

Comment maîtriser l'architecture de réplication MySQL


Architecture de réplication à un maître et plusieurs esclaves
Dans les applications pratiques, la plupart des modèles d'architecture de réplication MySQL copient un maître vers un ou plusieurs esclaves.
Dans un scénario où la pression des demandes de lecture de la bibliothèque principale est très élevée, vous pouvez configurer l'architecture de réplication à un maître et à plusieurs esclaves pour obtenir une séparation en lecture et en écriture et distribuer un grand nombre de demandes de lecture qui ne nécessitent pas de temps réel particulièrement élevé. -performances en temps réel de la base de données grâce à l'équilibrage de charge sur plusieurs bibliothèques esclaves (les requêtes de lecture avec des exigences en temps réel élevées peuvent être lues à partir de la bibliothèque principale) pour réduire la pression de lecture sur la bibliothèque principale, comme le montre la figure ci-dessous.
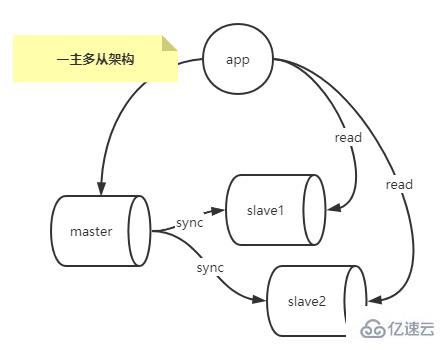
Inconvénients :
Le maître ne peut pas être arrêté, et il ne peut pas recevoir de demandes d'écriture lorsqu'il est arrêté
Il y aura des retards s'il y a trop d'esclaves
Depuis le maître doit être arrêté pour une maintenance de routine, alors un esclave doit être le maître de la Commission, lequel choisir est une question ?
Lorsqu'un esclave devient maître, il y aura des incohérences entre les données du maître actuel et celles du maître précédent, et le maître précédent n'a pas enregistré le fichier binlog et l'emplacement de position du nœud maître actuel.
Architecture de réplication multi-maître
L'architecture de réplication multi-maître résout le problème de point de défaillance unique du maître dans l'architecture de réplication multi-esclave à maître unique.
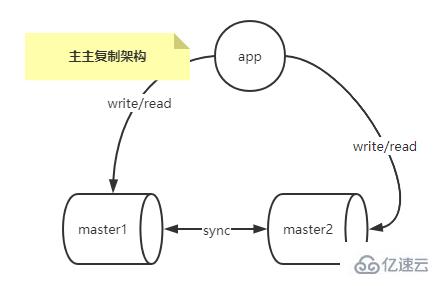
Vous pouvez utiliser un outil tiers, tel que keepalived, pour réaliser facilement une dérive IP, afin que les temps d'arrêt et la maintenance du maître n'affectent pas les opérations d'écriture.
Architecture de réplication en cascade
Un maître et plusieurs esclaves. S'il y a trop d'esclaves, la pression d'E/S et la pression du réseau de la bibliothèque principale augmenteront avec l'augmentation des bibliothèques esclaves, car chaque bibliothèque esclave aura un BINLOG indépendant. Le thread de vidage est utilisé pour envoyer des événements, et l'architecture de réplication en cascade résout les E/S supplémentaires et la pression réseau sur la bibliothèque principale dans le scénario maître-multi-esclave.
Comme le montre l’image ci-dessous.
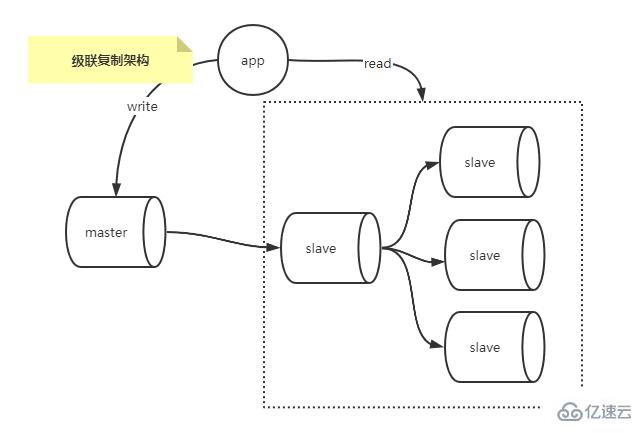
Par rapport à l'architecture un maître-multiple-esclave, la réplication en cascade copie uniquement les données de la base de données maître vers un petit nombre de bases de données esclaves, et d'autres bases de données esclaves copient ensuite les données de ce petit nombre de bases de données esclaves, ainsi alléger la charge de travail de la pression de la base de données maître.
