
 Périphériques technologiques
IA
En 24 heures et 200 $ pour copier le processus RLHF, Stanford a ouvert la « Ferme Alpaca »
Périphériques technologiques
IA
En 24 heures et 200 $ pour copier le processus RLHF, Stanford a ouvert la « Ferme Alpaca »
En 24 heures et 200 $ pour copier le processus RLHF, Stanford a ouvert la « Ferme Alpaca »

Fin février, Meta a open source une grande série de modèles LLaMA (traduit littéralement par alpaga), avec des paramètres allant de 7 milliards à 65 milliards, qui est appelée le prototype de la version Meta de ChatGPT. Par la suite, des institutions telles que l'Université de Stanford et l'Université de Californie à Berkeley ont réalisé des « innovations secondaires » basées sur LLaMA et ont lancé successivement plusieurs grands modèles open source tels que Alpaca et Vicuna. Pendant un certain temps, « Alpaca » est devenu le modèle haut de gamme. dans le cercle de l'IA. Ces modèles de type ChatGPT construits par la communauté open source itèrent très rapidement et sont hautement personnalisables. Ils sont appelés le remplacement open source de ChatGPT.
Cependant, la raison pour laquelle ChatGPT peut montrer de puissantes capacités en matière de compréhension, de génération, de raisonnement, etc. de texte est parce qu'OpenAI utilise un nouveau paradigme de formation pour les grands modèles tels que ChatGPT - RLHF (Reinforcement Learning from Human Feedback). , le modèle de langage est optimisé sur la base des commentaires humains grâce à l'apprentissage par renforcement. Grâce aux méthodes RLHF, les grands modèles de langage peuvent être alignés sur les préférences humaines, suivre l'intention humaine et minimiser les résultats inutiles, déformés ou biaisés. Cependant, la méthode RLHF repose sur une annotation et une évaluation manuelles approfondies, ce qui nécessite souvent des semaines et des milliers de dollars pour collecter des commentaires humains, ce qui est coûteux.
Maintenant, l'Université de Stanford, qui a lancé le modèle open source Alpaca, a proposé un autre simulateur - AlpacaFarm (traduit littéralement par ferme d'alpaga). AlpacaFarm peut reproduire le processus RLHF en 24 heures pour seulement environ 200 $, permettant aux modèles open source d'améliorer rapidement les résultats d'évaluation humaine, que l'on peut appeler l'équivalent du RLHF.

AlpacaFarm tente de développer rapidement et de manière rentable des méthodes d'apprentissage à partir des commentaires humains. Pour ce faire, l’équipe de recherche de Stanford a d’abord identifié trois difficultés principales dans l’étude des méthodes RLHF : le coût élevé des données sur les préférences humaines, le manque d’évaluations fiables et le manque d’implémentations de référence.
Pour résoudre ces trois problèmes, AlpacaFarm a construit des implémentations spécifiques d'annotateurs de simulation, d'évaluation automatique et de méthodes SOTA. Actuellement, le code du projet AlpacaFarm est open source.
- Adresse GitHub : https://github.com/tatsu-lab/alpaca_farm
- Adresse papier : https://tatsu-lab.github.io/alpaca_farm_paper. pdf
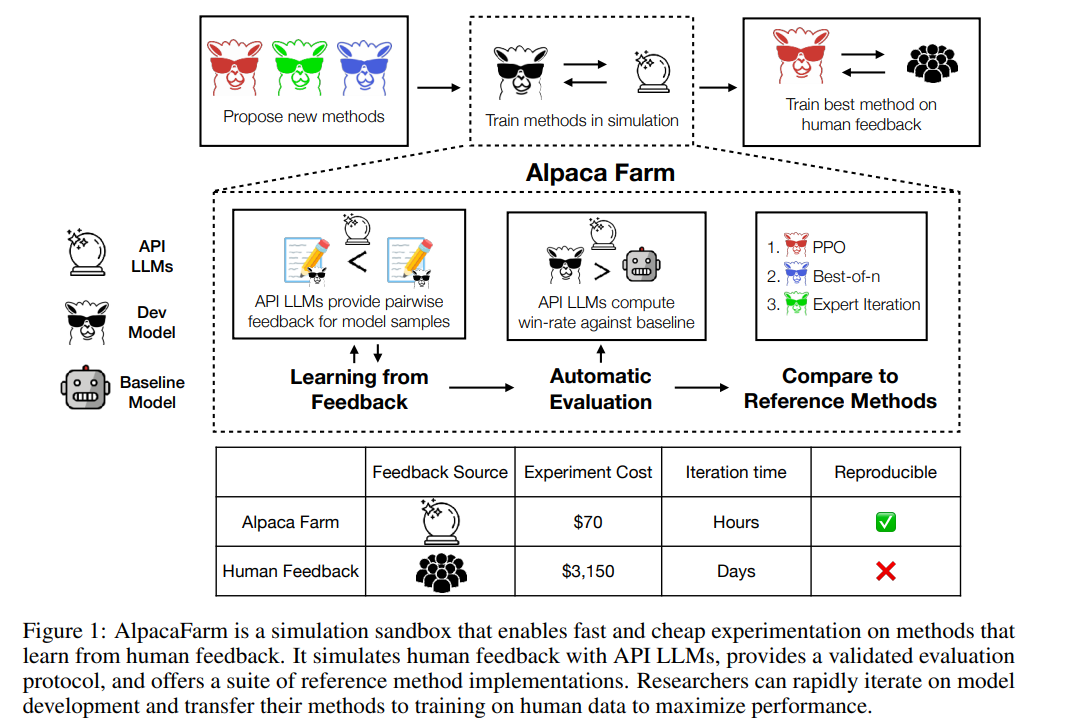
Comme le montre la figure ci-dessous, les chercheurs peuvent utiliser le simulateur AlpacaFarm pour développer rapidement de nouvelles méthodes d'apprentissage à partir des données de rétroaction humaine, et peuvent également migrer les méthodes SOTA existantes vers des données de préférences humaines réelles.
