

Méthode d'intégration Redis du cache Springboot

La valeur par défaut est d'utiliser ConcurrentMapCache de ConcurrentMapCacheManager comme composant de cache.
Lors de l'utilisation de ConcurrentMap, les données sont enregistrées dans ConcurrentMap<object></object>.
En fait, pendant le processus de développement, nous utilisons souvent des middleware de mise en cache.
Par exemple, nous utilisons souvent Redis, Memcache, y compris l'ehcache que nous utilisons, etc. Nous utilisons tous des middleware de mise en cache.
Lorsque nous avons expliqué le principe précédemment, nous avons également découvert que springboot prend en charge de nombreuses configurations de cache :
Comme le montre la figure ci-dessous :
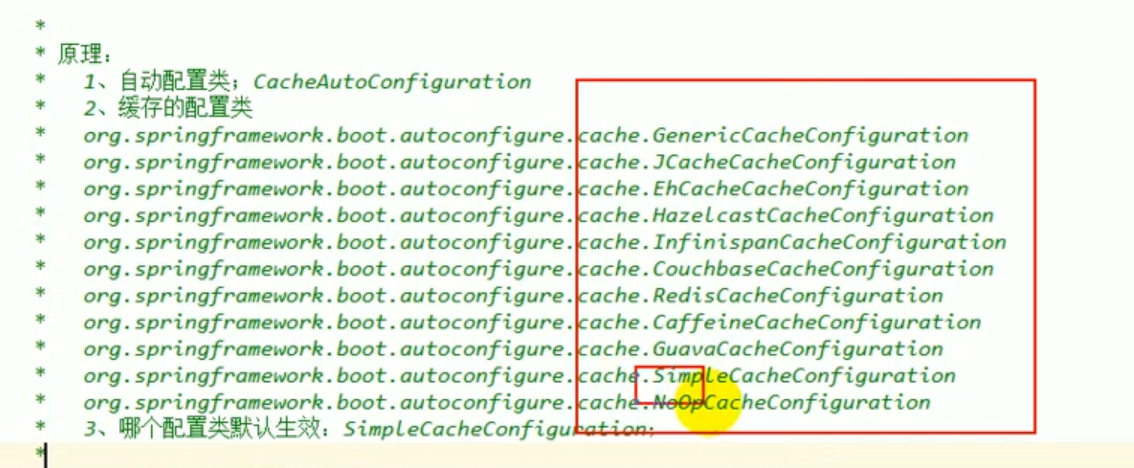
La configuration de départ par défaut est : SimpleCacheConfiguration.
Quand les autres caches sont-ils activés ?
Nous pouvons rechercher ces classes de configuration avec ctrl+n, puis entrer et voir leurs conditions conditionnelles :
