
 Périphériques technologiques
IA
Google n'ouvre pas PaLM en source ouverte, mais les internautes l'ouvrent en source ! Version miniature de centaines de milliards de paramètres : le maximum n'est que de 1 milliard, contexte 8k
Périphériques technologiques
IA
Google n'ouvre pas PaLM en source ouverte, mais les internautes l'ouvrent en source ! Version miniature de centaines de milliards de paramètres : le maximum n'est que de 1 milliard, contexte 8k
Google n'ouvre pas PaLM en source ouverte, mais les internautes l'ouvrent en source ! Version miniature de centaines de milliards de paramètres : le maximum n'est que de 1 milliard, contexte 8k

Google n'a pas de PaLM open source, mais les internautes l'ont open source.
Hier, un développeur a open sourceé trois versions miniatures du modèle PaLM sur GitHub : les paramètres sont 150 millions (PalM-150m), 410 millions (PalM -410m) et 1 milliard (PalM-1b).
Adresse du projet : https://github.com/conceptofmind/PaLM
Ces trois modèles ont été entraînés sur l'ensemble de données Google C4 avec une longueur de contexte de 8k. À l'avenir, des modèles comportant 2 milliards de paramètres seront formés.
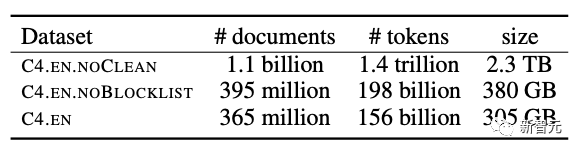
Ensemble de données Google C4
#🎜 🎜 #Open Source PaLMExemple généré à l'aide d'un modèle à 410 millions de paramètres :
Mon chien est très mignon, mais pas très doué pour socialiser avec d'autres chiens. Le chien aime toutes les nouvelles personnes et il aime sortir avec d'autres chiens. J'ai besoin de l'emmener au parc avec d'autres chiens. Il a une mauvaise haleine de chiot, mais ce n'est que lorsqu'il s'enfuit. une direction dans laquelle il ne veut pas aller. Actuellement, mon chien est très méchant. Il aimerait se dire bonjour dans le parc, mais il préfère prendre grand soin de lui pendant un moment. Il a aussi mauvaise haleine. Je vais devoir lui procurer des appareils orthodontiques. Cela fait 3 mois. Le chien a des douleurs mordantes autour de la bouche. Le chien est très timide et a peur. Le chien est très joueur et ils sont un peu. gâté. Je ne sais pas si c'est un truc de chien ou s'il est gâté. Il adore ses jouets et veut juste jouer avec ses jouets tout le temps et fait même des promenades. Il est un peu difficile, pas très bon. avec d'autres chiens . Le chien est juste un petit chiot qui va au parc C'est un chien super sympathique Il n'a pas eu de mauvaise gueule ni de mauvaise haleineMon chien est très mignon, mais il n'est pas doué avec les autres. Ce chien aime toutes les nouvelles personnes et il adore jouer avec d'autres chiens. Je dois l'emmener au parc avec les autres chiens. Il a un peu l'haleine d'un chiot, mais seulement lorsqu'il court dans une direction où il ne veut pas aller. Maintenant, mon chien est très méchant. Il voulait dire bonjour dans le parc, mais préférait prendre soin de lui pendant un moment. Il a aussi mauvaise haleine. Cela fait trois mois que je devais lui acheter un appareil dentaire. Le chien a des marques de morsures douloureuses autour de la bouche. Ce chien est très timide et effrayé. Ce chien est très joueur et il est un peu gâté. Je ne sais pas si c'est la faute du chien ou s'il est simplement gâté. Il adore ses jouets et veut juste jouer avec eux. Il joue toujours avec ses jouets et se promène même. Il est un peu difficile et ne s'entend pas bien avec les autres chiens. Le chien n'était qu'un chiot qui allait au parc. C'est un chien super sympathique. Il n'a plus de problème de mauvaise haleine.Bien que les paramètres soient effectivement un peu petits, l'effet généré est quand même un peu difficile à décrire...
