

Tout d'abord, comprenons la structure de stockage de l'index. Ce n'est qu'en connaissant la structure de stockage de l'index que nous pourrons mieux comprendre le problème de l'échec de l'index.
La structure de stockage de l'index est liée au moteur de stockage MySQL. Différents moteurs de stockage utilisent des structures différentes.
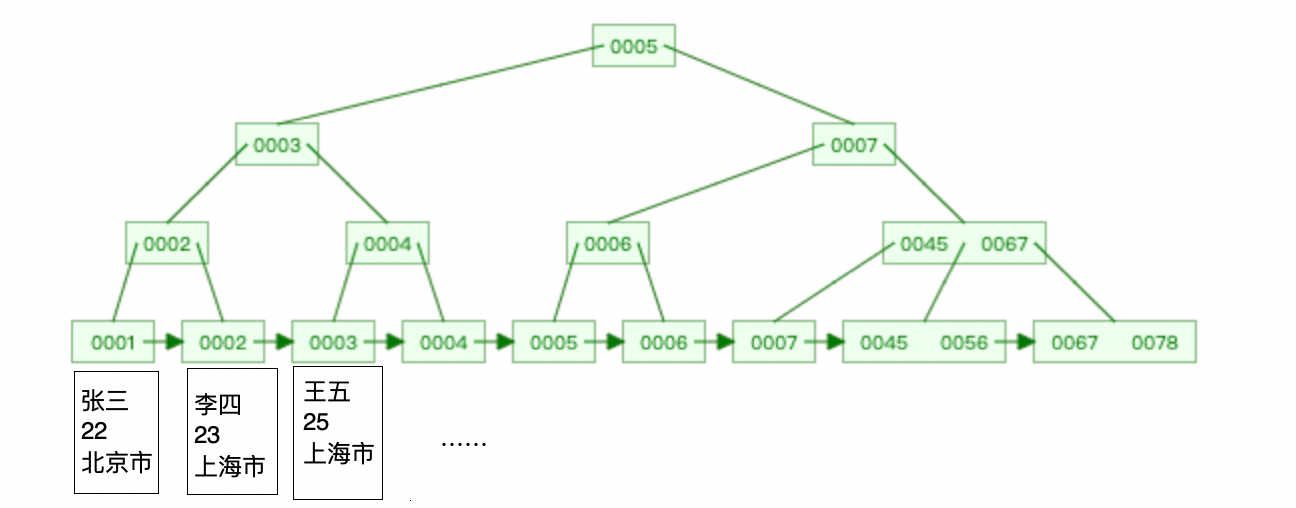
Le moteur de stockage par défaut de MySQL, InnoDB, utilise B+Tree comme structure de données d'index. Lors de la création d'une table, InnoDB créera par défaut un index de clé primaire, qui est un index clusterisé, et les autres index sont des index secondaires.
Le moteur de stockage MyISAM utilise l'index arborescent B+ par défaut lors de la création d'une table.