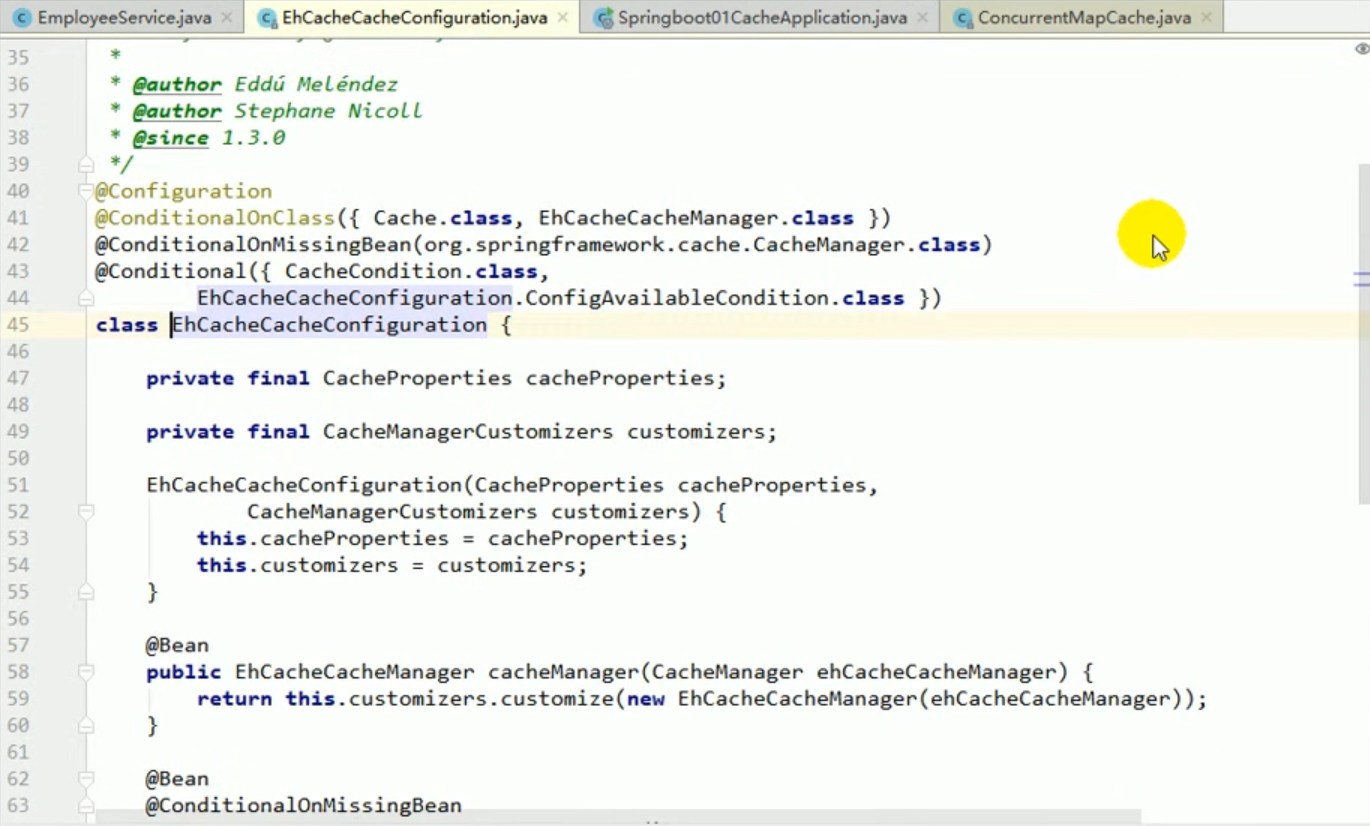
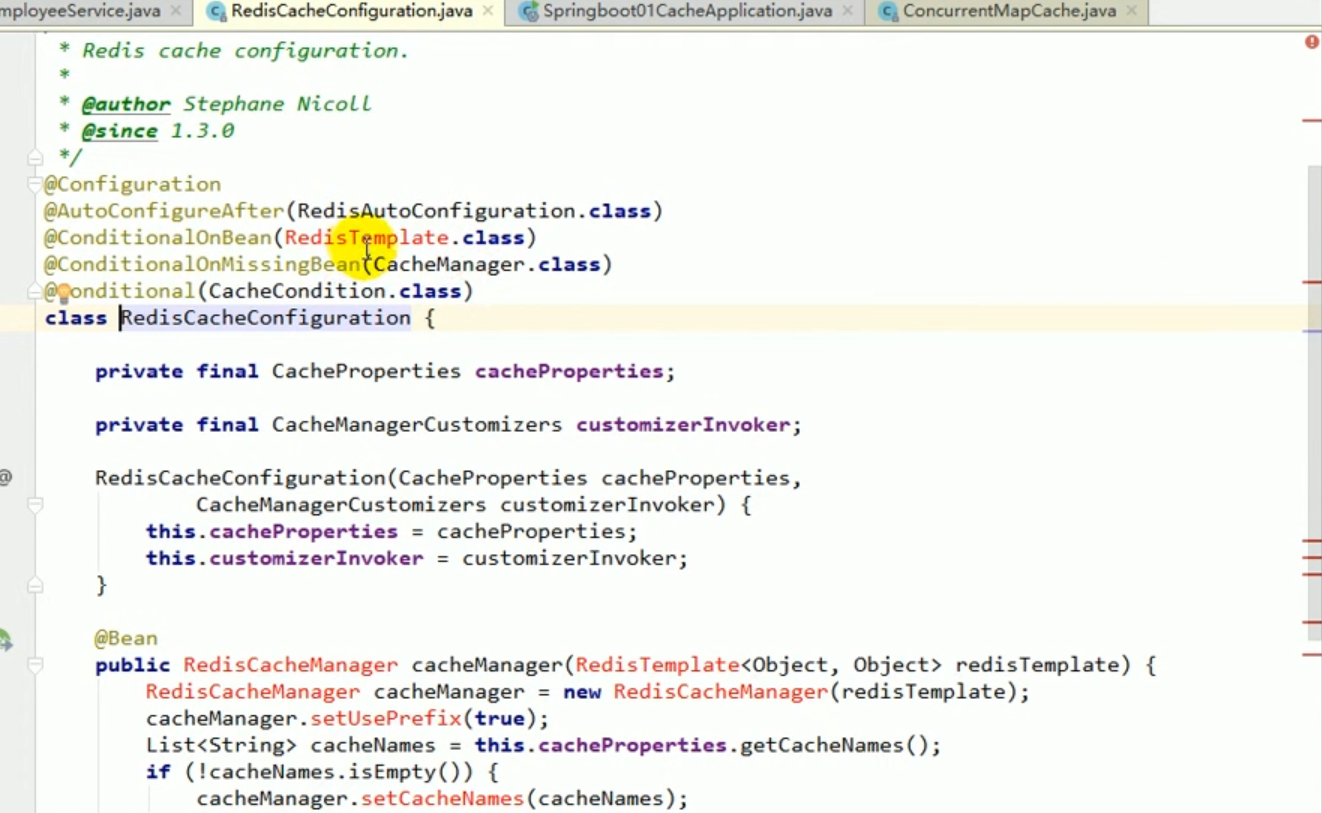
Cela signifie que ces configurations ne fonctionneront que lorsque vous importerez le package correspondant. efficace.
Intégrer Redis comme cache
S'il y a des étudiants qui ne connaissent pas la technologie Redis, il existe une vidéo explicative de la série Redis publiée par le professeur Zhou Yang de Shang Silicon Valley. Ou vous pouvez visiter le site officiel de Redis le plus rapidement possible pour apprendre que redis.cn est le site Web chinois pour l'apprentissage de Redis.
Installer redis
Rechercher l'image redis
Ceci est connecté à un entrepôt étranger et la vitesse est relativement lente.
Nous vous recommandons d'utiliser Docker Chine.
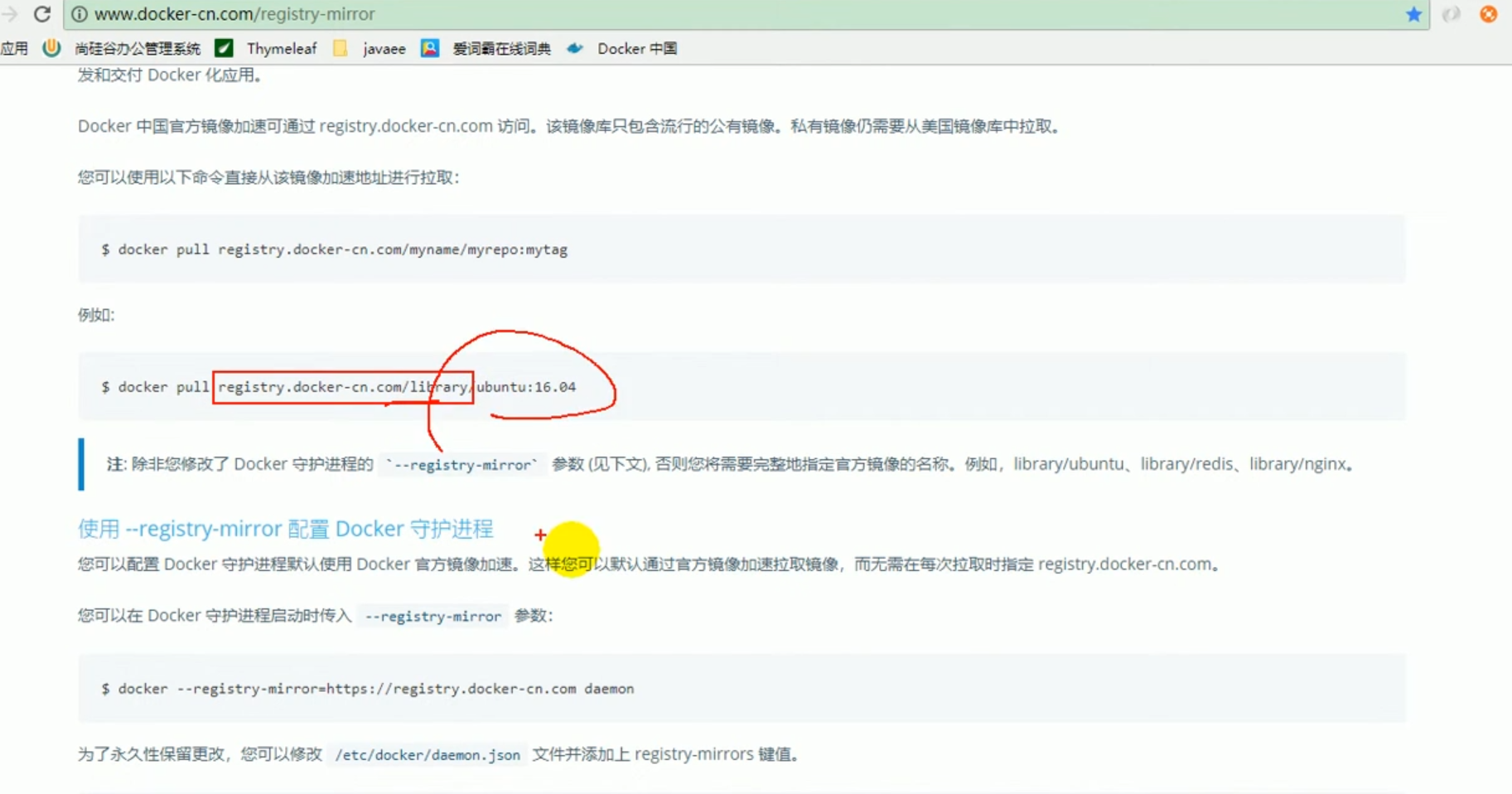
docker pull Registry.docker-cn.com/library/redis
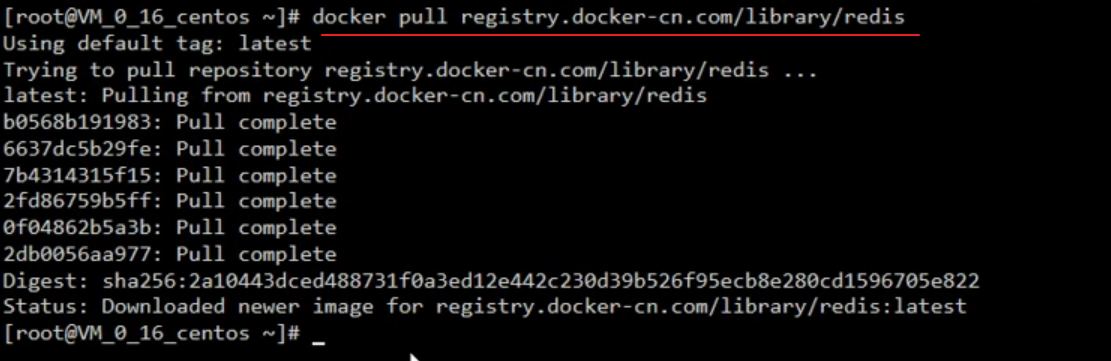

Démarrez l'image Redis
docker run -d -p 6379:6379 --name myredis [REPOSITORY] docker ps