Annotateur de simulation
AlpacaFarm est construit sur la base de 52 000 instructions de l'ensemble de données Alpaca, dont 10 000 instructions sont utilisées pour affiner l'instruction de base suivant le modèle, et les 42 000 instructions restantes sont utilisées pour apprendre les préférences et l'évaluation humaines, et principalement utilisé pour apprendre à partir d'annotateurs simulés. Cette étude aborde les trois défis majeurs que sont le coût de l'annotation, l'évaluation et la vérification de la mise en œuvre de la méthode RLHF, et propose des solutions une par une.
Tout d'abord, pour réduire les coûts d'annotation, cette étude a créé des invites pour les LLM accessibles par API (tels que GPT-4, ChatGPT), permettant à AlpacaFarm de simuler les commentaires humains pour seulement 1/45 du coût de la collecte de données à l'aide du RLHF. méthode. Cette étude a conçu un schéma d'annotation aléatoire et bruyant utilisant 13 invites différentes pour extraire différentes préférences humaines à partir de plusieurs LLM. Ce schéma d'annotation vise à capturer différents aspects du feedback humain, tels que les jugements de qualité, la variabilité entre les annotateurs et les préférences de style.
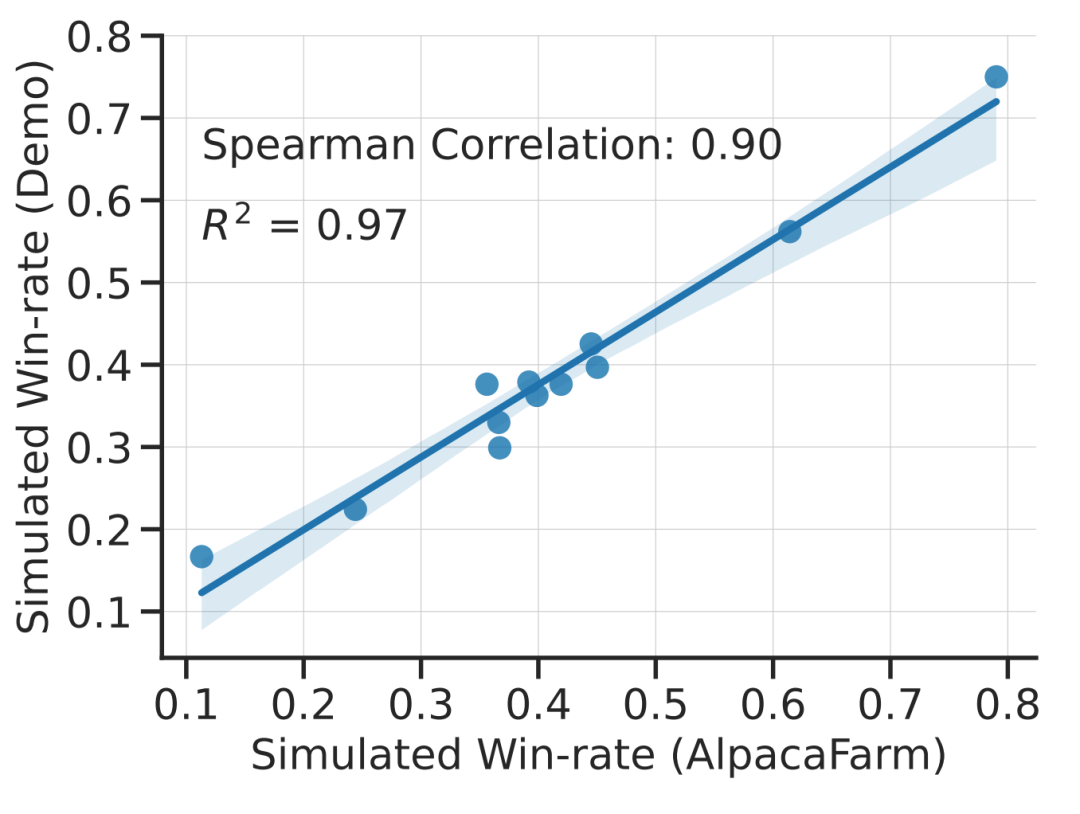
Cette étude montre expérimentalement que la simulation d’AlpacaFarm est précise. Lorsque l'équipe de recherche a utilisé AlpacaFarm pour former et développer des méthodes, celles-ci se sont classées de manière très cohérente avec les mêmes méthodes formées et développées à l'aide de commentaires humains réels. La figure ci-dessous montre la forte corrélation dans les classements entre les méthodes résultant du workflow de simulation AlpacaFarm et le workflow de feedback humain. Cette propriété est cruciale car elle montre que les conclusions expérimentales tirées des simulations sont susceptibles de s’avérer vraies dans des situations réelles.
