

Analyse du plan d'indexation simple MySQL

Index simple Mysql
1. Comment rechercher quand il n'y a pas d'index
Ignorez la notion d'index pour l'instant Si vous souhaitez rechercher directement un enregistrement maintenant, comment le rechercher ?
Rechercher dans une page
S'il y a très peu d'enregistrements dans le tableau et qu'une page suffit, alors il y a deux situations :
Utiliser la clé primaire comme condition de recherche : C'est la méthode mentionnée dans la précédente article , utilisez la méthode de dichotomie pour localiser rapidement l'emplacement dans le répertoire des pages, puis parcourez les enregistrements correspondant au groupe de l'emplacement, et enfin trouvez l'enregistrement spécifié.
Utilisez d'autres colonnes de clé non primaire comme conditions de recherche : étant donné qu'il n'y a pas de répertoire de pages pour les colonnes de clé non primaire dans la page de données, il est impossible de localiser rapidement l'emplacement via la méthode de dichotomie. enregistrement de la liste à chaînage unique à partir de l'enregistrement Infimum Inefficace.
Rechercher dans plusieurs pages
Lorsqu'il y a beaucoup d'enregistrements dans le tableau, de nombreuses pages de données seront utilisées pour les stocker. Dans ce cas, 2 étapes sont nécessaires :
Localiser la page où. le dossier est localisé.
Répétez le processus de recherche ci-dessus dans une page.
En général, lorsqu'il n'y a pas d'index, nous ne pouvons pas localiser rapidement la page où se trouve l'enregistrement. Nous ne pouvons rechercher qu'à partir de la première page le long de la liste doublement chaînée (la page contient la page précédente et la page suivante). , puis recherchez sur chaque page. Répétez le processus ci-dessus dans la page pour interroger les enregistrements spécifiés, ce qui nécessite de parcourir tous les enregistrements, ce qui prend beaucoup de temps.
2. Un index simple
Étant donné que l'enregistrement de positionnement est trop lent à cause d'un trop grand nombre de pages, comment le résoudre ? Vous souhaiterez peut-être vous référer au « Répertoire des pages ».
Le répertoire de pages est configuré pour localiser rapidement la position d'un enregistrement dans la page en fonction de la clé primaire. Par conséquent, nous pouvons explorer une méthode de création d’un « autre répertoire » pour localiser rapidement la page où se trouve l’enregistrement.
Mais il y a deux choses à faire avant que cet « autre répertoire » puisse être complété.
1. La valeur de la clé primaire de l'enregistrement utilisateur sur la page suivante doit être supérieure à celle de la page précédente
En supposant que chaque page de données peut contenir jusqu'à 3 enregistrements (en fait, elle peut en mettre plusieurs), alors insérez maintenant 3 enregistrements dans le tableau, chaque enregistrement a 3 colonnes c1, c2, c3. Pour plus de commodité, le format des lignes de stockage est également simplifié, ne laissant que les attributs clés. Les enregistrements virtuels Infimum et Supremum sont situés respectivement au début et à la fin de l'enregistrement utilisateur, avec trois enregistrements utilisateur au milieu.
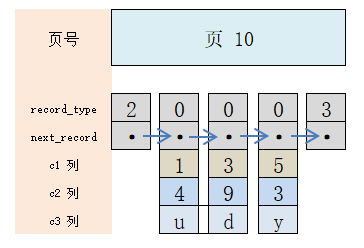
À ce moment, continuez à insérer 1 enregistrement. Dans le cas hypothétique, au moins une nouvelle page doit être allouée, les deux pages seront donc réaffectées et réorganisées.
