

Comment configurer le mode maître-esclave du cluster Redis


1. Pourquoi un cluster est-il nécessaire ?
Dans notre développement actuel, il n'est pas possible d'utiliser un seul Redis dans les projets d'ingénierie pour les raisons suivantes :
# 🎜🎜#(1) En termes de structure, un seul serveur Redis présente le risque d'un point de défaillance unique, et un serveur doit supporter la charge de toutes les requêtes, ce qui est relativement stressant #🎜🎜 #
(2) En termes de capacité, la capacité mémoire d'un seul serveur Redis est limitée Même si un serveur Redis a une capacité mémoire de 256G, toute la mémoire ne peut pas être utilisée comme. Mémoire de stockage Redis De manière générale, un seul serveur Redis La mémoire maximale utilisée par Redis ne doit pas dépasser 20 Go.(3) Les performances de lecture et d'écriture d'un seul serveur Redis sont limitées et les capacités de lecture et d'écriture peuvent être améliorées en utilisant un cluster.
2. Mode maître-esclave
Introduction
Actuellement, Redis a trois Il existe trois modes de cluster, à savoir : le mode maître-esclave, le mode sentinelle et le mode Cluster ; le mode maître-esclave est le plus simple des trois modes dans la réplication maître-esclave, il fait référence à la copie des données d'un Redis. serveur vers d’autres serveurs Redis. Le premier est appelé nœud maître (maître/leader), tandis que le second est appelé nœud esclave (esclave/suiveur).Note :
(1) La copie des données est unidirectionnel, ne peut aller que du nœud maître au nœud esclave. Le maître est principalement destiné à l'écriture et l'esclave est principalement destiné à la lecture.(2) Par défaut, chaque serveur Redis est un nœud maître ; (3) Un nœud maître peut avoir plusieurs nœuds esclaves (ou aucun nœud esclave), mais un nœud esclave ne peut avoir qu'un nœud maître. .
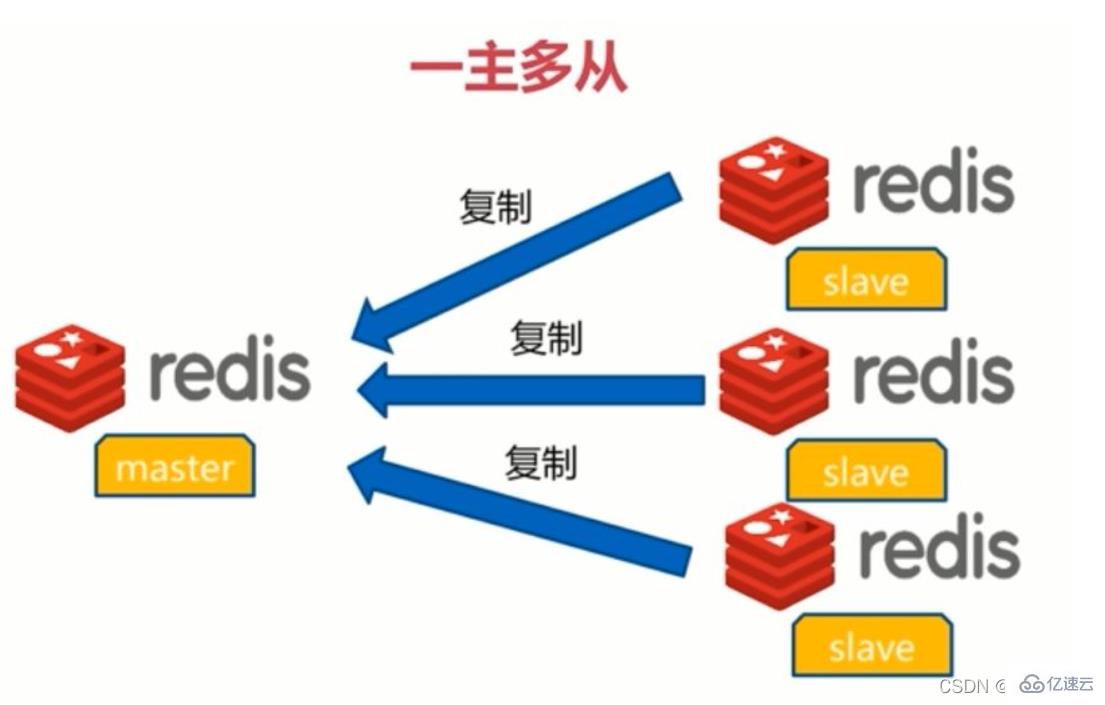 Fonction
Fonction
Redondance des données # 🎜🎜# : La réplication maître-esclave implémente la sauvegarde à chaud des données, qui est une méthode de redondance des données en plus de la persistance.Écrire moins et lire plus2. Récupération après panne : Lorsqu'un problème survient sur le nœud maître, le nœud esclave peut fournir des services pour réaliser une récupération rapide après panne ; il s'agit en fait d'une sorte de redondance de service.
