
 base de données
Redis
Comment SpringBoot AOP Redis implémente la fonction de double suppression retardée
base de données
Redis
Comment SpringBoot AOP Redis implémente la fonction de double suppression retardée
Comment SpringBoot AOP Redis implémente la fonction de double suppression retardée

1. Scénario métier
Dans le cas d'une concurrence multi-thread, supposons qu'il y ait deux demandes de modification de base de données Afin d'assurer la cohérence des données entre la base de données et redis,
La mise en œuvre de la demande de modification nécessite une mise en cascade. modifications après avoir modifié la base de données dans Redis.
Requête 1 : A modifie les données de la base de données B modifie les données Redis
Requête 2 : C modifie les données de la base de données D modifie les données Redis
Dans une situation concurrente, il y aura la situation A —> —> B
(Assurez-vous de comprendre que l'ordre d'exécution de plusieurs ensembles d'opérations atomiques exécutées simultanément par les threads peut se chevaucher)
1. Problèmes en ce moment
A a modifié les données de la base de données et les a finalement enregistrées dans Redis, et C a également modifié la base de données après les données A.
À l'heure actuelle, il existe une incohérence entre les données de Redis et les données de la base de données. Dans le processus de requête ultérieur, Redis sera d'abord vérifié pendant une longue période, ce qui entraînera un problème sérieux : les données interrogées ne sont pas les données réelles. dans la base de données.
2. Solution
Lorsque vous utilisez Redis, vous devez maintenir la cohérence de Redis et des données de la base de données. L'une des solutions les plus populaires est la stratégie de double suppression retardée.
Remarque : vous devez savoir que les tables de données fréquemment modifiées ne conviennent pas à l'utilisation de Redis, car le résultat de la stratégie de double suppression est de supprimer les données enregistrées dans Redis, et les requêtes ultérieures interrogeront la base de données. Par conséquent, Redis utilise un cache de données qui lit bien plus que les modifications.
Étapes d'exécution du plan de double suppression différée
Nous devons terminer l'opération de mise à jour de la base de données avant la deuxième suppression de Redis. Imaginez que s'il n'y a pas de troisième étape, il y a une forte probabilité qu'une fois les deux opérations de suppression Redis terminées, les données de la base de données n'aient pas été mises à jour. À ce moment-là, s'il y a une demande d'accès aux données, le problème est. nous l'avons mentionné au début apparaîtra. 4. Pourquoi devez-vous supprimer le cache deux fois ? Si nous n'avons pas de deuxième opération de suppression et qu'il y a une demande d'accès aux données à ce moment-là, il se peut qu'il s'agisse des données Redis qui n'ont pas été modifiées auparavant. Une fois l'opération de suppression exécutée, Redis sera vide. La demande arrive, la base de données sera consultée, à ce moment-là, les données de la base de données sont déjà des données mises à jour, garantissant la cohérence des données. 2. Pratique du code1. Introduire les dépendances Redis et SpringBoot AOP1> Supprimer le cache
2> Mettre à jour la base de données
3> Délai de 500 millisecondes (définir le délai d'exécution en fonction de l'activité spécifique)
4> 500 millisecondes ?
