
 Périphériques technologiques
IA
Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
Périphériques technologiques
IA
Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL

Les modèles d'apprentissage profond pour les tâches visuelles (telles que la classification d'images) sont généralement formés de bout en bout avec des données provenant d'un seul domaine visuel (telles que des images naturelles ou des images générées par ordinateur).
Généralement, une application qui effectue des tâches visuelles pour plusieurs champs doit créer plusieurs modèles pour chaque champ distinct et les former indépendamment. Les données ne sont pas partagées entre différents champs. Lors de l'inférence, les données d'entrée spécifiques à chaque champ de modèle seront traitées. .
Même s'ils sont orientés vers des domaines différents, certaines caractéristiques des premières couches entre ces modèles sont similaires, donc la formation conjointe de ces modèles est plus efficace. Cela réduit la latence et la consommation d'énergie, ainsi que le coût de la mémoire lié au stockage de chaque paramètre du modèle. Cette approche est appelée apprentissage multidomaine (MDL).
De plus, les modèles MDL peuvent également être meilleurs que les modèles à domaine unique. Une formation supplémentaire dans un domaine peut améliorer les performances du modèle dans un autre domaine, mais cela peut également produire des résultats négatifs. effets sur le transfert de connaissances, qui dépendent de la méthode de formation et de la combinaison de domaines spécifique. Bien que des travaux antérieurs sur MDL aient démontré l’efficacité des tâches d’apprentissage conjoint inter-domaines, ils impliquent une architecture de modèle élaborée à la main qui est inefficace lorsqu’elle est appliquée à d’autres travaux.

Lien papier : https://arxiv.org/pdf/2010.04904.pdf
Afin de résoudre ce problème, dans "Réseaux de neurones multi-chemins pour les réseaux multi-chemins sur appareil -domain Dans l'article "Visual Classification", les chercheurs de Google ont proposé un modèle MDL général.
L'article indique que ce modèle peut efficacement atteindre une grande précision, réduire le transfert de connaissances négatif, apprendre à améliorer le transfert de connaissances positif et optimiser efficacement le modèle conjoint face à des difficultés dans divers domaines spécifiques.
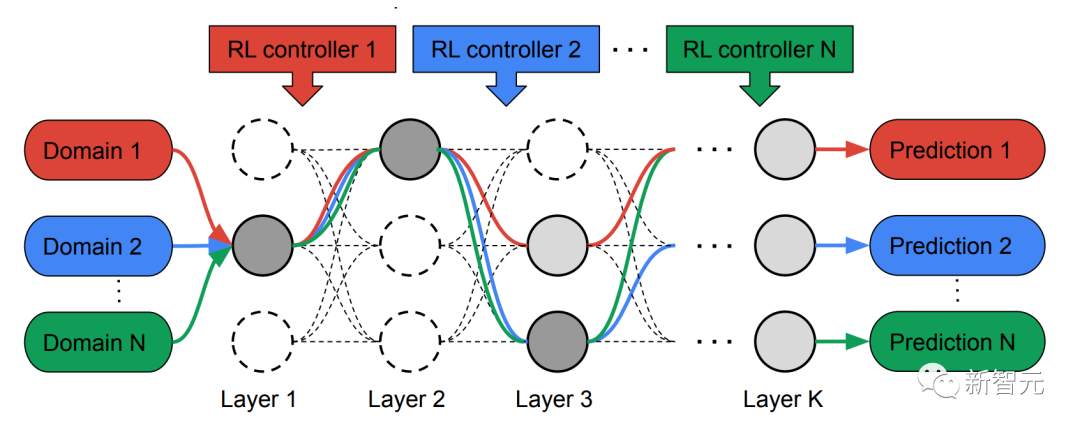
À cette fin, les chercheurs ont proposé une méthode de recherche d'architecture neuronale multi-chemins (MPNAS) pour construire un modèle unifié avec une architecture de réseau hétérogène pour plusieurs domaines.
Cette méthode étend la méthode efficace de recherche d'architecture neuronale (NAS) de la recherche à chemin unique à la recherche à chemins multiples pour trouver conjointement un chemin optimal pour chaque champ. Une nouvelle fonction de perte est également introduite, appelée Adaptive Balanced Domain Prioritization (ABDP), qui s'adapte aux difficultés spécifiques au domaine pour aider à entraîner efficacement les modèles. L’approche MPNAS qui en résulte est efficace et évolutive.