un produit ne doit être téléchargé qu'une seule fois, mais il peut être consulté plusieurs fois par les utilisateurs #🎜🎜 #, c'est-à-dire "
3. Pierre angulaire de la haute disponibilité (Cluster) : La réplication maître-esclave est également la base de la mise en œuvre des sentinelles et des clusters. Par conséquent, la réplication maître-esclave est la base de Redis high. disponibilité.
4. Load Balancing : Basé sur la réplication maître-esclave et avec une séparation lecture-écriture, le nœud maître peut fournir des services d'écriture et les nœuds esclaves peuvent fournir des services de lecture (c'est-à-dire lorsque écriture de données Redis L'application se connecte au nœud maître, et lors de la lecture des données Redis, l'application se connecte au nœud esclave) pour partager la charge du serveur, en particulier dans les scénarios où il y a moins d'écriture et plus de lecture, partageant la charge de lecture via plusieurs esclaves ; Les nœuds peuvent considérablement augmenter la concurrence du serveur Redis.
Par exemple, vous pouvez trouver sur notre site e-commerce qu'
" Dans ce cas, nous pouvons utiliser la réplication maître-esclave pour séparer la lecture et l'écriture , #🎜 🎜# pour ralentir la pression du serveur:
3. Construire un cluster maître-esclave#🎜 🎜#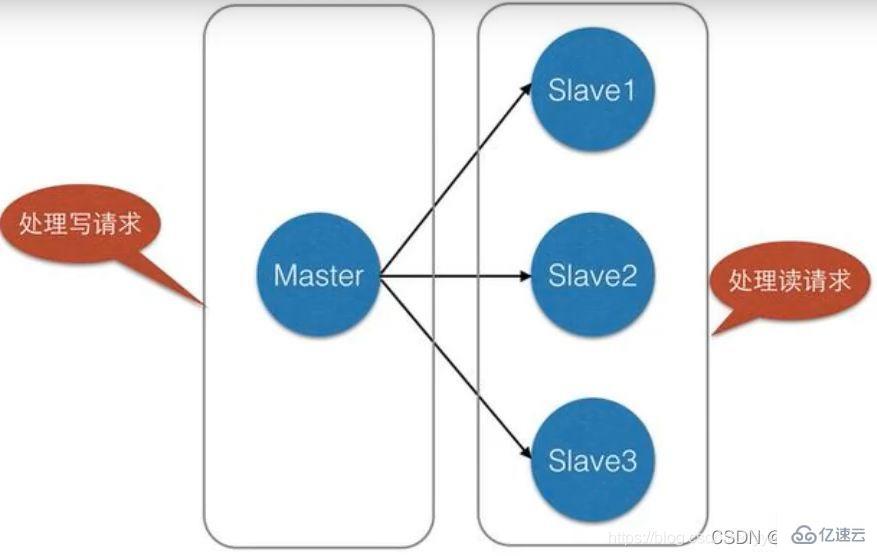
1. Copiez les trois fichiers de configuration (nom d'origine : redis.conf) et renommez-les. eux respectivement : redis79.conf, redis80 .conf, redis81.conf.
