

Comment implémenter le filtre Redis BloomFilter Bloom

Bloom Filter Concept
Un homme nommé Bloom a proposé le filtre Bloom (nom anglais : Bloom Filter) en 1970. Il s'agit en fait d'un long vecteur binaire et d'une série de fonctions de cartographie aléatoire. Les filtres Bloom peuvent être utilisés pour déterminer si un élément se trouve dans une collection. Son avantage est que l'efficacité spatiale et le temps de requête sont bien supérieurs à ceux des algorithmes ordinaires. Son inconvénient est qu'il présente un certain taux de mauvaise reconnaissance et des difficultés de suppression.
Principe du filtre Bloom
Le principe du filtre Bloom est que lorsqu'un élément est ajouté à l'ensemble, K fonctions de hachage sont utilisées pour mapper l'élément en K points dans un tableau de bits et les définir sur 1. Lors de la récupération, il suffit de regarder si ces points sont tous à 1 pour savoir (approximativement) s'il est dans l'ensemble : si l'un de ces points a 0, alors l'élément coché ne doit pas être là s'ils sont tous à 1 ; puis l'élément coché Très probablement. C'est l'idée de base du filtre Bloom.
La différence entre Bloom Filter et Bit-Map à fonction de hachage unique est que Bloom Filter utilise k fonctions de hachage et chaque chaîne correspond à k bits. Réduisant ainsi la probabilité de conflit
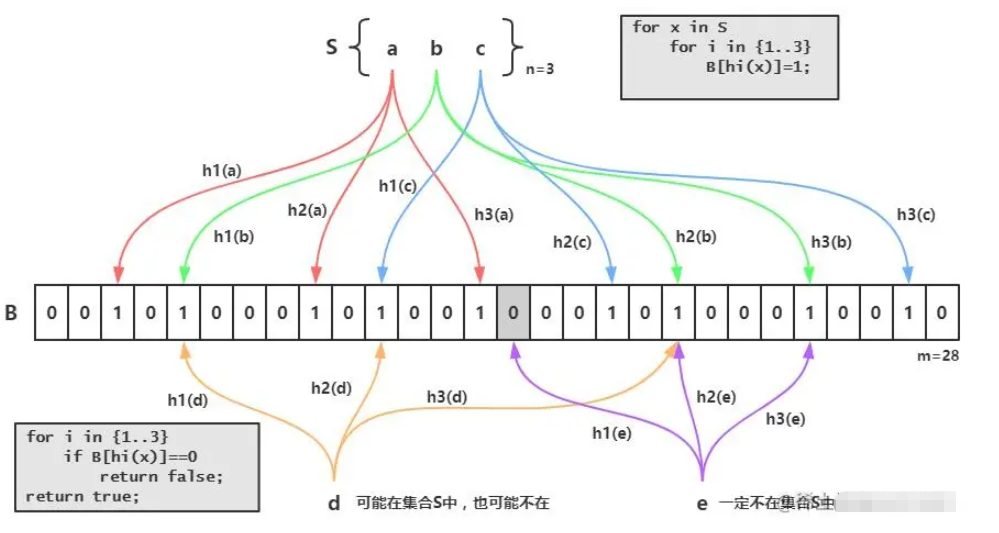
Pénétration du cache
Chaque requête sera directement envoyée à la base de données
En bref, en un mot, nous chargeons d'abord toutes les données de notre base de données dans notre Dans le filtre , par exemple, l'identifiant de la base de données a maintenant : 1, 2, 3
Utilisez ensuite l'identifiant : 1 comme exemple Après avoir haché trois fois dans l'image ci-dessus, il a changé les trois endroits où la valeur d'origine était de 0 à 1.
Lorsque les données arrivent pour la requête, si la valeur de id est 1, alors je hacherai 1 trois fois et constaterai que les valeurs des trois hachages sont exactement les mêmes que les trois positions ci-dessus, ce qui peut prouver que il y en a 1 dans le filtre
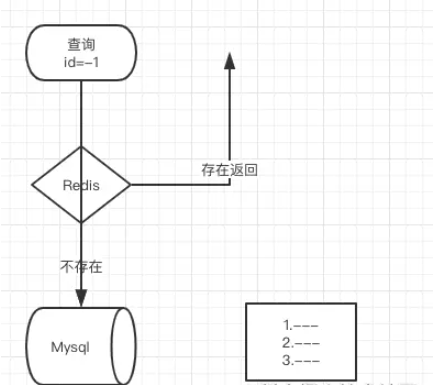
et vice versa si c'est différent, ça veut dire qu'il n'existe pas. Alors où est le scénario d'application ? Généralement, nous l'utiliserons pour éviter la panne du cache
Pour faire simple, l'identifiant de votre base de données commence par 1 puis augmente tout seul. Ensuite, je sais que votre interface est interrogée par identifiant, j'utiliserai donc des nombres négatifs pour interroger. À ce moment-là, j'ai découvert qu'il n'y avait pas de telles données dans le cache, et j'ai vérifié dans la base de données et je n'ai rien trouvé. Une requête ressemble à ceci, qu'en est-il de 100, 1 000 ou 10 000 ? Votre base de données est fondamentalement incapable de le gérer. Si vous ajoutez ceci au cache, il n'existera plus. Si vous jugez qu'il n'existe pas de telles données, vous ne les vérifierez pas.