Tout en ne conservant aucune dégradation des performances, le nouveau modèle réduit la taille du modèle et les FLOPS de 78 % et 32 % respectivement par rapport aux méthodes à domaine unique.
Recherche de structure neuronale multi-chemins
Afin de promouvoir le transfert positif de connaissances et d'éviter le transfert négatif, la solution traditionnelle consiste à construire un modèle MDL afin que chaque domaine partage la plupart des couches et apprenne les caractéristiques communes de chaque domaine. (appelé extraction de fonctionnalités), puis créez des couches spécifiques au domaine par-dessus. Cependant, cette méthode d’extraction de caractéristiques ne peut pas gérer des domaines présentant des caractéristiques significativement différentes (tels que les objets dans des images naturelles et des peintures artistiques). D’un autre côté, construire une structure hétérogène unifiée pour chaque modèle MDL prend du temps et nécessite des connaissances spécifiques au domaine.
Cadre d'architecture de recherche neuronale multi-chemins NAS est un paradigme puissant pour la conception automatique d'architectures d'apprentissage en profondeur. Il définit un espace de recherche composé de divers éléments de base potentiels qui peuvent faire partie du modèle final.
L'algorithme de recherche trouve la meilleure architecture candidate dans l'espace de recherche pour optimiser les objectifs du modèle tels que la précision de la classification. Les méthodes NAS récentes telles que TuNAS améliorent l'efficacité de la recherche en utilisant un échantillonnage de chemin de bout en bout.
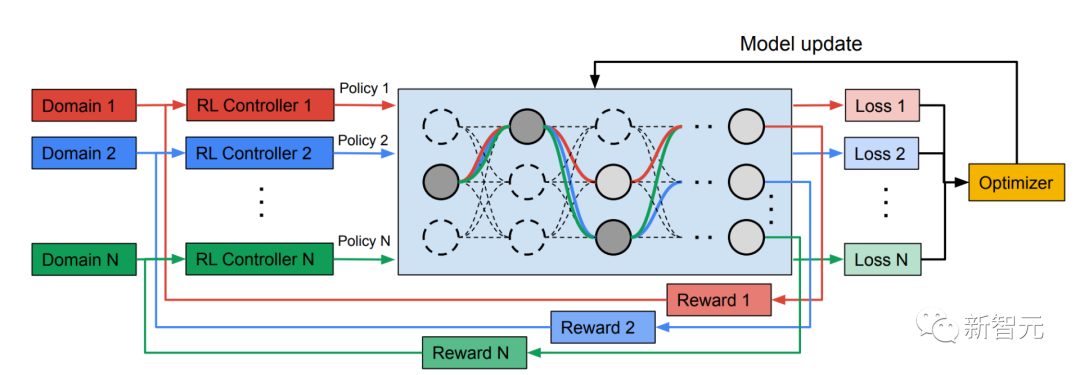
Inspiré de TuNAS, MPNAS construit l'architecture du modèle MDL en deux étapes : recherche et formation.
Dans la phase de recherche, afin de trouver conjointement un chemin optimal pour chaque domaine, MPNAS crée un contrôleur d'apprentissage par renforcement (RL) distinct pour chaque domaine, qui est tiré du super réseau (c'est-à-dire par la recherche Échantillonne des chemins de bout en bout (de la couche d'entrée à la couche de sortie) dans un sur-ensemble spatialement défini de tous les sous-réseaux possibles entre les nœuds candidats.
Au fil de plusieurs itérations, tous les contrôleurs RL mettent à jour les chemins pour optimiser les récompenses RL dans tous les domaines. A la fin de la phase de recherche, nous obtenons un sous-réseau pour chaque domaine. Enfin, tous les sous-réseaux sont combinés pour créer une structure hétérogène pour le modèle MDL, comme le montre la figure ci-dessous.