Bien sûr, il y a des inconvénients : la réplication traditionnelle de MySQL est asynchrone. Dans le scénario de réplication en cascade, les données de la base de données maître doivent être répliquées deux fois avant d'atteindre les autres bases de données esclaves. Le délai pendant cette période est comparé à celui d'une base de données maître. scénario de réplication multi-esclave où les données ne sont expérimentées qu'une seule fois. La copie est encore plus volumineuse.
En sélectionnant le moteur de table BLACKHOLE sur la base de données esclave secondaire, la latence de la réplication en cascade peut être réduite. Comme son nom l'indique, le moteur BLACKHOLE est un moteur de « trou noir ». Les données écrites dans la table BLACKHOLE ne seront pas écrites sur le disque. La table BLACKHOLE est toujours une table vide. Les opérations INSERT, UPDATE et DELETE enregistrent uniquement les événements. dans le BINLOG.
Ce qui suit démontre le moteur BLACKHOLE :
mysql> CREATE TABLE `user` (
-> `id` int NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> `name` varchar(255) NOT NULL DEFAULT '',
-> `age` tinyint unsigned NOT NULL DEFAULT 0
-> )ENGINE=BLACKHOLE charset=utf8mb4;Query OK, 0 rows affected (0.00 sec)mysql> INSERT INTO `user` (`name`,`age`) values("itbsl", "26");Query OK, 1 row affected (0.00 sec)mysql> select * from user;Empty set (0.00 sec)Vous pouvez voir qu'il n'y a aucune donnée dans la table utilisateur avec le moteur de stockage de BLACKHOLE.
Architecture combinée de réplication multi-maître et en cascade
Combine l'architecture de réplication multi-maître et en cascade, qui résout le problème du maître monopoint et résout le problème du délai de cascade esclave.
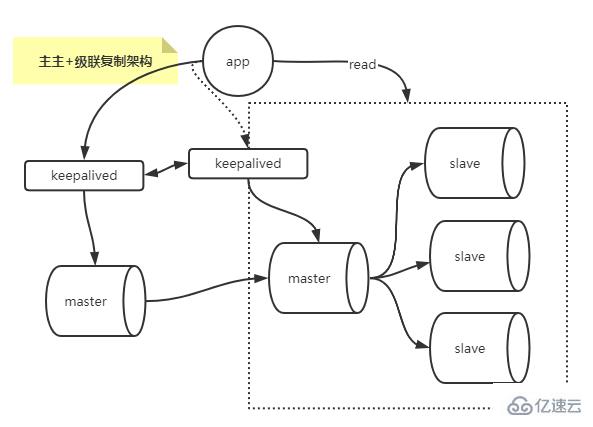
Construction d'une architecture de réplication multi-maître
Planification de l'hôte :
master1 : docker, port 3314
master2 : docker, port 3315
configuration master1
fichier de configuration my.cnf :$ cat /home/mysql/docker-data/3315/conf/my.cnf [mysqld] character_set_server=utf8 init_connect='SET NAMES utf8' symbolic-links=0 lower_case_table_names=1 server-id=1403314 log-bin=mysql-bin binlog-format=ROW auto_increment_increment=2 # 几个主库,这里就配几 auto_increment_offset=1 # 每个主库的偏移量需要不一致 gtid_mode=ON enforce-gtid-consistency=true binlog-do-db=order # 要同步的数据库
$ docker run --name mysql3314 -p 3314:3306 --privileged=true -ti -e MYSQL_ROOT_PASSWORD=root -e MYSQL_DATABASE=order -e MYSQL_USER=user -e MYSQL_PASSWORD=pass -v /home/mysql/docker-data/3314/conf:/etc/mysql/conf.d -v /home/mysql/docker-data/3314/data/:/var/lib/mysql -v /home/mysql/docker-data/3314/logs/:/var/log/mysql -d mysql:5.7
mysql> GRANT REPLICATION SLAVE,FILE,REPLICATION CLIENT ON *.* TO 'repluser'@'%' IDENTIFIED BY '123456'; Query OK, 0 rows affected, 1 warning (0.01 sec) mysql> FLUSH PRIVILEGES; Query OK, 0 rows affected (0.01 sec)
