
 base de données
Redis
Le filtre SpringBoot+Redis Bloom empêche le trafic malveillant de pénétrer dans le cache
base de données
Redis
Le filtre SpringBoot+Redis Bloom empêche le trafic malveillant de pénétrer dans le cache
Le filtre SpringBoot+Redis Bloom empêche le trafic malveillant de pénétrer dans le cache

Les détails sont les suivants :
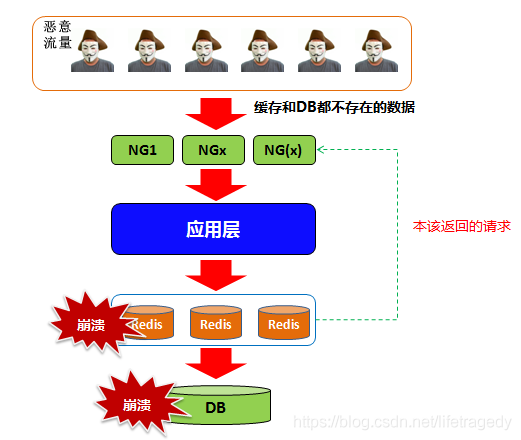
Qu'est-ce que la pénétration du trafic malveillant
Supposons que dans notre Redis Il existe un ensemble d'e-mails enregistrés d'utilisateurs, avec l'e-mail comme clé, et cela correspond à certains champs de la table User dans la base de données.
Normalement, nous vérifierons d'abord si l'utilisateur est membre de Redis, car il est plus rapide de lire les données du cache. Si ce membre n'existe pas dans le cache, nous l'interrogerons dans la base de données.
Imaginez maintenant qu'il y ait des dizaines de millions de requêtes provenant d'IP différentes (ne pensez pas qu'il n'y en a pas, nous les avons rencontrées en 2018 et 2019, car le coût des attaques est très faible) avec des requêtes qui n'existe pas dans Redis. clé pour accéder à votre site web, alors imaginons :
La requête parvient au serveur Web ; ##🎜🎜 #La requête est envoyée à la couche application->Couche microservice
Demande de récupération de données depuis Redis, cette clé n'existe pas dans Redis ;
Ensuite, la requête atteint la couche DB et une requête est effectuée une fois la connexion DB établie
- #🎜🎜 #Qu'il s'agisse de dizaines ou de centaines de millions de demandes de connexion à la base de données, peu importe que Redis puisse se le permettre, car la base de données sera immédiatement submergée. Il s'agit de « pénétration de Redis », également connue sous le nom de « panne de cache ». Elle fera exploser votre cache ou même la base de données, provoquant une série d'« effets d'avalanche ». Comment prévenir
Faux positifs&&Faux négatifs
Parce que BloomFiter sacrifie une certaine précision pour l'efficacité de l'espace. Cela pose donc le problème des faux positifs.
Faux positif
BloomFilter aura un certain taux d'erreur lorsqu'il jugera qu'un élément est dans la collection. Ce taux d'erreur est appelé faux positif. Généralement abrégé en fpp.
Faux négatifsTaux d'erreur de BloomFilter lorsqu'il juge qu'un élément n'est pas dans l'ensemble. BloomFilter détermine que l'élément n'est pas dans la collection, alors l'élément ne doit pas être dans la collection. La probabilité de faux négatifs est donc de 0.
BloomFilter utilise un tableau d'octets de longueur m bits, utilise k fonctions de hachage et ajoute un élément : mappez l'élément à k positions dans le tableau d'octets via k hachages et définissez la position correspondante. L'octet est 1.
Puisqu'il stocke des bits, la quantité de données sera très petite. Lors de la rédaction de ce blog, j'ai inséré 1 million de messages électroniques dans le filtre Bloom Redis et celui-ci n'occupait que moins de 3 Mo.
Bloom Filter aura plusieurs valeurs clés. Sur la base de cette valeur, vous pouvez calculer approximativement le nombre de données à introduire et la quantité de ressources système qu'elles occuperont, à quel moment elles causeront de faux dommages. Cet algorithme a une URL : https://krisives.github.io/bloom-calculator/ Nous mettons 1 million de données et supposons que le taux de dommages accidentels est de 0,001 %. Regardez, il détermine automatiquement les ressources de mémoire du système. pour lesquels Redis doit postuler, combien ?