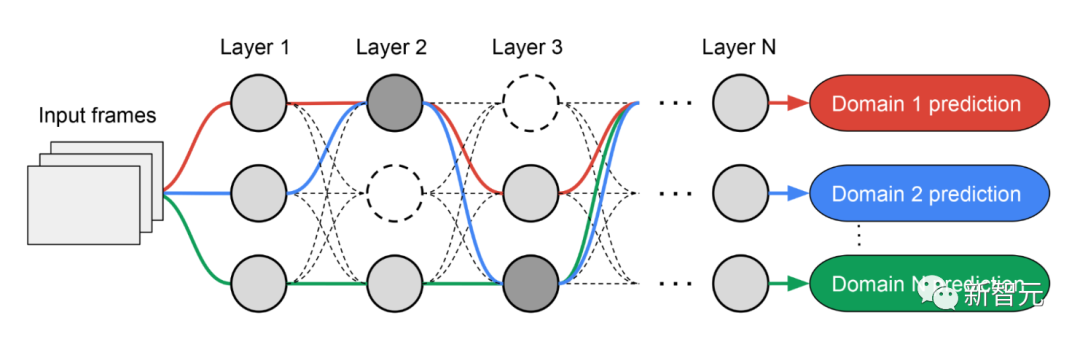
En raison des sous-titres de chacun domaine Le réseau est recherché indépendamment, de sorte que les éléments constitutifs de chaque couche peuvent être partagés par plusieurs domaines (c'est-à-dire des nœuds gris foncé), utilisés par un seul domaine (c'est-à-dire des nœuds gris clair) ou n'être utilisés par aucun sous-réseau (c'est-à-dire nœuds ponctuels).
Le chemin de chaque domaine peut également ignorer n'importe quelle couche pendant le processus de recherche. Le réseau de sortie est à la fois hétérogène et efficace, étant donné que les sous-réseaux sont libres de choisir les blocs à utiliser en cours de route de manière à optimiser les performances.
La figure suivante montre l'architecture de recherche de deux domaines de Visual Domain Decathlon.
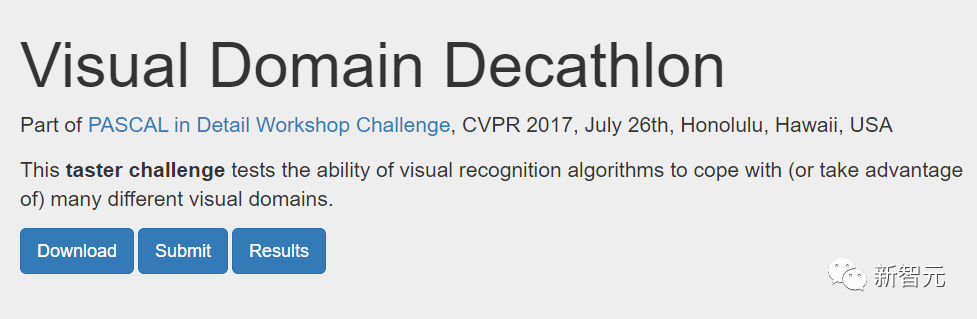
Visual Domain Decathlon est CVPR 201 7 Dans le cadre du PASCAL in Detail Workshop Challenge, la capacité des algorithmes de reconnaissance visuelle à gérer (ou exploiter) de nombreux domaines visuels différents a été testée. Comme on peut le constater, les sous-réseaux de ces deux domaines hautement liés (l’un rouge, l’autre vert) partagent la plupart des éléments constitutifs de leurs chemins qui se chevauchent, mais il existe encore des différences entre eux.
