
 Périphériques technologiques
IA
Raisonnement GPT-4 amélioré de 1750 % ! Un ancien élève de la classe Tsinghua Yao de Princeton a proposé un nouveau cadre 'Thinking Tree ToT', permettant au LLM de réfléchir à plusieurs reprises.
Périphériques technologiques
IA
Raisonnement GPT-4 amélioré de 1750 % ! Un ancien élève de la classe Tsinghua Yao de Princeton a proposé un nouveau cadre 'Thinking Tree ToT', permettant au LLM de réfléchir à plusieurs reprises.
Raisonnement GPT-4 amélioré de 1750 % ! Un ancien élève de la classe Tsinghua Yao de Princeton a proposé un nouveau cadre 'Thinking Tree ToT', permettant au LLM de réfléchir à plusieurs reprises.

En 2022, Jason Wei, ancien scientifique chinois de Google Brain, a proposé pour la première fois dans un travail pionnier sur la chaîne de pensée que le CoT pouvait améliorer la capacité de raisonnement du LLM.
Mais même avec la chaîne de réflexion, LLM fait parfois des erreurs sur des questions très simples.
Récemment, des chercheurs de l'Université de Princeton et de Google DeepMind ont proposé un nouveau cadre de raisonnement de modèle de langage - "Tree of Thought" (ToT).
ToT généralise la méthode actuellement populaire de la « chaîne de pensée » pour guider le modèle de langage et résoudre les étapes intermédiaires du problème en explorant des unités cohérentes de texte (pensée).

Adresse papier : https://arxiv.org/abs/2305.10601
Adresse du projet : https://github.com/kyegomez/tree-of-thoughts
En termes simples, "Thinking Tree" permet à LLM de :
· Donnez-vous plusieurs chemins de raisonnement différents
· Après avoir évalué chacun, décidez du prochain plan d'action
· Tracez en avant ou en arrière si nécessaire pour parvenir à une prise de décision globale
Les résultats expérimentaux de l'article montrent que ToT améliore considérablement les performances du LLM dans trois nouvelles tâches (jeu de 24 points, écriture créative, mini mots croisés) Compétences en résolution de problèmes.
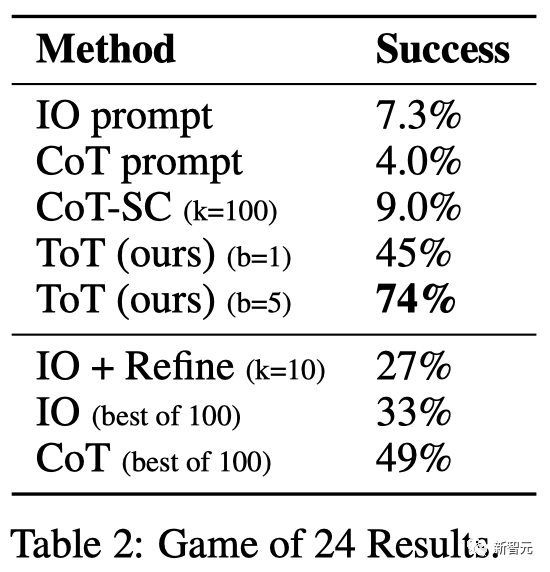
Par exemple, dans le jeu en 24 points, GPT-4 n'a résolu que 4 % des tâches, mais le taux de réussite de la méthode ToT a atteint 74 %.
Laissons LLM "réfléchir encore et encore"
Les grands modèles de langage GPT et PaLM utilisés pour générer du texte se sont désormais avérés capables d'effectuer un large éventail de tâches.
La base du progrès de tous ces modèles reste le « mécanisme autorégressif » utilisé à l'origine pour générer du texte, prenant des décisions au niveau des jetons les unes après les autres de gauche à droite.