Un autre cas d'utilisation du filtre Bloom
Supposons que j'ai exploré 400 millions d'URL avec un robot d'exploration Python, j'ai besoin de supprimer le poids ? 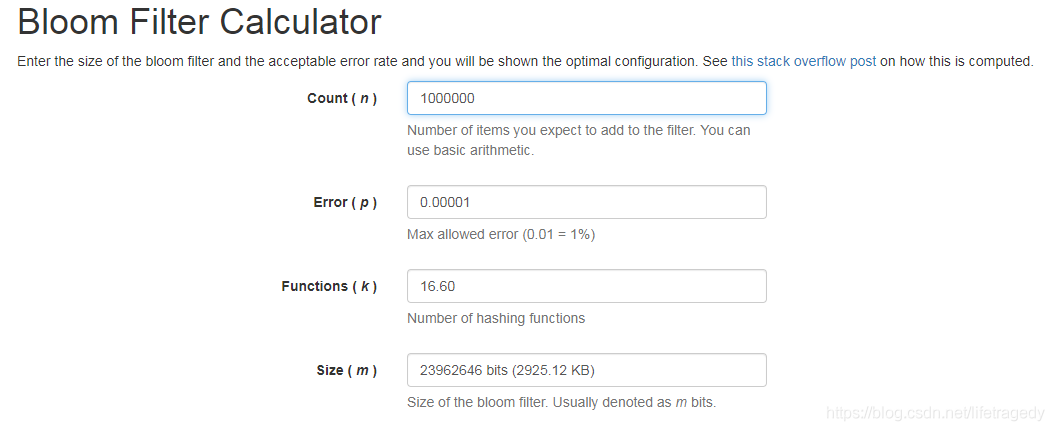
git clone https://github.com/RedisLabsModules/redisbloom.git
cd redisbloom
make # 编译
Copier après la connexion
Il existe deux façons de charger le filtre Bloom lorsque Redis démarre. Méthode : git clone https://github.com/RedisLabsModules/redisbloom.git cd redisbloom make # 编译
Chargement manuel :
redis-server --loadmodule ./redisbloom/rebloom.so
Auto-chargement à chaque démarrage : #🎜🎜 ## 🎜🎜#Modifiez le fichier redis.conf de Redis et ajoutez :
loadmodule /soft/redisbloom/redisbloom.so
在Redis里使用Bloom Filter
基本指令:
bf.reserve {key} {error_rate} {size}
127.0.0.1:6379> bf.reserve userid 0.01 100000 OK
上面这条命令就是:创建一个空的布隆过滤器,并设置一个期望的错误率和初始大小。{error_rate}过滤器的错误率在0-1之间,如果要设置0.1%,则应该是0.001。该数值越接近0,内存消耗越大,对cpu利用率越高。
bf.add {key} {item}
127.0.0.1:6379> bf.add userid '181920' (integer) 1
上面这条命令就是:往过滤器中添加元素。如果key不存在,过滤器会自动创建。
bf.exists {key} {item}
127.0.0.1:6379> bf.exists userid '101310299' (integer) 1
这个命令的作用是检查 Bloom 过滤器中是否包含指定 key 的值。存在:返回1,不存在:返回0。
结合SpringBoot使用
网上很多写的都是要么是直接使用jedis来操作的,或者是java里execute一个外部进程来调用Redis的bloom filter指令的。许多代码调试不通或只能达到helloworld级别,无法用于生产级别的应用。
笔者给出的代码保障读者完全可用!
笔者不是数学家,因此就借用了google的guava包来实现了核心算法,核心代码如下:
BloomFilterHelper.java
package org.sky.platform.util;
import com.google.common.base.Preconditions;
import com.google.common.hash.Funnel;
import com.google.common.hash.Hashing;
public class BloomFilterHelper<T> {
private int numHashFunctions;
private int bitSize;
private Funnel<T> funnel;
public BloomFilterHelper(Funnel<T> funnel, int expectedInsertions, double fpp) {
Preconditions.checkArgument(funnel != null, "funnel不能为空");
this.funnel = funnel;
bitSize = optimalNumOfBits(expectedInsertions, fpp);
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
int[] murmurHashOffset(T value) {
int[] offset = new int[numHashFunctions];
long hash74 = Hashing.murmur3_128().hashObject(value, funnel).asLong();
int hash2 = (int) hash74;
int hash3 = (int) (hash74 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int nextHash = hash2 + i * hash3;
if (nextHash < 0) {
nextHash = ~nextHash;
}
offset[i - 1] = nextHash % bitSize;
}
return offset;
}
/**
* 计算bit数组的长度
*/
private int optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (int) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
/**
* 计算hash方法执行次数
*/
private int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
}下面放出全工程解说,我已经将源码上传到了我的git上了,确保读者可用,源码地址在这:https://github.com/mkyuangithub/mkyuangithub.git
搭建spring boot工程
项目Redis配置
我们在redis-practice工程里建立一个application.properties文件,内容如下:
spring.redis.database=0 spring.redis.host=192.168.56.101 spring.redis.port=6379 spring.redis.password=111111 spring.redis.pool.max-active=10 spring.redis.pool.max-wait=-1 spring.redis.pool.max-idle=10 spring.redis.pool.min-idle=0 spring.redis.timeout=1000
以上这个是demo环境的配置。
我们此处依旧使用的是在前一篇springboot+nacos+dubbo实现异常统一管理中的xxx-project->sky-common->nacos-parent的依赖结构。
在redis-practice工程的org.sky.config包中放入redis的springboot配置
RedisConfig.java