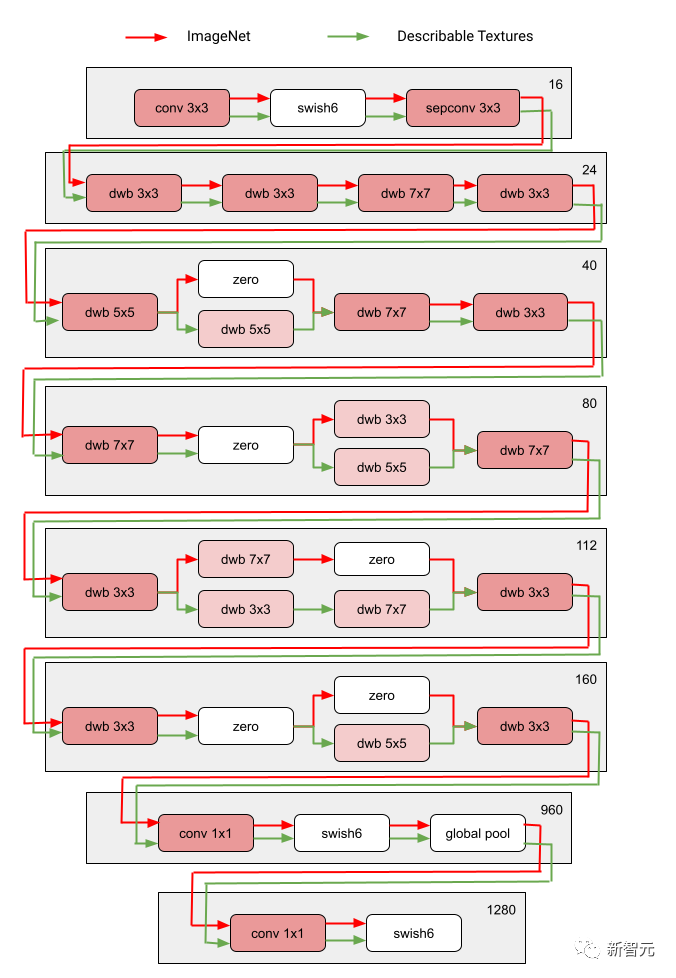
Les chemins rouges et verts sur la figure représentent respectivement les sous-réseaux d'ImageNet et des textures descriptibles, Les nœuds rose foncé représentent les blocs partagés par plusieurs domaines, et les nœuds rose clair représentent les blocs utilisés par chaque chemin. Le bloc « dwb » dans le diagramme représente le bloc dwbottleneck. Le bloc Zéro dans la figure indique que le sous-réseau ignore le bloc La figure ci-dessous montre la similarité des chemins dans les deux champs mentionnés ci-dessus. La similarité est mesurée par le score de similarité Jaccard entre les sous-réseaux pour chaque domaine, où plus élevé signifie plus de chemins similaires.

La photo montre le score de similarité Jaccard entre les chemins des dix domaines matrice de confusion. Le score varie de 0 à 1. Plus le score est élevé, plus les deux chemins partagent de nœuds.
Formation de modèles multi-domaines hétérogènes
Dans la deuxième phase, les modèles générés par MPNAS seront formés à partir de zéro pour tous les domaines. Pour ce faire, il est nécessaire de définir une fonction objectif unifiée pour tous les domaines. Pour gérer avec succès une grande variété de domaines, les chercheurs ont conçu un algorithme qui s'ajuste tout au long du processus d'apprentissage pour équilibrer les pertes entre les domaines, appelé Adaptive Balanced Domain Prioritization (ABDP). Ci-dessous montre la précision, la taille du modèle et les FLOPS des modèles formés dans différents paramètres. Nous comparons MPNAS avec trois autres méthodes : NAS indépendant du domaine : les modèles sont recherchés et formés séparément pour chaque domaine.
Multi-tête à chemin unique : utilisez un modèle pré-entraîné comme épine dorsale partagée pour tous les domaines, avec des têtes de classification distinctes pour chaque domaine.
NAS multi-têtes : recherchez une architecture de base unifiée pour tous les domaines, avec des têtes de classification distinctes pour chaque domaine.
D'après les résultats, nous pouvons observer que le NAS doit construire un ensemble de modèles pour chaque domaine, ce qui entraîne des modèles volumineux. Bien que les NAS multi-têtes et multi-têtes à chemin unique puissent réduire considérablement la taille du modèle et les FLOPS, forcer les domaines à partager le même backbone introduit un transfert de connaissances négatif, réduisant ainsi la précision globale.

En revanche, MPNAS peut créer des modèles petits et efficaces tout en conservant une précision globale élevée. La précision moyenne du MPNAS est même 1,9 % supérieure à celle de la méthode NAS indépendante du domaine, car le modèle est capable de réaliser un transfert actif de connaissances. La figure ci-dessous compare la meilleure précision par domaine de ces méthodes.
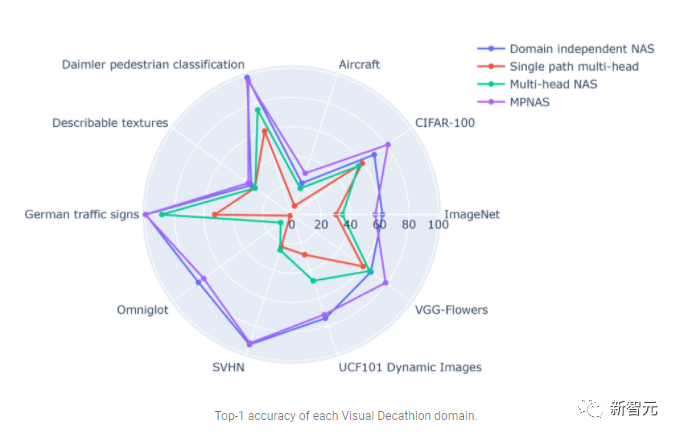
L'évaluation montre qu'en utilisant l'ABDP dans le cadre des étapes de recherche et de formation, la précision du top 1 passe de 69,96 % à 71,78 % (incrément : +1,81 %).