Alors, un mécanisme aussi simple peut-il suffire à établir un « modèle linguistique pour résoudre des problèmes généraux » ? Dans la négative, quels problèmes remettent en question le paradigme actuel et quels devraient être les véritables mécanismes alternatifs ?
C'est précisément la littérature sur la « cognition humaine » qui fournit quelques indices sur cette problématique.
La recherche sur le modèle du « double processus » montre que les humains ont deux modes de prise de décision : le mode rapide, automatique et inconscient – « Système 1 » et le mode lent, délibéré et conscient – « Système 2 ».
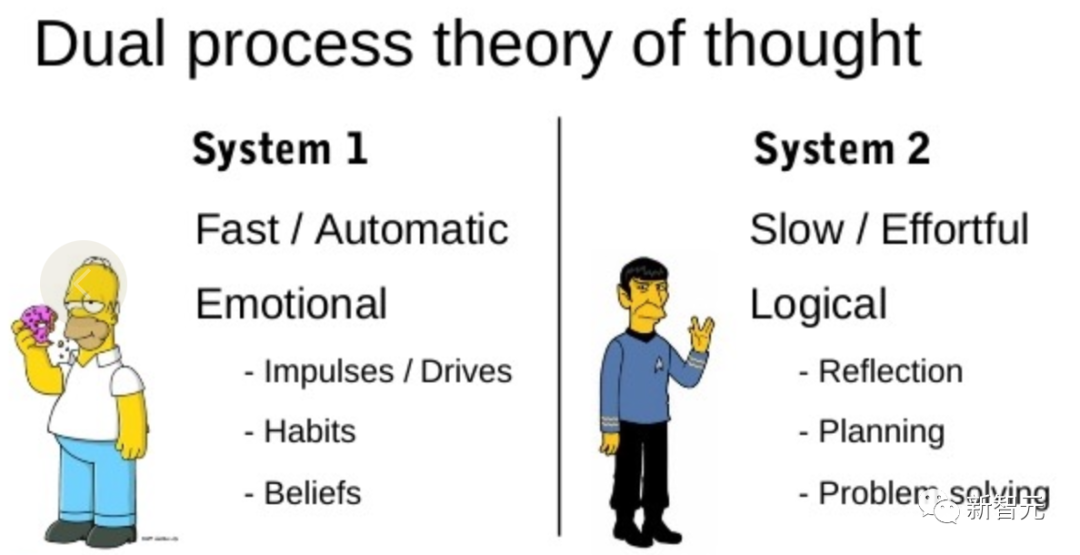
Les modèles de langage associant simplement des choix au niveau des jetons peuvent rappeler le « Système 1 », cette capacité peut donc être améliorée à partir du processus de planification du « Système 2 ».
Le « Système 1 » permet à LLM de maintenir et d'explorer plusieurs alternatives au choix actuel, plutôt que de simplement en choisir une, tandis que le « Système 2 » évalue son état actuel et prévoit activement et regarde en arrière pour prendre une décision plus globale.
Pour concevoir un tel processus de planification, les chercheurs sont remontés aux origines de l'intelligence artificielle et des sciences cognitives, en s'inspirant du processus de planification que les scientifiques Newell, Shaw et Simon ont commencé à explorer dans les années 1950.
Newell et ses collègues décrivent la résolution de problèmes comme « une recherche en combinant l'espace du problème », représenté par un arbre.
Dans le processus de résolution de problèmes, vous devez utiliser à plusieurs reprises les informations existantes pour explorer afin d'obtenir plus d'informations jusqu'à ce que vous trouviez enfin une solution.

Cette perspective met en évidence 2 principales lacunes des méthodes existantes d'utilisation du LLM pour résoudre des problèmes généraux :
1 Localement, le LLM n'explore pas les différentes suites du processus de réflexion - la branche de l'arbre.
2. Dans l'ensemble, LLM n'inclut aucun type de planification, prospective ou rétrospective pour aider à évaluer ces différentes options.