Ces modèles sont compatibles avec de nombreux référentiels Lucidrain Popular tels que Toolformer-pytorch, Palm-rlhf-pytorch et Palm-pytorch.
Les trois derniers modèles open source sont des modèles de base et seront formés sur des ensembles de données à plus grande échelle.
Tous les modèles seront ajustés davantage avec des instructions sur FLAN pour fournir des modèles flan-PaLM.
En termes d'algorithme d'optimisation, l'atténuation de poids découplée Adam W est utilisée, mais vous pouvez également choisir d'utiliser l'écurie Adam W de Mitchell Wortsman.
Actuellement, le modèle a été téléchargé sur le hub Torch et les fichiers sont également stockés dans le hub Huggingface.
Si le modèle ne peut pas être téléchargé correctement depuis le hub Torch, assurez-vous d'effacer les points de contrôle et les dossiers de modèles dans .cache/torch/hub/ . Si le problème n'est toujours pas résolu, vous pouvez télécharger le fichier depuis le référentiel de Huggingface. Actuellement, l’intégration de Huggingface est en cours.
Toutes les données d'entraînement ont été pré-étiquetées avec le tagger GPTNEOX et la longueur de la séquence est réduite à 8192. Cela permettra d’économiser des coûts importants de prétraitement des données.
Ces ensembles de données ont été stockés sur Huggingface au format parquet, et vous pouvez trouver les morceaux de données individuels ici : C4 Chunk 1, C4 Chunk 2, C4 Chunk 3, C4 Chunk 4 et C4 Chunk 5.
Il existe une autre option dans le script de formation distribué, pour ne pas utiliser l'ensemble de données C4 pré-étiqueté fourni, mais pour charger et traiter un autre ensemble de données comme openwebtext.
Installation
Une vague d'installation est requise avant d'essayer d'exécuter le modèle.
<code>git clone https://github.com/conceptofmind/PaLM.gitcd PaLM/pip3 install -r requirements.txt</code>
En utilisant
, vous pouvez charger des modèles pré-entraînés à l'aide de Torch Hub pour une formation supplémentaire ou un réglage précis :
<code>model = torch.hub.load("conceptofmind/PaLM", "palm_410m_8k_v0").cuda()</code>De plus, vous pouvez également charger directement les points de contrôle du modèle PyTorch via la méthode suivante :
<code>from palm_rlhf_pytorch import PaLMmodel = PaLM(num_tokens=50304, dim=1024, depth=24, dim_head=128, heads=8, flash_attn=True, qk_rmsnorm = False,).cuda()model.load('/palm_410m_8k_v0.pt')</code>Pour utiliser le modèle pour générer du texte, vous pouvez utiliser la ligne de commande :
prompt - Invite pour générer du texte.
seq_len - la longueur de séquence du texte généré, la valeur par défaut est 256.
température - température d'échantillonnage, la valeur par défaut est 0,8
filter_thres - seuil de filtre utilisé pour l'échantillonnage. La valeur par défaut est 0,9.
model - le modèle utilisé pour la génération. Il existe trois paramètres différents (150m, 410m, 1b) : palm_150m_8k_v0, palm_410m_8k_v0, palm_1b_8k_v0.
<code>python3 inference.py "My dog is very cute" --seq_len 256 --temperature 0.8 --filter_thres 0.9 --model "palm_410m_8k_v0"</code>
Pour améliorer les performances, le raisonnement utilise torch.compile(), Flash Attention et Hidet.
Si vous souhaitez étendre la génération en ajoutant un traitement de flux ou d'autres fonctions, l'auteur fournit un script d'inférence général "inference.py".
Formation
Ces modèles "Open Source Palm" sont formés sur 64 GPU A100 (80Go).
Afin de faciliter la formation des modèles, l'auteur propose également un script de formation distribué train_distributed.py.
Vous pouvez librement modifier la couche de modèle et la configuration des hyperparamètres pour répondre aux exigences matérielles, et vous pouvez également charger les poids du modèle et modifier le script d'entraînement pour affiner le modèle.
