
 Périphériques technologiques
IA
Meta utilise la Bible pour former un modèle super multilingue : reconnaître 1107 langues et identifier 4017 langues
Périphériques technologiques
IA
Meta utilise la Bible pour former un modèle super multilingue : reconnaître 1107 langues et identifier 4017 langues
Meta utilise la Bible pour former un modèle super multilingue : reconnaître 1107 langues et identifier 4017 langues

Il y a une histoire sur la Tour de Babel dans la Bible. On dit que les êtres humains se sont unis pour planifier la construction d'une haute tour, dans l'espoir de conduire au ciel, mais Dieu a confondu le langage humain et le langage humain. le plan était donc un échec. Aujourd’hui, la technologie de l’IA devrait faire tomber les barrières entre les langues humaines et aider l’humanité à créer une tour de Babel civilisée.
Récemment, une étude de Meta a fait un pas important vers cet aspect. Ils appellent la méthode nouvellement proposée Discours massivement multilingue (Super Multilingual Speech/MMS ), qui utilise la Bible dans le cadre des données d'entraînement et a obtenu les résultats suivants :
- formé avec wave2vec 2.0 sur 1107 langues et obtenu un Le multi-langue Le modèle de reconnaissance vocale avec 1 milliard de paramètres a un taux d'erreur réduit de plus de 50 % par rapport au modèle Whisper d'OpenAI.
- Un seul modèle de synthèse audio prend en charge la synthèse vocale (TTS) pour ces 1107 langues.
- a développé un classificateur de reconnaissance de langues capable d'identifier 4017 langues.
Comment Meta résout-il le problème de la rareté des données dans de nombreuses langues rares ? La méthode qu'ils ont utilisée est intéressante, utilisant des corpus religieux, car les corpus comme la Bible ont les données vocales les plus « alignées ». Bien que cet ensemble de données soit orienté vers le contenu religieux et présente principalement des voix masculines, l'article montre que le modèle fonctionne également bien dans d'autres domaines lorsqu'il utilise des voix féminines. C'est le comportement émergent du modèle de base, et c'est vraiment étonnant. Ce qui est encore plus étonnant, c'est que Meta a publié gratuitement tous les modèles nouvellement développés (reconnaissance vocale, TTS et reconnaissance linguistique) !
- Téléchargement du modèle : https://github.com/facebookresearch/fairseq/tree/main/examples/mms
- Adresse papier : https://research.facebook.com/publications/scaling-speech-technology-to-1000-linguals/#🎜🎜 #
Afin de créer un modèle de parole capable de reconnaître des milliers de mots, le premier défi est Collectez des données audio dans différentes langues, car le plus grand ensemble de données vocales existant ne compte que 100 langues au maximum. Pour surmonter ce problème, les chercheurs Meta ont utilisé des textes religieux, tels que la Bible, qui ont été traduits dans de nombreuses langues différentes, et ces traductions ont été largement étudiées. Ces traductions contiennent des enregistrements audio de personnes qui les lisent dans différentes langues, et ces audios sont également accessibles au public. À l’aide de ces audios, les chercheurs ont créé un ensemble de données contenant des enregistrements audio de personnes lisant le Nouveau Testament dans 1 100 langues, avec une durée audio moyenne de 32 heures par langue.
Ils ont ensuite inclus des enregistrements non annotés de nombreuses autres lectures chrétiennes, augmentant ainsi le nombre de langues disponibles à plus de 4 000. Bien que le champ de cet ensemble de données soit unique et se compose principalement de voix masculines, les résultats de l’analyse montrent que le modèle nouvellement développé par Meta fonctionne tout aussi bien sur les voix féminines et que le modèle n’est pas particulièrement orienté vers la production d’un langage plus religieux. Les chercheurs ont déclaré dans le blog que cela est principalement dû à la méthode de classification temporelle connexionniste qu'ils ont utilisée, qui est de loin supérieure aux grands modèles de langage (LLM) ou aux modèles de reconnaissance vocale séquence à séquence plus restreints.