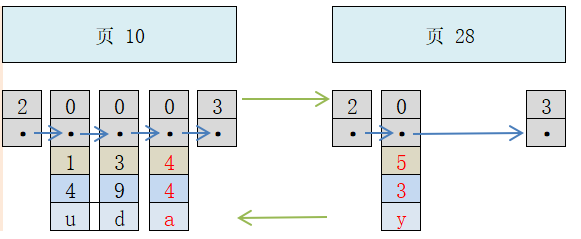
Veuillez noter que les deux enregistrements affichés en rouge incluent un enregistrement nouvellement inséré avec une clé primaire de 4, qui doit être placé sur une nouvelle page. Cependant, afin de satisfaire à l'exigence selon laquelle la valeur de clé primaire de l'enregistrement utilisateur sur la page suivante doit être supérieure à la valeur de clé primaire de l'enregistrement utilisateur sur la page précédente, des opérations telles que le déplacement d'enregistrement sont également effectuées. être appelé « fractionnement de page ».
Aussi, pourquoi la nouvelle page est-elle la page 28, et non la 11 ? Étant donné que les pages ne peuvent pas être côte à côte sur le disque, elles établissent simplement une relation de liste chaînée en conservant les numéros de la page précédente et de la page suivante.
2. Créez une entrée de répertoire pour toutes les pages
Maintenant, continuez à ajouter des données au tableau. La relation finale entre plusieurs pages est la suivante :
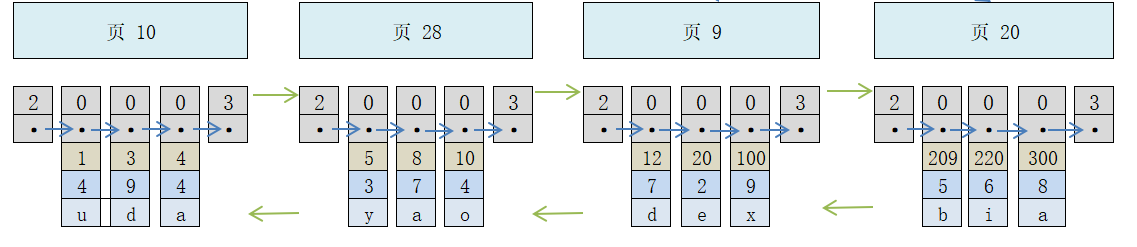
Afin de localiser rapidement un enregistrement à partir de plusieurs pages non adjacentes. , vous devez les cataloguer car les pages peuvent ne pas être contiguës sur le disque.
Chaque page correspond à une entrée d'annuaire, et chaque entrée d'annuaire comprend :
La plus petite valeur de clé primaire dans l'enregistrement utilisateur de la page, représentée par key
Le numéro de page, représenté par page_no
Donc, après les avoir catalogués, la relation est la suivante :
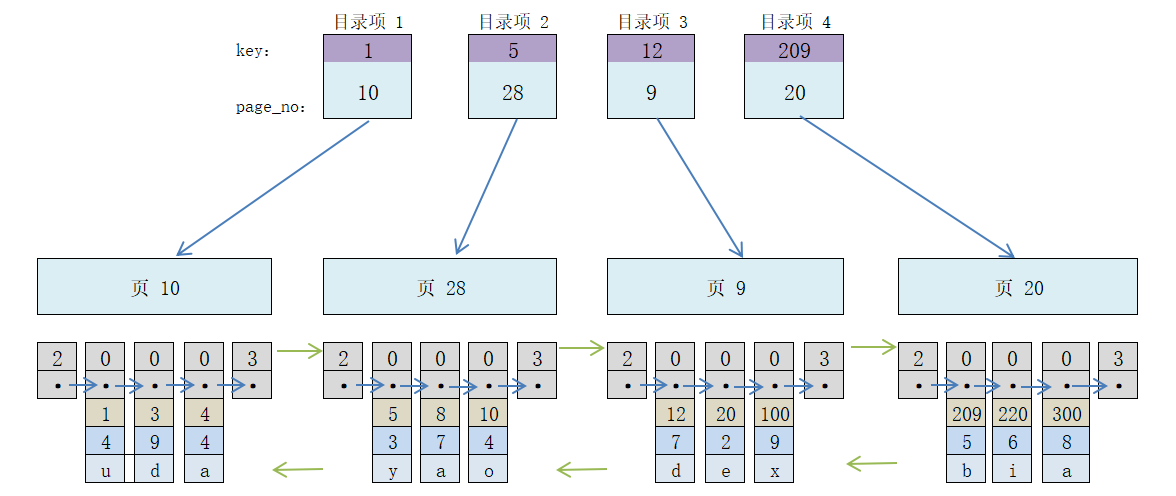
Donc, maintenant je veux trouver l'enregistrement avec une valeur de clé primaire de 20. Plus précisément, je vais le faire en deux étapes :
Utiliser la dichotomie méthode pour déterminer rapidement la clé primaire à partir des entrées du répertoire. L'enregistrement avec la valeur de clé 20 se trouve dans l'entrée de répertoire 3 et le numéro de page sur lequel il se trouve est 9. Sachant qu'il se trouve à la page 9, répétez l'approche précédente pour trouver l'enregistrement cible final.