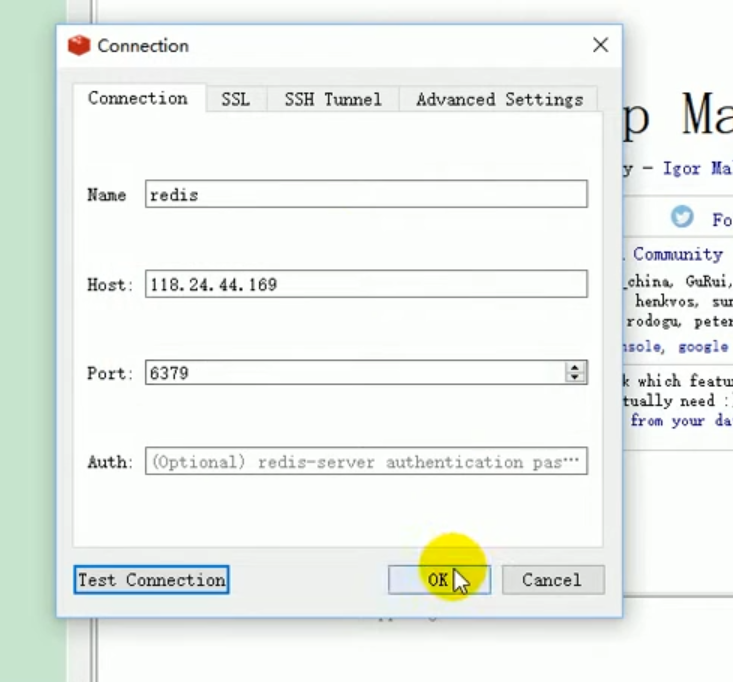
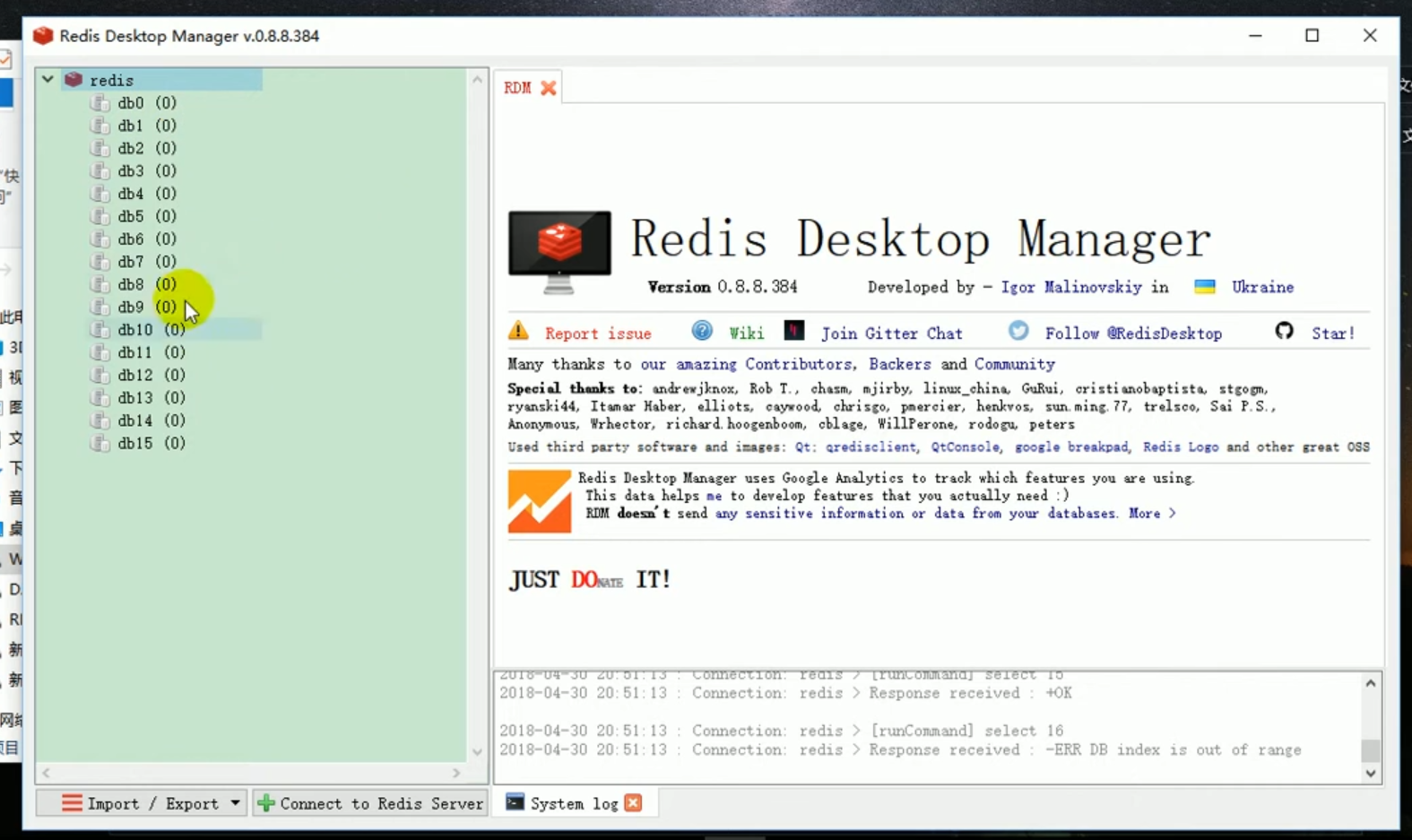
Pour tester, ouvrez l'outil de connexion Redis. Gestionnaire de bureau Redis
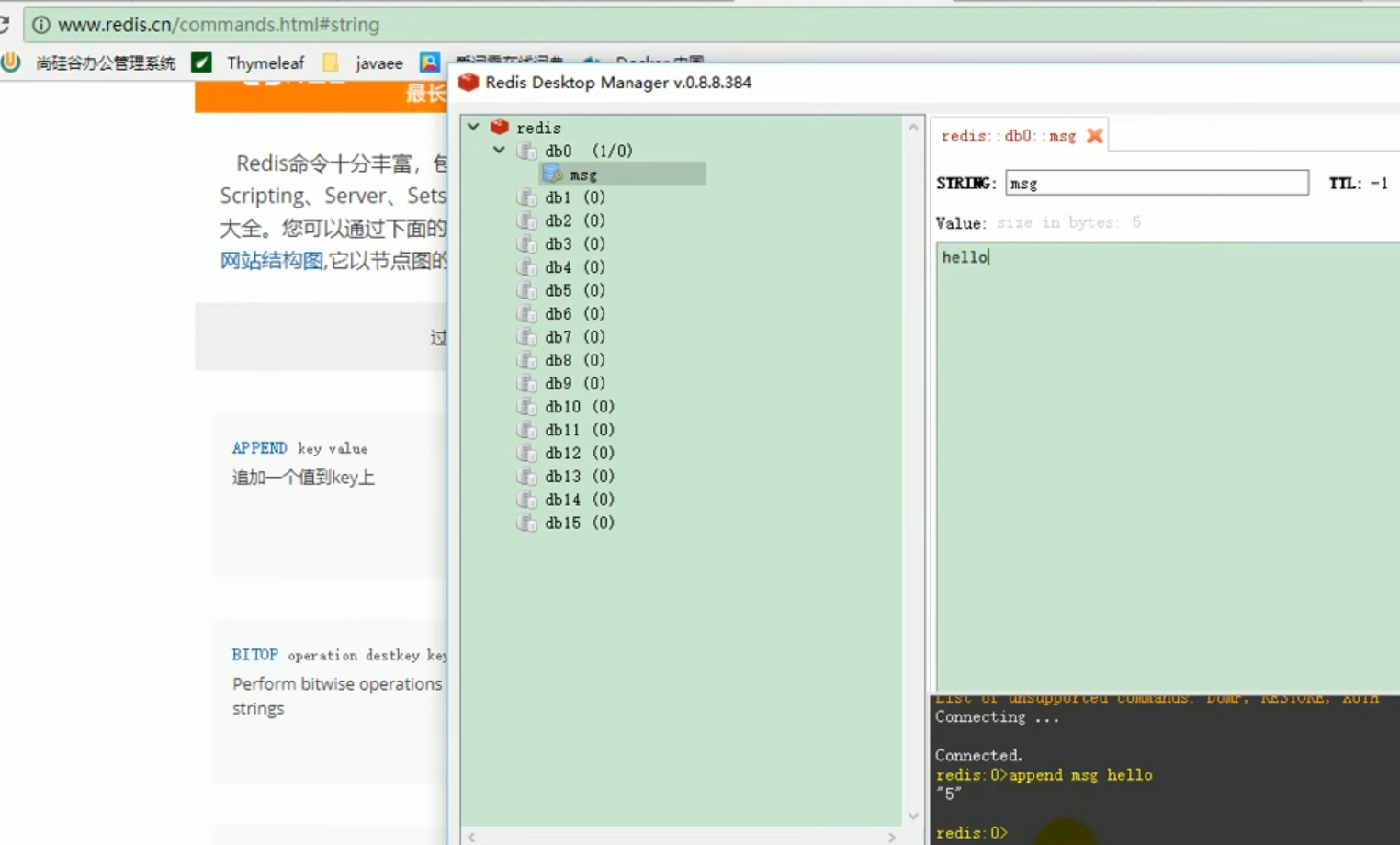
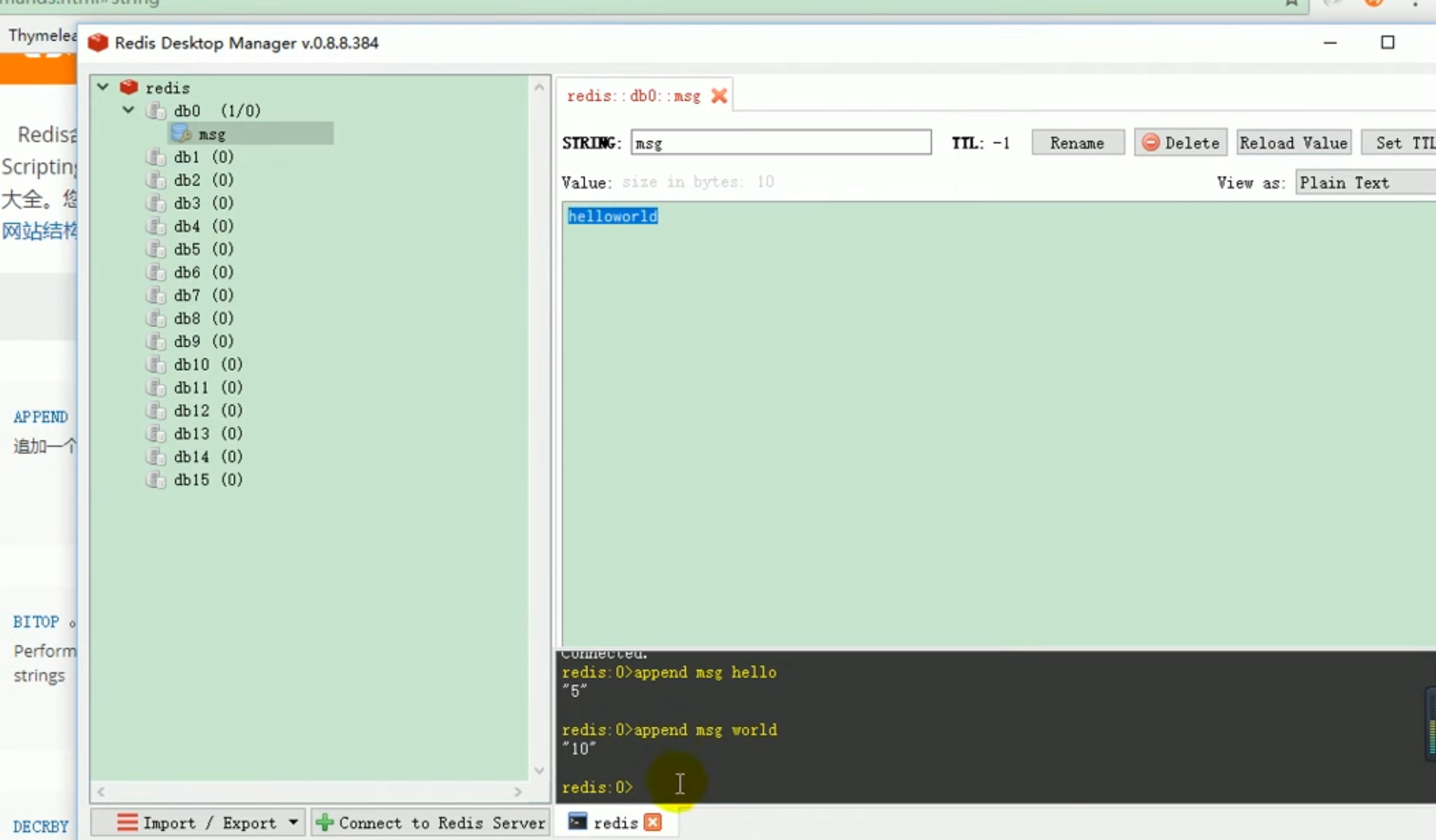
liste des opérations redis
 Présentation de Redis Starter
Présentation de Redis Starter
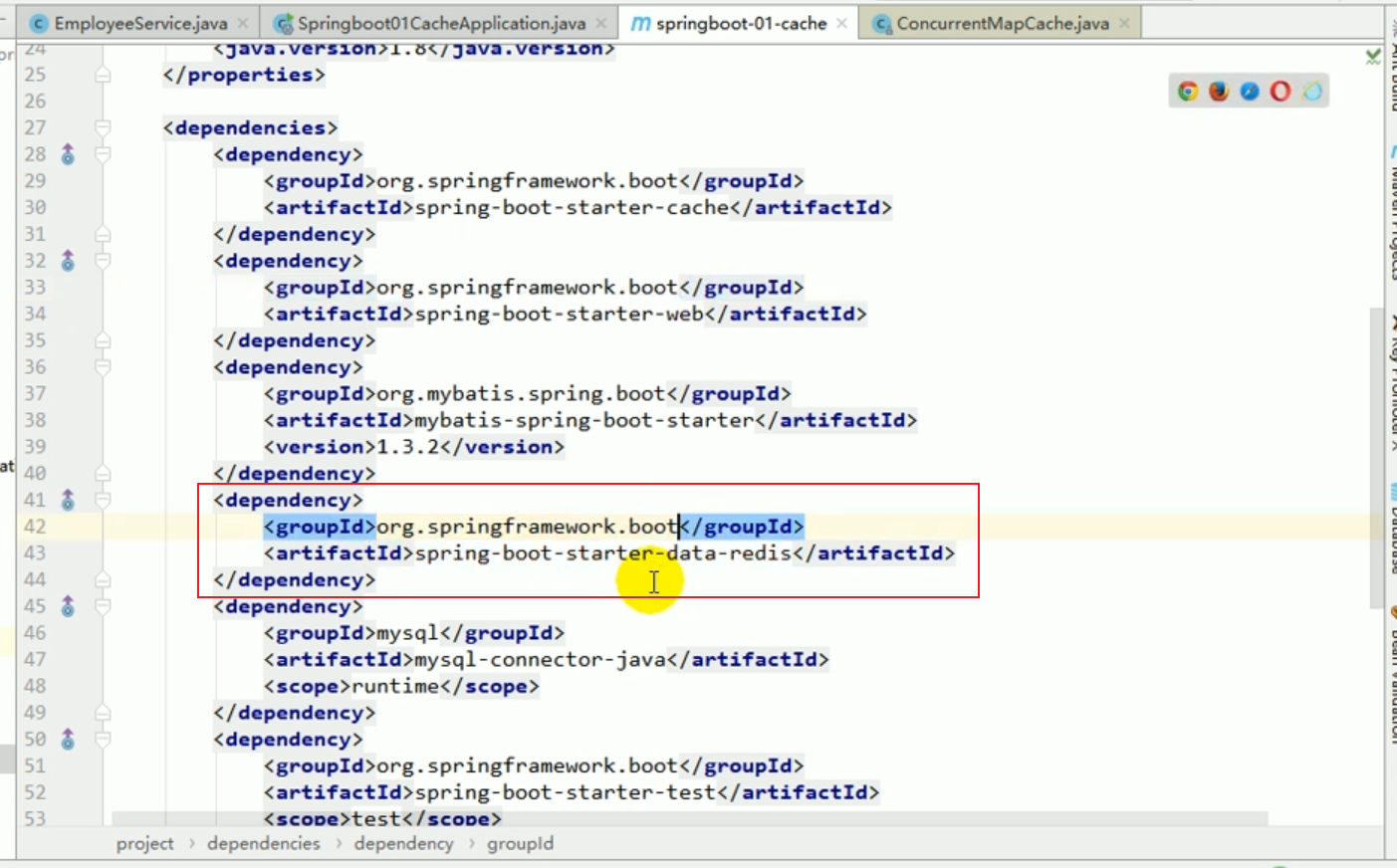
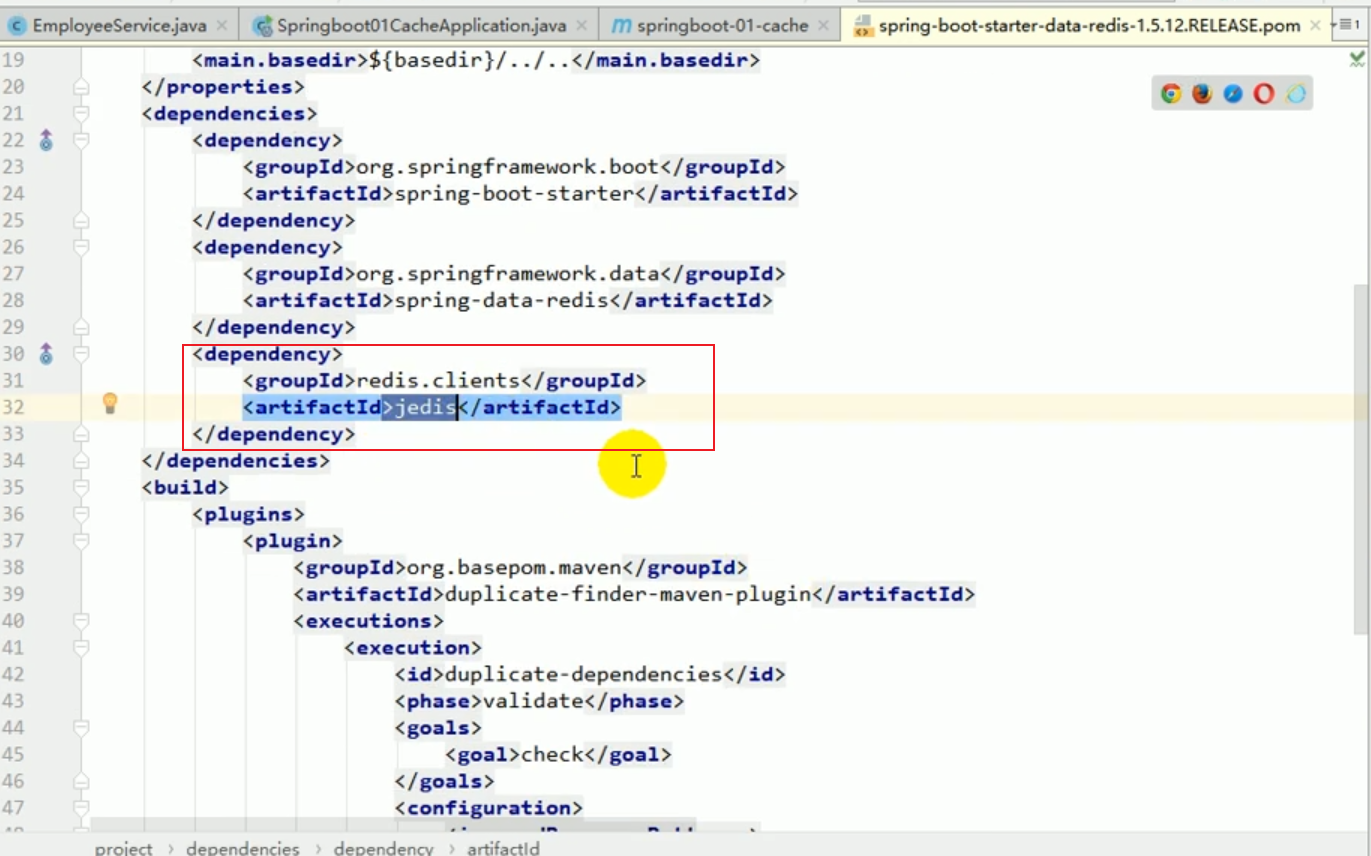
Configurer redis
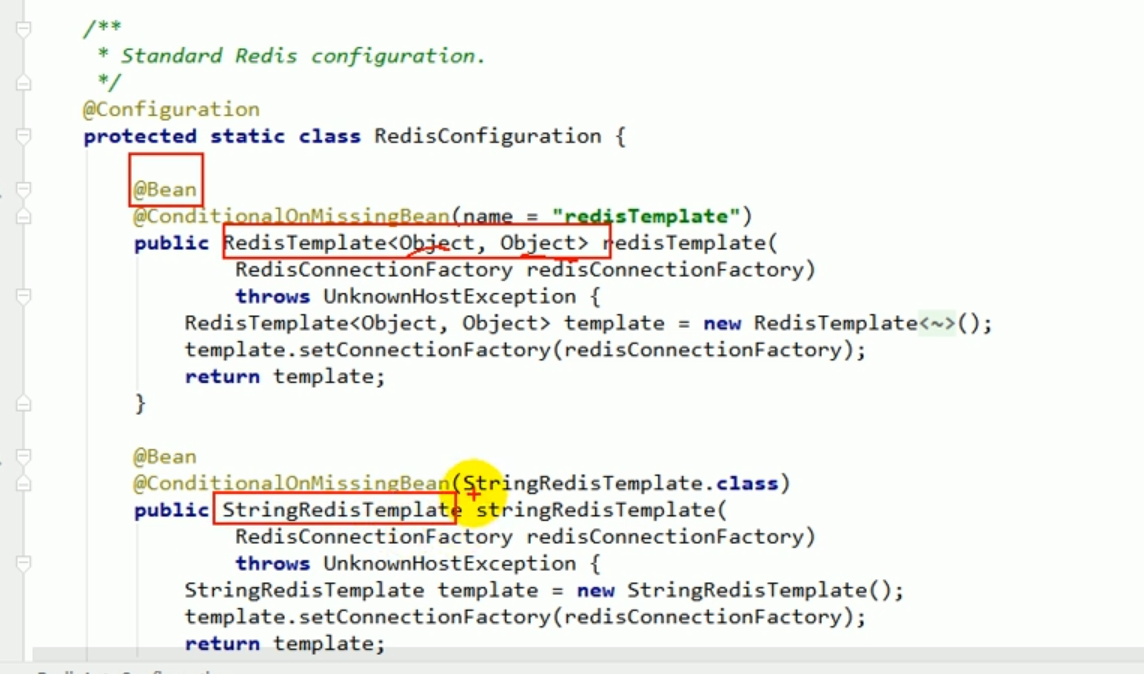 #🎜 🎜# Ajouter composants au conteneur, l'un s'appelle RedisTemplate et l'autre s'appelle StringRedisTemplate, deux choses.
#🎜 🎜# Ajouter composants au conteneur, l'un s'appelle RedisTemplate et l'autre s'appelle StringRedisTemplate, deux choses.
Ces deux choses sont utilisées pour faire fonctionner Redis.
C'est le même que le jdbcTemplate que tout le monde utilisait auparavant, utilisé pour faire fonctionner la base de données.