<!-- redis使用 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- aop -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>Copier après la connexion
2 Écrire des annotations et des aspects AOP personnalisésClearAndReloadCache a retardé la double suppression des annotations<!-- redis使用 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- aop -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>/**
*延时双删
**/
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Target(ElementType.METHOD)
public @interface ClearAndReloadCache {
String name() default "";
}Copier après la connexion
ClearAndReloadCacheAspect a retardé la double suppression des aspects/**
*延时双删
**/
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Target(ElementType.METHOD)
public @interface ClearAndReloadCache {
String name() default "";
}@Aspect
@Component
public class ClearAndReloadCacheAspect {
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 切入点
*切入点,基于注解实现的切入点 加上该注解的都是Aop切面的切入点
*
*/
@Pointcut("@annotation(com.pdh.cache.ClearAndReloadCache)")
public void pointCut(){
}
/**
* 环绕通知
* 环绕通知非常强大,可以决定目标方法是否执行,什么时候执行,执行时是否需要替换方法参数,执行完毕是否需要替换返回值。
* 环绕通知第一个参数必须是org.aspectj.lang.ProceedingJoinPoint类型
* @param proceedingJoinPoint
*/
@Around("pointCut()")
public Object aroundAdvice(ProceedingJoinPoint proceedingJoinPoint){
System.out.println("----------- 环绕通知 -----------");
System.out.println("环绕通知的目标方法名:" + proceedingJoinPoint.getSignature().getName());
Signature signature1 = proceedingJoinPoint.getSignature();
MethodSignature methodSignature = (MethodSignature)signature1;
Method targetMethod = methodSignature.getMethod();//方法对象
ClearAndReloadCache annotation = targetMethod.getAnnotation(ClearAndReloadCache.class);//反射得到自定义注解的方法对象
String name = annotation.name();//获取自定义注解的方法对象的参数即name
Set<String> keys = stringRedisTemplate.keys("*" + name + "*");//模糊定义key
stringRedisTemplate.delete(keys);//模糊删除redis的key值
//执行加入双删注解的改动数据库的业务 即controller中的方法业务
Object proceed = null;
try {
proceed = proceedingJoinPoint.proceed();
} catch (Throwable throwable) {
throwable.printStackTrace();
}
//开一个线程 延迟1秒(此处是1秒举例,可以改成自己的业务)
// 在线程中延迟删除 同时将业务代码的结果返回 这样不影响业务代码的执行
new Thread(() -> {
try {
Thread.sleep(1000);
Set<String> keys1 = stringRedisTemplate.keys("*" + name + "*");//模糊删除
stringRedisTemplate.delete(keys1);
System.out.println("-----------1秒钟后,在线程中延迟删除完毕 -----------");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
return proceed;//返回业务代码的值
}
}server:
port: 8082
spring:
# redis setting
redis:
host: localhost
port: 6379
# cache setting
cache:
redis:
time-to-live: 60000 # 60s