Bien que les deux prennent en charge les index arborescents B+ comme InnoDB, ils stockent les données de différentes manières
InnoDB est un index clusterisé (les nœuds feuilles de l'index arborescent B+ enregistrent les données eux-mêmes)
MyISAM est un index non clusterisé (le feuilles de l'arborescence B+ L'adresse physique où le nœud enregistre les données)
Comme le montre la figure ci-dessous :
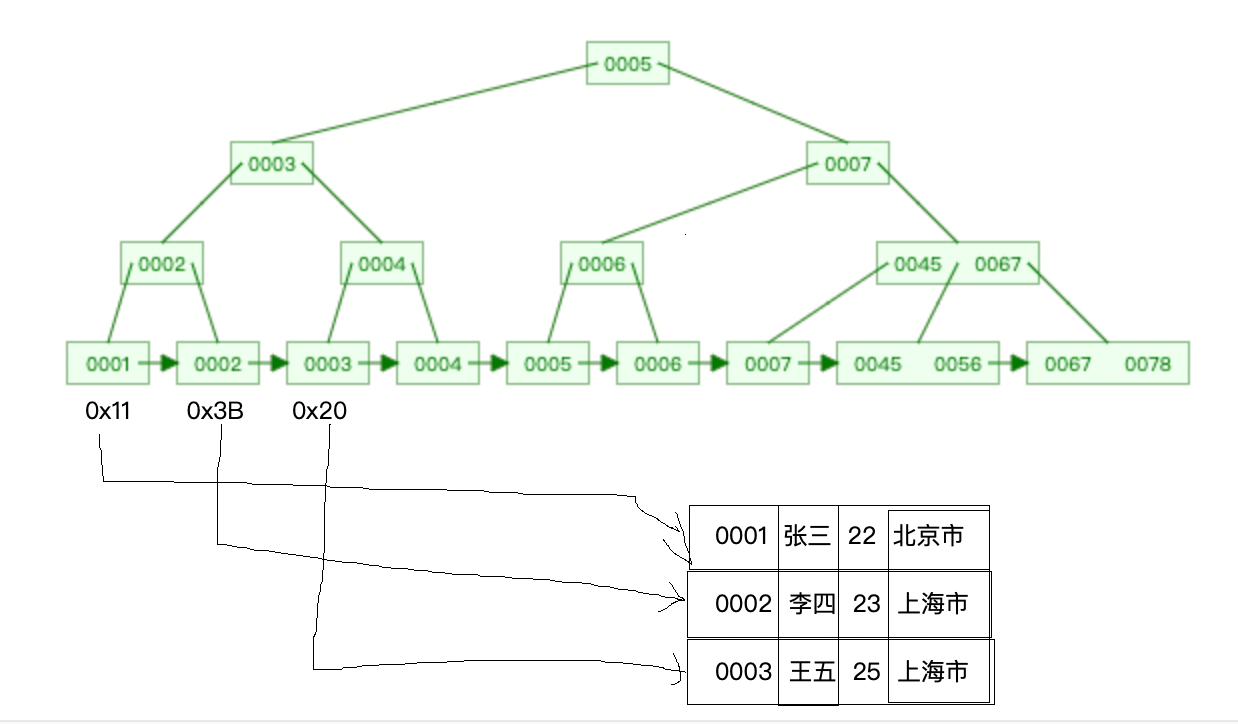
Le moteur de stockage InnoDB peut être divisé en [index clusterisé] et [index secondaire]. La différence entre eux réside dans les feuilles de l'index clusterisé. Les nœuds stockent les données réelles, toutes les données complètes sont stockées dans les nœuds feuilles de l'index clusterisé et les nœuds feuilles de l'index secondaire stockent les valeurs de clé primaire.
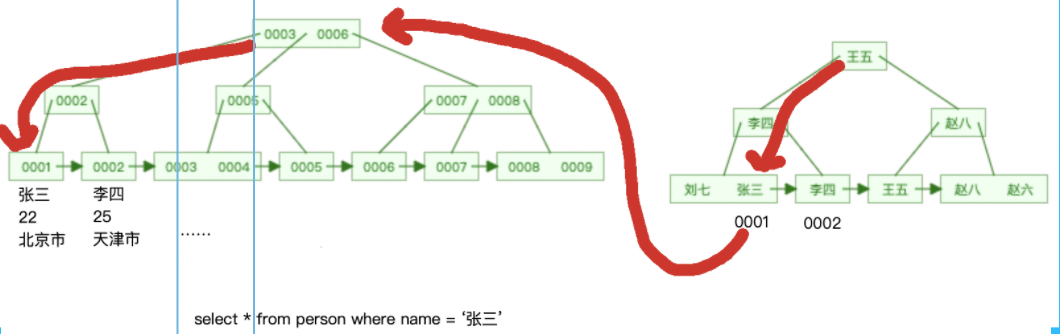
Lorsque vous utilisez le champ d'index secondaire comme condition de requête et interrogez les données sur l'index clusterisé,
trouvera d'abord le nœud feuille correspondant sur l'index secondaire pour obtenir la valeur de la clé primaire en fonction des conditions,
puis en fonction de la valeur de la clé primaire va à l'index clusterisé pour trouver le nœud feuille correspondant, puis interroge les données correspondantes
Ce processus est rappelé à la table
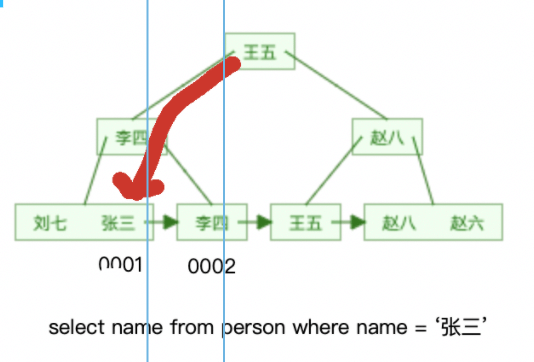
Utilisez l'index secondaire comme condition de requête et les données interrogées. se trouve dans le nœud feuille de l'index secondaire Lors du téléchargement, il vous suffit de trouver le nœud feuille correspondant à l'arbre B+ de l'index secondaire et de lire les données. Ce processus est appelé index de couverture