Ce sont les deux modèles que Spring utilise pour simplifier le fonctionnement de Redis. Si vous souhaitez utiliser ces deux éléments dans le programme, injectez-les simplement automatiquement. # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # redis test # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # #
redis liste des opérations :
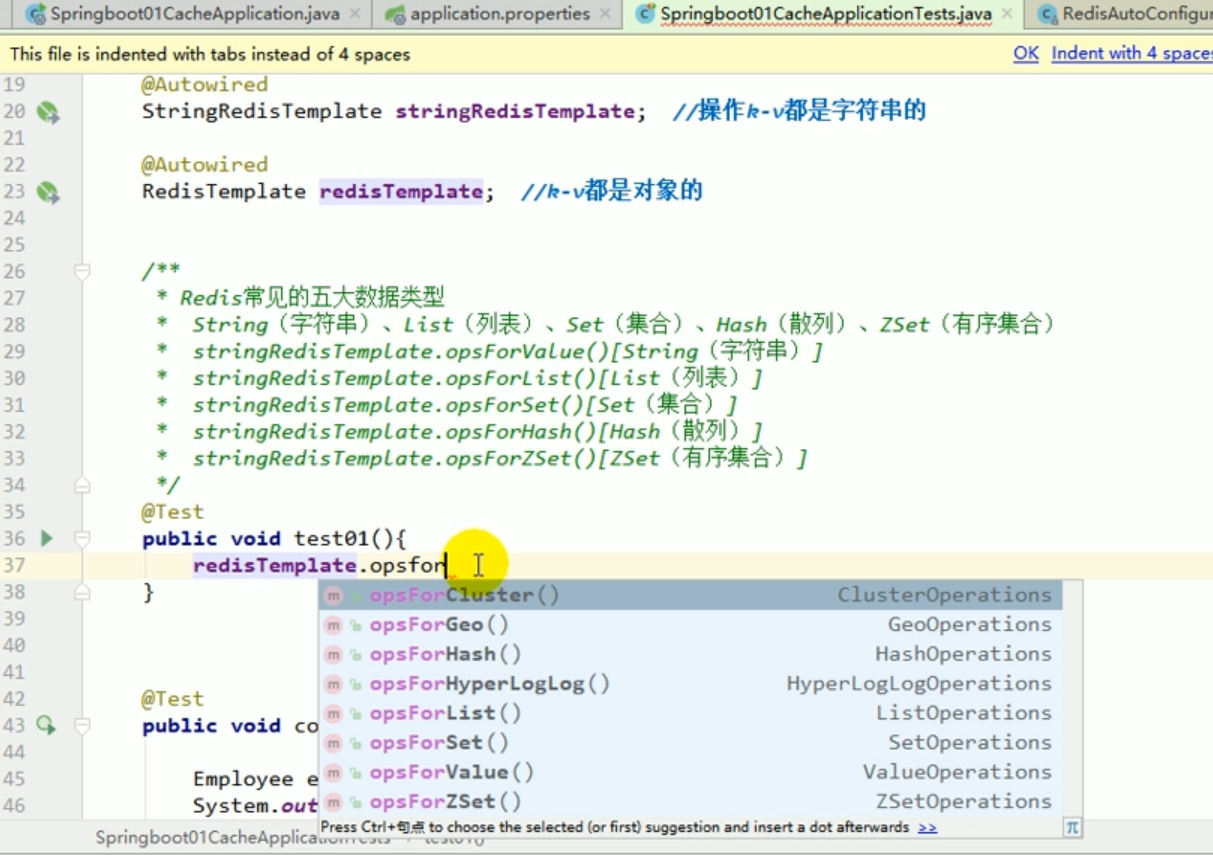
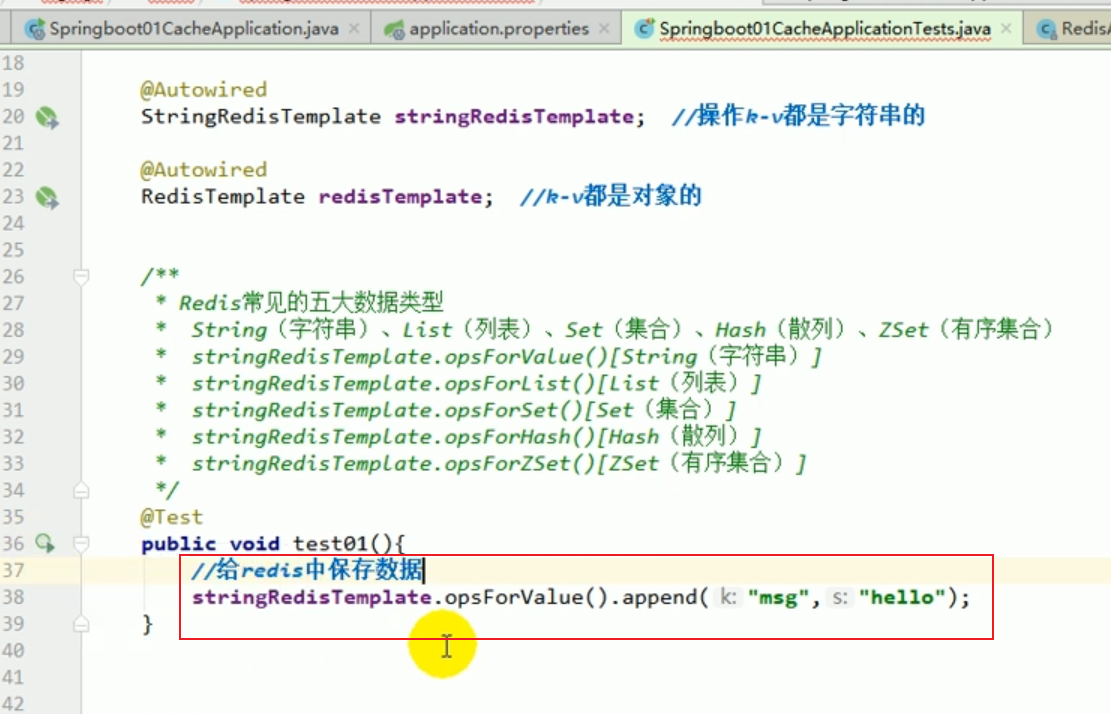
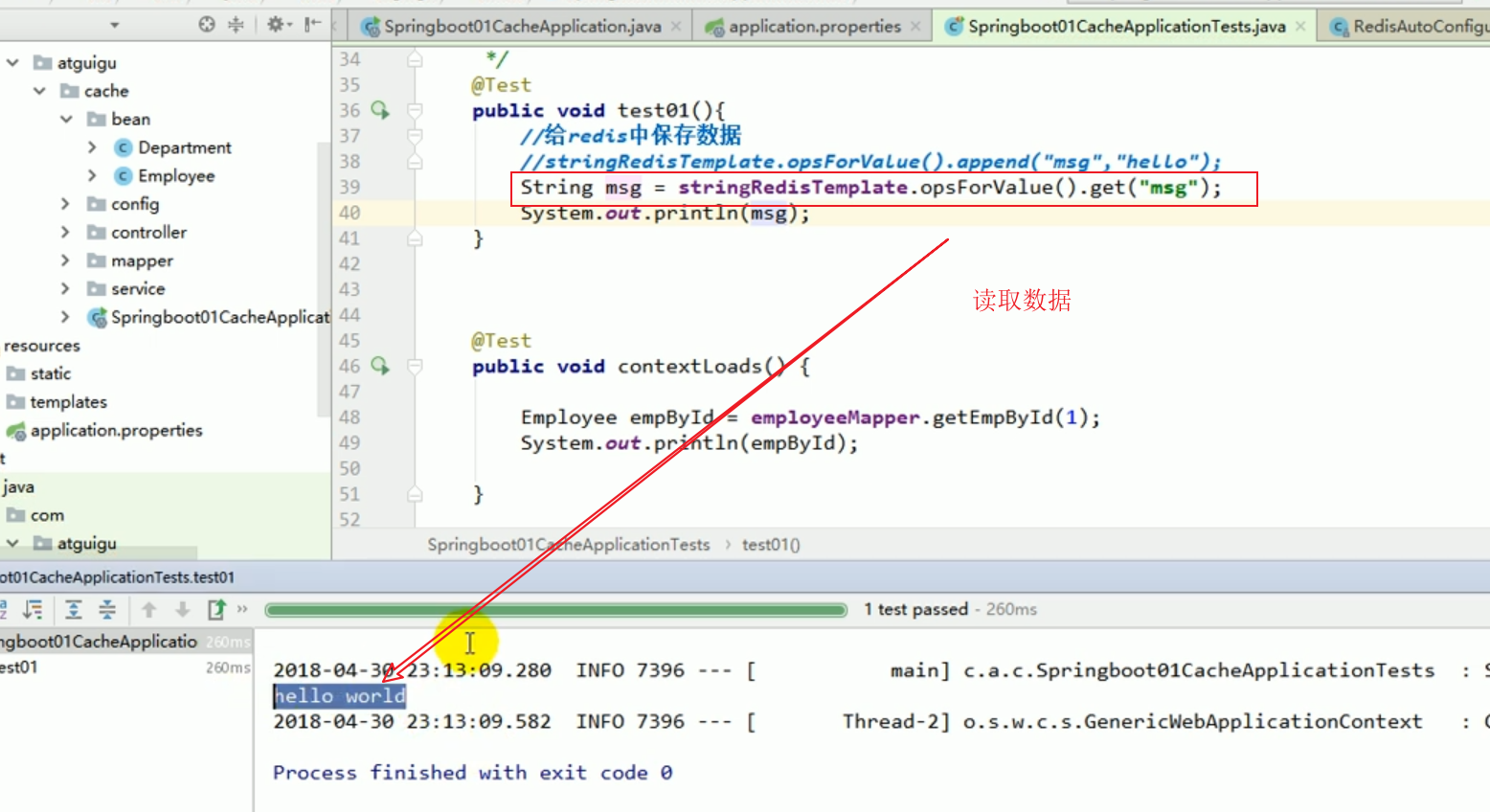
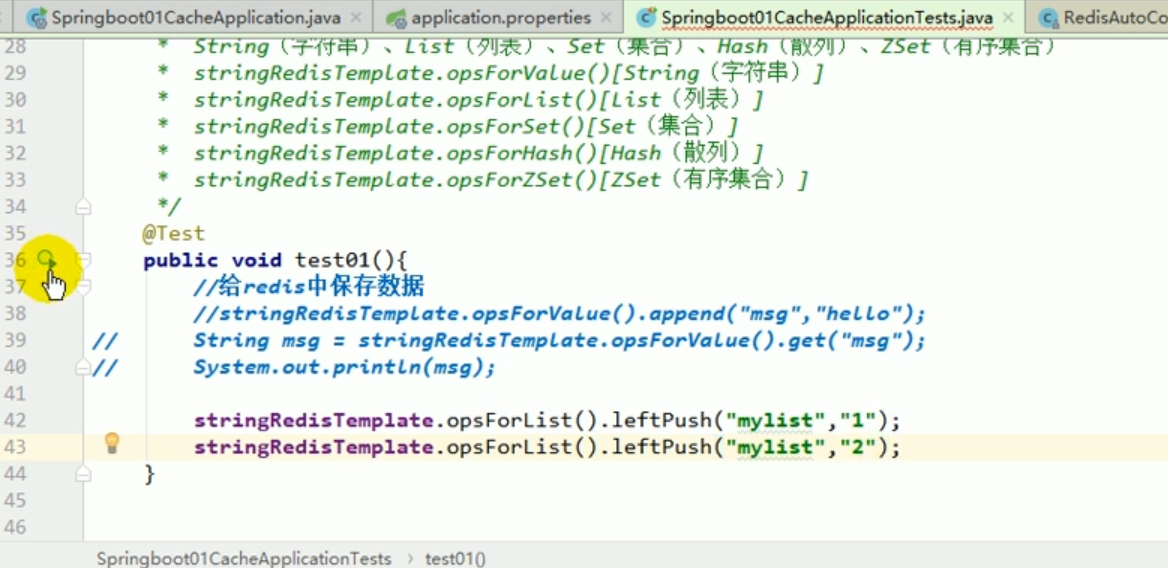
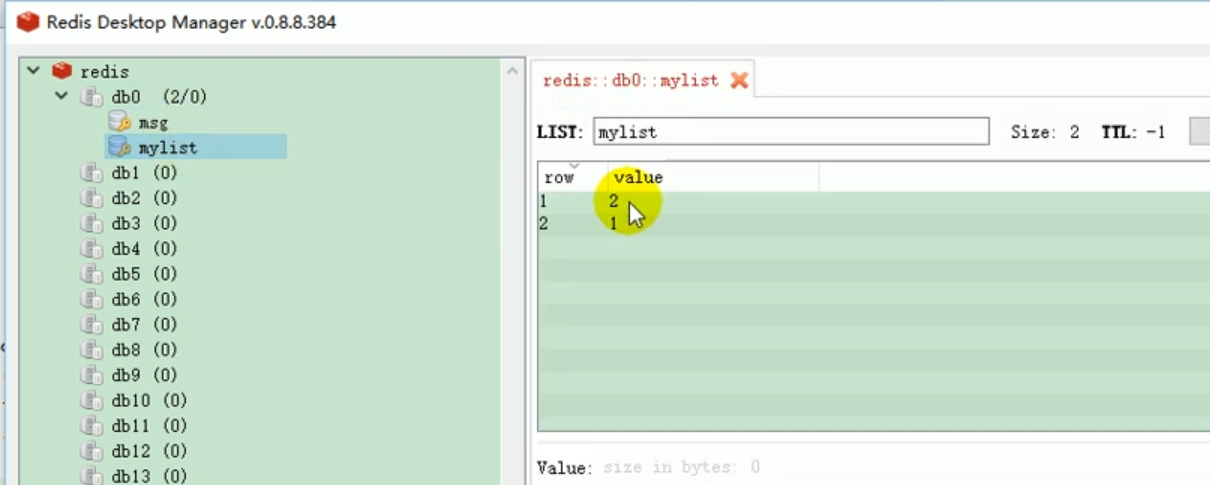
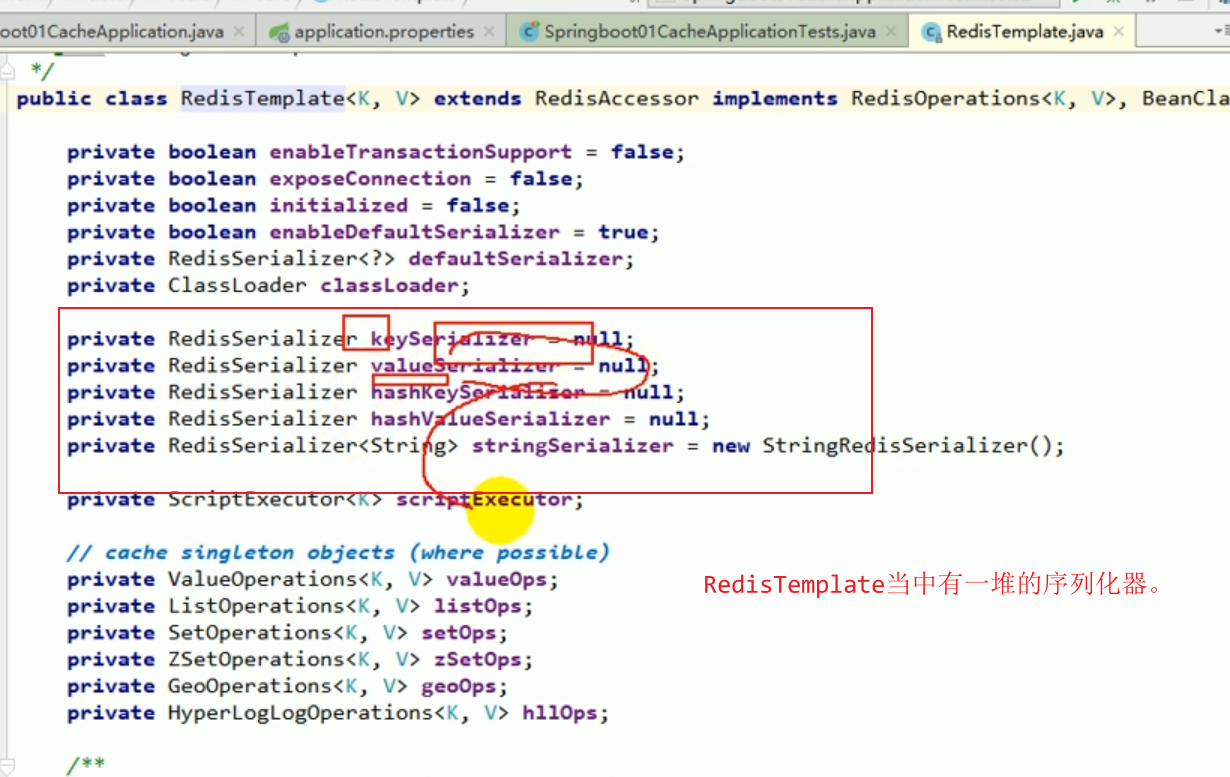
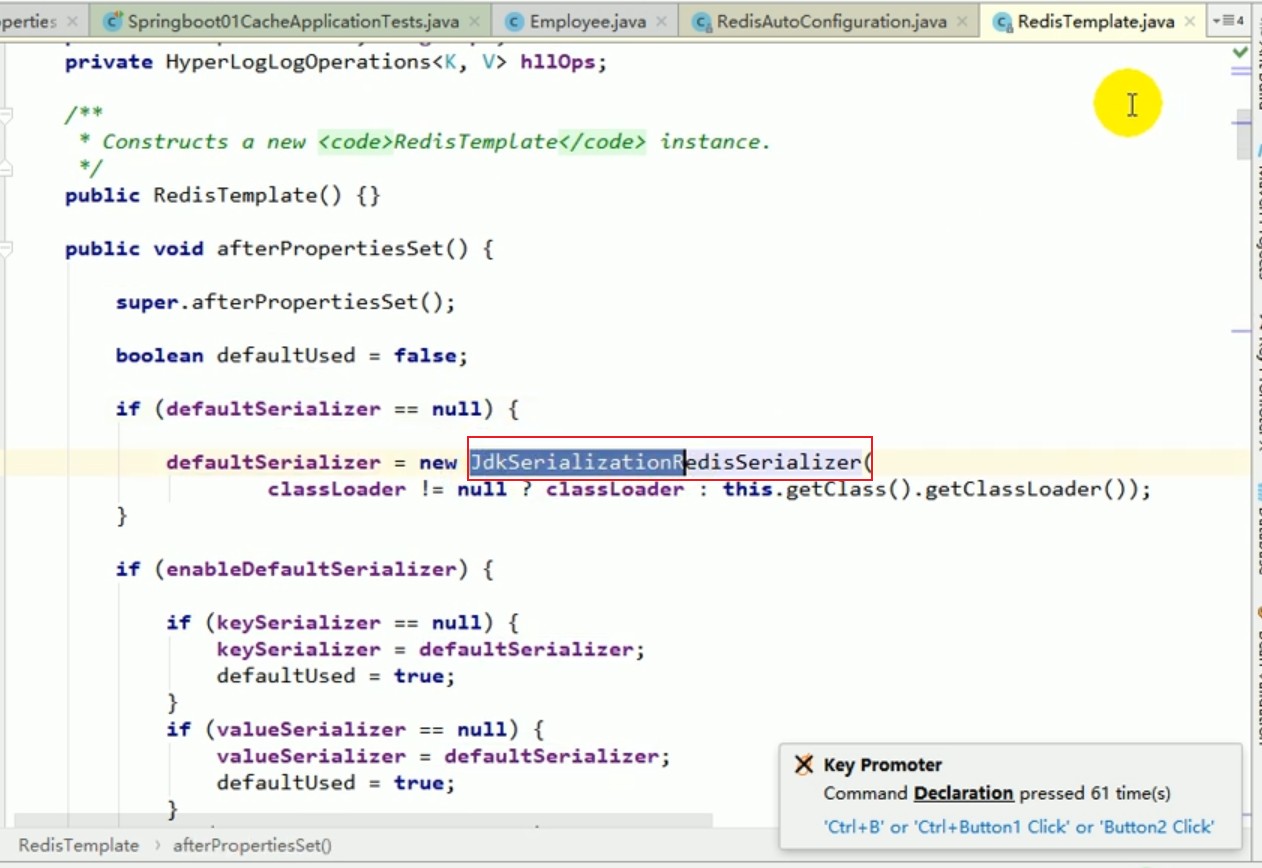
Ces choses incompréhensibles sont toutes le résultat de la sérialisation . # 🎜🎜 ## 🎜🎜 # Règles de sérialisation par défaut Redemplate # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # # 🎜 🎜#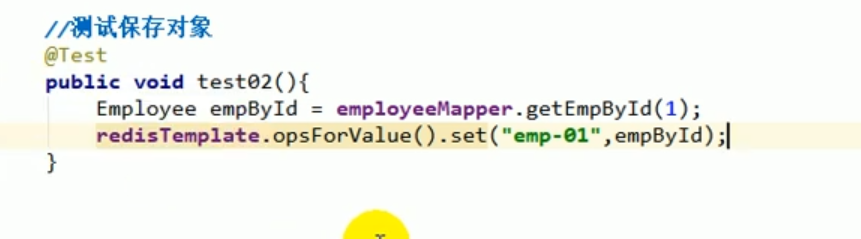 Le sérialiseur par défaut est le JdkSerializationRedisSerializer utilisé.
Le sérialiseur par défaut est le JdkSerializationRedisSerializer utilisé.