Afin de résoudre ces problèmes, les chercheurs ont proposé un cadre d'arbre de pensée (ToT) qui utilise des modèles de langage pour résoudre des problèmes généraux, permettant à LLM d'explorer plusieurs chemins de raisonnement.
Méthode ToT en quatre étapes
Actuellement, les méthodes existantes, telles que IO, CoT, CoT-SC, résolvent des problèmes en échantillonnant des séquences de langage continues.
Et ToT entretient activement un "arbre pensant". Chaque case rectangulaire représente une pensée, et chaque pensée est une séquence verbale cohérente qui sert d'étape intermédiaire dans la résolution d'un problème.
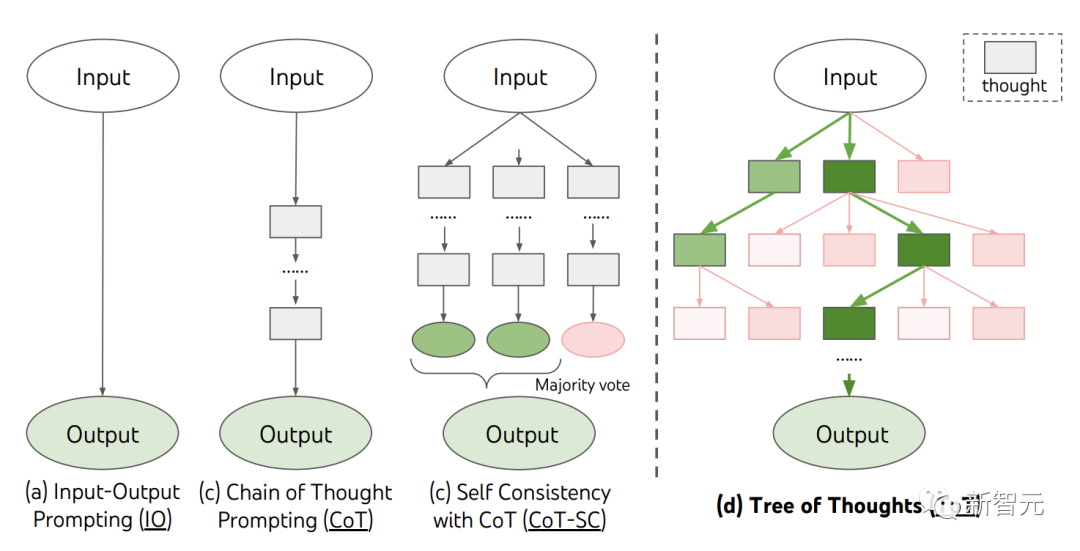
ToT définit tout problème comme une recherche sur un arbre, où chaque nœud est un état représentant une solution partielle à la séquence d'entrées et de pensées jusqu'à présent.
ToT doit répondre à 4 questions lors de l'exécution d'une tâche spécifique :
Comment décomposer le processus intermédiaire en étapes de réflexion ; comment générer des idées potentielles à partir de chaque état ; comment évaluer heuristiquement l'état à quel algorithme de recherche ; utiliser .
1. Décomposition de la pensée
CoT échantillonne de manière cohérente la pensée sans décomposition explicite, tandis que ToT utilise les propriétés du problème pour concevoir et décomposer les étapes de réflexion intermédiaires.
Selon la question, une idée peut être quelques mots (mots croisés), une équation (24 points) ou tout un plan d'écriture (écriture créative).
De manière générale, une idée doit être suffisamment « petite » pour que LLM puisse produire des échantillons significatifs et diversifiés. Par exemple, générer un livre complet est souvent trop « gros » pour être cohérent.
Mais une idée doit également être suffisamment « grande » pour que LLM puisse évaluer ses perspectives de résolution du problème. Par exemple, la génération d’un jeton est souvent trop « petite » pour être évaluée.
2. Générateur de pensées 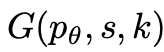
Étant donné l'état de l'arbre 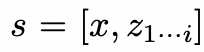 , générez k candidats pour la prochaine étape de réflexion à travers 2 stratégies.