La requête ci-dessus conditionne tout. utilisez la colonne d'index, mais cela ne signifie pas qu'elle est utilisée. L'index de la colonne d'index prendra certainement effet. Examinons à nouveau la situation d'échec de l'index
Lors de l'utilisation d'une requête floue gauche ou gauche, cela est, comme "% Zhang" Ou comme "%张%" Ces deux méthodes de requête floue provoqueront un échec de l'indexlike "%张"或like "%张%"这两种模糊查询方式都会导致索引失效
因为B+树是根据索引值进行排列的,前缀不确定的时候可能是,“小张”,"二张"之类的所有的情况,就只能通过全表扫描的方式来查询
例如:SELECT * FROM sys_user WHERE LENGTH(user_id) = 3 ;

因为索引保存的是索引字段的原始值,而不是经过函数计算后的值,所以使用函数的时候就不会走索引了
不过从MySQL8.0开始,索引特性增加了函数索引,也就是针对该函数计算后的值建立一个索引,这样就可以通过扫描索引来查询数据了;
alter table t_user add key idx_name_length ((length(name)));
例如:select * from sys_user where user_id+1 =3;

但是如果是SELECT * FROM sys_user WHERE user_id = 1+1 ;这样的不在索引字段上进行计算,就又会走索引了

原因跟对索引使用函数差不多,索引保存的是索引字段的原始值,而不是运算后的值,所以无法走索引
这里的phone字段是二级索引,且是varchar类型的


使用整型作为查询参数的时候,执行计划中type为ALL,也就是通过全表扫描查询的,但如果是字符串类型,还是走索引查询的
我们再看一个例子
这里user_id
 Utilisez les fonctions sur l'index
Utilisez les fonctions sur l'index
SELECT * FROM sys_user WHERE LENGTH(user_id) = 3;</code >🎜🎜<img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/887/227/168525106945121.png" class="lazy" alt="Instance analyse de l'échec de l'index dans les détails de MySQL" />🎜🎜 Étant donné que l'index enregistre la valeur originale du champ d'index au lieu de la valeur calculée par la fonction, l'index ne sera pas utilisé lors de l'utilisation de la fonction. Cependant, à partir de MySQL 8.0, la fonction d'index ajoute la fonction index, qui est pour La valeur calculée par cette fonction crée un index, afin que les données puissent être interrogées en scannant l'index ; 🎜<div