Le sérialiseur par défaut est le sérialiseur JDK utilisé. 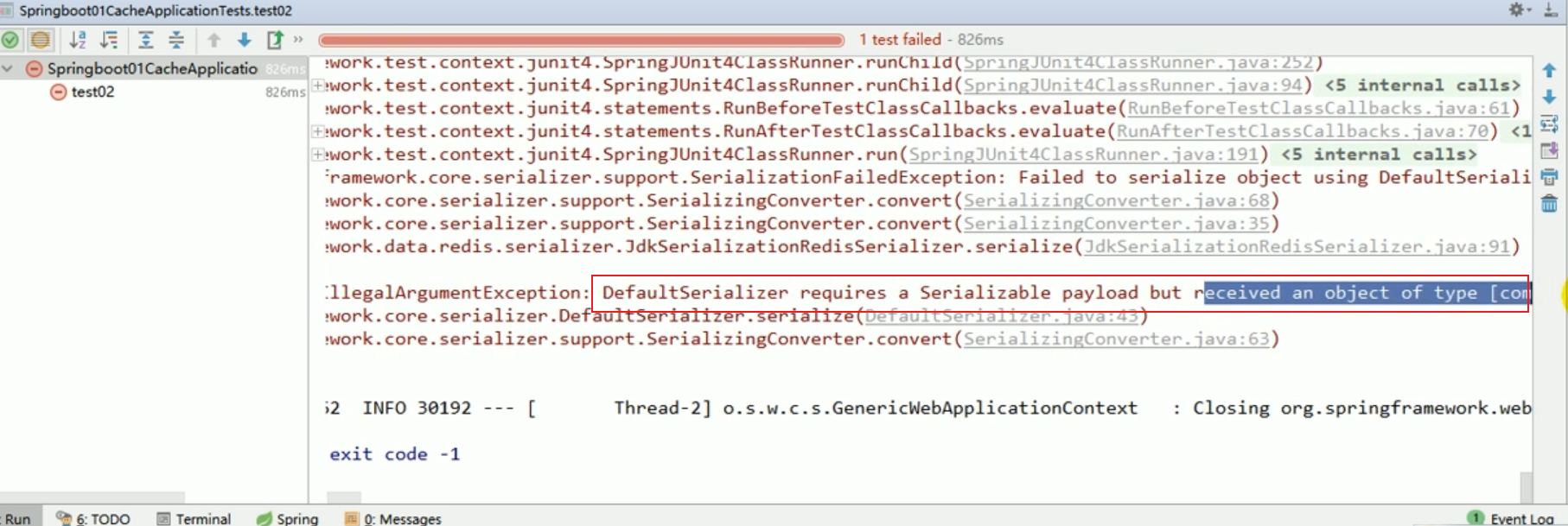
 redis configuration
redis configuration
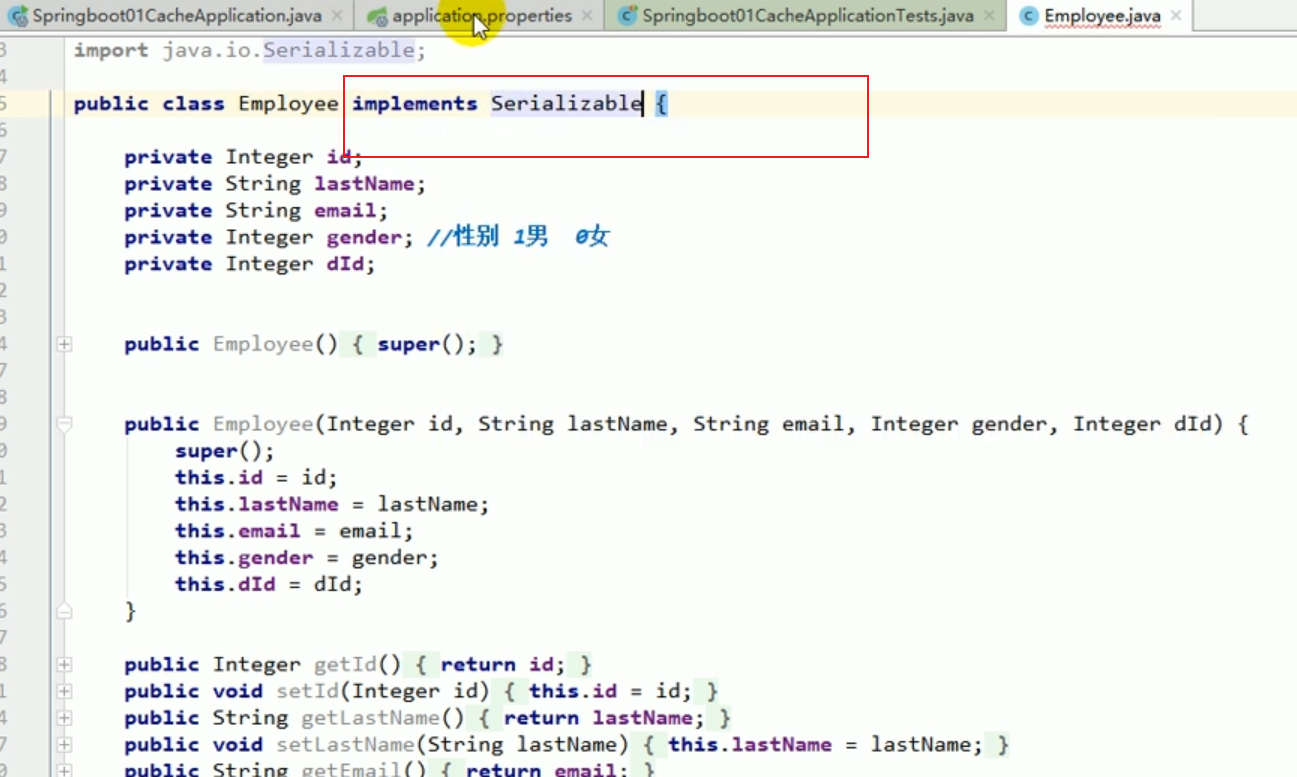
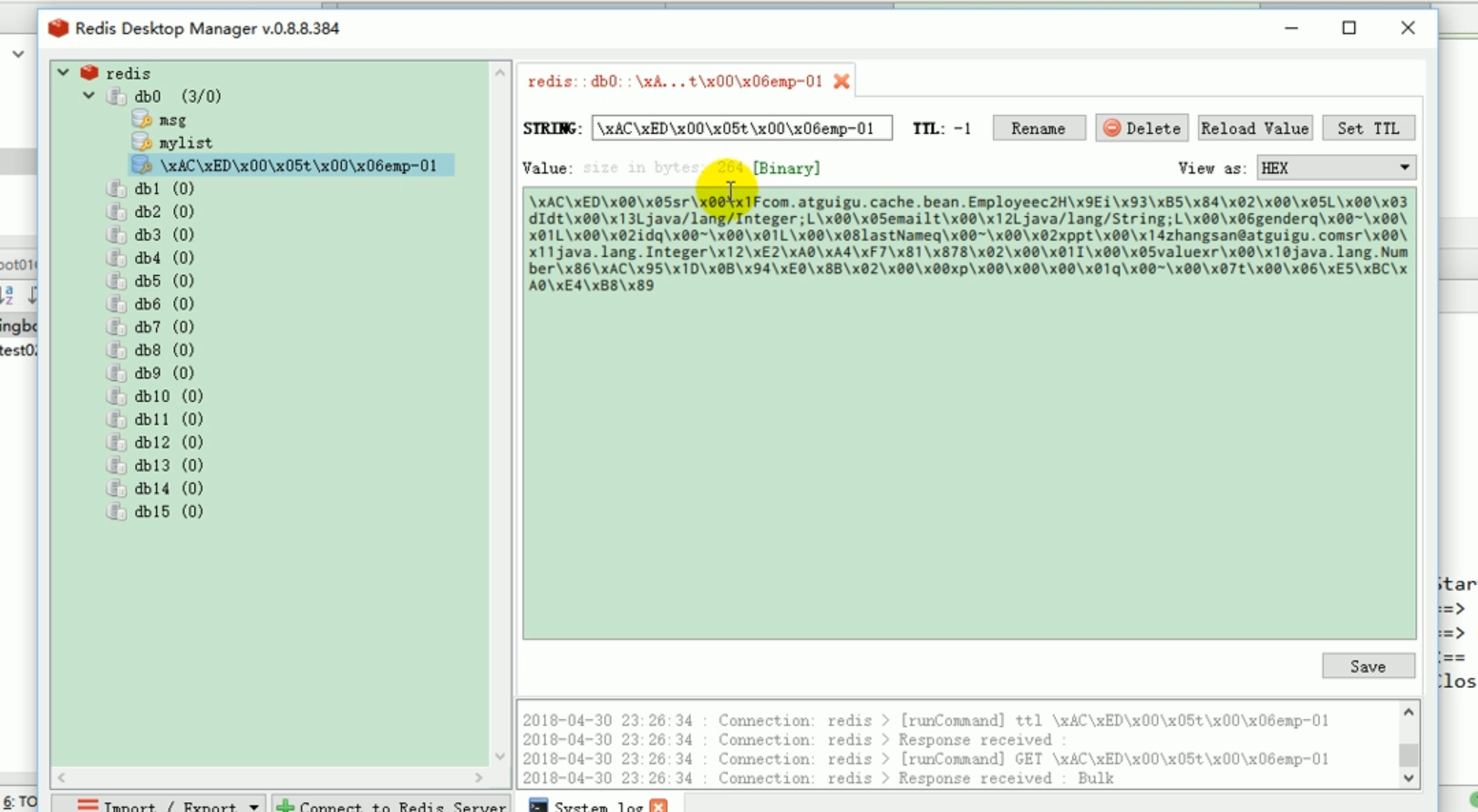
Dans la classe de test, nous sommes automatiquement injecté Configurez votre propre redisTemplate.
 Puis on teste à nouveau la sauvegarde de l'objet.
Puis on teste à nouveau la sauvegarde de l'objet.
Cela montre que notre modification du sérialiseur a réussi.
Cela montre clairement que si nous voulons enregistrer l'objet plus tard, nous devons souvent modifier le sérialiseur.
Tester le cache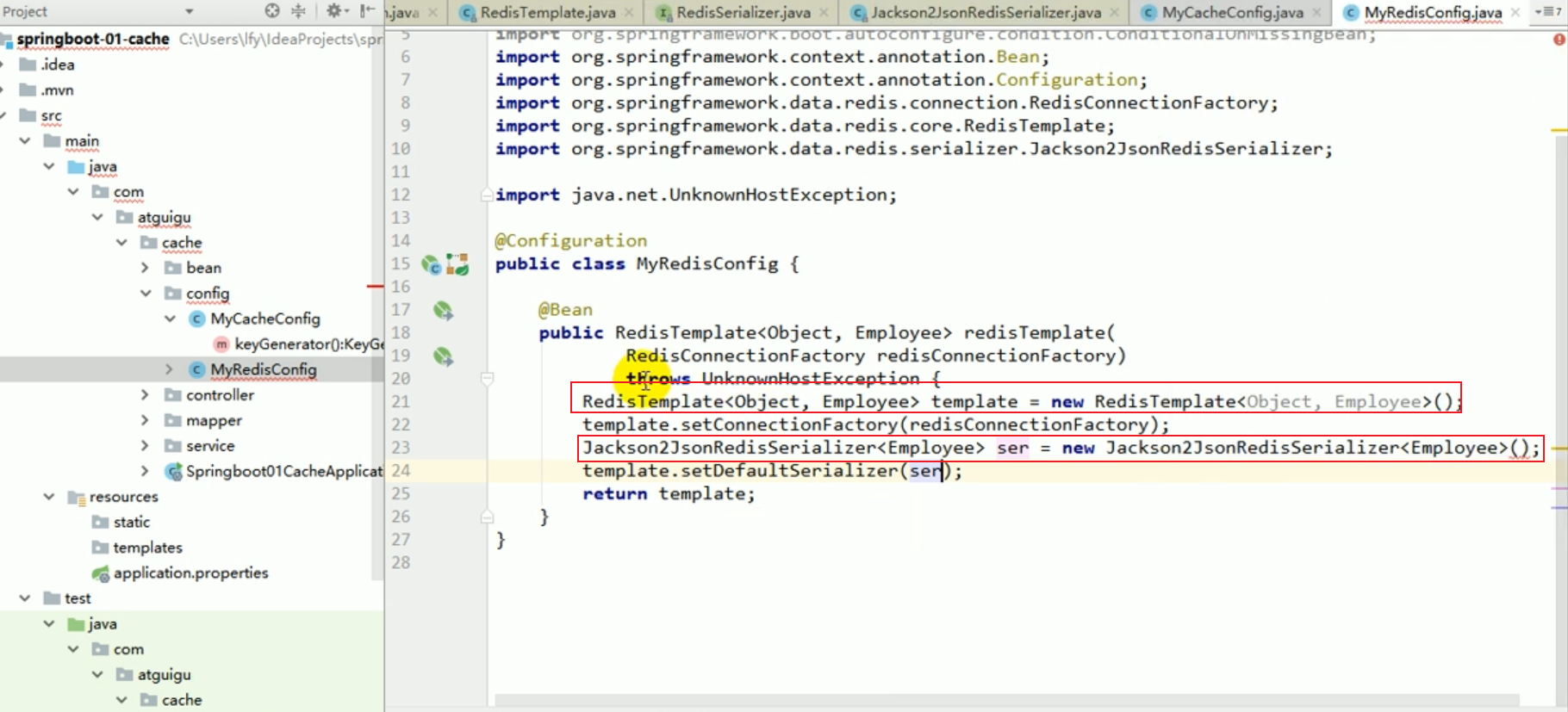
Nous avons déjà utilisé le gestionnaire de cache de ConCurrentMap.
Ce gestionnaire de cache nous aide à créer des composants de cache.
Le composant cache est utilisé pour mettre en cache et effectuer un travail CRUD.
Maintenant que nous avons introduit Redis, que va-t-il se passer ?
Nous définissons toujours debug=true dans application.properties afin que le rapport de configuration automatique puisse être activé.
A ce moment, nous redémarrons notre programme et recherchons dans la console.
Voyons quelle classe de configuration automatique est efficace ?
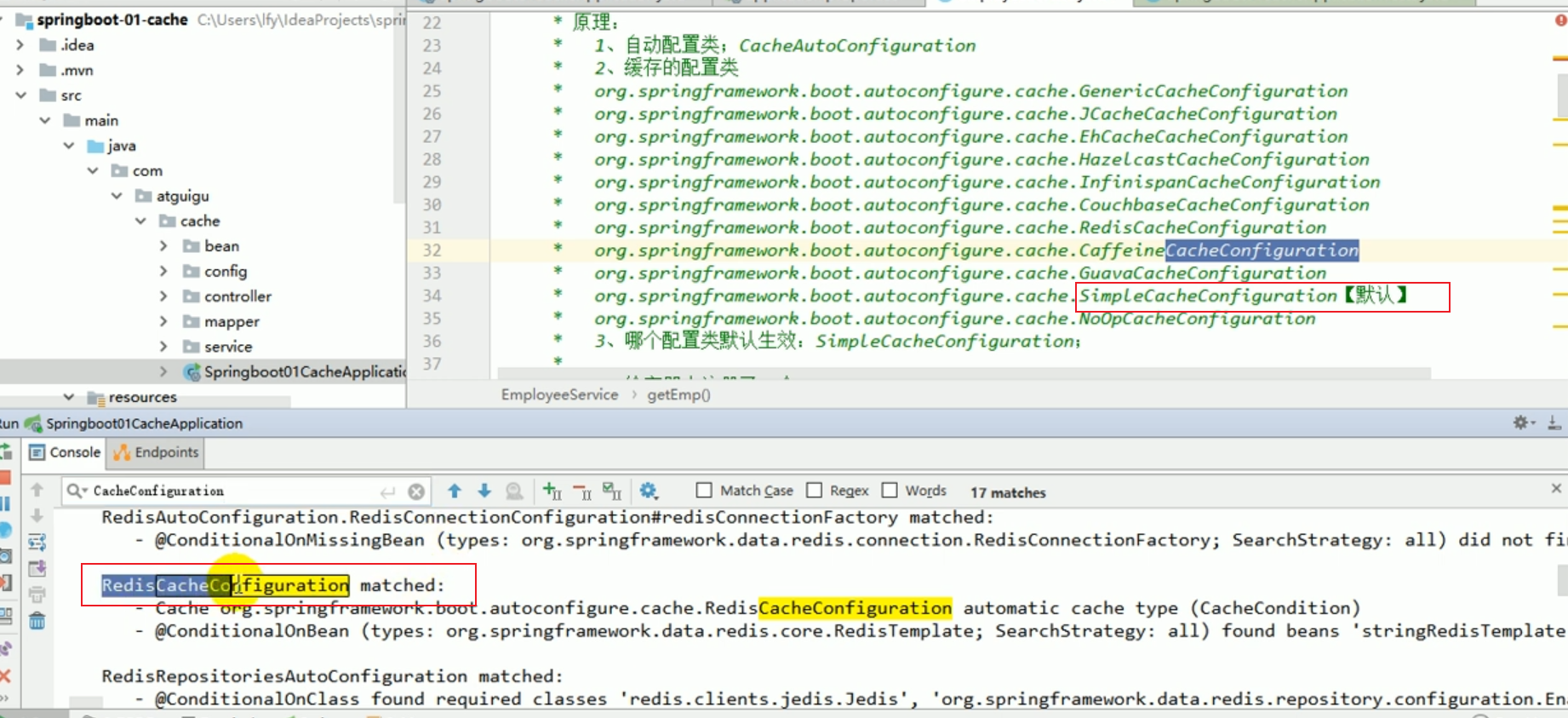
La valeur par défaut d'origine est : SimpleCacheConfiguration.