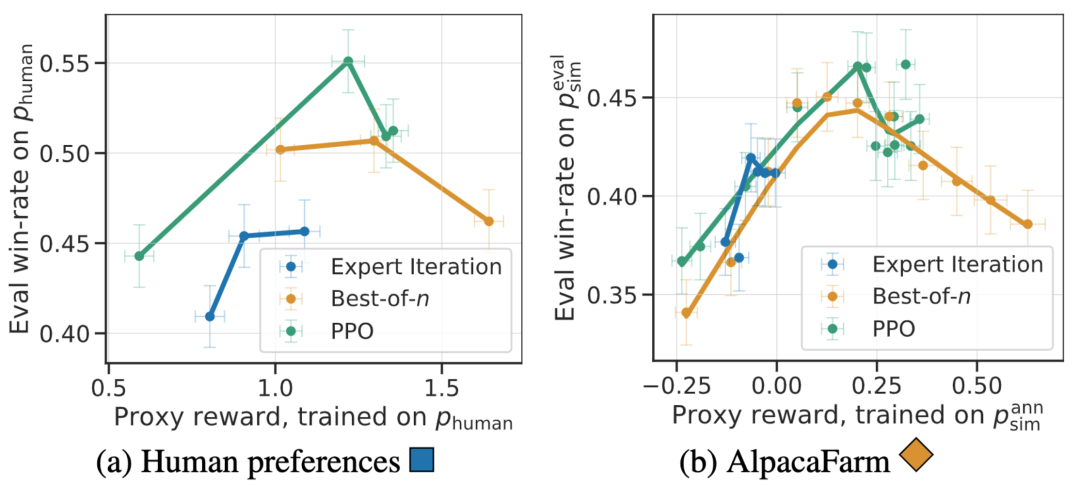
En plus de la corrélation au niveau de la méthode, le simulateur AlpacaFarm peut également reproduire des phénomènes qualitatifs tels que la sur-optimisation du modèle de récompense, mais la formation continue RLHF pour les récompenses de substitution peut nuire aux performances du modèle. La figure ci-dessous montre ce phénomène dans le cas de la rétroaction humaine (à gauche) et d'AlpacaFarm (à droite). Nous pouvons voir qu'AlpacaFarm capture initialement le comportement déterministe correct de l'amélioration des performances du modèle, puis à mesure que la formation RLHF se poursuit, les performances du modèle diminuent.
Évaluation
Pour l'évaluation, l'équipe de recherche a utilisé les interactions des utilisateurs en temps réel avec Alpaca 7B comme guidage et la distribution d'instructions simulées en combinant plusieurs ensembles de données publics existants, y compris l'ensemble de données d'auto-instruction, l'utilité anthropique. ensemble de données et ensemble d'évaluation pour Open Assistant, Koala et Vicuna. À l’aide de ces instructions d’évaluation, l’étude a comparé la réponse du modèle RLHF au modèle Davinci003 et a utilisé un score pour mesurer le nombre de fois où le modèle RLHF a mieux répondu, appelant ce score le taux de victoire. Comme le montre la figure ci-dessous, une évaluation quantitative du classement du système sur la base des données d'évaluation de l'étude montre que le classement du système et les commandes utilisateur en temps réel sont fortement corrélés. Ce résultat montre que l’agrégation de données publiques existantes peut atteindre des performances similaires à de simples instructions réelles.
