflits de l'ensemble d'écriture
doit être ; activé la fonction GTID, le format de journal binaire doit être défini sur ROW, utilisé pour la sélection principale et le jeu d'écriture
COMMIT peut provoquer un échec, similaire au scénario d'échec du niveau d'isolement des transactions d'instantané
Actuellement, un MGR le cluster prend en charge jusqu'à 9 nœuds
Ne prend pas en charge les clés étrangères et les fonctionnalités de point de sauvegarde, ne peut pas effectuer de détection de contrainte globale et de restauration partielle
Le journal binaire ne prend pas en charge la somme de contrôle des événements binlog
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Créez une base de données à l'aide de NAVICAT Premium: Connectez-vous au serveur de base de données et entrez les paramètres de connexion. Cliquez avec le bouton droit sur le serveur et sélectionnez Créer une base de données. Entrez le nom de la nouvelle base de données et le jeu de caractères spécifié et la collation. Connectez-vous à la nouvelle base de données et créez le tableau dans le navigateur d'objet. Cliquez avec le bouton droit sur le tableau et sélectionnez Insérer des données pour insérer les données.
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Vous pouvez créer une nouvelle connexion MySQL dans NAVICAT en suivant les étapes: ouvrez l'application et sélectionnez une nouvelle connexion (CTRL N). Sélectionnez "MySQL" comme type de connexion. Entrez l'adresse Hostname / IP, le port, le nom d'utilisateur et le mot de passe. (Facultatif) Configurer les options avancées. Enregistrez la connexion et entrez le nom de la connexion.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