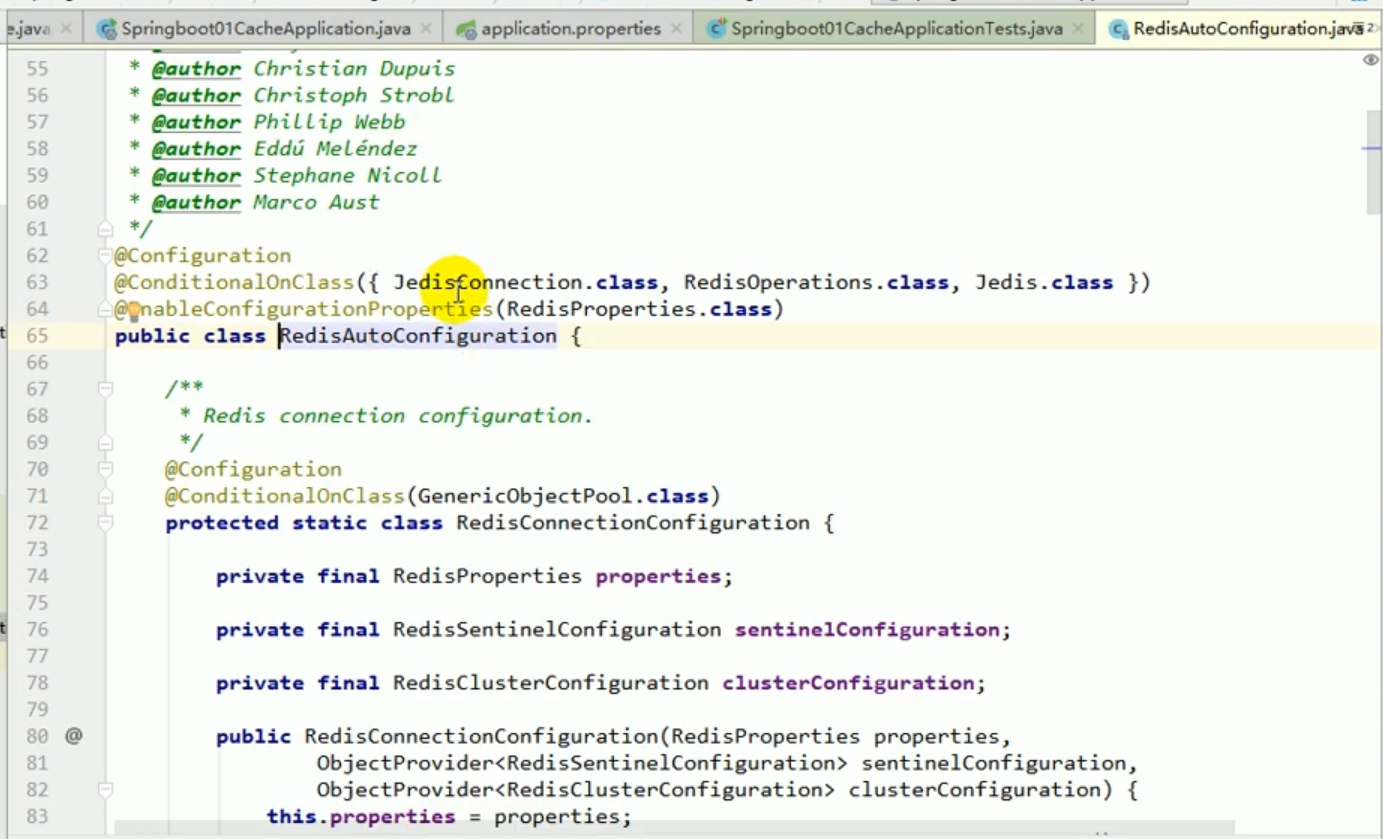
Maintenant que nous avons introduit les démarreurs liés à Redis, le programme active RedisCacheConfiguration par défaut.

Démarrez simplement le programme et testez-le directement.
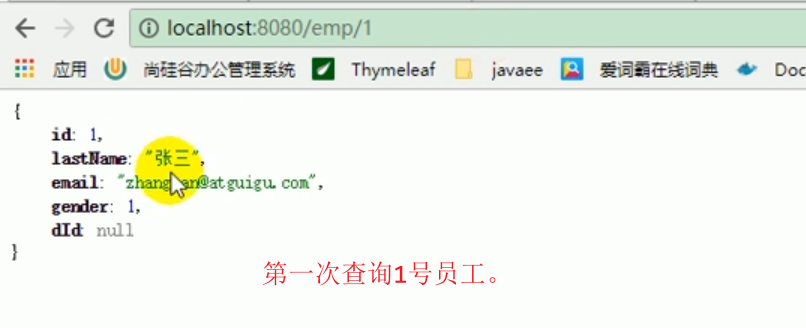

Cela signifie que lorsque vous interrogez pour la première fois, vous interrogez la base de données.
Lors de la deuxième interrogation, il n'y avait aucune sortie sur la console, indiquant que le cache avait été interrogé.
Le cache n'est activé que par Redis par défaut.
Alors il doit être en redis.
Nous pouvons le vérifier :
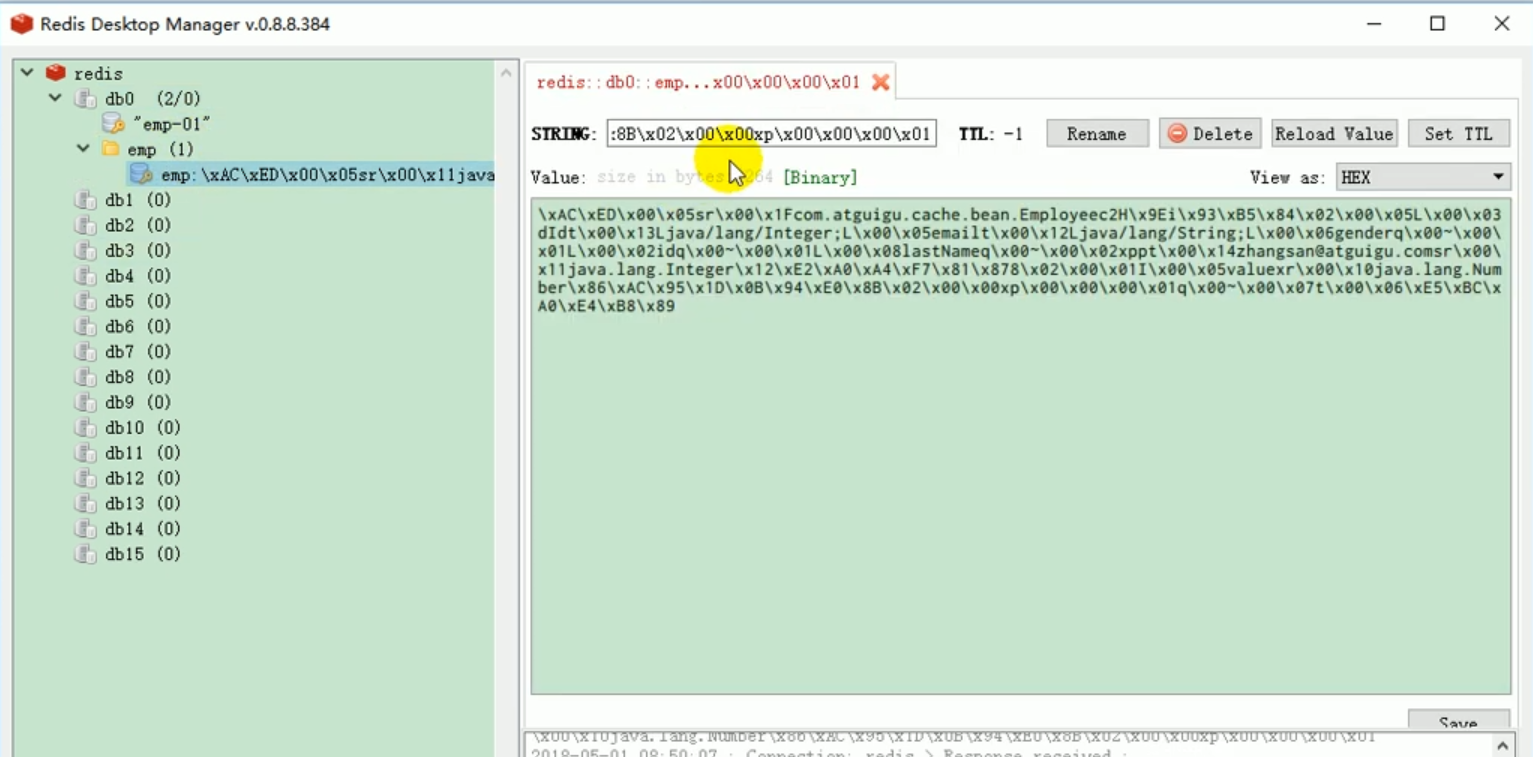
Cela illustre un problème lorsque k et v sont tous deux des objets, ils sont enregistrés. par défaut, les objets sont enregistrés à l'aide de la sérialisation. Nous voulons que Redis l'enregistre automatiquement au format JSON.
Que devons-nous faire ?
Analysons d’abord les principes de ces processus.
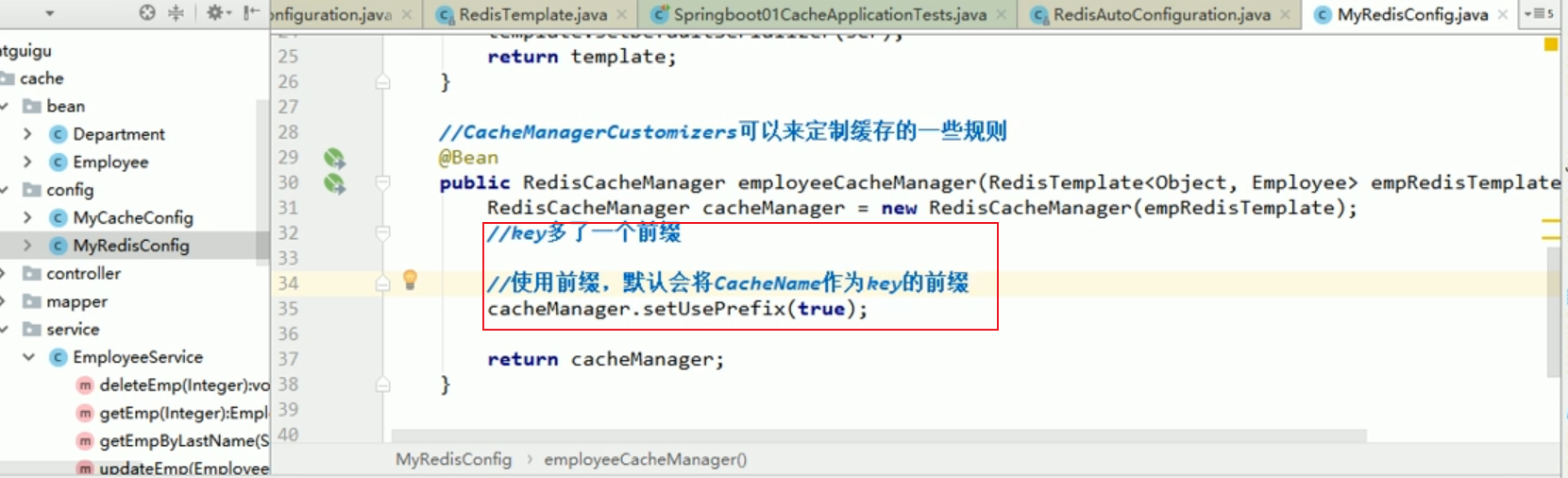
1. Nous avons introduit le starter de redis, donc notre cachemanager est devenu rediscachemanager,
2 Lorsque le rediscachemanager est créé par défaut et exploite nos données, il passe Inséré. une chose de remodelage.

3. Ce redistemplate a été créé pour nous par redisautoconfiguration. Le mécanisme de sérialisation par défaut utilisé par ce remodèle est jdkserializationredisserializer. Cela équivaut au fait que le redisCacheManager que redis nous empêche par défaut ne répond pas tout à fait à nos exigences.
Que devons-nous faire ?
Nous devrions personnaliser CacheManager.
RedisCacheManager personnalisé
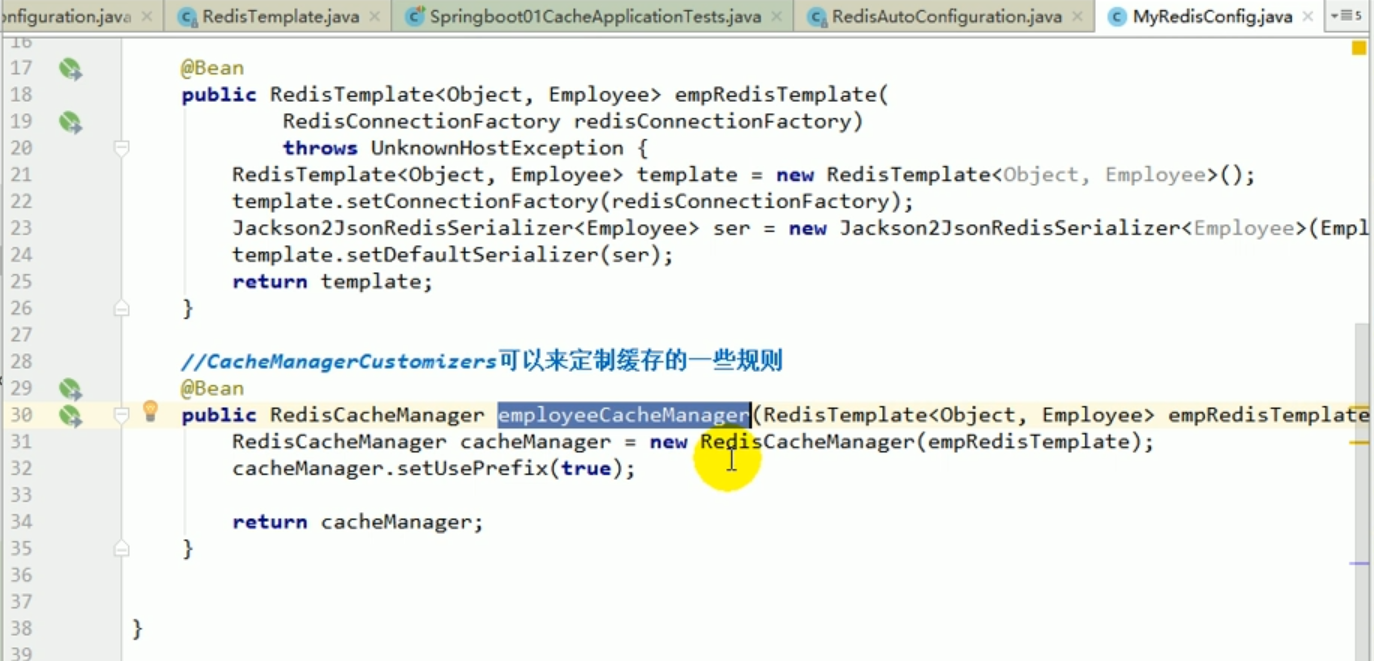
À ce moment, nous recommençons le projet pour les tests. À ce moment, nous pouvons voir Le. le résultat en redis est ce que nous voulons.