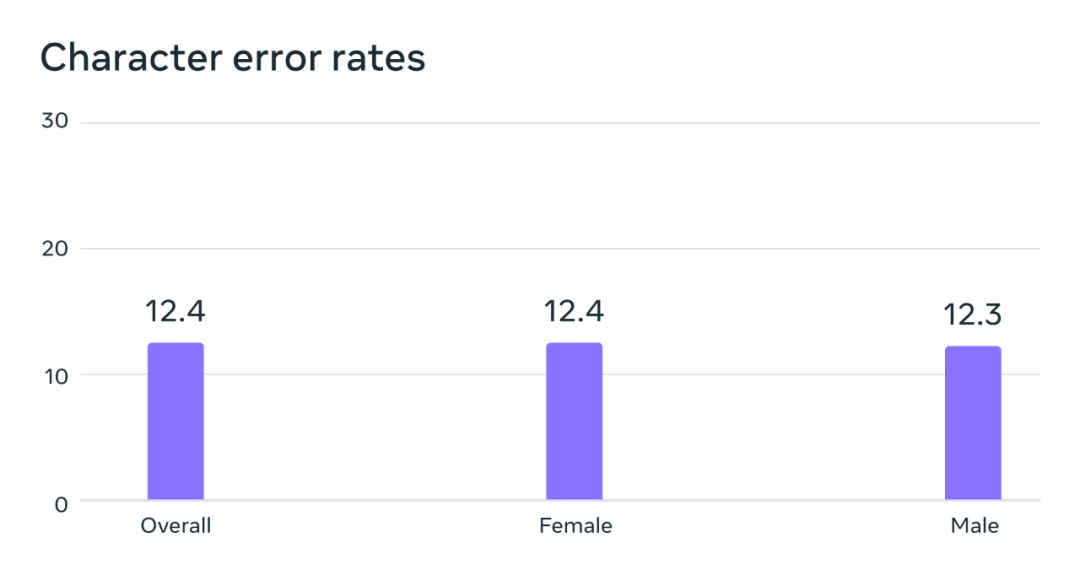
Analyse des situations potentielles de préjugés sexistes. Sur le benchmark FLEURS, ce modèle de reconnaissance vocale automatique formé sur l'ensemble de données Multilingual Speech (MMS) présente des taux d'erreur similaires pour les voix masculines et féminines.
Afin d'améliorer la qualité des données afin qu'elles puissent être utilisées par des algorithmes d'apprentissage automatique, ils ont également adopté certaines méthodes de prétraitement. Tout d’abord, ils ont formé un modèle d’alignement sur des données existantes provenant de plus de 100 langues, puis l’ont associé à un algorithme d’alignement forcé efficace capable de gérer de très longs enregistrements de plus de 20 minutes. Ensuite, après plusieurs cycles de processus d'alignement, une dernière étape de filtrage de validation croisée est effectuée pour supprimer les données potentiellement mal alignées en fonction de la précision du modèle. Afin de permettre à d'autres chercheurs de créer de nouveaux ensembles de données vocales, Meta a ajouté l'algorithme d'alignement à PyTorch et a publié le modèle d'alignement.
Pour former un modèle de reconnaissance vocale supervisée universellement utilisable, 32 heures de données par langue ne suffisent pas. Par conséquent, leur modèle est développé sur la base de wav2vec 2.0, qui correspond à leurs recherches antérieures sur l'apprentissage auto-supervisé de la représentation vocale, ce qui peut réduire considérablement la quantité de données étiquetées requises pour la formation. Plus précisément, les chercheurs ont formé un modèle auto-supervisé en utilisant environ 500 000 heures de données vocales dans plus de 1 400 langues, soit plus de cinq fois plus de langues que n'importe quelle étude précédente. Ensuite, sur la base de tâches vocales spécifiques (telles que la reconnaissance vocale multilingue ou la reconnaissance linguistique), les chercheurs affinent le modèle résultant.
Résultats
Les chercheurs ont évalué le modèle nouvellement développé sur certains critères existants.
La formation de son modèle de reconnaissance vocale multilingue utilise le modèle wav2vec 2.0 avec 1 milliard de paramètres, et l'ensemble de données de formation contient plus de 1 100 langues. Les performances du modèle diminuent effectivement à mesure que le nombre de langues augmente, mais la diminution est très faible : lorsque le nombre de langues passe de 61 à 1 107, le taux d'erreur de caractère n'augmente que de 0,4 %, mais la couverture linguistique augmente de plus. plus de 18 fois.
