

Quelles sont les manières courantes d'utiliser Redis ?

1. Méthodes d'utilisation courantes
Plusieurs méthodes d'utilisation courantes de Redis incluent :
1. plusieurs copies (maître-esclave) ;
3.Redis Sentinel (sentinelle)
4.Redis Cluster ; développement .
2. Avantages et inconvénients des différentes méthodes d'utilisation
1 Copie unique Redis
Copie unique Redis, utilisant une architecture de déploiement de nœud Redis unique, non Le nœud de secours synchronise les données en temps réel et ne fournit pas de stratégies de persistance et de sauvegarde des données. Il convient aux scénarios commerciaux de mise en cache pure avec de faibles exigences de fiabilité des données.
Avantages : 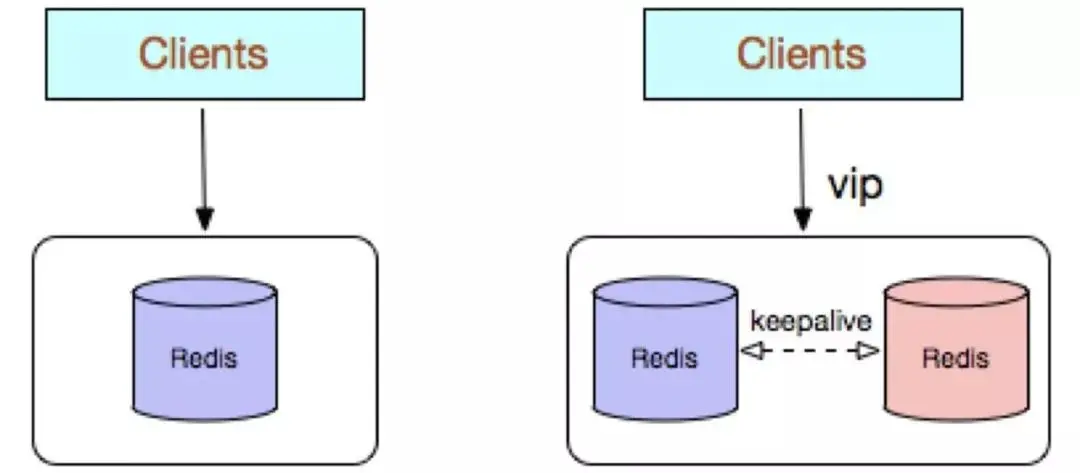
Architecture simple et déploiement facile
Coût élevé ; performances : Il n'y a pas besoin de nœud de sauvegarde lors de l'utilisation du cache (la disponibilité d'une seule instance peut être garantie par superviseur ou crontab Bien entendu, afin de répondre à la haute disponibilité de l'entreprise, un nœud de sauvegarde peut également être). sacrifié, mais une seule instance peut fournir des services externes en même temps
#🎜 🎜#Haute performance. Inconvénients : ne garantit pas la fiabilité des données Une fois le cache utilisé et le processus redémarré, les données sont perdues, même s'il existe un nœud de sauvegarde pour résoudre le problème. Haute disponibilité, mais cela ne peut toujours pas résoudre le problème de préchauffage du cache, il ne convient donc pas aux entreprises ayant des exigences élevées en matière de fiabilité des données Les hautes performances sont limitées par ; En raison de la puissance de traitement d'un processeur monocœur (Redis est un mécanisme monothread), le processeur est le principal goulot d'étranglement, il convient donc aux scénarios avec des commandes d'opération simples et moins de tri et de calcul. Vous pouvez également envisager d'utiliser Memcached à la place. 