package org.sky.config;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.*;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
@EnableCaching
public class RedisConfig extends CachingConfigurerSupport {
/**
* 选择redis作为默认缓存工具
*
* @param redisTemplate
* @return
*/
@Bean
public CacheManager cacheManager(RedisTemplate redisTemplate) {
RedisCacheManager rcm = new RedisCacheManager(redisTemplate);
return rcm;
}
/**
* retemplate相关配置
*
* @param factory
* @return
*/
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 配置连接工厂
template.setConnectionFactory(factory);
// 使用Jackson2JsonRedisSerializer来序列化和反序列化redis的value值(默认使用JDK的序列化方式)
Jackson2JsonRedisSerializer jacksonSeial = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
// 指定要序列化的域,field,get和set,以及修饰符范围,ANY是都有包括private和public
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
// 指定序列化输入的类型,类必须是非final修饰的,final修饰的类,比如String,Integer等会跑出异常
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jacksonSeial.setObjectMapper(om);
// 值采用json序列化
template.setValueSerializer(jacksonSeial);
// 使用StringRedisSerializer来序列化和反序列化redis的key值
template.setKeySerializer(new StringRedisSerializer());
// 设置hash key 和value序列化模式
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(jacksonSeial);
template.afterPropertiesSet();
return template;
}
/**
* 对hash类型的数据操作
*
* @param redisTemplate
* @return
*/
@Bean
public HashOperations<String, String, Object> hashOperations(RedisTemplate<String, Object> redisTemplate) {
return redisTemplate.opsForHash();
}
/**
* 对redis字符串类型数据操作
*
* @param redisTemplate
* @return
*/
@Bean
public ValueOperations<String, Object> valueOperations(RedisTemplate<String, Object> redisTemplate) {
return redisTemplate.opsForValue();
}
/**
* 对链表类型的数据操作
*
* @param redisTemplate
* @return
*/
@Bean
public ListOperations<String, Object> listOperations(RedisTemplate<String, Object> redisTemplate) {
return redisTemplate.opsForList();
}
/**
* 对无序集合类型的数据操作
*
* @param redisTemplate
* @return
*/
@Bean
public SetOperations<String, Object> setOperations(RedisTemplate<String, Object> redisTemplate) {
return redisTemplate.opsForSet();
}
/**
* 对有序集合类型的数据操作
*
* @param redisTemplate
* @return
*/
@Bean
public ZSetOperations<String, Object> zSetOperations(RedisTemplate<String, Object> redisTemplate) {
return redisTemplate.opsForZSet();
}
}这个配置除实现了springboot自动发现redis在application.properties中的配置外我们还添加了不少redis基本的数据结构的操作的封装。
我们为此还要再封装一套Redis Util小组件,它们位于sky-common工程中
RedisUtil.java
package org.sky.platform.util;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.util.Collection;
import java.util.Date;
import java.util.Set;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import com.google.common.base.Preconditions;
import org.springframework.data.redis.core.RedisTemplate;
@Component
public class RedisUtil {
@Autowired
private RedisTemplate<String, String> redisTemplate;
/**
* 默认过期时长,单位:秒
*/
public static final long DEFAULT_EXPIRE = 60 * 60 * 24;
/**
* 不设置过期时长
*/
public static final long NOT_EXPIRE = -1;
public boolean existsKey(String key) {
return redisTemplate.hasKey(key);
}
/**
* 重名名key,如果newKey已经存在,则newKey的原值被覆盖
*
* @param oldKey
* @param newKey
*/
public void renameKey(String oldKey, String newKey) {