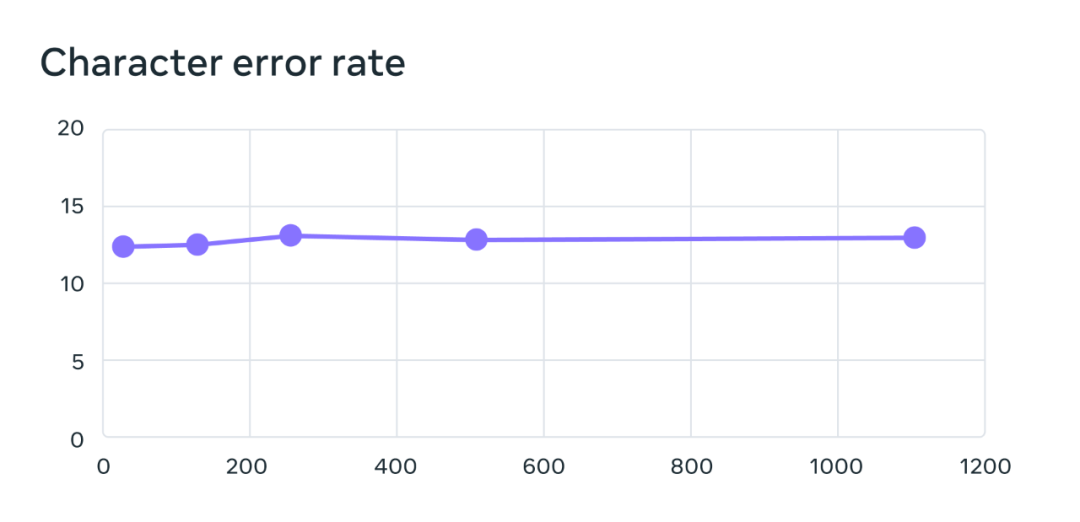
Sur le test de référence de 61 langues FLEURS, le taux d'erreur sur les caractères évolue à mesure que le nombre de langues augmente. Plus le taux d'erreur est élevé, plus le modèle est mauvais.
En comparant le modèle Whisper d'OpenAI, les chercheurs ont découvert que le taux d'erreur de mot de leur modèle n'était que la moitié de celui de Whisper, tandis que le nouveau modèle prenait en charge 11 fois plus de langues. Ce résultat démontre les capacités supérieures de la nouvelle méthode.
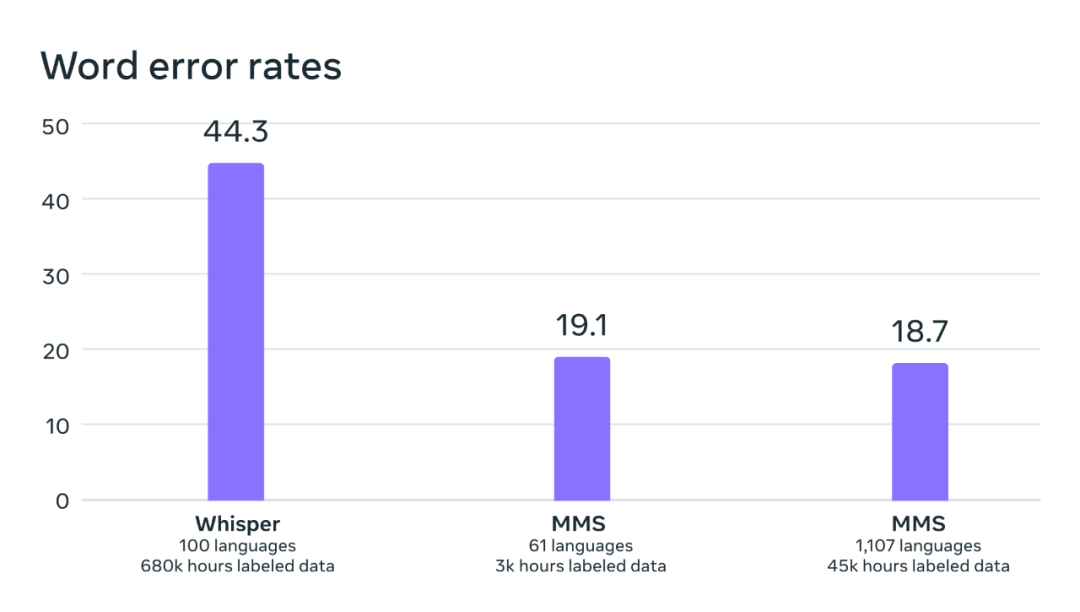
Comparaison des taux d'erreur de mots entre OpenAI Whisper et MMS sur un benchmark directement comparable de 54 langages FLEURS.