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test
username: root
password: 1234
# mp setting
mybatis-plus:
mapper-locations: classpath*:com/pdh/mapper/*.xml
global-config:
db-config:
table-prefix:
configuration:
# log of sql
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# hump
map-underscore-to-camel-case: trueDROP TABLE IF EXISTS `user_db`;
CREATE TABLE `user_db` (
`id` int(4) NOT NULL AUTO_INCREMENT,
`username` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of user_db
-- ----------------------------
INSERT INTO `user_db` VALUES (1, '张三');
INSERT INTO `user_db` VALUES (2, '李四');
INSERT INTO `user_db` VALUES (3, '王二');
INSERT INTO `user_db` VALUES (4, '麻子');
INSERT INTO `user_db` VALUES (5, '王三');
INSERT INTO `user_db` VALUES (6, '李三');
Copier après la connexion
5, UserControllerDROP TABLE IF EXISTS `user_db`; CREATE TABLE `user_db` ( `id` int(4) NOT NULL AUTO_INCREMENT, `username` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of user_db -- ---------------------------- INSERT INTO `user_db` VALUES (1, '张三'); INSERT INTO `user_db` VALUES (2, '李四'); INSERT INTO `user_db` VALUES (3, '王二'); INSERT INTO `user_db` VALUES (4, '麻子'); INSERT INTO `user_db` VALUES (5, '王三'); INSERT INTO `user_db` VALUES (6, '李三');
/**
* 用户控制层
*/
@RequestMapping("/user")
@RestController
public class UserController {
@Autowired
private UserService userService;
@GetMapping("/get/{id}")
@Cache(name = "get method")
//@Cacheable(cacheNames = {"get"})
public Result get(@PathVariable("id") Integer id){
return userService.get(id);
}
@PostMapping("/updateData")
@ClearAndReloadCache(name = "get method")
public Result updateData(@RequestBody User user){
return userService.update(user);
}
@PostMapping("/insert")
public Result insert(@RequestBody User user){
return userService.insert(user);
}
@DeleteMapping("/delete/{id}")
public Result delete(@PathVariable("id") Integer id){
return userService.delete(id);
}
}/**
* service层
*/
@Service
public class UserService {
@Resource
private UserMapper userMapper;
public Result get(Integer id){
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(User::getId,id);
User user = userMapper.selectOne(wrapper);
return Result.success(user);
}
public Result insert(User user){
int line = userMapper.insert(user);
if(line > 0)
return Result.success(line);
return Result.fail(888,"操作数据库失败");
}
public Result delete(Integer id) {
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(User::getId, id);
int line = userMapper.delete(wrapper);
if (line > 0)
return Result.success(line);
return Result.fail(888, "操作数据库失败");
}