redisTemplate.rename(oldKey, newKey);
}
/**
* newKey不存在时才重命名
*
* @param oldKey
* @param newKey
* @return 修改成功返回true
*/
public boolean renameKeyNotExist(String oldKey, String newKey) {
return redisTemplate.renameIfAbsent(oldKey, newKey);
}
/**
* 删除key
*
* @param key
*/
public void deleteKey(String key) {
redisTemplate.delete(key);
}
/**
* 删除多个key
*
* @param keys
*/
public void deleteKey(String... keys) {
Set<String> kSet = Stream.of(keys).map(k -> k).collect(Collectors.toSet());
redisTemplate.delete(kSet);
}
/**
* 删除Key的集合
*
* @param keys
*/
public void deleteKey(Collection<String> keys) {
Set<String> kSet = keys.stream().map(k -> k).collect(Collectors.toSet());
redisTemplate.delete(kSet);
}
/**
* 设置key的生命周期
*
* @param key
* @param time
* @param timeUnit
*/
public void expireKey(String key, long time, TimeUnit timeUnit) {
redisTemplate.expire(key, time, timeUnit);
}
/**
* 指定key在指定的日期过期
*
* @param key
* @param date
*/
public void expireKeyAt(String key, Date date) {
redisTemplate.expireAt(key, date);
}
/**
* 查询key的生命周期
*
* @param key
* @param timeUnit
* @return
*/
public long getKeyExpire(String key, TimeUnit timeUnit) {
return redisTemplate.getExpire(key, timeUnit);
}
/**
* 将key设置为永久有效
*
* @param key
*/
public void persistKey(String key) {
redisTemplate.persist(key);
}
/**
* 根据给定的布隆过滤器添加值
*/
public <T> void addByBloomFilter(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
redisTemplate.opsForValue().setBit(key, i, true);
}
}
/**
* 根据给定的布隆过滤器判断值是否存在
*/
public <T> boolean includeByBloomFilter(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
Preconditions.checkArgument(bloomFilterHelper != null, "bloomFilterHelper不能为空");
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
if (!redisTemplate.opsForValue().getBit(key, i)) {
return false;
}
}
return true;
}
}RedisKeyUtil.java
package org.sky.platform.util;
public class RedisKeyUtil {
/**
* redis的key 形式为: 表名:主键名:主键值:列名
*
* @param tableName 表名
* @param majorKey 主键名
* @param majorKeyValue 主键值
* @param column 列名
* @return
*/
public static String getKeyWithColumn(String tableName, String majorKey, String majorKeyValue, String column) {
StringBuffer buffer = new StringBuffer();
buffer.append(tableName).append(":");
buffer.append(majorKey).append(":");
buffer.append(majorKeyValue).append(":");
buffer.append(column);
return buffer.toString();
}
/**
* redis的key 形式为: 表名:主键名:主键值
*
* @param tableName 表名
* @param majorKey 主键名
* @param majorKeyValue 主键值
* @return
*/
public static String getKey(String tableName, String majorKey, String majorKeyValue) {
StringBuffer buffer = new StringBuffer();
buffer.append(tableName).append(":");
buffer.append(majorKey).append(":");
buffer.append(majorKeyValue).append(":");
return buffer.toString();
}
}然后就是制作 redis里如何使用BloomFilter的BloomFilterHelper.java了,它也位于sky-common文件夹,源码如上已经贴了,因此此处就不再作重复。
最后我们在sky-common里放置一个UserVO用于演示
UserVO.java
package org.sky.vo;
import java.io.Serializable;
public class UserVO implements Serializable {
private String name;
private String address;
private Integer age;
private String email = "";
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}下面给出我们所有gitrepo里依赖的nacos-parent的pom.xml文件内容,此次我们增加了对于“spring-boot-starter-data-redis”,它跟着我们的全局springboot版本走:

