

Exemple d'analyse du problème de mise en cache Redis

1. Application du cache Redis
Dans nos scénarios commerciaux réels, Redis est généralement utilisé en conjonction avec d'autres bases de données pour réduire la pression sur la base de données back-end, par exemple en l'utilisant avec la base de données relationnelle MySQL.
Redis mettra en cache les données fréquemment interrogées dans MySQL, telles que les données de hotspot, de cette façon, lorsque les utilisateurs accèdent, ils n'ont pas besoin d'interroger dans MySQL, mais obtiennent ainsi directement les données mises en cache dans Redis. réduisant la pression de lecture sur la base de données back-end.
Si les données interrogées par l'utilisateur ne sont pas disponibles dans Redis, alors la demande de requête de l'utilisateur sera transférée vers la base de données MySQL. Lorsque MySQL renvoie les données au client, il mettra également en cache les données dans Redis afin que le l'utilisateur peut le relire, vous pouvez obtenir des données directement depuis Redis. L'organigramme est le suivant :
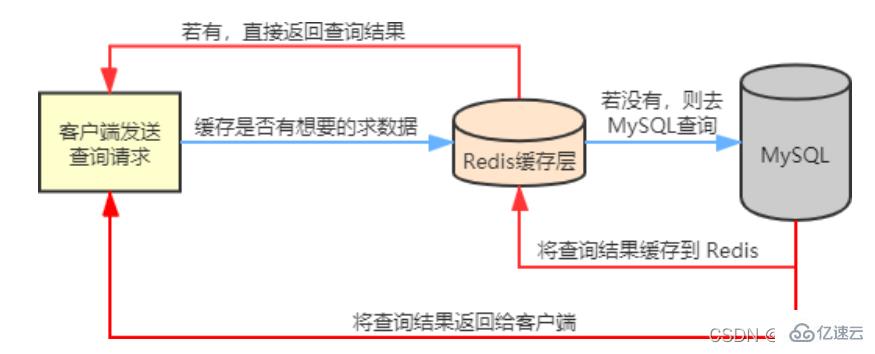
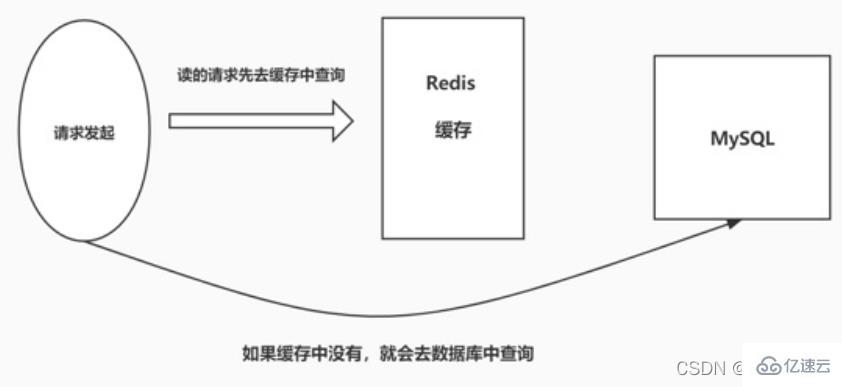
Solution 2.2Lors de l'utilisation de Redis comme base de données de cache, nous serons inévitablement confrontés à trois problèmes de cache courants
Pénétration du cache
Panne du cache
- Avalanche de cache cache, la demande de requête sera transférée à la base de données de la couche de persistance MySQL. Il s'avère que les données n'existent pas dans MySQL et ne peuvent renvoyer qu'un objet vide, ce qui signifie que la requête a échoué. S'il y a beaucoup de requêtes de ce type, ou si les utilisateurs utilisent de telles requêtes pour mener des attaques malveillantes, cela exercera une forte pression sur la base de données MySQL et même s'effondrera. Ce phénomène est appelé pénétration du cache.