, générez k candidats pour la prochaine étape de réflexion à travers 2 stratégies.
(a) Échantillonnage à partir d'une invite CoT  Pensée :
Pensée :
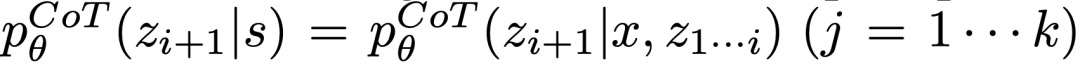
fonctionne mieux lorsque l'espace de réflexion est riche (comme si chaque idée est un paragraphe) et  mène à la diversité.
mène à la diversité.
(b) Utilisez « invite de proposition » pour proposer des idées dans l'ordre : 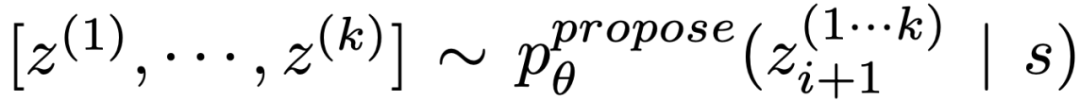
. Cela fonctionne mieux lorsque l'espace de réflexion est limité (par exemple, chaque pensée ne représente qu'un mot ou une ligne), donc présenter différentes idées dans le même contexte évite les duplications.
3. Évaluateur d'État
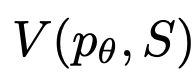
Étant donné différents fronts d'État, l'évaluateur d'État évalue leurs progrès dans la résolution du problème comme une heuristique permettant à l'algorithme de recherche de déterminer quels États doivent être explorés et dans quel ordre.
Bien que les heuristiques soient le moyen standard de résoudre les problèmes de recherche, elles sont généralement programmées (DeepBlue) ou apprises (AlphaGo). Ici, les chercheurs proposent une troisième option pour raisonner consciemment sur les états via le LLM.
Le cas échéant, cette heuristique réfléchie peut être plus flexible que les règles procédurales et plus efficace que les modèles appris. Avec le Thought Generator, les chercheurs ont également envisagé 2 stratégies pour évaluer les États indépendamment ou ensemble : attribuer des valeurs à chaque État indépendamment et voter entre les États ;
4. Algorithme de recherche
Enfin, dans le cadre ToT, les gens peuvent brancher et utiliser différents algorithmes de recherche basés sur la structure de l'arborescence.
Les chercheurs ont exploré ici 2 algorithmes de recherche relativement simples :
Algorithme 1 - Breadth First Search (BFS), qui maintient un ensemble des états les plus prometteurs de b à chaque étape.
Algorithme 2 - Depth First Search (DFS), explore d'abord les états les plus prometteurs jusqu'à ce que le résultat final soit atteint, ou que l'évaluateur d'état juge impossible de résoudre le problème à partir du seuil actuel. Dans les deux cas, DFS revient à l’état parent de s pour poursuivre l’exploration.

D'après ce qui précède, la méthode de LLM consistant à mettre en œuvre la recherche heuristique par l'auto-évaluation et la prise de décision consciente est nouvelle.
Expériences
À cette fin, l'équipe a proposé trois tâches de test - même le modèle de langage le plus avancé GPT-4 est très riche sous les invites IO standard ou les invites de chaîne de pensée (CoT) difficiles.

Game of 24
24 est un jeu de raisonnement mathématique où le but est d'obtenir 24 en utilisant 4 nombres et des opérations arithmétiques de base (+-*/).
Par exemple, étant donné l'entrée "4 9 10 13", le résultat de la réponse peut être "(10-4)*(13-9)=24".
ToT setup
L'équipe a décomposé le processus de réflexion du modèle en 3 étapes, chaque étape est une équation intermédiaire.