parent工程的pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.sky.demo</groupId>
<artifactId>nacos-parent</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>pom</packaging>
<description>Demo project for Spring Boot Dubbo Nacos</description>
<modules>
</modules>
<properties>
<java.version>1.8</java.version>
<spring-boot.version>1.5.15.RELEASE</spring-boot.version>
<dubbo.version>2.7.3</dubbo.version>
<curator-framework.version>4.0.1</curator-framework.version>
<curator-recipes.version>2.8.0</curator-recipes.version>
<druid.version>1.1.20</druid.version>
<guava.version>27.0.1-jre</guava.version>
<fastjson.version>1.2.59</fastjson.version>
<dubbo-registry-nacos.version>2.7.3</dubbo-registry-nacos.version>
<nacos-client.version>1.1.4</nacos-client.version>
<mysql-connector-java.version>5.1.46</mysql-connector-java.version>
<disruptor.version>3.4.2</disruptor.version>
<aspectj.version>1.8.13</aspectj.version>
<nacos-service.version>0.0.1-SNAPSHOT</nacos-service.version>
<spring.data.redis>1.8.14-RELEASE</spring.data.redis>
<skycommon.version>0.0.1-SNAPSHOT</skycommon.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<compiler.plugin.version>3.8.1</compiler.plugin.version>
<war.plugin.version>3.2.3</war.plugin.version>
<jar.plugin.version>3.1.2</jar.plugin.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>${spring-boot.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
<version>${dubbo.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo</artifactId>
<version>${dubbo.version}</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>${curator-framework.version}</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>${curator-recipes.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql-connector-java.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>${druid.version}</version>
</dependency>
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>${disruptor.version}</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-registry-nacos</artifactId>
<version>${dubbo-registry-nacos.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba.nacos</groupId>
<artifactId>nacos-client</artifactId>
<version>${nacos-client.version}</version>
</dependency>
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>${aspectj.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>${spring-boot.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${compiler.plugin.version}</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<version>${war.plugin.version}</version>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>${jar.plugin.version}</version>
</plugin>
</plugins>
</build>
</project>sky-common中pom.