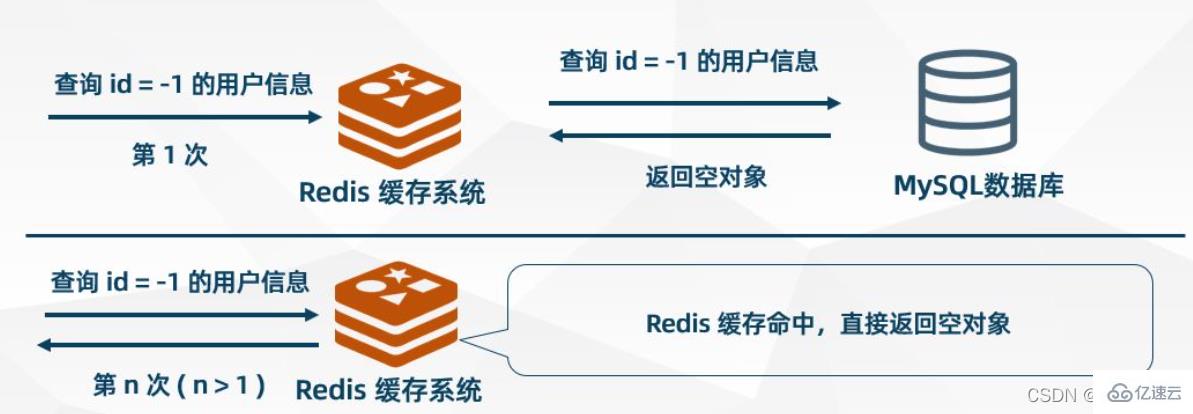
Cache les objets vides
sera obtenu du cache. La demande de l'utilisateur est bloquée dans la couche de cache, protégeant ainsi la base de données principale. Cependant, cette approche présente également quelques problèmes. La requête ne peut pas entrer dans MSQL, mais cette stratégie occupera l'espace du cache Redis.Lorsque MySQL renvoie un objet vide, Redis met l'objet en cache et définit un délai d'expiration pour celui-ci. Lorsque l'utilisateur lance à nouveau la même demande, un
objet vide
Filtre Bloom
Stockez d'abord toutes les clés des données de hotspot auxquelles l'utilisateur peut accéder dans le filtre Bloom (également appelé préchauffage du cache), lorsqu'il y a une demande de l'utilisateur. Passez d'abord par le filtre Bloom . Le filtre Bloom déterminera si la clé demandée existe. Si elle n'existe pas, la requête sera directement rejetée. Sinon, la requête continuera. S'il n'y a pas de cache, allez-y à nouveau. Requête dans la base de données. Par rapport à la première méthode, l’utilisation de la méthode du filtre Bloom est plus efficace et plus pratique. Le schéma de processus est le suivant :
2.3 Comparaison des solutions
Les deux solutions peuvent résoudre le problème de pénétration du cache, mais leurs scénarios d'utilisation sont différents :
Cache les objets vides : Le nombre de clés adaptées aux données vides est limité, Scénarios où la probabilité de demandes de clés répétées est élevée.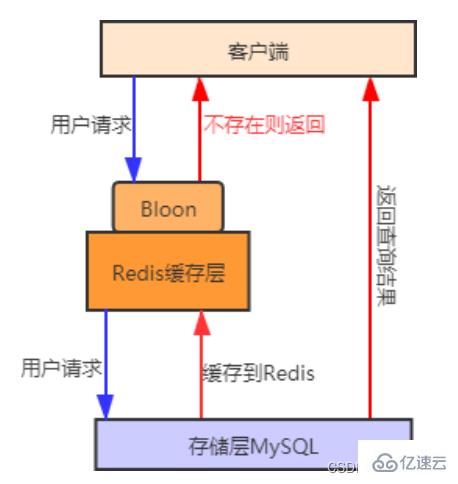
3. Panne du cache 3.1 IntroductionFiltre Bloom : adapté aux scénarios dans lesquels les clés des données vides sont différentes et la probabilité de demandes de clés répétées est faible.