class="code" style="position:relative; padding:0px; margin:0px;"><div class="code" style="position:relative; padding:0px; margin:0px;"><pre class='brush:php;toolbar:false;'>SELECT * FROM sys_user WHERE phone = 18200000000 ;</pre><div class="contentsignin">Copier après la connexion</div></div><div class="contentsignin">Copier après la connexion</div></div>🎜 Effectuer un calcul d'expression sur l'index 🎜🎜 Par exemple : <code>select * depuis sys_user où user_id+1 =3;</ code>🎜🎜<img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/887/227/168525107040754.png" class="lazy" alt="Analyse d'instance d'échec de l'index dans les détails MySQL" />🎜 🎜Mais si <code>SELECT * FROM sys_user WHERE user_id = 1+1; n'est pas calculé sur le champ d'index, l'index sera à nouveau utilisé🎜🎜🎜🎜La raison est similaire à l'utilisation de fonctions sur index. L'index enregistre le champ d'index La valeur d'origine, pas la valeur calculée, donc l'index ne peut pas être utilisé🎜🎜Utilisez la conversion implicite pour l'index🎜🎜Le champ téléphone ici est un index secondaire et est de type varchar🎜🎜🎜🎜  🎜🎜Lors de l'utilisation d'entiers comme requête paramètres , le type dans le plan d'exécution est ALL, c'est-à-dire qu'il est interrogé via une analyse complète de la table, mais s'il s'agit d'un type chaîne, il est toujours interrogé par index 🎜🎜 Regardons un autre exemple 🎜🎜Ici
🎜🎜Lors de l'utilisation d'entiers comme requête paramètres , le type dans le plan d'exécution est ALL, c'est-à-dire qu'il est interrogé via une analyse complète de la table, mais s'il s'agit d'un type chaîne, il est toujours interrogé par index 🎜🎜 Regardons un autre exemple 🎜🎜Ici user_id est de type bigint, mais l'utilisation d'une chaîne comme paramètre de requête supprime toujours l'index 🎜🎜🎜🎜