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.sky.demo</groupId> <artifactId>skycommon</artifactId> <version>0.0.1-SNAPSHOT</version> <parent> <groupId>org.sky.demo</groupId> <artifactId>nacos-parent</artifactId> <version>0.0.1-SNAPSHOT</version> </parent> <dependencies> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> </dependency> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-recipes</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.spockframework</groupId> <artifactId>spock-core</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.spockframework</groupId> <artifactId>spock-spring</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-configuration-processor</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-log4j2</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <exclusions> <exclusion> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-logging</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.aspectj</groupId> <artifactId>aspectjweaver</artifactId> </dependency> <dependency> <groupId>com.lmax</groupId> <artifactId>disruptor</artifactId> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> </dependency> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> </dependencies> </project>
到此,我们的springboot+redis基本框架、util类、bloomfilter组件搭建完毕,接下来我们重点说我们的demo工程
Demo工程:redis-practice说明
pom.xml文件,它依赖于nacos-parent同时还引用了sky-common
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.sky.demo</groupId>
<artifactId>redis-practice</artifactId>
<version>0.0.1-SNAPSHOT</version>
<description>Demo Redis Advanced Features</description>
<parent>
<groupId>org.sky.demo</groupId>
<artifactId>nacos-parent</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo</artifactId>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.spockframework</groupId>
<artifactId>spock-core</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.spockframework</groupId>
<artifactId>spock-spring</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</dependency>
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
</dependency>
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
</dependency>
<dependency>
<groupId>org.sky.demo</groupId>
<artifactId>skycommon</artifactId>
<version>${skycommon.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/test/java</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
<resources>
<resource>
<directory>src/main/resources</directory>
</resource>
<resource>
<directory>src/main/webapp</directory>
<targetPath>META-INF/resources</targetPath>
<includes>
<include>**/**</include>
</includes>
</resource>
<resource>
<directory>src/main/resources</directory>
<filtering>true</filtering>
<includes>
<include>application.properties</include>
<include>application-${profileActive}.properties</include>
</includes>
</resource>
</resources>
</build>
</project>用于启动的Application.java
package org.sky;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@EnableTransactionManagement
@ComponentScan(basePackages = { "org.sky" })
@EnableAutoConfiguration
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}然后我们制作了一个controller名为UserController,该controller里有两个方法:
public ResponseEntity
addUser(@RequestBody String params),该方法用于接受来自外部的api post然后把一条email地址塞入redis的bloomfilter中; public ResponseEntity
findEmailInBloom(@RequestBody String params),该方法用于接受来自外部的api post然后去redis的bloomfilter中验证是否外部输入的user信息中的email地址在上百万的email记录中存在;
以此来完成验证塞入redis的bloom filter中上百万条记录占用了多少内存以及使用bloom filter查询一条记录有多快。
UserController.java
package org.sky.controller;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;
import javax.annotation.Resource;
import org.sky.platform.util.BloomFilterHelper;