La panne du cache signifie que les données interrogées par l'utilisateur n'existent pas dans le cache, mais existent dans la base de données principale. La raison de ce phénomène est généralement. causé par la clé dans le cache provoqué par l'expiration. Par exemple, une clé de données rapide reçoit tout le temps un grand nombre d'accès simultanés. Si la clé échoue soudainement à un certain moment, un grand nombre de requêtes simultanées entreront dans la base de données principale, provoquant une augmentation instantanée de sa pression. Ce phénomène est appelé rupture de cache.
3.2 Solution
Modifier l'heure d'expiration
Définissez les données du point d'accès pour qu'elles n'expirent jamais.
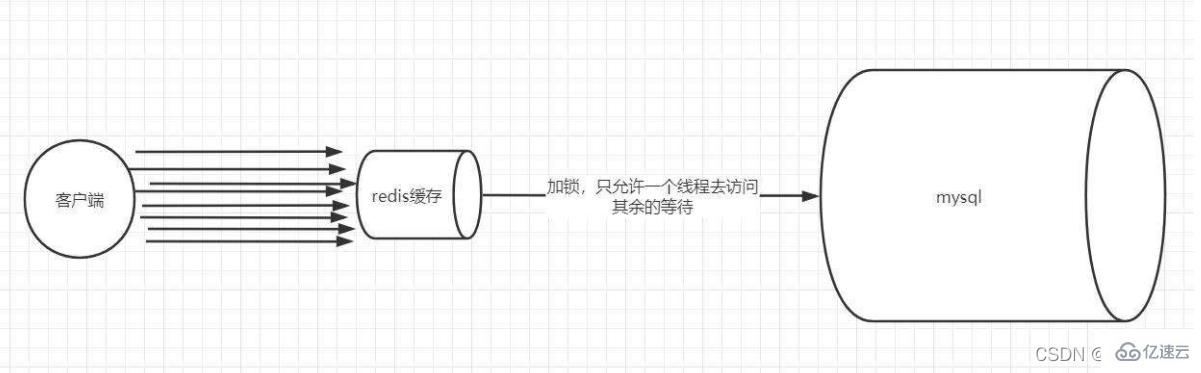
Verrouillage distribué
Adoptez la méthode de verrouillage distribué pour repenser l'utilisation du cache. Le processus est le suivant :
Lock : Lorsque nous interrogeons les données par clé, nous interrogeons d'abord le cache, sinon, verrouillez-le via un verrouillage distribué. Le premier processus pour obtenir le verrou entre dans la base de données principale pour interroger et met en mémoire tampon les résultats de la requête dans Redis.
Déverrouillage : lorsque d'autres processus constatent que le verrou est occupé par un certain processus, ils entrent en état d'attente. Après le déverrouillage, d'autres processus accèdent à leur tour à la clé mise en cache.
3.3 Comparaison des solutions
N'expire jamais : étant donné que cette solution ne fixe pas de délai d'expiration réel, il n'y a en fait aucune série de dangers causés par les clés de hotspot, mais il y aura une situation d'incohérence des données, et la complexité du code augmentera.
Verrouillage Mutex : L'idée de cette solution est relativement simple, mais il existe certains dangers cachés. S'il y a un problème dans le processus de création du cache ou si cela prend beaucoup de temps, il peut y avoir un risque de blocage et. blocage du pool de threads, mais cette méthode peut être plus efficace, elle réduit la charge de stockage back-end et fait un meilleur travail de cohérence.