Ensuite, en utilisant des ensembles de données existants (tels que FLEURS et CommonVoice) et de nouveaux ensembles de données, les méta-chercheurs ont également formé un modèle d'identification de langue (LID) et l'ont évalué sur la tâche FLEURS LID. Les résultats montrent que non seulement le nouveau modèle est très performant, mais qu’il prend également en charge 40 fois plus de langues.
Des recherches précédentes ne prenaient également en charge que plus de 100 langues sur le benchmark VoxLingua-107, tandis que MMS prend en charge plus de 4 000 langues.
De plus, Meta a également construit un système de synthèse vocale prenant en charge 1 100 langues. Les données d'entraînement pour les modèles actuels de synthèse vocale sont généralement le corpus vocal d'un seul locuteur. Une limitation des données MMS est que de nombreuses langues n’ont qu’un petit nombre de locuteurs, souvent même un seul locuteur. Cependant, cela est devenu un avantage lors de la création d'un système de synthèse vocale, Meta a donc construit un système TTS prenant en charge plus de 1 100 langues. Les chercheurs affirment que la qualité de la parole générée par ces systèmes est en réalité assez bonne, et plusieurs exemples sont donnés ci-dessous.
Démo du modèle de synthèse vocale MMS pour les langues yoruba, iroko et maithili.
Cependant, les chercheurs affirment que la technologie de l’IA n’est toujours pas parfaite, et il en va de même pour le MMS. Par exemple, MMS peut mal transcrire des mots ou des phrases sélectionnés lors de la synthèse vocale. Cela peut entraîner un langage offensant et/ou inexact dans le résultat. Les chercheurs ont souligné l’importance de travailler avec la communauté de l’IA pour se développer de manière responsable.
Prendre en charge la valeur de mille mots avec un seul modèle
De nombreuses langues dans le monde sont sur le point de disparaître, et les limites de la technologie actuelle de reconnaissance vocale et de génération vocale ne feront qu'accélérer encore cette tendance. Le chercheur a imaginé dans son blog : Peut-être que la technologie peut encourager les gens à conserver leur propre langue, car avec une bonne technologie, ils peuvent utiliser leur langue préférée pour obtenir des informations et utiliser la technologie.
Ils estiment que le projet MMS est une étape importante dans cette direction. Ils ont également déclaré que le projet continuerait à se développer et prendrait en charge davantage de langues à l'avenir, et résoudrait même les problèmes de dialectes et d'accents.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Le FP8 et la précision de quantification inférieure en virgule flottante ne sont plus le « brevet » du H100 ! Lao Huang voulait que tout le monde utilise INT8/INT4, et l'équipe Microsoft DeepSpeed a commencé à exécuter FP6 sur A100 sans le soutien officiel de NVIDIA. Les résultats des tests montrent que la quantification FP6 de la nouvelle méthode TC-FPx sur A100 est proche ou parfois plus rapide que celle de INT4, et a une précision supérieure à celle de cette dernière. En plus de cela, il existe également une prise en charge de bout en bout des grands modèles, qui ont été open source et intégrés dans des cadres d'inférence d'apprentissage profond tels que DeepSpeed. Ce résultat a également un effet immédiat sur l'accélération des grands modèles : dans ce cadre, en utilisant une seule carte pour exécuter Llama, le débit est 2,65 fois supérieur à celui des cartes doubles. un