Future Directions
MPNAS est une solution efficace pour créer des réseaux hétérogènes afin de remédier au déséquilibre des données, à la diversité des domaines, à la migration négative, à l'évolutivité du domaine et au grand espace de recherche pour d'éventuelles stratégies de partage de paramètres dans MDL. En utilisant un espace de recherche de type MobileNet, le modèle généré est également adapté aux appareils mobiles. Pour les tâches incompatibles avec les algorithmes de recherche existants, les chercheurs continuent d'étendre MPNAS pour l'apprentissage multitâche et espèrent utiliser MPNAS pour créer des modèles multidomaines unifiés.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 YOLO est immortel ! YOLOv9 est sorti : performances et vitesse SOTA~
Feb 26, 2024 am 11:31 AM
YOLO est immortel ! YOLOv9 est sorti : performances et vitesse SOTA~
Feb 26, 2024 am 11:31 AM
Les méthodes d'apprentissage profond d'aujourd'hui se concentrent sur la conception de la fonction objectif la plus appropriée afin que les résultats de prédiction du modèle soient les plus proches de la situation réelle. Dans le même temps, une architecture adaptée doit être conçue pour obtenir suffisamment d’informations pour la prédiction. Les méthodes existantes ignorent le fait que lorsque les données d’entrée subissent une extraction de caractéristiques couche par couche et une transformation spatiale, une grande quantité d’informations sera perdue. Cet article abordera des problèmes importants lors de la transmission de données via des réseaux profonds, à savoir les goulots d'étranglement de l'information et les fonctions réversibles. Sur cette base, le concept d'information de gradient programmable (PGI) est proposé pour faire face aux différents changements requis par les réseaux profonds pour atteindre des objectifs multiples. PGI peut fournir des informations d'entrée complètes pour la tâche cible afin de calculer la fonction objectif, obtenant ainsi des informations de gradient fiables pour mettre à jour les pondérations du réseau. De plus, un nouveau cadre de réseau léger est conçu
 Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Jun 14, 2023 pm 01:43 PM
Cette 'erreur' n'est pas vraiment une erreur : commencez par quatre articles classiques pour comprendre ce qui ne va pas avec le schéma d'architecture du Transformer.
Jun 14, 2023 pm 01:43 PM
Il y a quelque temps, un tweet soulignant l'incohérence entre le schéma d'architecture du Transformer et le code de l'article de l'équipe Google Brain "AttentionIsAllYouNeed" a déclenché de nombreuses discussions. Certains pensent que la découverte de Sebastian était une erreur involontaire, mais elle est aussi surprenante. Après tout, compte tenu de la popularité du document Transformer, cette incohérence aurait dû être mentionnée mille fois. Sebastian Raschka a déclaré en réponse aux commentaires des internautes que le code « le plus original » était effectivement cohérent avec le schéma d'architecture, mais que la version du code soumise en 2017 a été modifiée, mais que le schéma d'architecture n'a pas été mis à jour en même temps. C’est aussi la cause profonde des discussions « incohérentes ».
 Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Les modèles d'apprentissage profond pour les tâches de vision (telles que la classification d'images) sont généralement formés de bout en bout avec des données provenant d'un seul domaine visuel (telles que des images naturelles ou des images générées par ordinateur). Généralement, une application qui effectue des tâches de vision pour plusieurs domaines doit créer plusieurs modèles pour chaque domaine distinct et les former indépendamment. Les données ne sont pas partagées entre différents domaines. Lors de l'inférence, chaque modèle gérera un domaine spécifique. Même s'ils sont orientés vers des domaines différents, certaines caractéristiques des premières couches entre ces modèles sont similaires, de sorte que la formation conjointe de ces modèles est plus efficace. Cela réduit la latence et la consommation d'énergie, ainsi que le coût de la mémoire lié au stockage de chaque paramètre du modèle. Cette approche est appelée apprentissage multidomaine (MDL). De plus, les modèles MDL peuvent également surpasser les modèles simples.