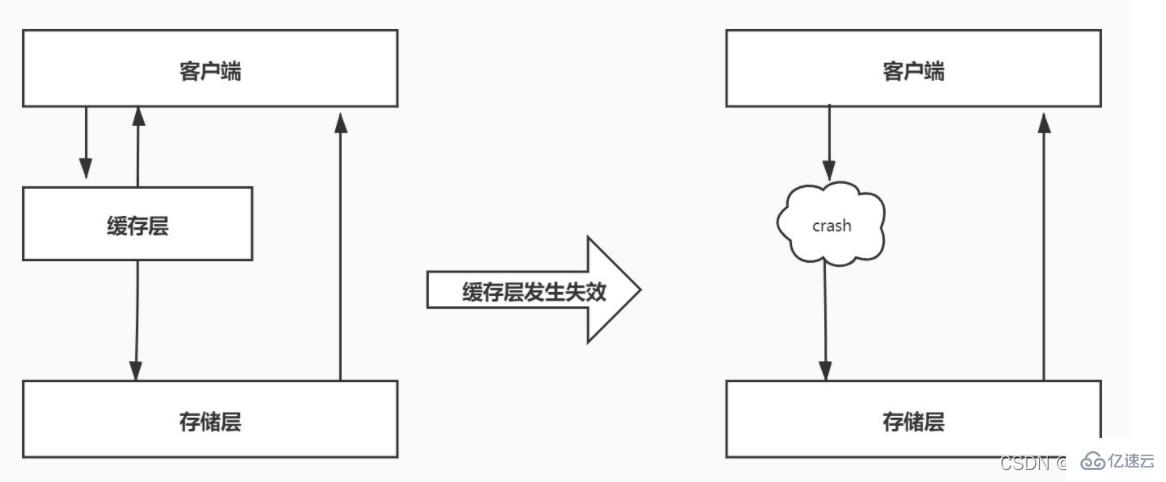
4. Avalanche de cache
4.1 Introduction
L'avalanche de cache signifie qu'un grand nombre de clés dans le cache expirent en même temps, et à ce moment-là, la quantité d'accès aux données est très importante, ce qui conduit à un augmentation soudaine de la pression sur la base de données back-end, et même Hang, ce phénomène est appelé avalanche de cache. Cela diffère de la panne du cache. La panne du cache se produit lorsqu'une certaine touche de raccourci expire soudainement lorsque le degré de concurrence est particulièrement important, tandis que l'avalanche du cache se produit lorsqu'un grand nombre de clés expirent en même temps, elles ne sont donc pas du même ordre. d'ampleur du tout.
4.2 Solution
Gestion de l'expiration
Afin de réduire les pannes de cache et les problèmes d'avalanche causés par un grand nombre de clés expirant en même temps, vous pouvez adopter la stratégie des données de hotspot ne jamais expirant, ce qui est différent de l'avalanche de cache. Il existe des similitudes. De plus, afin d'éviter que les clés n'expirent en même temps, vous pouvez leur définir une heure d'expiration aléatoire.
redis haute disponibilité
Un Redis peut raccrocher à cause d'une avalanche, vous pouvez alors ajouter quelques Redis supplémentaires et créer un cluster. Si l'un raccroche, les autres peuvent continuer à travailler.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Que faire si redis-server ne peut être trouvé
Apr 10, 2025 pm 06:54 PM
Que faire si redis-server ne peut être trouvé
Apr 10, 2025 pm 06:54 PM
Étapes pour résoudre le problème que Redis-Server ne peut pas trouver: Vérifiez l'installation pour vous assurer que Redis est installé correctement; Définissez les variables d'environnement redis_host et redis_port; Démarrer le serveur Redis Redis-Server; Vérifiez si le serveur exécute Redis-Cli Ping.
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Pour afficher toutes les touches dans Redis, il existe trois façons: utilisez la commande Keys pour retourner toutes les clés qui correspondent au modèle spécifié; Utilisez la commande SCAN pour itérer les touches et renvoyez un ensemble de clés; Utilisez la commande info pour obtenir le nombre total de clés.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment afficher le numéro de version de redis
Apr 10, 2025 pm 05:57 PM
Comment afficher le numéro de version de redis
Apr 10, 2025 pm 05:57 PM
Pour afficher le numéro de version redis, vous pouvez utiliser les trois méthodes suivantes: (1) Entrez la commande Info, (2) Démarrez le serveur avec l'option - Version et (3) afficher le fichier de configuration.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment effacer les données avec redis
Apr 10, 2025 pm 08:03 PM
Comment effacer les données avec redis
Apr 10, 2025 pm 08:03 PM
Les deux méthodes suivantes peuvent être utilisées pour effacer les données dans Redis: Commande Flushall: Supprimer toutes les clés et valeurs dans la base de données. Config ResetStat Commande: Réinitialisez tous les états de la base de données (y compris les clés, les valeurs et autres statistiques).