为什么第一个例子导致了索引失效,而第二个不会呢?
这里就要了解一下MySQL的字符转换规则了,看是数字转字符串,还是字符串转数字
我们可以用select "10">9来测试一下
如果是数字转字符串,那么就相当于select "10">"9"结果应该是0
如果是字符串转数字,那么就相当于select 10>9,结果是1
在MySQL中的执行结果如下:

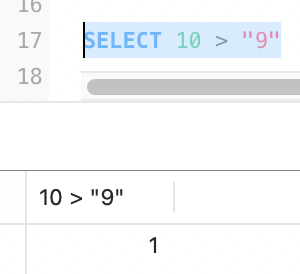
这就说明,MySQL在遇到数字与字符串的比较的时候,会自动把字符串转换为数字,然后进行比较
也就是说,在第一个例子中
SELECT * FROM sys_user WHERE phone = 18200000000 ;
相当于
SELECT * FROM sys_user WHERE CAST(phone AS UNSIGNED) = 18200000000 ;
这就在索引字段上使用了函数,所以导致索引失效
而在第二个例子中
SELECT * FROM sys_user WHERE user_id = "1" ;
相当于
SELECT * FROM sys_user WHERE user_id = CAST("1" AS UNSIGNED) ;函数式作用在查询参数上的,并没有作用在索引字段上,所以还是走索引的
多个普通字段组合在一起创建的索引叫做联合索引(组合索引)
在使用联合索引的时候,一定要注意顺序问题,联合索引的使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引匹配。
例如,创建了一个(a,b,c)联合索引,那么如果查询条件是一下几种,就可以匹配上联合索引
where a = 1
where a = 1 and b = 2
where a = 1 and b = 2 and c = 3
需要注意的是,因为有查询优化器,所以a字段在where子句中的顺序不重要
若缺少a字段,则以下几种情况由于不符合最左匹配原则将无法匹配联合索引,导致该联合索引失效
where b = 2
where c = 3
where b = 2 and c = 3
还有一个比较特殊的查询条件:where a = 1 and c = 3
在MySQL5.5的话,前面的a 会走索引,在联合索引找到主键值,然后回表,到主键索引读取数据行,然后在比对c字段的值
在MySQL5.6之后,有一个索引下推的功能,
下推就是将部分上层(服务层)负责的事情,交给了下层(引擎层)处理
存储引擎直接在联合索引里按照c=3过滤,按照过滤后的数据在进行回表扫描,减少了回表的次数,从而提升了性能
在执行计划中Extra = Using index condition就表示使用了索引下推

联合索引不遵循最左匹配原则的原因:在联合索引中,数据按照第一列索引进行排序,第一列数据相同时,才会按照第二列进行排序,以此类推,所以直接使用第二列进行查询的时候,联合索引就会失效
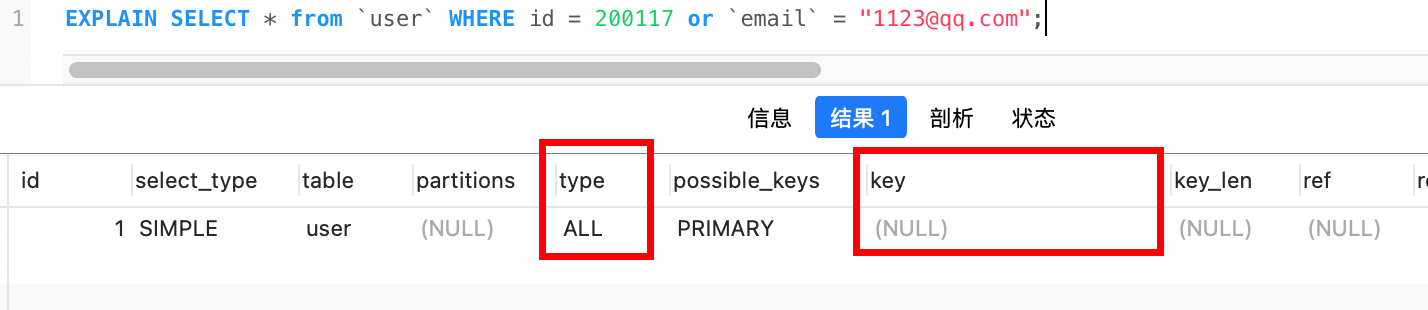
where子句中or的条件列有不是索引列会导致索引失效
例如:下图中id是索引列,email不是索引列,从执行计划来看,进行了全文扫描并没有使用到索引
因为or关键字只满足一个条件就可以,因此只要有一个列不是索引列,其他索引列也就没有意义了,就会进行全表扫描
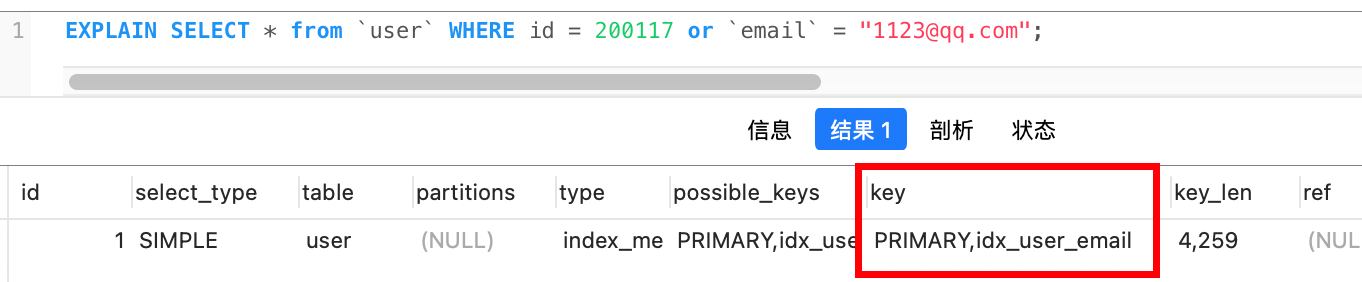
在email列上建立索引之后,可以看到执行计划中使用到了两个索引
type = index_merge表示对id 和email都进行了扫描,然后进行了合并
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