2. Copies multiples Redis (maître-esclave) Les copies multiples Redis adoptent une structure de déploiement maître-esclave (réplication) Par rapport à une seule copie, la plus grande fonctionnalité est. que les données maîtres sont synchronisées en temps réel entre les instances et que des stratégies de persistance et de sauvegarde des données sont fournies. La configuration de l'environnement de base de l'entreprise permet de déployer des instances maître-esclave sur différents serveurs physiques pour réaliser simultanément des stratégies de fourniture de services externes et de séparation en lecture-écriture. Avantages :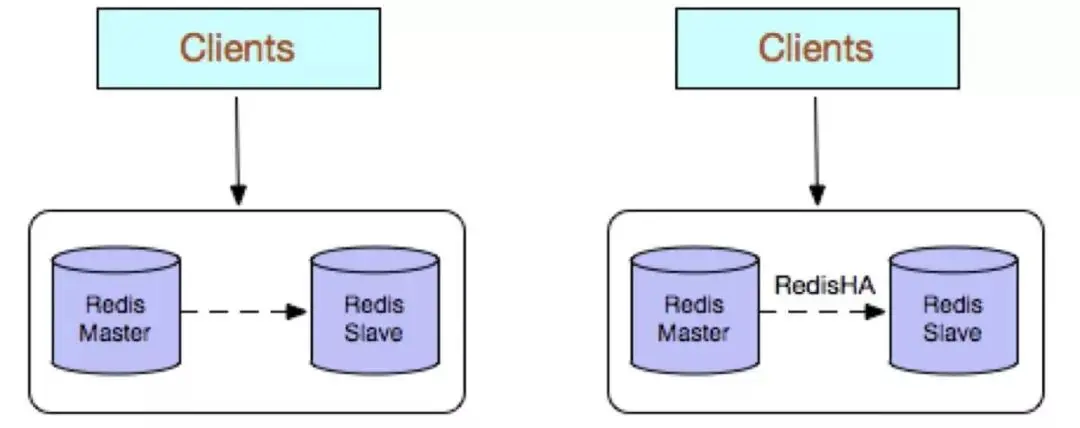 Haute fiabilité : D'une part, il adopte un double serveur principal et de sauvegarde architecture, qui peut Lorsque la base de données principale tombe en panne, elle effectue automatiquement la commutation maître-sauvegarde, et la base de données esclave est promue pour fournir des services à la base de données principale afin d'assurer le bon fonctionnement du service, d'autre part, en activant la fonction de persistance des données. et la configuration d'une stratégie de sauvegarde raisonnable peut résoudre efficacement le problème du mauvais fonctionnement des données et du mauvais fonctionnement des données.
Haute fiabilité : D'une part, il adopte un double serveur principal et de sauvegarde architecture, qui peut Lorsque la base de données principale tombe en panne, elle effectue automatiquement la commutation maître-sauvegarde, et la base de données esclave est promue pour fournir des services à la base de données principale afin d'assurer le bon fonctionnement du service, d'autre part, en activant la fonction de persistance des données. et la configuration d'une stratégie de sauvegarde raisonnable peut résoudre efficacement le problème du mauvais fonctionnement des données et du mauvais fonctionnement des données.
;
La capacité d'écriture de la base de données principale est limitée par une seule machine, elle peut donc être considérée comme du Sharding ; La capacité de stockage de la bibliothèque principale est limitée par une seule machine, vous pouvez considérer Pika ; Les inconvénients de la réplication native seront également plus importants dans les versions antérieures, telles que : Redis Après l'interruption de la réplication, l'esclave lancera psync. Si la synchronisation échoue à ce moment, un. une synchronisation complète sera effectuée. Lorsque la bibliothèque principale effectue une sauvegarde