mysql> change master to master_host='172.23.252.98',master_port=3315,master_user='repluser',master_password='123456',master_auto_position=1; Query OK, 0 rows affected, 2 warnings (0.03 sec) mysql> start slave; Query OK, 0 rows affected (0.00 sec)
auto_increment_offset=2 # 每个主库的偏移量需要不一致
mysql> create table t_order(id int primary key auto_increment, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into t_order(name) values("A");
Query OK, 1 row affected (0.01 sec)
mysql> insert into t_order(name) values("B");
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_order;
+----+------+
| id | name |
+----+------+
| 2 | A |
| 4 | B |
+----+------+
2 rows in set (0.00 sec)mysql> select * from t_order;
+----+------+
| id | name |
+----+------+
| 2 | A |
| 4 | B |
+----+------+
2 rows in set (0.00 sec)
mysql> insert into t_order(name) values("E");
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_order;
+----+------+
| id | name |
+----+------+
| 2 | A |
| 4 | B |
| 5 | E |
+----+------+
3 rows in set (0.00 sec)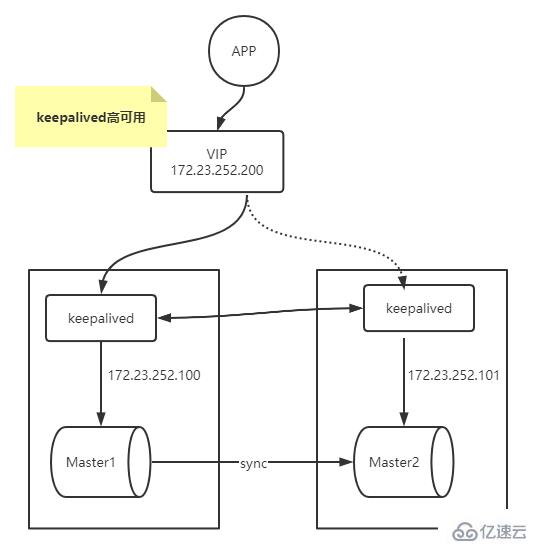
$ sudo apt-get install -y keepalived
$ cat /etc/keepalived/keepalived3314.conf! Configuration File for keepalived#简单的头部,这里主要可以做邮件通知报警等的设置,此处就暂不配置了;global_defs {
#notificationd LVS_DEVEL}#预先定义一个脚本,方便后面调用,也可以定义多个,方便选择;vrrp_script chk_haproxy {
script "/etc/keepalived/chkmysql.sh" #具体脚本路径
interval 2 #脚本循环运行间隔}#VRRP虚拟路由冗余协议配置vrrp_instance VI_1 { #VI_1 是自定义的名称;
state BACKUP #MASTER表示是一台主设备,BACKUP表示为备用设备【我们这里因为设置为开启不抢占,所以都设置为备用】
nopreempt #开启不抢占
interface eth0 #指定VIP需要绑定的物理网卡
virtual_router_id 11 #VRID虚拟路由标识,也叫做分组名称,该组内的设备需要相同
priority 130 #定义这台设备的优先级 1-254;开启了不抢占,所以此处优先级必须高于另一台
advert_int 1 #生存检测时的组播信息发送间隔,组内一致
authentication { #设置验证信息,组内一致
auth_type PASS #有PASS 和 AH 两种,常用 PASS
auth_pass asd #密码
}
virtual_ipaddress {
172.23.252.200 #指定VIP地址,组内一致,可以设置多个IP
}
track_script { #使用在这个域中使用预先定义的脚本,上面定义的
chk_haproxy }
#notify_backup "/etc/init.d/haproxy restart" #表示当切换到backup状态时,要执行的脚本
#notify_fault "/etc/init.d/haproxy stop" #故障时执行的脚本}$ cat /etc/keepalived/chkmysql.s.sh#!/bin/bashmysql -uroot -proot -P 3314 -e "show status;" > /dev/null 2>&1if [ $? == 0 ];then
echo "$host mysql login successfully"
exit 0else
echo "$host login failed"
killall keepalived exit 2fiCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1205
24
52
1205
24

 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
 Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Comment démarrer MySQL par Docker
Apr 15, 2025 pm 12:09 PM
Le processus de démarrage de MySQL dans Docker se compose des étapes suivantes: Tirez l'image MySQL pour créer et démarrer le conteneur, définir le mot de passe de l'utilisateur racine et mapper la connexion de vérification du port Créez la base de données et l'utilisateur accorde toutes les autorisations sur la base de données
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