 Quelle est l'architecture et le principe de fonctionnement de Spring Data JPA ?
Apr 17, 2024 pm 02:48 PM
Quelle est l'architecture et le principe de fonctionnement de Spring Data JPA ?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA est basé sur l'architecture JPA et interagit avec la base de données via le mappage, l'ORM et la gestion des transactions. Son référentiel fournit des opérations CRUD et les requêtes dérivées simplifient l'accès à la base de données. De plus, il utilise le chargement paresseux pour récupérer les données uniquement lorsque cela est nécessaire, améliorant ainsi les performances.
 1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
Adresse papier : https://arxiv.org/abs/2307.09283 Adresse code : https://github.com/THU-MIG/RepViTRepViT fonctionne bien dans l'architecture ViT mobile et présente des avantages significatifs. Ensuite, nous explorons les contributions de cette étude. Il est mentionné dans l'article que les ViT légers fonctionnent généralement mieux que les CNN légers sur les tâches visuelles, principalement en raison de leur module d'auto-attention multi-têtes (MSHA) qui permet au modèle d'apprendre des représentations globales. Cependant, les différences architecturales entre les ViT légers et les CNN légers n'ont pas été entièrement étudiées. Dans cette étude, les auteurs ont intégré des ViT légers dans le système efficace.
 Quelle est la courbe d'apprentissage de l'architecture du framework Golang ?
Jun 05, 2024 pm 06:59 PM
Quelle est la courbe d'apprentissage de l'architecture du framework Golang ?
Jun 05, 2024 pm 06:59 PM
La courbe d'apprentissage de l'architecture du framework Go dépend de la familiarité avec le langage Go et le développement back-end ainsi que de la complexité du framework choisi : une bonne compréhension des bases du langage Go. Il est utile d’avoir une expérience en développement back-end. Les cadres qui diffèrent en complexité entraînent des différences dans les courbes d'apprentissage.
 Savez-vous que les programmeurs seront en déclin dans quelques années ?
Nov 08, 2023 am 11:17 AM
Savez-vous que les programmeurs seront en déclin dans quelques années ?
Nov 08, 2023 am 11:17 AM
Le magazine "ComputerWorld" a écrit un article disant que "la programmation disparaîtra d'ici 1960" parce qu'IBM a développé un nouveau langage FORTRAN, qui permet aux ingénieurs d'écrire les formules mathématiques dont ils ont besoin, puis de les soumettre à l'ordinateur pour que la programmation se termine. Picture Quelques années plus tard, nous avons entendu un nouveau dicton : tout homme d'affaires peut utiliser des termes commerciaux pour décrire ses problèmes et dire à l'ordinateur quoi faire. Grâce à ce langage de programmation appelé COBOL, les entreprises n'ont plus besoin de programmeurs. Plus tard, il est dit qu'IBM a développé un nouveau langage de programmation appelé RPG qui permet aux employés de remplir des formulaires et de générer des rapports, de sorte que la plupart des besoins de programmation de l'entreprise puissent être satisfaits grâce à lui.
 Exploration des réseaux siamois en utilisant la perte contrastive pour la comparaison de similarité d'images
Apr 02, 2024 am 11:37 AM
Exploration des réseaux siamois en utilisant la perte contrastive pour la comparaison de similarité d'images
Apr 02, 2024 am 11:37 AM
Introduction Dans le domaine de la vision par ordinateur, mesurer avec précision la similarité des images est une tâche critique avec un large éventail d'applications pratiques. Des moteurs de recherche d’images aux systèmes de reconnaissance faciale en passant par les systèmes de recommandation basés sur le contenu, la capacité de comparer et de trouver efficacement des images similaires est importante. Le réseau siamois combiné à la perte contrastive fournit un cadre puissant pour apprendre la similarité des images de manière basée sur les données. Dans cet article de blog, nous plongerons dans les détails des réseaux siamois, explorerons le concept de perte contrastive et explorerons comment ces deux composants fonctionnent ensemble pour créer un modèle de similarité d'image efficace. Premièrement, le réseau siamois se compose de deux sous-réseaux identiques partageant les mêmes poids et paramètres. Chaque sous-réseau code l'image d'entrée dans un vecteur de caractéristiques, qui