complète, cela peut provoquer des retards d'une milliseconde ou de deuxième niveau et, en raison du mécanisme COW, cela peut provoquer des problèmes dans des cas extrêmes. le programme se ferme anormalement ou plante ; le nœud de la bibliothèque principale génère des fichiers de sauvegarde, ce qui consomme les ressources d'E/S du disque du serveur et de CPU (compression) ; l'envoi de fichiers de sauvegarde de plusieurs Go provoque une augmentation soudaine de la bande passante d'exportation du serveur et bloque les requêtes. Dernière version. 3, Redis Sentinel (Sentinel) Redis Sentinel est une solution native haute disponibilité lancée dans la version communautaire Son architecture de déploiement comprend principalement deux parties : le cluster Redis Sentinel et. Cluster de données Redis. Le cluster Redis Sentinel est un cluster distribué composé de plusieurs nœuds Sentinel, qui peut réaliser la découverte de pannes, le basculement automatique, le centre de configuration et la notification client. Le nombre de nœuds pour satisfaire Redis Sentinel doit être un nombre impair et le nombre est 2n+1 (n≥1).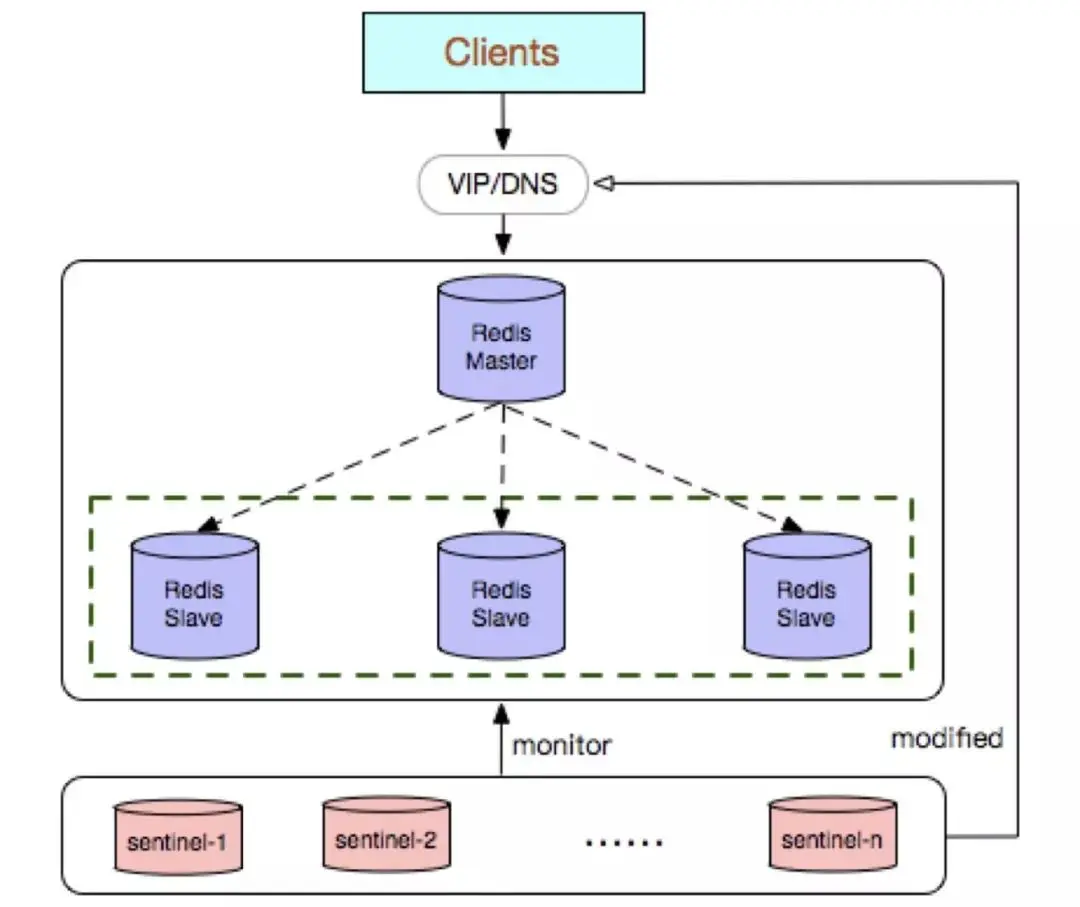
 peut résoudre le problème de commutation de haute disponibilité en mode maître-esclave Redis
peut résoudre le problème de commutation de haute disponibilité en mode maître-esclave Redis
Cela ne peut pas résoudre le problème de la séparation entre lecture et écriture, et c'est relativement compliqué à mettre en œuvre.
Suggestion :
Si vous surveillez la même entreprise, vous pouvez choisir un cluster Sentinel pour surveiller plusieurs groupes de nœuds de données Redis. Sinon, choisissez un cluster Sentinel pour surveiller un groupe. du plan de nœuds de données Redis.
Il est recommandé de définir la configuration du moniteur Sentinel sur la moitié des nœuds Sentinel plus 1. Lorsque Sentinel est déployé dans plusieurs IDC, il n'est pas recommandé de dépasser le nombre de Sentinels déployés dans un seul IDC (numéro Sentinel – quorum).
Définissez les paramètres de manière raisonnable pour éviter toute coupure accidentelle et contrôlez le contrôle de la sensibilité de commutation :
a quorum
b. 🎜#
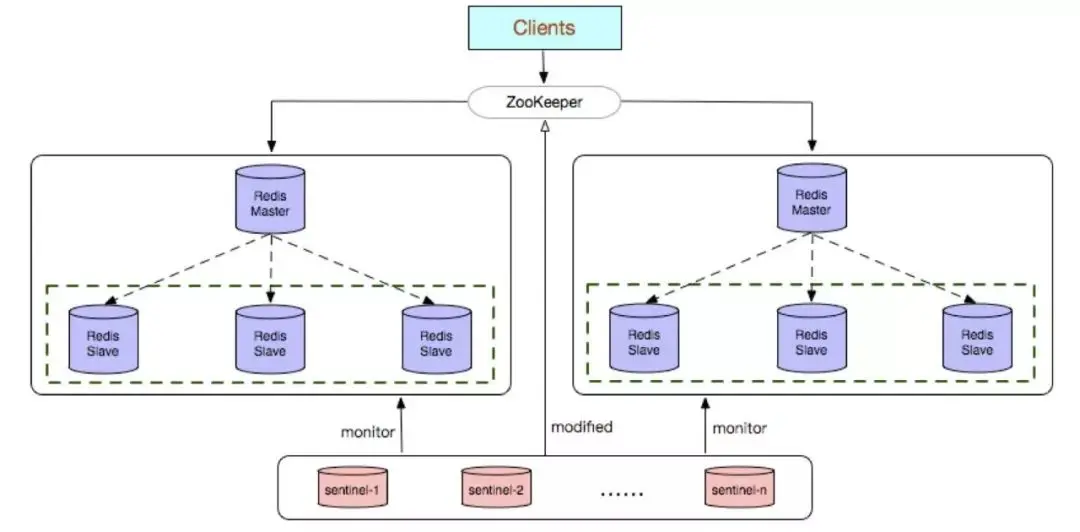