Méthode de référence
Pour le troisième défi - manque de mise en œuvre de référence, l'équipe de recherche a mis en œuvre et testé plusieurs algorithmes d'apprentissage populaires (tels que PPO, itération experte, échantillonnage best-of-n) . L'équipe de recherche a constaté que les méthodes plus simples qui fonctionnaient dans d'autres domaines n'étaient pas meilleures que le modèle SFT original de l'étude, ce qui suggère qu'il est important de tester ces algorithmes dans un environnement réel de suivi des instructions.
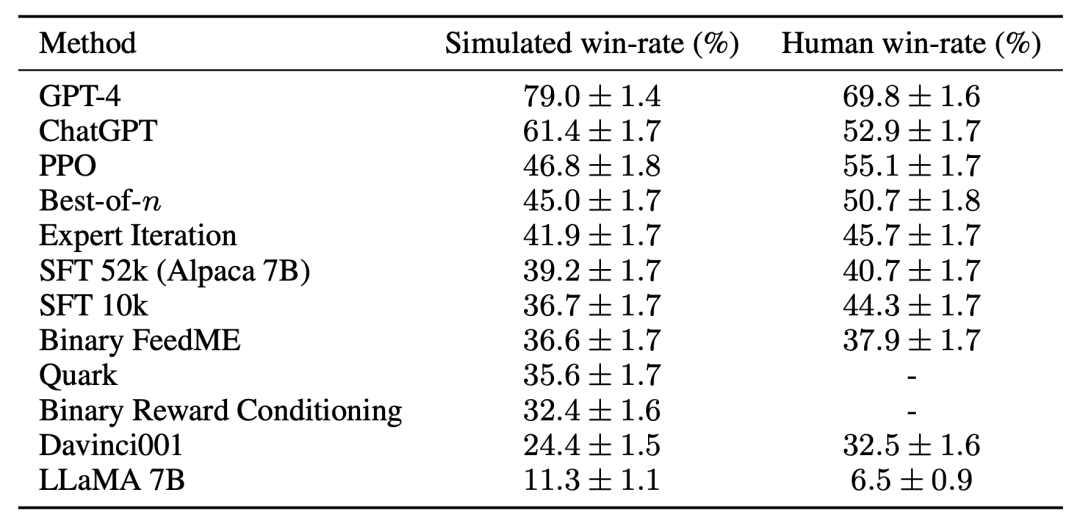
Basé sur une évaluation manuelle, l'algorithme PPO s'est avéré le plus efficace, augmentant le taux de victoire du modèle de 44 % à 55 % par rapport à Davinci003, dépassant même ChatGPT.
Ces résultats montrent que l'algorithme PPO est très efficace pour optimiser le taux de réussite du modèle. Il est important de noter que ces résultats sont spécifiques aux données d'évaluation et aux annotateurs de cette étude. Bien que les instructions d'évaluation de l'étude représentent des instructions utilisateur en temps réel, elles ne couvrent peut-être pas des problèmes plus complexes, et il n'est pas certain que l'amélioration du taux de victoire provienne de l'exploitation des préférences de style plutôt que de la réalité ou de l'exactitude. Par exemple, l'étude a révélé que le modèle PPO produisait des résultats beaucoup plus longs et fournissait souvent des explications plus détaillées pour les réponses, comme indiqué ci-dessous : les préférences simulées peuvent améliorer considérablement les résultats de l'évaluation humaine du modèle sans nécessiter que le modèle soit recyclé sur les préférences humaines. Bien que ce processus de transfert soit fragile et encore légèrement moins efficace que le recyclage du modèle sur les données de préférences humaines. Cependant, il peut copier le pipeline RLHF en 24 heures pour seulement 200 $, ce qui permet au modèle d'améliorer rapidement les performances d'évaluation humaine. Le simulateur AlpacaFarm est encore trop performant. Il est conçu par la communauté open source pour reproduire les fonctions puissantes de modèles tels que. ChatGPT. Un autre effort.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Comment effectuer une vérification de la signature numérique avec Debian OpenSSL
Apr 13, 2025 am 11:09 AM
Comment effectuer une vérification de la signature numérique avec Debian OpenSSL
Apr 13, 2025 am 11:09 AM
En utilisant OpenSSL pour la vérification de la signature numérique sur Debian System, vous pouvez suivre ces étapes: Préparation à installer OpenSSL: Assurez-vous que votre système Debian a installé OpenSSL. Si vous n'êtes pas installé, vous pouvez utiliser la commande suivante pour l'installer: SudoaptupDaSudoaptinInStallOpenssl pour obtenir la clé publique: la vérification de la signature numérique nécessite la clé publique du signataire. En règle générale, la clé publique sera fournie sous la forme d'un fichier, comme public_key.pe
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