À ce stade, une solution simple est complétée. Le répertoire simple complété a un alias appelé index.
3. Problèmes exposés par l'index simple
L'index simple mentionné ci-dessus est le contenu mis en place par l'auteur du livre original pour aider les lecteurs à comprendre étape par étape.
Jetons donc un coup d’œil à l’index suggéré ci-dessus et voyons quels problèmes il y a.
Question 1 :
InnoDB utilise les pages comme unité de base pour gérer l'espace de stockage, ce qui signifie qu'il ne peut économiser que jusqu'à 16 Ko de stockage continu.
Lorsqu'il y a de plus en plus d'enregistrements dans la table, un très grand espace de stockage continu est nécessaire pour contenir toutes les entrées du répertoire, ce qui est irréaliste pour les tables contenant de grandes quantités de données.
Question 2 :
Nous devons souvent ajouter, supprimer et modifier des enregistrements, ce qui peut affecter tout le corps.
Par exemple, si je supprime tous les enregistrements de la page 28 dans l'image ci-dessus, alors la page 28 n'a pas besoin d'exister et l'entrée de répertoire 2 n'a pas besoin d'exister. À ce stade, vous devez déplacer les éléments du répertoire après l’élément de répertoire 2 vers l’avant.
Même si elle n'est pas déplacée, placer l'entrée de répertoire 2 comme redondante dans la liste des entrées de répertoire gaspillera quand même beaucoup d'espace de stockage.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Compétences de traitement de structures de données volumineuses de PHP
May 08, 2024 am 10:24 AM
Compétences de traitement de structures de données volumineuses de PHP
May 08, 2024 am 10:24 AM
Compétences en matière de traitement de la structure des Big Data : Chunking : décomposez l'ensemble de données et traitez-le en morceaux pour réduire la consommation de mémoire. Générateur : générez des éléments de données un par un sans charger l'intégralité de l'ensemble de données, adapté à des ensembles de données illimités. Streaming : lisez des fichiers ou interrogez les résultats ligne par ligne, adapté aux fichiers volumineux ou aux données distantes. Stockage externe : pour les ensembles de données très volumineux, stockez les données dans une base de données ou NoSQL.
 Comment utiliser la sauvegarde et la restauration MySQL en PHP ?
Jun 03, 2024 pm 12:19 PM
Comment utiliser la sauvegarde et la restauration MySQL en PHP ?
Jun 03, 2024 pm 12:19 PM
La sauvegarde et la restauration d'une base de données MySQL en PHP peuvent être réalisées en suivant ces étapes : Sauvegarder la base de données : Utilisez la commande mysqldump pour vider la base de données dans un fichier SQL. Restaurer la base de données : utilisez la commande mysql pour restaurer la base de données à partir de fichiers SQL.
 Comment optimiser les performances des requêtes MySQL en PHP ?