c. failover-timeout 180000d maxcliente. synchronisation la plus longue possible, sinon le timing du journal sera perturbé. Redis recommande d'utiliser des opérations de pipeline et multi-clés pour réduire le nombre de RTT et améliorer l'efficacité des requêtes. Configurez vous-même le centre de configuration (zookeeper) pour faciliter l'accès des clients au lien de l'instance. 4, Redis ClusterRedis Cluster est une solution de cluster distribué Redis lancée par la version communautaire. Elle résout principalement les besoins de la distribution Redis, par exemple, en cas de rencontre unique. Mémoire machine , lorsqu'il y a des goulots d'étranglement tels que la concurrence et le trafic, Redis Cluster peut atteindre un bon objectif d'équilibrage de charge. La configuration minimale du nœud de cluster Redis Cluster est supérieure à 6 nœuds (3 maîtres et 3 esclaves). Le nœud maître fournit des opérations de lecture et d'écriture, et le nœud esclave sert de nœud de sauvegarde. ne fournit pas de requêtes et n'est utilisé que pour le basculement. Redis Cluster utilise le partitionnement des emplacements virtuels. Toutes les clés sont mappées sur 0 ~ 16383 emplacements entiers selon la fonction de hachage. Chaque nœud est responsable de la maintenance d'une partie des emplacements et des données de valeur de clé mappées par le. créneaux.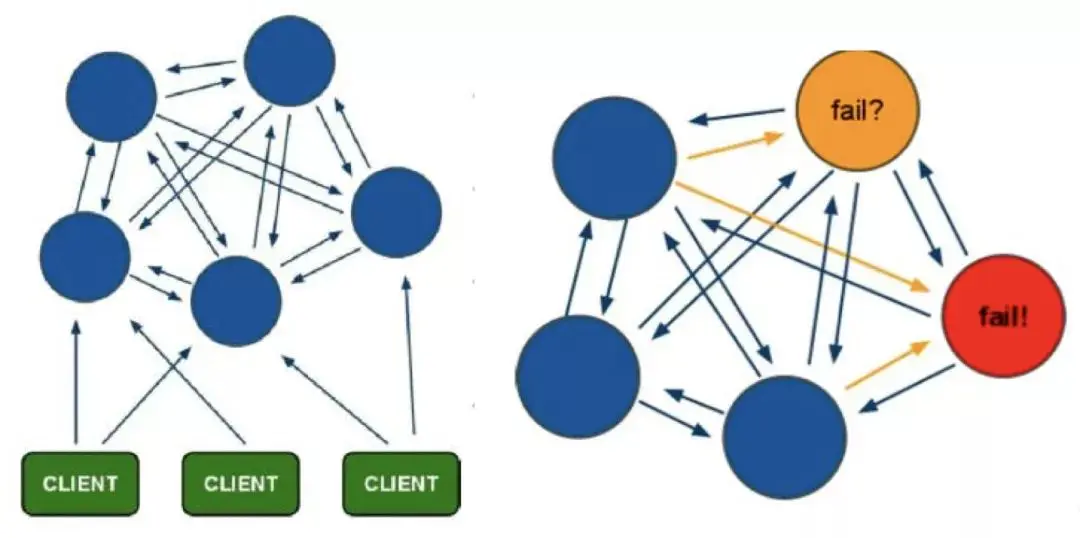 Avantages :
Avantages :
Avantages :
haute fiabilité et haute disponibilité ;
haute autonomie et contrôlabilité
adapté aux besoins réels de l'entreprise, bonne évolutivité et bonne compatibilité ;
Inconvénients :
Mise en œuvre complexe et coûts de développement élevés ;
Besoin d'établir des installations périphériques de support, telles que la surveillance, les services de noms de domaine, les bases de données pour stocker les informations de métadonnées, etc. ;
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Pour afficher toutes les touches dans Redis, il existe trois façons: utilisez la commande Keys pour retourner toutes les clés qui correspondent au modèle spécifié; Utilisez la commande SCAN pour itérer les touches et renvoyez un ensemble de clés; Utilisez la commande info pour obtenir le nombre total de clés.
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