Enfin, l'auteur a déclaré qu'il ajouterait un script de réglage spécifique et explorerait LoRA à l'avenir.

Données
Différents ensembles de données peuvent être prétraités en exécutant le script build_dataset.py de la même manière que l'ensemble de données C4 utilisé lors de la formation. Cela pré-étiquetera les données, les divisera en morceaux d'une longueur de séquence spécifiée et les téléchargera sur le hub Huggingface.
Par exemple :
<code>python3 build_dataset.py --seed 42 --seq_len 8192 --hf_account "your_hf_account" --tokenizer "EleutherAI/gpt-neox-20b" --dataset_name "EleutherAI/the_pile_deduplicated"</code>
PaLM 2 arrive
En avril 2022, Google a officiellement annoncé pour la première fois PaLM avec 540 milliards de paramètres. Comme les autres LLM, PaLM peut effectuer diverses tâches de génération et d’édition de texte.
PaLM est la première utilisation à grande échelle par Google du système Pathways pour étendre la formation à 6 144 puces, ce qui constitue la plus grande configuration système basée sur TPU utilisée pour la formation à ce jour.
Sa capacité de compréhension est exceptionnelle. Non seulement il peut comprendre les blagues, mais il peut également expliquer les points amusants à vous qui ne comprenez pas.

À la mi-mars seulement, Google a ouvert pour la première fois son API de grand modèle de langage PaLM. Cela signifie que les utilisateurs peuvent l'utiliser pour effectuer des tâches telles que résumer du texte, écrire du code et même convertir PaLM Train en un chatbot conversationnel comme ChatGPT.
 Lors de la prochaine conférence annuelle I/O de Google, Pichai annoncera les derniers développements de l'entreprise dans le domaine de l'IA.
Lors de la prochaine conférence annuelle I/O de Google, Pichai annoncera les derniers développements de l'entreprise dans le domaine de l'IA.
On dit que le modèle de langage à grande échelle le plus récent et le plus avancé, PaLM 2, sera bientôt lancé.
PaLM 2 contient plus de 100 langues et fonctionne sous le nom de code interne "Unified Language Model". Il effectue également des tests approfondis en codage et en mathématiques ainsi qu'en écriture créative.
Le mois dernier, Google a déclaré que son LLM médical « Med-PalM2 » pouvait répondre aux questions d'examen médical avec une précision de 85 % au « niveau du médecin expert ».
De plus, Google sortira également le robot de chat Bard supporté par les grands modèles, ainsi qu'une expérience générative pour la recherche.
Reste à voir si la dernière version de l'IA pourra redresser le dos de Google.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment commenter Deepseek
Feb 19, 2025 pm 05:42 PM
Comment commenter Deepseek
Feb 19, 2025 pm 05:42 PM
Deepseek est un puissant outil de récupération d'informations. .
 Comment rechercher Deepseek
Feb 19, 2025 pm 05:39 PM
Comment rechercher Deepseek
Feb 19, 2025 pm 05:39 PM
Deepseek est un moteur de recherche propriétaire qui ne recherche que dans une base de données ou un système spécifique, plus rapide et plus précis. Lorsque vous l'utilisez, il est conseillé aux utilisateurs de lire le document, d'essayer différentes stratégies de recherche, de demander de l'aide et des commentaires sur l'expérience utilisateur afin de tirer le meilleur parti de leurs avantages.
 Sesame Open Door Exchange Page d'enregistrement de page Enregistrement Gate Trading App The Registration Site Web
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Page d'enregistrement de page Enregistrement Gate Trading App The Registration Site Web
Feb 28, 2025 am 11:06 AM
Cet article présente le processus d'enregistrement de la version Web de Sesame Open Exchange (GATE.IO) et l'application Gate Trading en détail. Qu'il s'agisse de l'enregistrement Web ou de l'enregistrement de l'application, vous devez visiter le site Web officiel ou l'App Store pour télécharger l'application authentique, puis remplir le nom d'utilisateur, le mot de passe, l'e-mail, le numéro de téléphone mobile et d'autres informations et terminer la vérification des e-mails ou du téléphone mobile.