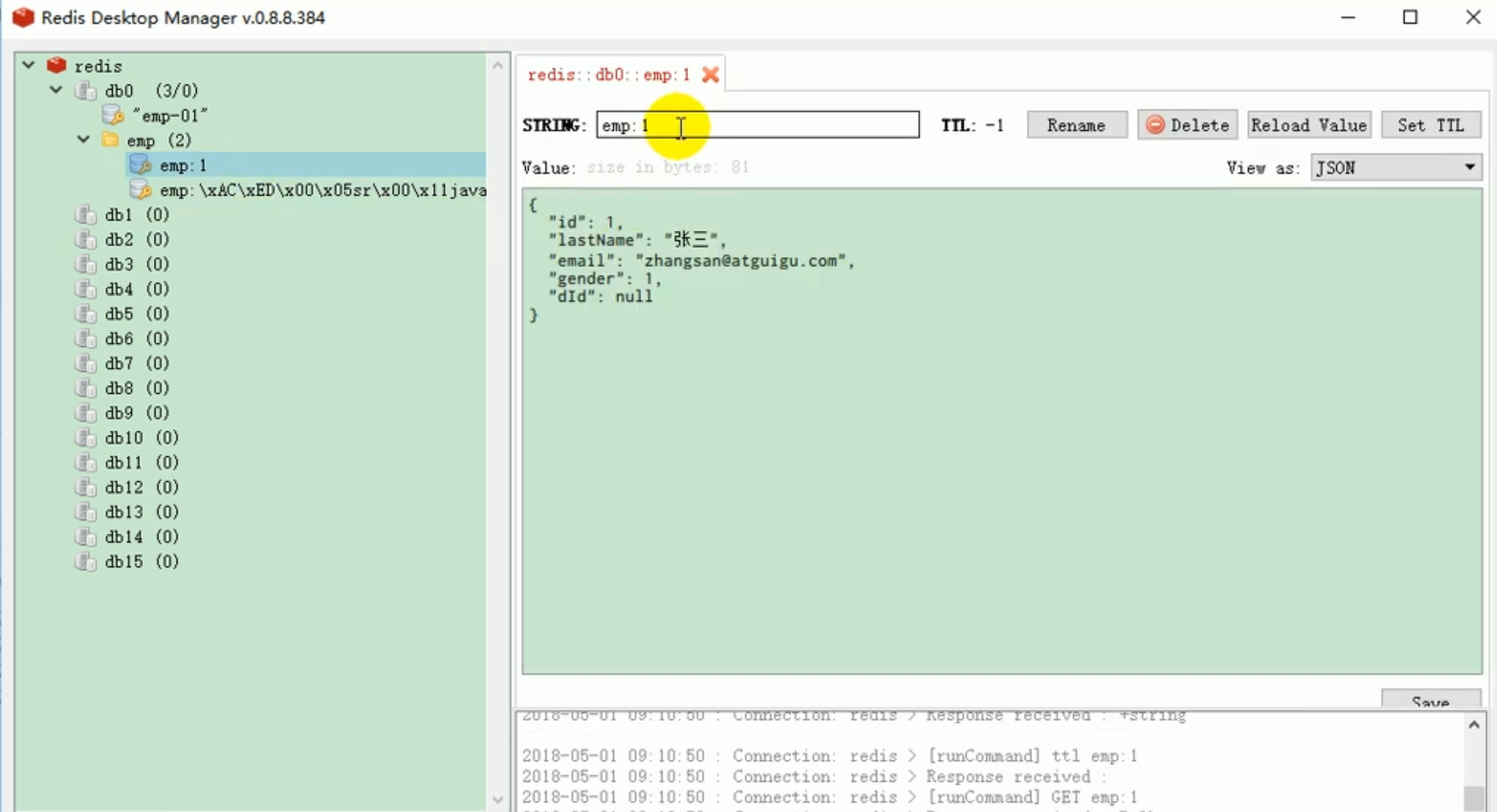
Lors de la prochaine interview, Yun Qiu pourra demander à ceux qui veulent venir au parc logiciel, connaissez-vous le starter redis ? Lors de l'enregistrement d'objets, quelles sont les règles de sérialisation par défaut de redisTemplate ?
Si nous souhaitons modifier les règles de sérialisation par défaut lors de l'utilisation de Redis, que devons-nous faire ?
Nous pouvons personnaliser redisCacheManager, puis personnaliser redisTemplate et transmettre le sérialiseur lié à json dans redisTemplate.
Petits problèmes restants
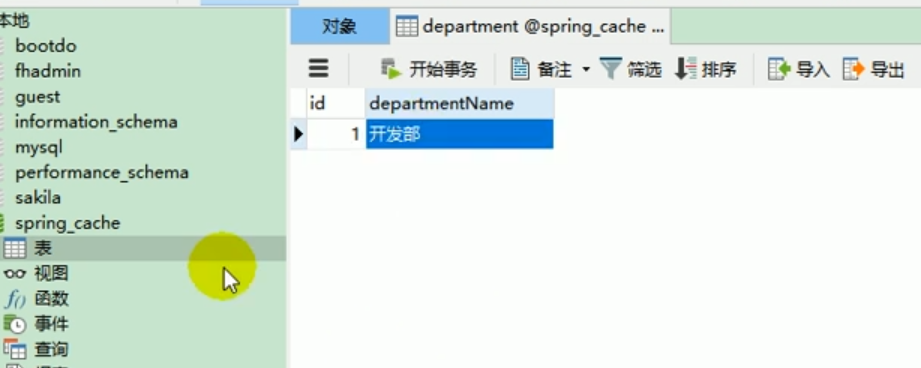
Base de données
Ce que nous avons dans la base de données , mettez une donnée dans la table du département :
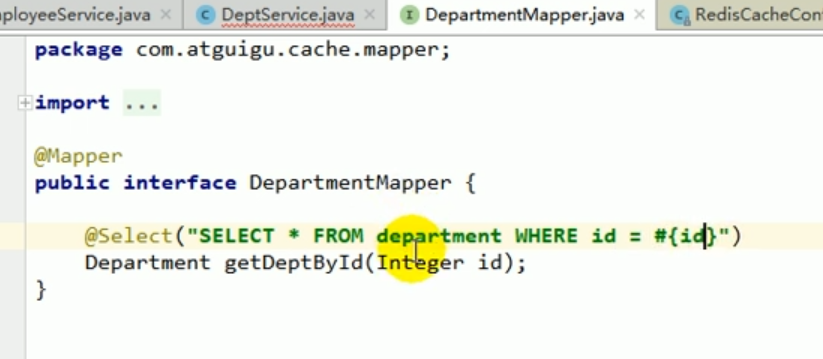
mapper
Nous écrivons un mapper correspondant au fonctionnement du département.
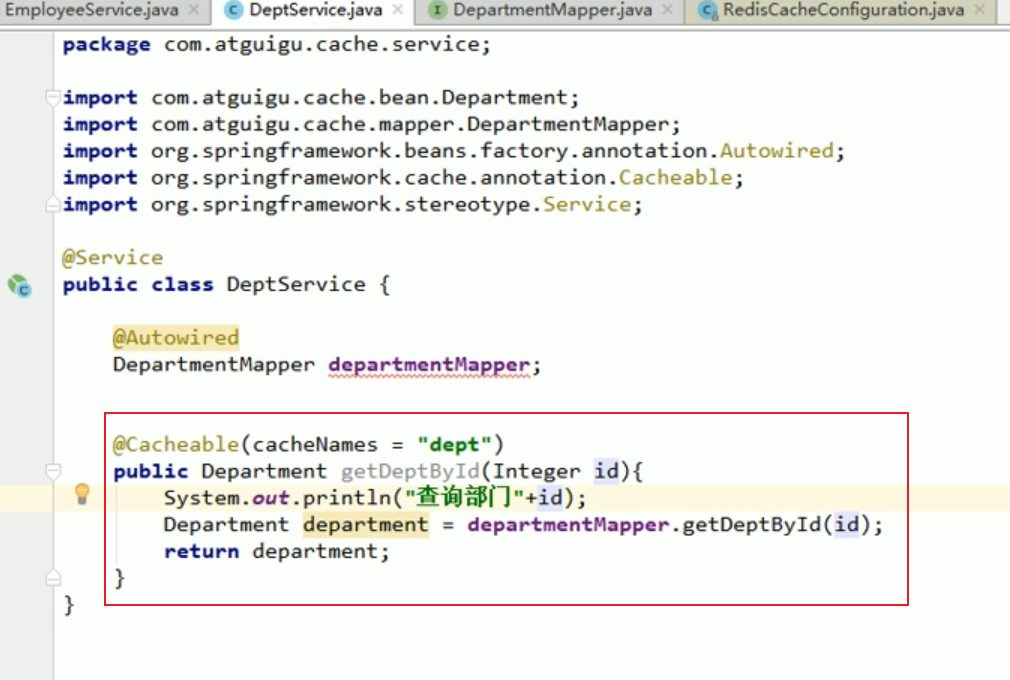
service
Écrivons un service correspondant
 #🎜 🎜#
#🎜 🎜#
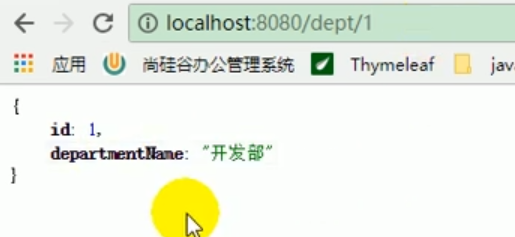
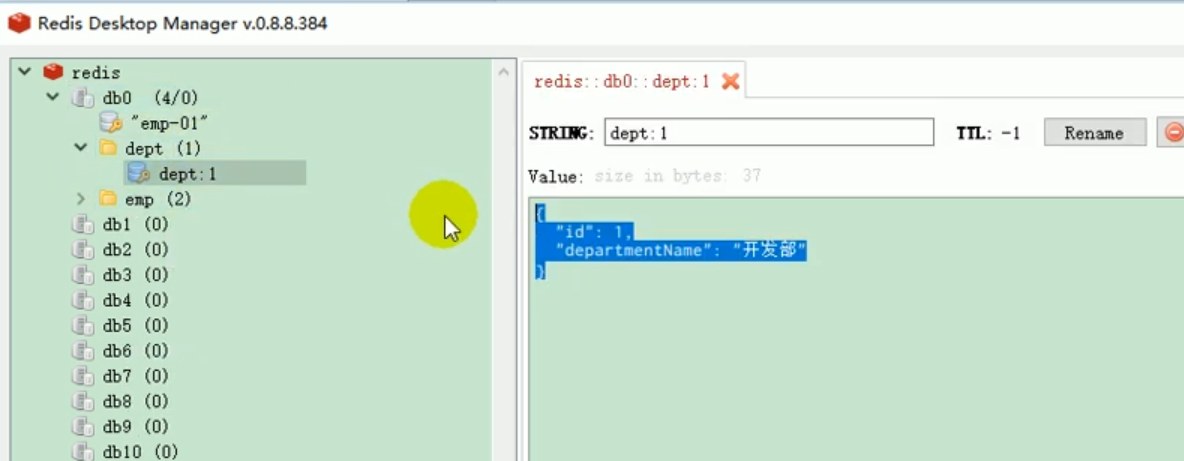
Nous avons vu qu'il existe des données liées au département dans Redis.
Lorsque nous interrogeons Dept pour la deuxième fois, nous devons utiliser Redis en cache.
Mais lorsque nous avons vérifié pour la deuxième fois, l'erreur suivante s'est produite.
Error
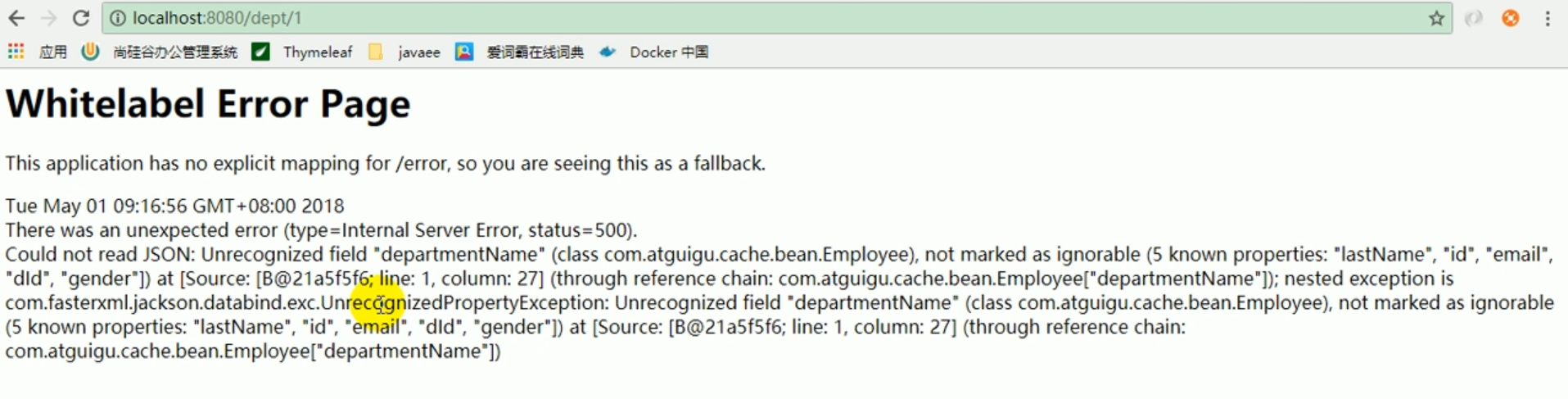
L'erreur signalée ci-dessus signifie que le json ne peut pas être lu.
Parce qu'il faut convertir l'objet json du service en objet json du collaborateur, ce qui n'est pas possible.
C'est parce que le redisCacheManager que nous avons placé est destiné aux employés opérationnels.
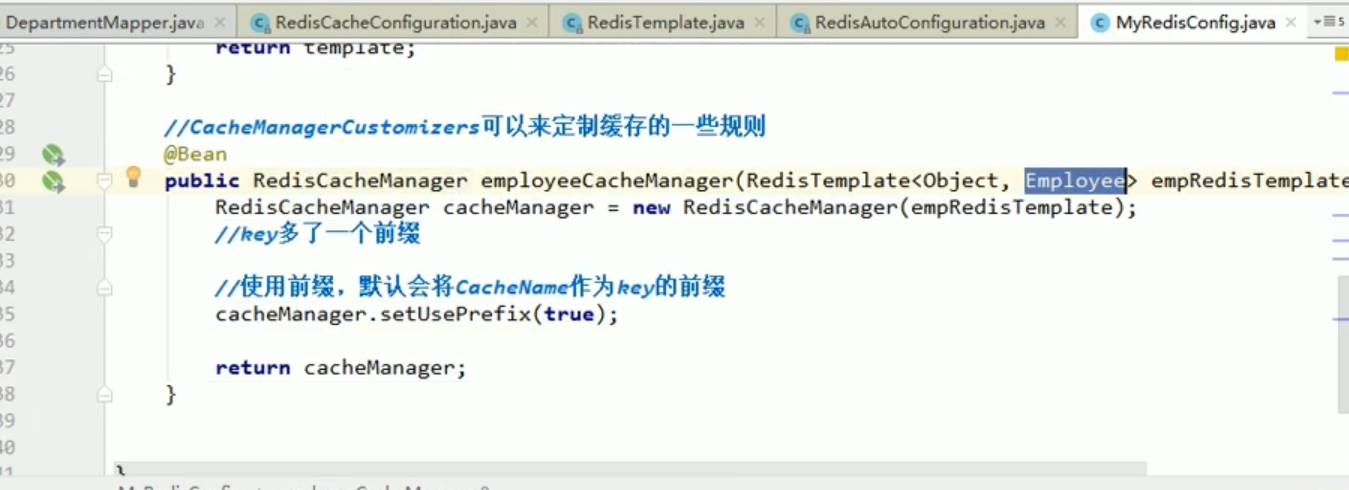
Donc, l'effet que nous voyons maintenant est très magique.
Les données mises en cache peuvent être stockées dans Redis.
Mais lorsque nous interrogeons le cache pour la deuxième fois, nous ne pouvons pas le désérialiser.
Il s'avère que ce que nous stockons sont les données JSON du département, et notre gestionnaire de cache utilise le modèle de l'employé pour faire fonctionner Redis par défaut.
Cette chose ne peut que désérialiser les données des employés.