Cette chose fonctionne si bien, alors quels sont les inconvénients ? Oui, jetons un coup d'œil ci-dessous
Inconvénients du filtre Bloom
La raison pour laquelle le filtre Bloom peut être plus efficace dans le temps et dans l'espace est qu'il sacrifie l'exactitude du jugement et la commodité de la suppression
Bien que le conteneur Il puisse ne pas contenir les éléments qui doivent être trouvés, mais en raison de l'opération de hachage, les valeurs de ces éléments dans k positions de hachage sont toutes 1, cela peut donc conduire à une erreur de jugement. En établissant une liste blanche pour stocker les éléments susceptibles d'être mal évalués, lorsque le filtre Bloom stocke une liste noire, le taux d'erreur d'évaluation peut être réduit.
La suppression est difficile. Un élément placé dans le conteneur est mappé à 1 dans les k positions du tableau de bits. Lors de la suppression, il ne peut pas être simplement mis à 0 directement, car cela peut affecter le jugement des autres éléments. Vous pouvez utiliser Counting Bloom Filter
FAQ
1 Pourquoi utiliser plusieurs fonctions de hachage ?
Si une seule fonction de hachage est utilisée, le hachage lui-même sera souvent en conflit. Par exemple, pour un tableau d'une longueur de 100, si une seule fonction de hachage est utilisée, après l'ajout d'un élément, la probabilité de conflit lors de l'ajout du deuxième élément est de 1 % et la probabilité de conflit lors de l'ajout du troisième élément est de 2. %... Mais si deux éléments sont ajoutés, la probabilité de conflit est de 1%. Une fonction de hachage, après l'ajout d'un élément, la probabilité de conflit lors de l'ajout du deuxième élément est réduite à 4 sur 10 000 (quatre situations de conflit possibles, le le nombre total de situations est de 100x100)
Implémentation du langage Go
package main
import (
"fmt"
"github.com/bits-and-blooms/bitset"
)
//设置哈希数组默认大小为16
const DefaultSize = 16
//设置种子,保证不同哈希函数有不同的计算方式
var seeds = []uint{7, 11, 13, 31, 37, 61}
//布隆过滤器结构,包括二进制数组和多个哈希函数
type BloomFilter struct {
//使用第三方库
set *bitset.BitSet
//指定长度为6
hashFuncs [6]func(seed uint, value string) uint
}
//构造一个布隆过滤器,包括数组和哈希函数的初始化
func NewBloomFilter() *BloomFilter {
bf := new(BloomFilter)
bf.set = bitset.New(DefaultSize)
for i := 0; i < len(bf.hashFuncs); i++ {
bf.hashFuncs[i] = createHash()
}
return bf
}
//构造6个哈希函数,每个哈希函数有参数seed保证计算方式的不同
func createHash() func(seed uint, value string) uint {
return func(seed uint, value string) uint {
var result uint = 0
for i := 0; i < len(value); i++ {
result = result*seed + uint(value[i])
}
//length = 2^n 时,X % length = X & (length - 1)
return result & (DefaultSize - 1)
}
}
//添加元素
func (b *BloomFilter) add(value string) {
for i, f := range b.hashFuncs {
//将哈希函数计算结果对应的数组位置1
b.set.Set(f(seeds[i], value))
}
}
//判断元素是否存在
func (b *BloomFilter) contains(value string) bool {
//调用每个哈希函数,并且判断数组对应位是否为1
//如果不为1,直接返回false,表明一定不存在
for i, f := range b.hashFuncs {
//result = result && b.set.Test(f(seeds[i], value))
if !b.set.Test(f(seeds[i], value)) {
return false
}
}
return true
}
func main() {
filter := NewBloomFilter()
filter.add("asd")
fmt.Println(filter.contains("asd"))
fmt.Println(filter.contains("2222"))
fmt.Println(filter.contains("155343"))
}Les résultats de sortie sont les suivants :
vrai
fauxfaux
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Comment afficher toutes les clés dans Redis
Apr 10, 2025 pm 07:15 PM
Pour afficher toutes les touches dans Redis, il existe trois façons: utilisez la commande Keys pour retourner toutes les clés qui correspondent au modèle spécifié; Utilisez la commande SCAN pour itérer les touches et renvoyez un ensemble de clés; Utilisez la commande info pour obtenir le nombre total de clés.
 Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Comment implémenter le redis sous-jacent
Apr 10, 2025 pm 07:21 PM
Redis utilise des tables de hachage pour stocker les données et prend en charge les structures de données telles que les chaînes, les listes, les tables de hachage, les collections et les collections ordonnées. Redis persiste les données via des instantanés (RDB) et ajoutez les mécanismes d'écriture uniquement (AOF). Redis utilise la réplication maître-esclave pour améliorer la disponibilité des données. Redis utilise une boucle d'événement unique pour gérer les connexions et les commandes pour assurer l'atomicité et la cohérence des données. Redis définit le temps d'expiration de la clé et utilise le mécanisme de suppression paresseux pour supprimer la clé d'expiration.