 Pourquoi le lien d'échange de Bybit ne peut-il pas être téléchargé directement et installé?
Feb 21, 2025 pm 10:57 PM
Pourquoi le lien d'échange de Bybit ne peut-il pas être téléchargé directement et installé?
Feb 21, 2025 pm 10:57 PM
Pourquoi le lien d'échange de Bybit ne peut-il pas être téléchargé directement et installé? Bybit est un échange de crypto-monnaie qui fournit des services de trading aux utilisateurs. Les applications mobiles de l'échange ne peuvent pas être téléchargées directement via AppStore ou GooglePlay pour les raisons suivantes: 1. La politique de l'App Store empêche Apple et Google d'avoir des exigences strictes sur les types d'applications autorisées dans l'App Store. Les demandes d'échange de crypto-monnaie ne répondent souvent pas à ces exigences car elles impliquent des services financiers et nécessitent des réglementations et des normes de sécurité spécifiques. 2. Conformité des lois et réglementations Dans de nombreux pays, les activités liées aux transactions de crypto-monnaie sont réglementées ou restreintes. Pour se conformer à ces réglementations, l'application ByBit ne peut être utilisée que via des sites Web officiels ou d'autres canaux autorisés
 Sesame Open Door Trading Platform Download Version mobile Gateio Trading Plateforme de téléchargement Adresse de téléchargement
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Version mobile Gateio Trading Plateforme de téléchargement Adresse de téléchargement
Feb 28, 2025 am 10:51 AM
Il est crucial de choisir un canal formel pour télécharger l'application et d'assurer la sécurité de votre compte.
 Top 10 recommandé pour l'application de trading d'actifs numériques crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 recommandé pour l'application de trading d'actifs numériques crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Cet article recommande les dix principales plates-formes de trading de crypto-monnaie qui méritent d'être prêtées, notamment Binance, Okx, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, Bydfi et Xbit décentralisées. Ces plateformes ont leurs propres avantages en termes de quantité de devises de transaction, de type de transaction, de sécurité, de conformité et de fonctionnalités spéciales. Le choix d'une plate-forme appropriée nécessite une considération complète en fonction de votre propre expérience de trading, de votre tolérance au risque et de vos préférences d'investissement. J'espère que cet article vous aide à trouver le meilleur costume pour vous-même
 Binance Binance Site officiel Dernière version Portail de connexion
Feb 21, 2025 pm 05:42 PM
Binance Binance Site officiel Dernière version Portail de connexion
Feb 21, 2025 pm 05:42 PM
Pour accéder à la dernière version du portail de connexion du site Web de Binance, suivez simplement ces étapes simples. Accédez au site officiel et cliquez sur le bouton "Connectez-vous" dans le coin supérieur droit. Sélectionnez votre méthode de connexion existante. Entrez votre numéro de mobile ou votre mot de passe enregistré et votre mot de passe et complétez l'authentification (telles que le code de vérification mobile ou Google Authenticator). Après une vérification réussie, vous pouvez accéder à la dernière version du portail de connexion du site Web officiel de Binance.
 La dernière adresse de téléchargement de Bitget en 2025: étapes pour obtenir l'application officielle
Feb 25, 2025 pm 02:54 PM
La dernière adresse de téléchargement de Bitget en 2025: étapes pour obtenir l'application officielle
Feb 25, 2025 pm 02:54 PM
Ce guide fournit des étapes de téléchargement et d'installation détaillées pour l'application officielle Bitget Exchange, adaptée aux systèmes Android et iOS. Le guide intègre les informations de plusieurs sources faisant autorité, y compris le site officiel, l'App Store et Google Play, et met l'accent sur les considérations pendant le téléchargement et la gestion des comptes. Les utilisateurs peuvent télécharger l'application à partir des chaînes officielles, y compris l'App Store, le téléchargement officiel du site Web APK et le saut de site Web officiel, ainsi que des paramètres d'enregistrement, de vérification d'identité et de sécurité. De plus, le guide couvre les questions et considérations fréquemment posées, telles que