Jun 03, 2024 pm 08:11 PM
Comment optimiser les performances des requêtes MySQL en PHP ?
Jun 03, 2024 pm 08:11 PM
Les performances des requêtes MySQL peuvent être optimisées en créant des index qui réduisent le temps de recherche d'une complexité linéaire à une complexité logarithmique. Utilisez PreparedStatements pour empêcher l’injection SQL et améliorer les performances des requêtes. Limitez les résultats des requêtes et réduisez la quantité de données traitées par le serveur. Optimisez les requêtes de jointure, notamment en utilisant des types de jointure appropriés, en créant des index et en envisageant l'utilisation de sous-requêtes. Analyser les requêtes pour identifier les goulots d'étranglement ; utiliser la mise en cache pour réduire la charge de la base de données ; optimiser le code PHP afin de minimiser les frais généraux.
 Comment insérer des données dans une table MySQL en utilisant PHP ?
Jun 02, 2024 pm 02:26 PM
Comment insérer des données dans une table MySQL en utilisant PHP ?
Jun 02, 2024 pm 02:26 PM
Comment insérer des données dans une table MySQL ? Connectez-vous à la base de données : utilisez mysqli pour établir une connexion à la base de données. Préparez la requête SQL : Écrivez une instruction INSERT pour spécifier les colonnes et les valeurs à insérer. Exécuter la requête : utilisez la méthode query() pour exécuter la requête d'insertion en cas de succès, un message de confirmation sera généré.
 Comment créer une table MySQL en utilisant PHP ?
Jun 04, 2024 pm 01:57 PM
Comment créer une table MySQL en utilisant PHP ?
Jun 04, 2024 pm 01:57 PM
La création d'une table MySQL à l'aide de PHP nécessite les étapes suivantes : Connectez-vous à la base de données. Créez la base de données si elle n'existe pas. Sélectionnez une base de données. Créer un tableau. Exécutez la requête. Fermez la connexion.
 Comment utiliser les procédures stockées MySQL en PHP ?
Jun 02, 2024 pm 02:13 PM
Comment utiliser les procédures stockées MySQL en PHP ?
Jun 02, 2024 pm 02:13 PM
Pour utiliser les procédures stockées MySQL en PHP : Utilisez PDO ou l'extension MySQLi pour vous connecter à une base de données MySQL. Préparez l'instruction pour appeler la procédure stockée. Exécutez la procédure stockée. Traitez le jeu de résultats (si la procédure stockée renvoie des résultats). Fermez la connexion à la base de données.
 Comment corriger les erreurs mysql_native_password non chargé sur MySQL 8.4
Dec 09, 2024 am 11:42 AM
Comment corriger les erreurs mysql_native_password non chargé sur MySQL 8.4
Dec 09, 2024 am 11:42 AM
L'un des changements majeurs introduits dans MySQL 8.4 (la dernière version LTS en 2024) est que le plugin « MySQL Native Password » n'est plus activé par défaut. De plus, MySQL 9.0 supprime complètement ce plugin. Ce changement affecte PHP et d'autres applications
 La différence entre la base de données Oracle et MySQL
May 10, 2024 am 01:54 AM
La différence entre la base de données Oracle et MySQL
May 10, 2024 am 01:54 AM
La base de données Oracle et MySQL sont toutes deux des bases de données basées sur le modèle relationnel, mais Oracle est supérieur en termes de compatibilité, d'évolutivité, de types de données et de sécurité ; tandis que MySQL se concentre sur la vitesse et la flexibilité et est plus adapté aux ensembles de données de petite et moyenne taille. ① Oracle propose une large gamme de types de données, ② fournit des fonctionnalités de sécurité avancées, ③ convient aux applications de niveau entreprise ; ① MySQL prend en charge les types de données NoSQL, ② a moins de mesures de sécurité et ③ convient aux applications de petite et moyenne taille.