2. Modifier le fichier de configuration

Modifier le numéro de port
port 6379
daemonize:yes
logfile “6379.log"
dbfilename dump6379.rdb
Modifier le numéro de port
port 6380
daemonize:yes
Définir le nom du fichier d'identification du processus de journalisation
pidfile /var/run/redis_6380.pid
#🎜🎜 # Définir le nom du fichier journal#🎜 🎜#logfile “6380.log"
dbfilename dump6380.rdb
#🎜🎜 #Modifier le numéro de port
port 6381
daemonize:yes
Définir le nom du fichier d'identification du processus d'enregistrement
pidfile /var/run/redis_6381.pid
Définir le nom du fichier journal#🎜🎜 #
logfile “6381.log"
Définir le nom du fichier db# 🎜🎜#dbfilename dump6381.rdb
#🎜🎜 #
pid(port ID) : L'ID du processus est enregistré et le fichier est verrouillé. Empêche le programme d'être démarré plusieurs fois.logfile : Effacer l'emplacement du fichier journal dbfilename : dumpxxx.file #Emplacement du fichier persistantport : Le numéro de port occupé par le processus
3.2、搭建一主二从
启动Redis服务器
注意:默认情况下,每台Reids服务器都是主节点,而我们要搭建主从只需要在从机那本搭建即可。
现在分别启动redis79,redis80,redis81服务器。
redis-server redis79.conf redis-server redis80.conf redis-server redis81.conf
使用以下命令,查看是否启动成功:
ps -ef|grep redis

打开三个客户端窗口,分别对应操作三个Redis服务器。
输入命令:
注意要指定端口,才知道我们要打开哪一个Redis。
窗口一:
redis-cli -p 6379
窗口二:
redis-cli -p 6380
窗口三:
redis-cli -p 6381
设置主从关系
我们将redis79设置为主节点,而将redis80和redis81设置为从结点。
配置主机的IP地址和端口号,相当于想认其为自己的老大。
redis80:
#SLAVEOF IP地址 端口 127.0.0.1:6380> slaveof 127.0.0.1 6379 OK
redis81:
#SLAVEOF IP地址 端口 127.0.0.1:6381> slaveof 127.0.0.1 6379 OK
这个时候,我们在从机使用INFO命令就可以查看主从关系了:
info replication
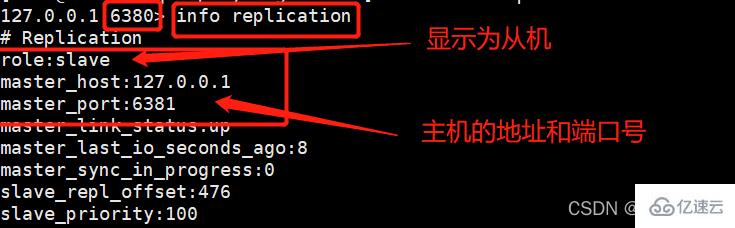
而此时我们去主机redis79中使用同样的命令进行查看:
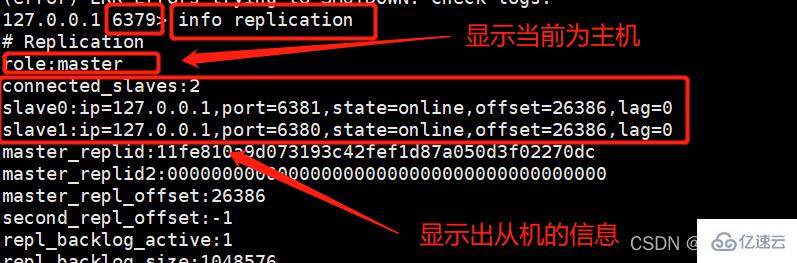
现在我们的一主二从的关系就成功搭建好了!
提示:如果要将从机变成主机,我们只需要在从机执行以下命令,即可让自己变为主机。
SLAVEOF no one
四、知识讲解
知识一
主机可以进行读写操作,而从机只能读操作。
注意:主机中的所有信息和数据,都会自动被从机保存。
主机:
127.0.0.1:6379> set key1 v1 OK 127.0.0.1:6379> get key1 "v1"
从机:
127.0.0.1:6380> get key1 "v1" 127.0.0.1:6380> set key2 v2 #进行写操作就会报错,提示从机只能进行读操作 (error) READONLY You can't write against a read only replica.