import org.sky.platform.util.RedisUtil;
import org.sky.vo.UserVO;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpStatus;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.google.common.base.Charsets;
import com.google.common.hash.Funnel;
@RestController
@RequestMapping("user")
public class UserController extends BaseController {
@Resource
private RedisTemplate redisTemplate;
@Resource
private RedisUtil redisUtil;
@PostMapping(value = "/addEmailToBloom", produces = "application/json")
public ResponseEntity<String> addUser(@RequestBody String params) {
ResponseEntity<String> response = null;
String returnResultStr;
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON_UTF8);
Map<String, Object> result = new HashMap<>();
try {
JSONObject requestJsonObj = JSON.parseObject(params);
UserVO inputUser = getUserFromJson(requestJsonObj);
BloomFilterHelper<String> myBloomFilterHelper = new BloomFilterHelper<>((Funnel<String>) (from,
into) -> into.putString(from, Charsets.UTF_8).putString(from, Charsets.UTF_8), 1500000, 0.00001);
redisUtil.addByBloomFilter(myBloomFilterHelper, "email_existed_bloom", inputUser.getEmail());
result.put("code", HttpStatus.OK.value());
result.put("message", "add into bloomFilter successfully");
result.put("email", inputUser.getEmail());
returnResultStr = JSON.toJSONString(result);
logger.info("returnResultStr======>" + returnResultStr);
response = new ResponseEntity<>(returnResultStr, headers, HttpStatus.OK);
} catch (Exception e) {
logger.error("add a new product with error: " + e.getMessage(), e);
result.put("message", "add a new product with error: " + e.getMessage());
returnResultStr = JSON.toJSONString(result);
response = new ResponseEntity<>(returnResultStr, headers, HttpStatus.INTERNAL_SERVER_ERROR);
}
return response;
}
@PostMapping(value = "/checkEmailInBloom", produces = "application/json")
public ResponseEntity<String> findEmailInBloom(@RequestBody String params) {
ResponseEntity<String> response = null;
String returnResultStr;
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON_UTF8);
Map<String, Object> result = new HashMap<>();
try {
JSONObject requestJsonObj = JSON.parseObject(params);
UserVO inputUser = getUserFromJson(requestJsonObj);
BloomFilterHelper<String> myBloomFilterHelper = new BloomFilterHelper<>((Funnel<String>) (from,
into) -> into.putString(from, Charsets.UTF_8).putString(from, Charsets.UTF_8), 1500000, 0.00001);
boolean answer = redisUtil.includeByBloomFilter(myBloomFilterHelper, "email_existed_bloom",
inputUser.getEmail());
logger.info("answer=====" + answer);
result.put("code", HttpStatus.OK.value());
result.put("email", inputUser.getEmail());
result.put("exist", answer);
returnResultStr = JSON.toJSONString(result);
logger.info("returnResultStr======>" + returnResultStr);
response = new ResponseEntity<>(returnResultStr, headers, HttpStatus.OK);
} catch (Exception e) {
logger.error("add a new product with error: " + e.getMessage(), e);
result.put("message", "add a new product with error: " + e.getMessage());
returnResultStr = JSON.toJSONString(result);
response = new ResponseEntity<>(returnResultStr, headers, HttpStatus.INTERNAL_SERVER_ERROR);