public Result update(User user){
int i = userMapper.updateById(user);
if(i > 0)
return Result.success(i);
return Result.fail(888,"操作数据库失败");
}
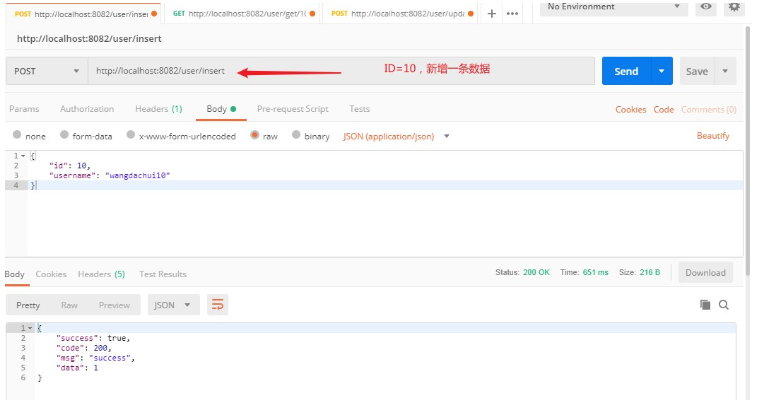
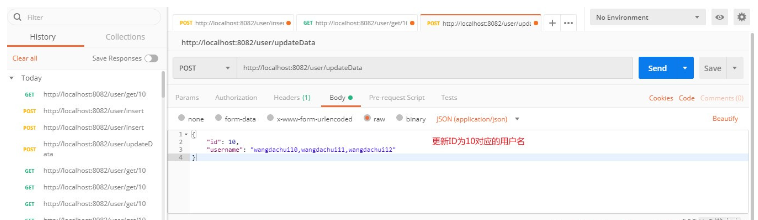
}Copier après la connexion3 Test de vérification1, ID=10, ajouter une nouvelle donnée.
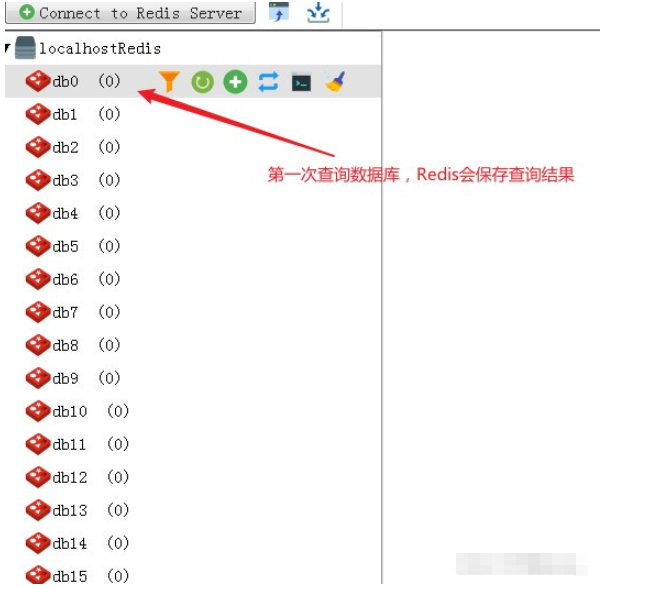
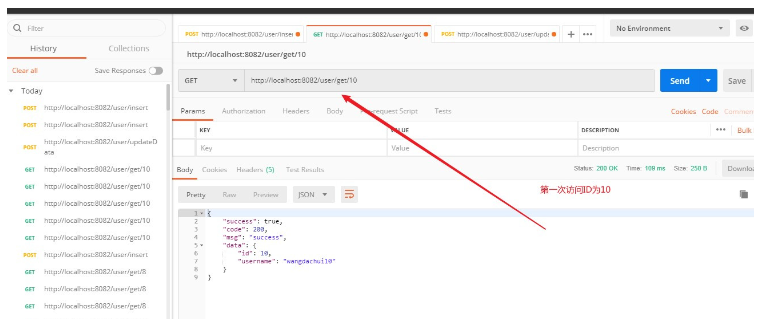
2 Stocker dans Redis/**
* service层
*/
@Service
public class UserService {
@Resource
private UserMapper userMapper;
public Result get(Integer id){
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(User::getId,id);
User user = userMapper.selectOne(wrapper);
return Result.success(user);
}
public Result insert(User user){
int line = userMapper.insert(user);
if(line > 0)
return Result.success(line);
return Result.fail(888,"操作数据库失败");
}
public Result delete(Integer id) {
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(User::getId, id);
int line = userMapper.delete(wrapper);
if (line > 0)
return Result.success(line);
return Result.fail(888, "操作数据库失败");
}
public Result update(User user){
int i = userMapper.updateById(user);
if(i > 0)
return Result.success(i);
return Result.fail(888,"操作数据库失败");
}
}
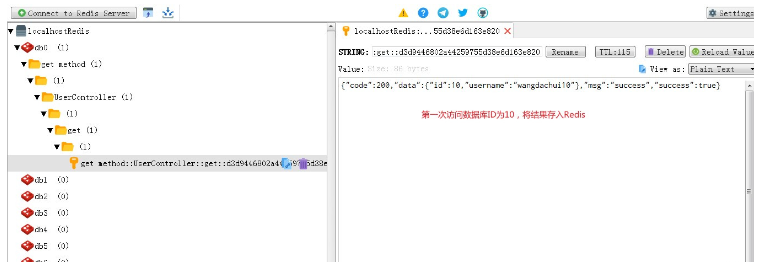
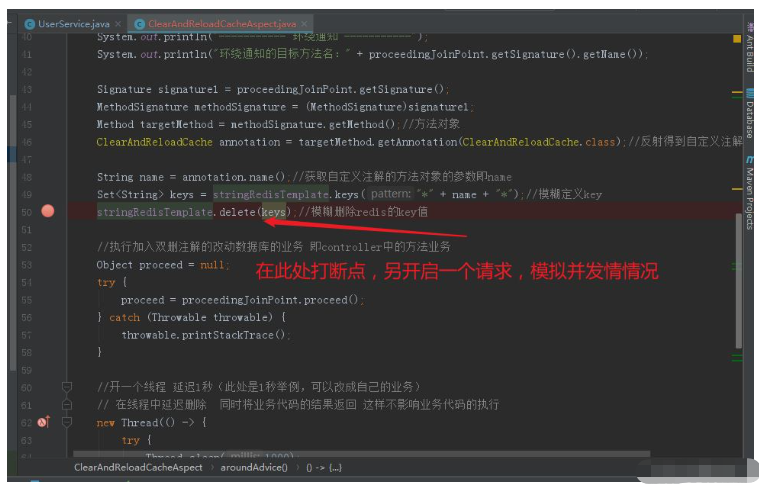
 Créer un point d'arrêt, simuler Un thread pour exécuter le premier Après une suppression, avant que A ne termine la mise à jour de la base de données, un autre thread B accède à ID=10 et lit les anciennes données.
Créer un point d'arrêt, simuler Un thread pour exécuter le premier Après une suppression, avant que A ne termine la mise à jour de la base de données, un autre thread B accède à ID=10 et lit les anciennes données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Pour afficher toutes les touches dans Redis, il existe trois façons: utilisez la commande Keys pour retourner toutes les clés qui correspondent au modèle spécifié; Utilisez la commande SCAN pour itérer les touches et renvoyez un ensemble de clés; Utilisez la commande info pour obtenir le nombre total de clés.
 Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Comment démarrer le serveur avec redis
Apr 10, 2025 pm 08:12 PM
Les étapes pour démarrer un serveur Redis incluent: Installez Redis en fonction du système d'exploitation. Démarrez le service Redis via Redis-Server (Linux / MacOS) ou Redis-Server.exe (Windows). Utilisez la commande redis-Cli Ping (Linux / MacOS) ou redis-Cli.exe Ping (Windows) pour vérifier l'état du service. Utilisez un client redis, tel que redis-cli, python ou node.js pour accéder au serveur.