Résoudre les erreurs
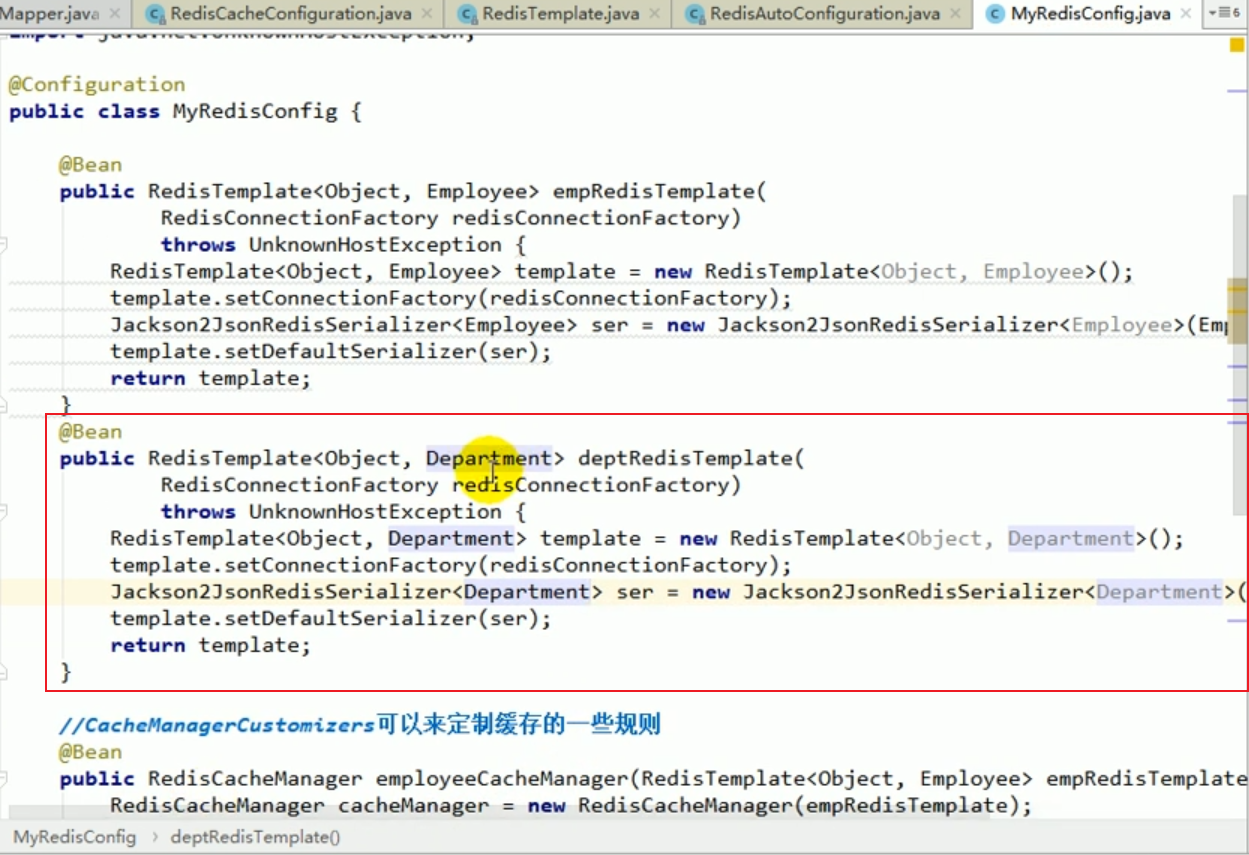
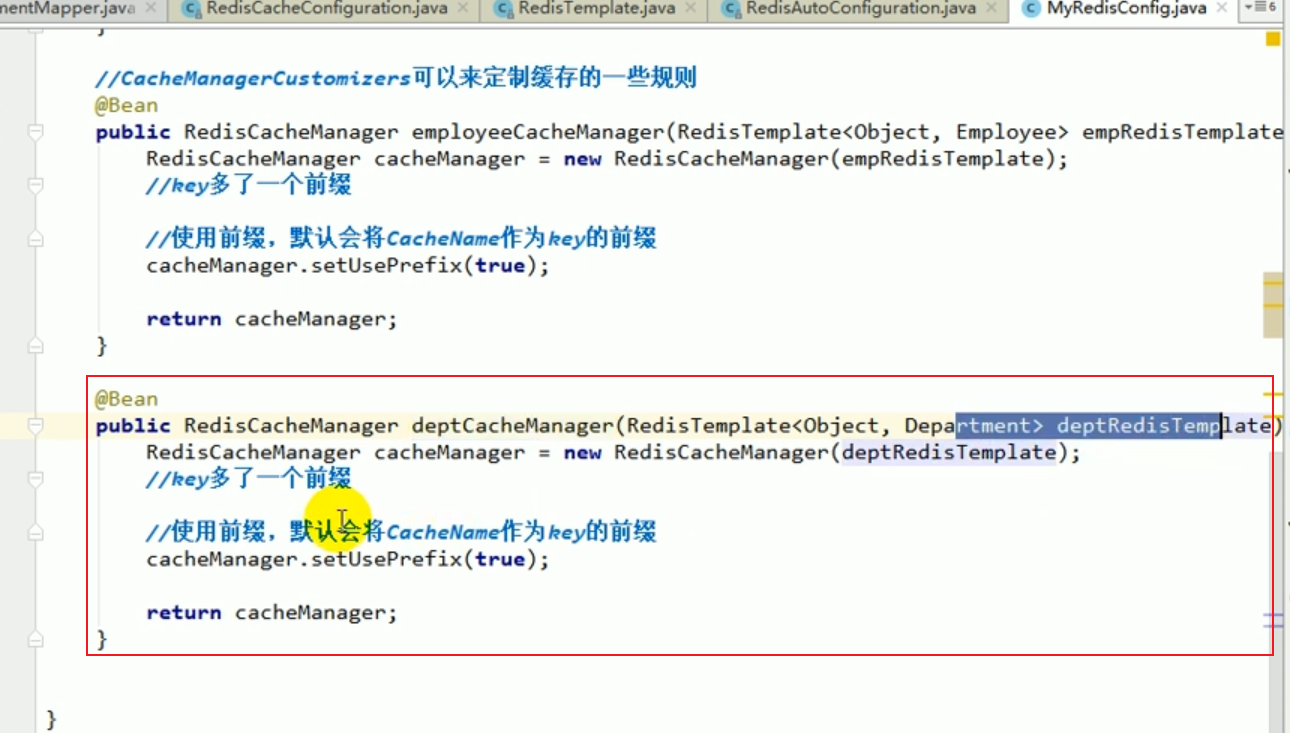
À ce moment, il est égal à 2 Il existe deux redisCacheManagers, lequel devons-nous utiliser ?
Nous pouvons le préciser dans le service.
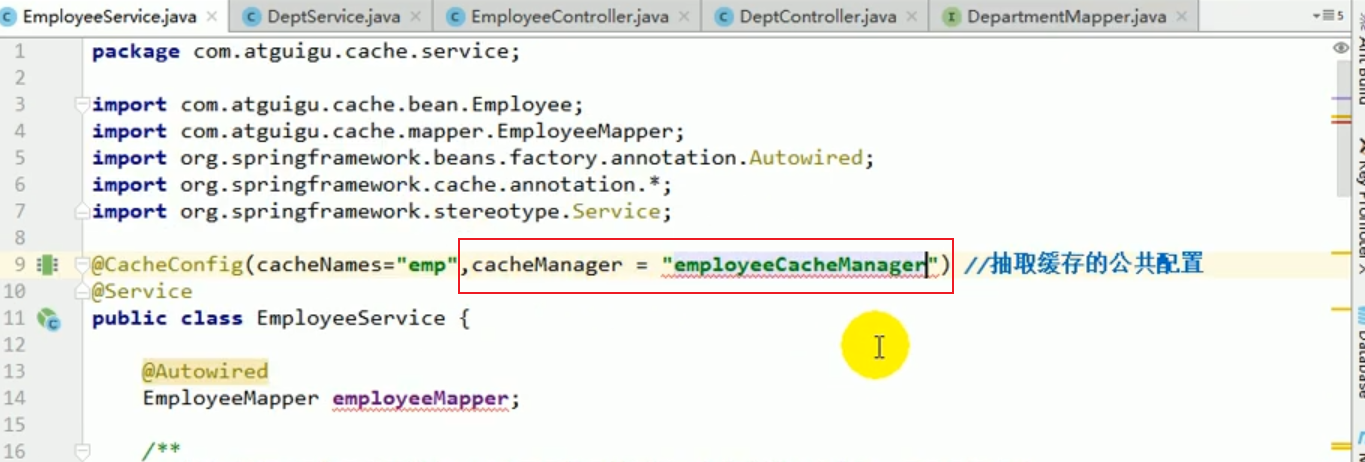
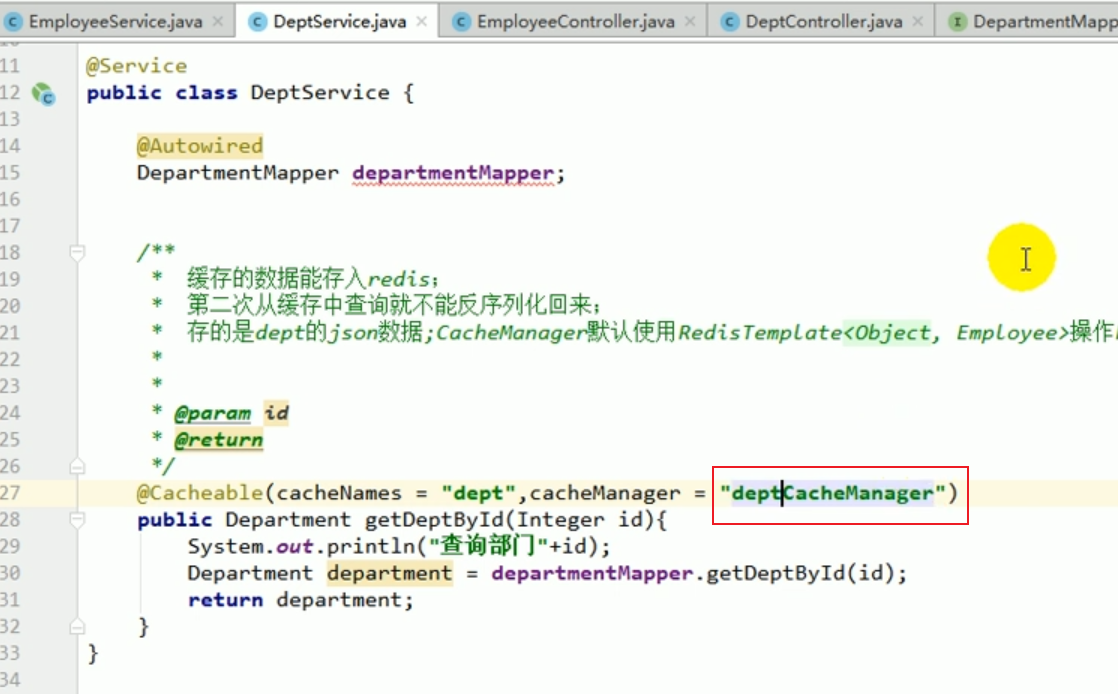
Ensuite, nous avons relancé le projet, et le résultat était une erreur :
# 🎜🎜#
À ce stade, voyons si nous pouvons désérialiser et lire notre département depuis Redis normalement et avec succès lors de l'exécution de la deuxième requête du département. Où sont les informations ?
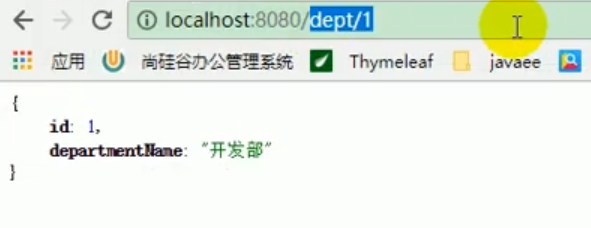
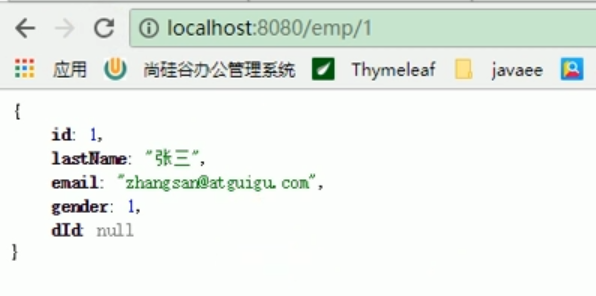 A cette époque, nous avons découvert que que ce soit un employé ou un service, nous pouvons tout le monde apprend de La désérialisation dans Redis est interrogée avec succès.
A cette époque, nous avons découvert que que ce soit un employé ou un service, nous pouvons tout le monde apprend de La désérialisation dans Redis est interrogée avec succès.
C'est parfait.
Méthode de codage pour faire fonctionner le cache
Ce que nous avons dit auparavant consiste à utiliser des annotations pour placer des données dans le cache.
Cependant, lors du développement, nous rencontrons souvent de telles situations.
C'est-à-dire que lorsque notre développement atteint un certain stade, nous devons mettre certaines données dans le cache.
Nous devons utiliser du codage pour faire fonctionner le cache.
Par exemple, après avoir interrogé les informations du département, nous souhaitons mettre ces informations dans Redis.
On peut injecter le cacheManager du département.
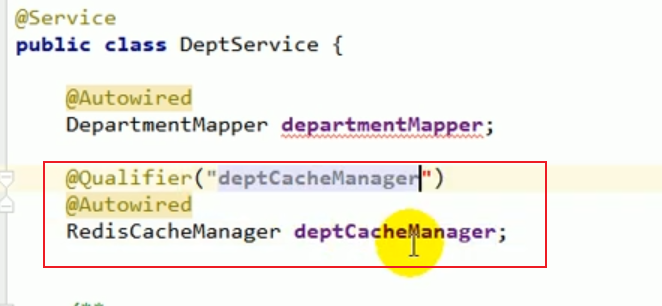 Puis pendant le processus d'encodage, on peut obtenir le cache en exploitant ce cacheManager,
Puis pendant le processus d'encodage, on peut obtenir le cache en exploitant ce cacheManager,
Ensuite, faire fonctionner le cache Component pour ajouter, supprimer, modifier et vérifier des données.
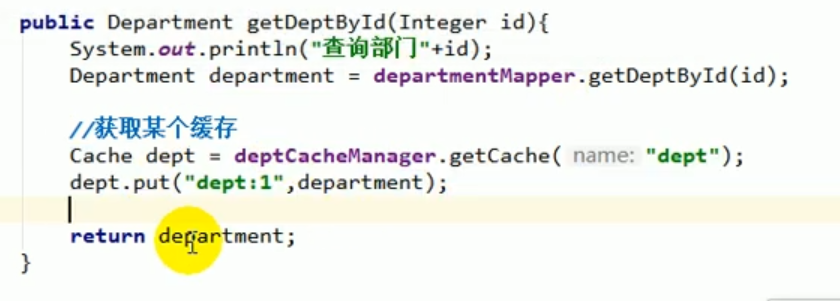 Nous avons testé le code ci-dessus et démarré le projet, et avons constaté que tout allait bien et que les données ont été mises avec succès dans Redis : #🎜 🎜#
Nous avons testé le code ci-dessus et démarré le projet, et avons constaté que tout allait bien et que les données ont été mises avec succès dans Redis : #🎜 🎜#
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Comment faire du message middleware pour redis
Apr 10, 2025 pm 07:51 PM
Redis, en tant que Message Middleware, prend en charge les modèles de consommation de production, peut persister des messages et assurer une livraison fiable. L'utilisation de Redis comme Message Middleware permet une faible latence, une messagerie fiable et évolutive.