}
return response;
}
private UserVO getUserFromJson(JSONObject requestObj) {
String userName = requestObj.getString("username");
String userAddress = requestObj.getString("address");
String userEmail = requestObj.getString("email");
int userAge = requestObj.getInteger("age");
UserVO u = new UserVO();
u.setName(userName);
u.setAge(userAge);
u.setEmail(userEmail);
u.setAddress(userAddress);
return u;
}
}注意UserController中的BloomFilterHelper的用法,我在Redis的bloomfilter里申明了可以用于存放150万数据的空间。如果存和的数据大于了你预先申请的空间怎么办?那么它会增加“误伤率”。
下面我们把这个项目运行起来看看效果吧。
运行redis-practice工程
运行起来后
我们可以使用postman先来做个小实验
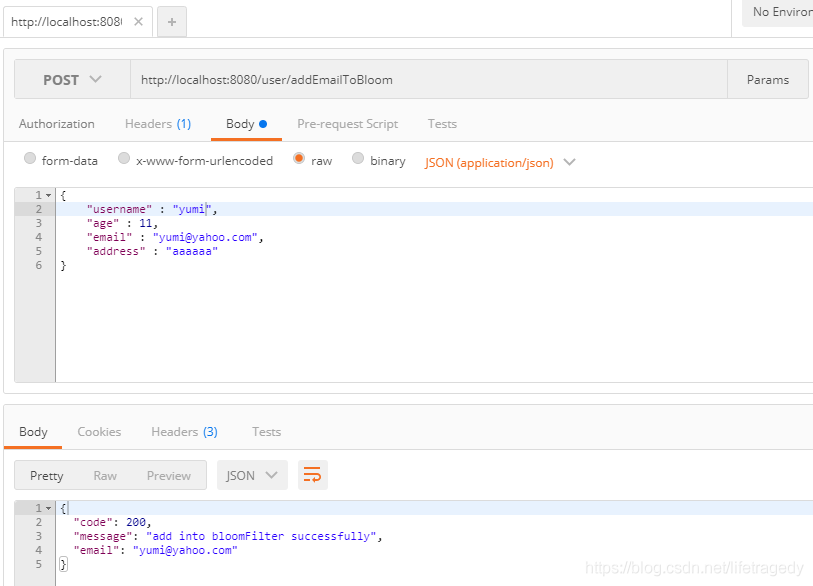
我们使用"、addEmailToBloom"往redis bloom filter里插入了一个“yumi@yahoo.com”的email。
接下来我们会使用“/checkEmailInBloom”来验证这个email地址是否存在
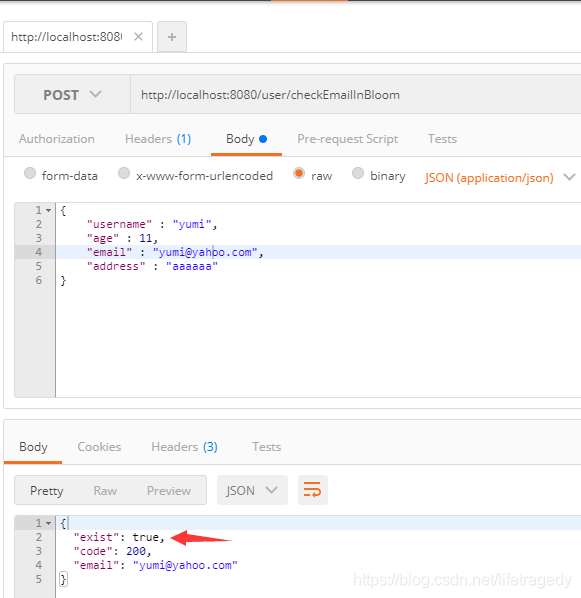
我们使用redisclient连接上我们的redis查看,这个值确实也是插入进了bloom filter了。
使用压测工具喂120万条数据进入Redis Bloomfilter看实际效果
接下来,我们用jmeter对着“/addEmailToBloom”喂上个120万左右数据进去,然后我们再来看bloom filter在120万email按照布隆算 法喂进去后我们的系统是如何表现的。
我这边使用的是apache-jmeter5.0,为了偷懒,我用了apache-jmeter里的_RandomString函数来动态创造16位字符长度的email。这边用户名、地址信息都是恒定,就是email是每次不一样,都是一串16位的随机字符+“@163.com”。
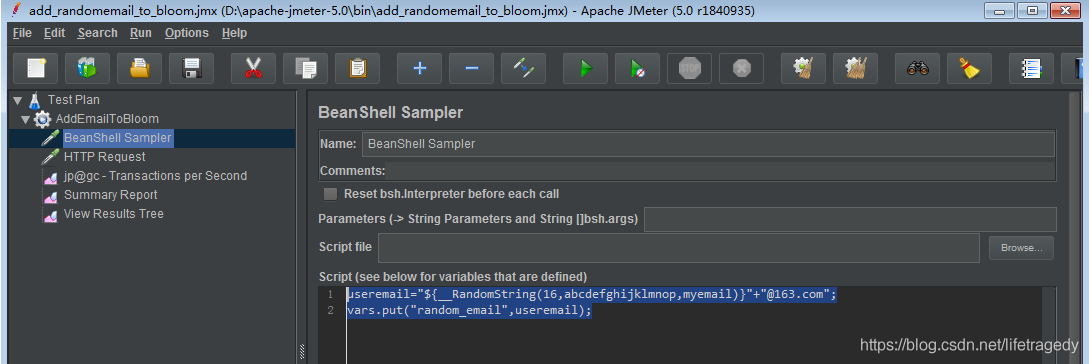
jmeter中BeanShell产生16位字符随机组成email的函数
useremail="${__RandomString(16,abcdefghijklmnop,myemail)}"+"@163.com";
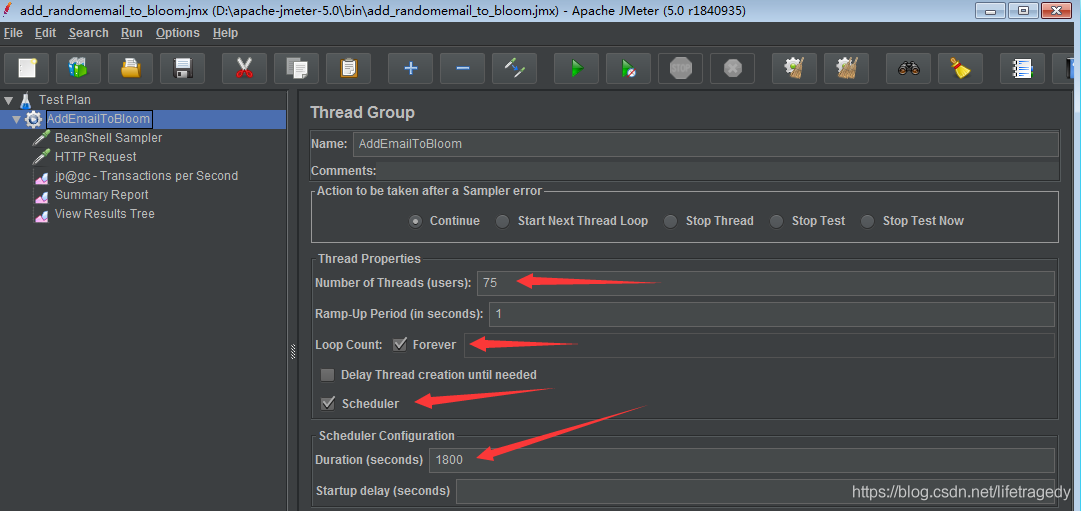
vars.put("random_email",useremail);jmeter测试计划设置成了75个线程,连续运行30分钟(实践上笔者运行了3个30分钟,因为是demo环境,30分钟每次插大概40万条数据进去吧)
jmeter post请求
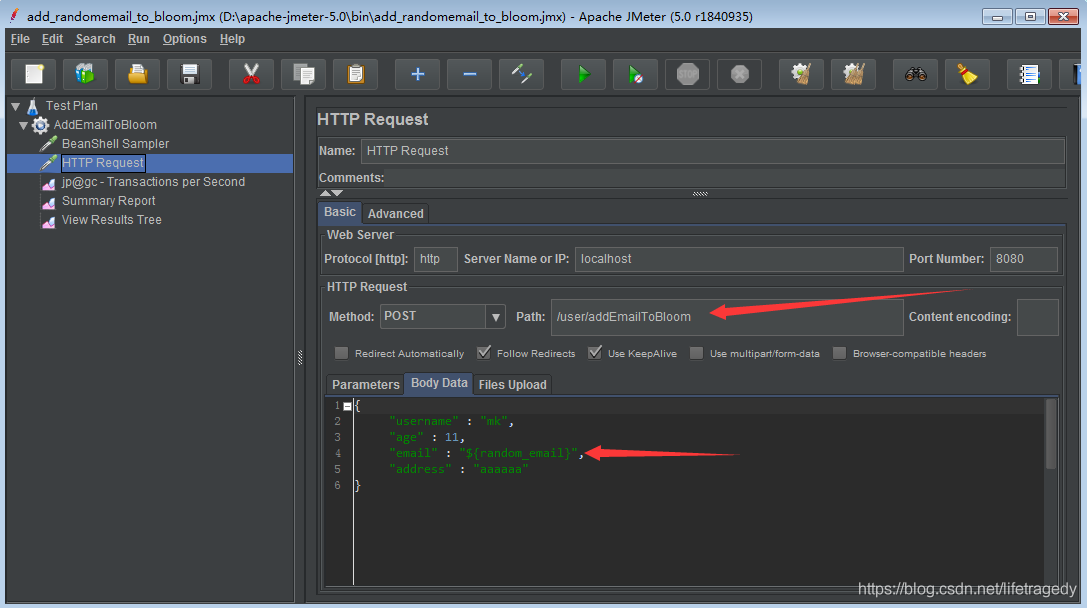
然后我们使用jmeter命令行来运行这个测试计划:
jmeter -n -t add_randomemail_to_bloom.jmx -l add_email_to_bloom\report\03-result.csv -j add_email_to_bloom\logs\03-log.log -e -o add_email_to_bloom\html_report_3
它代表:
-t 指定jmeter执行计划文件所在路径;
-l 生成report的目录,这个目录如果不存在则创建 ,必须是一个空目录;
-j 生成log的目录,这个目录如果不存在则创建 ,必须是一个空目录;
-e 生成html报告,它配合着-o参数一起使用;
-o 生成html报告所在的路径,这个目录如果不存在则创建 ,必须是一个空目录;
回车后它就开始运行了
一直执行到这个过程全部结束,跳出command命令符为止。
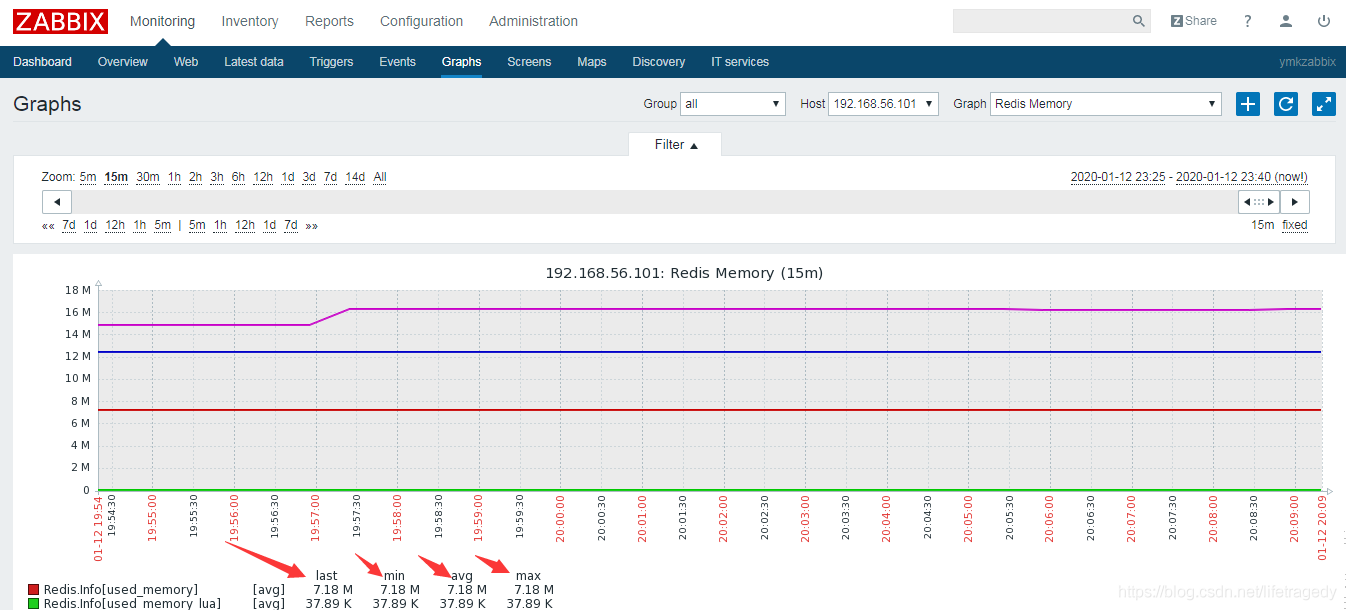
我们查看我们用-e -o生成的jmeter html报告,前面说过了,我一共运行了3次,第一次是10分钟70059条数据 ,第二次是30分钟40多万条数据 ,第三次是45他钟70多万条数据。我共计插入了1,200,790条email。
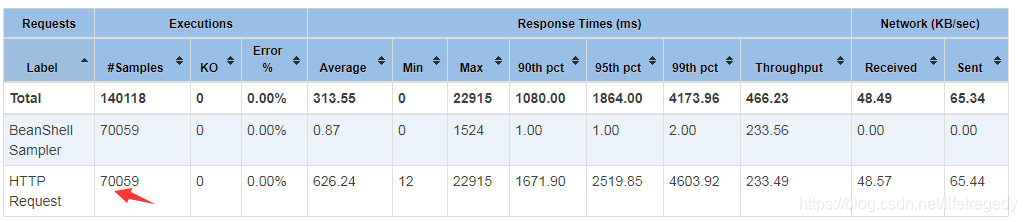
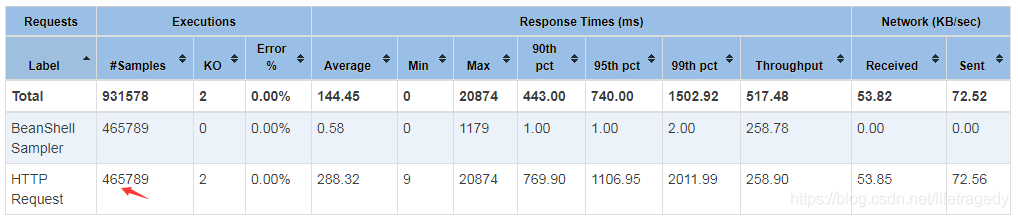
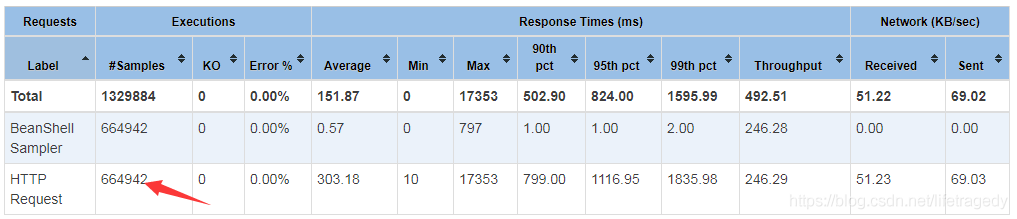
而这120万数据总计在redis中占用内存不超过8mb,见下面demo环境的zabbix录制的记录
120万条数据插进去后,我们接着从我们的log4j的输出中随便找一条logger.info住的email如:egpoghnfjekjajdo@163.com来看一下,redis bloomfilter找到这条记录的表现如何,76ms,我运行了多次,平均在80ms左右:
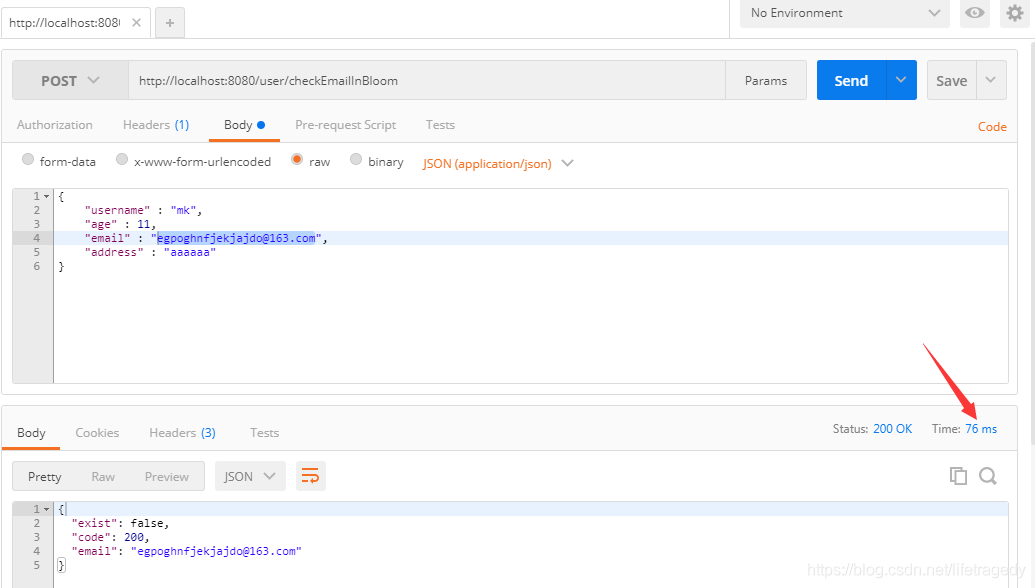
通过上面这么一个实例,大家可以看到把email以hash后并以bit的形式存入bloomfilter后,它占用的内存是多么的小,而查询效率又是多么的高。
往往在生产上,我们经常会把上千万或者是上亿的记录"load"进bloomfilter,然后拿它去做“防击穿”或者是去重的动作。
Tant que la clé qui n'existe pas dans bloomfilter renvoie directement false au client, avec l'expansion dynamique de la mise en cache de nginx, cdn, waf et de la couche d'interface, il est en fait très simple pour l'ensemble du site Web de résister à 6 chiffres ou même une simultanéité à 7 chiffres.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Redis, en tant que Message Middleware, prend en charge les modèles de consommation de production, peut persister des messages et assurer une livraison fiable. L'utilisation de Redis comme Message Middleware permet une faible latence, une messagerie fiable et évolutive.
