

De manière générale, le moteur de stockage de la base de données utilise B-tree ou B+-tree pour stocker l'index. Regardez d’abord l’arbre B, comme indiqué sur la figure.
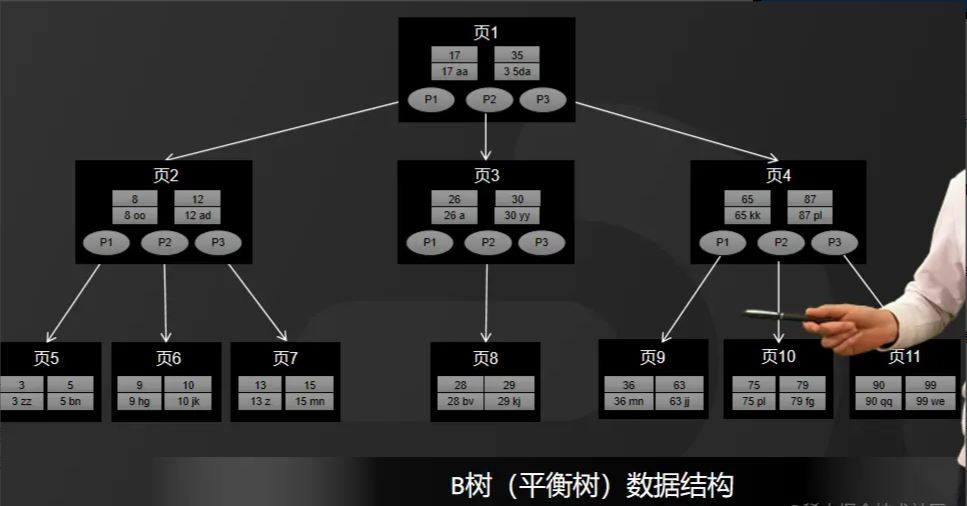
L'arbre B est un arbre équilibré à plusieurs voies. Cette structure de stockage est utilisée pour stocker une grande quantité de données. Sa hauteur totale sera plus élevée. celui d'un arbre binaire, sera beaucoup plus court.
Pour la base de données, toutes les données seront enregistrées sur le disque et l'efficacité des E/S disque est relativement faible, en particulier dans le cas d'E/S disque aléatoires.
Ainsi, la hauteur détermine le nombre d'E/S disque. Moins le nombre d'E/S disque est important, plus l'amélioration des performances est importante. C'est pourquoi B-tree est utilisé comme structure de stockage d'index. comme le montre la figure présentée.
Le moteur de stockage InnoDB de MySQL utilise une structure B-tree améliorée, à savoir l'arbre B+, comme structure d'index et de stockage de données.
Par rapport à la structure B-tree, l'arbre B+ a été optimisé sous deux aspects, comme le montre la figure.
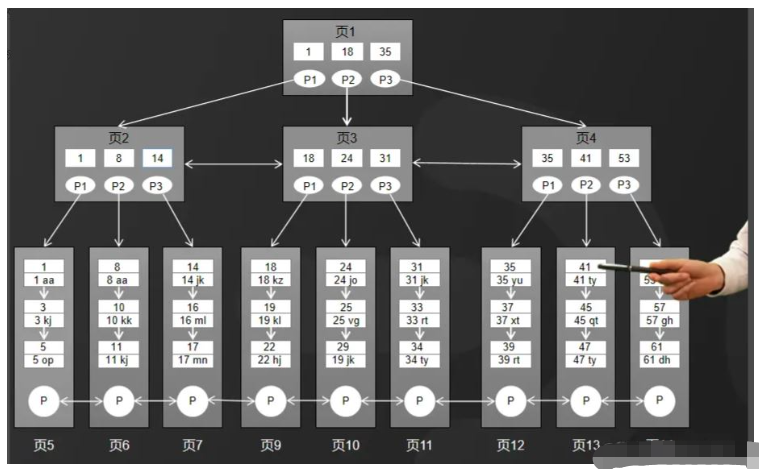
1. Toutes les données de l'arborescence B+ sont stockées dans des nœuds feuilles, et les nœuds non-feuilles ne stockent que des index.
2. Les données dans les nœuds feuilles sont liées à l'aide d'une liste doublement chaînée.
Je pense que la structure d'index MySQL utilise l'arbre B+ pour les 4 raisons suivantes :
 #🎜 🎜#
#🎜 🎜#
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