知识二
主机如果宕机了,从机依旧可以读取到主机宕机前的数据,但仍然没有写操作,如果主机恢复过来了,从机依旧可以获取到主机写的数据。
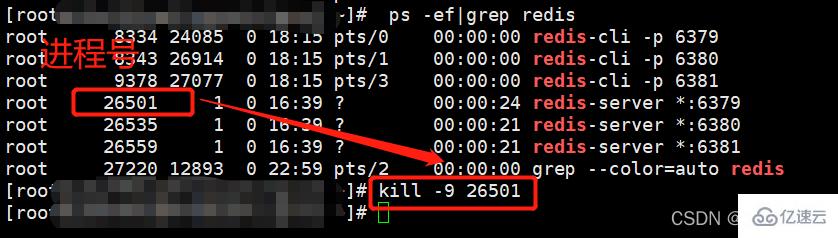
(1)停止主机进程(演示主机宕机了)
停止进程的命令:
kill -9 pid #pid为redis进程号
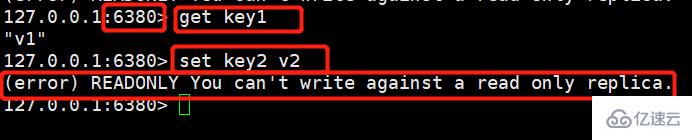
(2)从机获取宕机前主机写入的数据
可以发现,能够顺利拿到,但仍然是无法进行写操作的。
(3)恢复主机
redis-server redis79.conf
(4)主机重新写入数据,从机获取最新数据。
主机写入数据:
127.0.0.1:6379> set k2 yixin OK
从机读取最新数据:
127.0.0.1:6380> get k2 "yixin"
知识三
两种配置方式下的从机断开情况
a、命令行设置主从关系
从机断开了,其重新连接后变为主机,能拿到断开之前的数据,但拿不到主机新写入的值,如果重新设置主从关系,就可以拿到主机全部的数据了。
(1)停止从机进程。
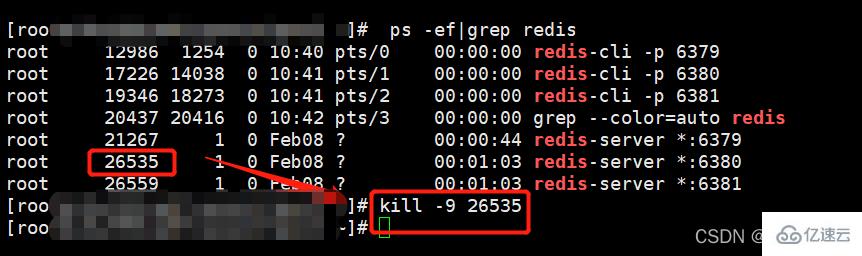
(2)主机写入新数据。
127.0.0.1:6379> set k3 new OK
(3)重新启动从机服务器。
redis-server redis80.conf
(4)尝试获取从机宕机前主机写入的数据,发现可以拿到。
127.0.0.1:6380> get k1 "v1"
(5)尝试获取从机宕机期间主机写入的数据,发现无法拿到了。
127.0.0.1:6380> get k3 (nil)
此次我们可以进行查看主从关系,由于是命令行配置的,所以重启之后又变回主机了。
127.0.0.1:6380> info replication # Replication role:master connected_slaves:0
(6)如果要拿到主机的所有数据,只要执行以下命令重新配置主从关系就可以了。
slaveof 127.0.0.1 6379
b、配置文件设置的主从关系
从机断开后,重新连接,也是可以拿到主机的全部数据的。
(1)修改配置文件redis80.conf,添加主从关系。
#指定主机的ip与port slaveof 127.0.0.1 6379
(2)主机添加新数据
127.0.0.1:6379> set k5 hello OK
(3)重新启动redis80服务器。
redis-server redis80.conf
(4)获取从机宕机期间主机新写入的数据,发现现在可以顺利拿到了。
127.0.0.1:6380> get k5 "hello"
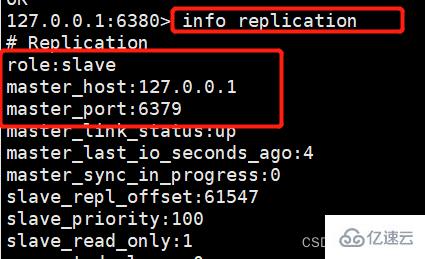
我们来查看6380的主从关系,可以发现在重启的时候就已经设置好主从关系了。
五、复制原理
(1)Slave 启动成功连接到 Master 后会发送一个sync同步命令
(2)Master 接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
(3)全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
(4)增量复制:Master 继续将新的所有收集到的修改命令依次传给slave,完成同步。
注意:只要是重新连接master,一次完全同步(全量复制)将被自动执行! 我们的数据一定可以在从机中看到。
六、主从模式的优缺点
优点
(1)同一个Master可以同步多个Slaves。
(2)Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载Master的同步压力。因此我们可以将Redis的Replication架构视为图结构。
(3)Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端仍然可以提交查询或修改请求。
(4)Slave Server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据。
(5)为了分载Master的读操作压力,Slave服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成。即便如此,系统的伸缩性还是得到了很大的提高。
(6)Master可以将数据保存操作交给Slaves完成,从而避免了在Master中要有独立的进程来完成此操作。
(7)支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
缺点
(1) Redis 主从模式不具备自动容错和恢复功能,如果主节点宕机,Redis 集群将无法工作,此时需要人为干预,将从节点提升为主节点。
(2) 如果主机宕机前有一部分数据未能及时同步到从机,即使切换主机后也会造成数据不一致的问题,从而降低了系统的可用性。
(3) 因为只有一个主节点,所以其写入能力和存储能力都受到一定程度地限制。
(4) 在进行数据全量同步时,若同步的数据量较大可能会造卡顿的现象。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