Comme le montre la figure 2(a), à chaque nœud, extrayez le numéro sur la « gauche » et invitez LLM à générer une éventuelle étape suivante. (Les « invites de proposition » données à chaque étape sont les mêmes)
Parmi eux, l'équipe effectue une recherche en largeur (BFS) dans ToT et retient les meilleurs candidats b=5 à chaque étape.
Comme le montre la figure 2(b), LLM est invité à évaluer chaque candidat réfléchi comme « certainement/possiblement/impossible » jusqu'à 24. Éliminez les solutions partielles impossibles basées sur le bon sens « trop grand/trop petit » et conservez les éléments « possibles » restants.
Résultats
Comme le montre le tableau 2, les méthodes d'invite IO, CoT et CoT-SC ont donné de mauvais résultats sur la tâche, avec des taux de réussite de seulement 7,3 %, 4,0 % et 9,0. %. En comparaison, ToT a atteint un taux de réussite de 45 % lorsque l’étendue est b=1, et de 74 % lorsque b=5.
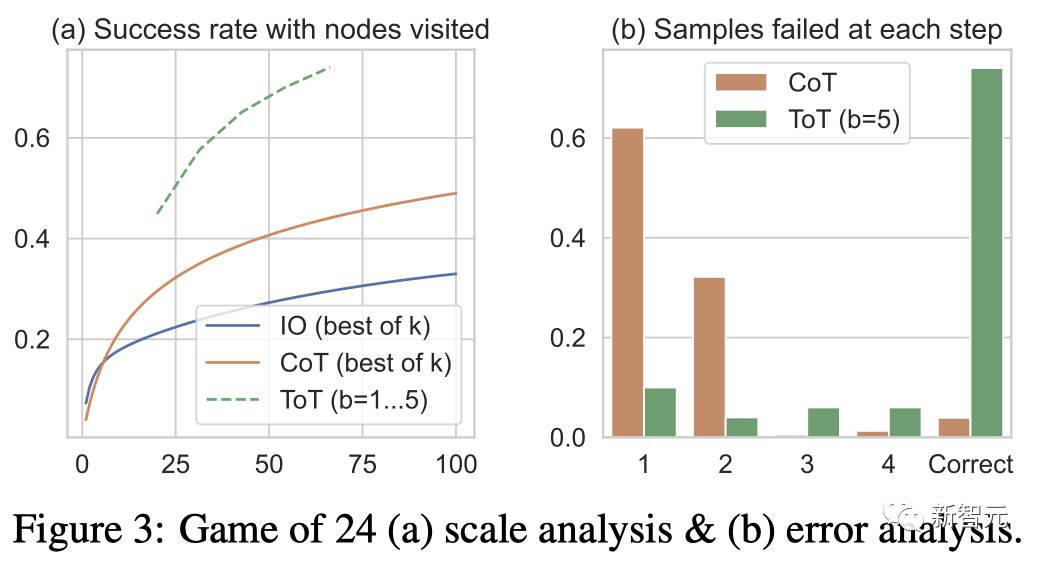
L'équipe a également examiné le paramètre de prédiction d'IO/CoT en utilisant les k meilleurs échantillons (1≤k≤100) pour calculer le taux de réussite et a tracé les 5 taux de réussite dans la figure 3(a).
Comme prévu, CoT évolue mieux que IO, les 100 meilleurs échantillons CoT atteignant un taux de réussite de 49 %, mais toujours pire que l'exploration de plus de nœuds (b>1) dans ToT.
Analyse des erreurs
La figure 3 (b) analyse les échantillons CoT et ToT à quelle étape ils ont échoué à la tâche, c'est-à-dire penser (dans CoT) ou tout b penser (dans ToT) sont invalides ou ne peuvent pas atteindre 24 ans.
Il convient de noter qu'environ 60 % des échantillons CoT ont échoué lors de la première étape, ou en d'autres termes, les trois premiers mots (comme « 4+9 »).
Écriture créative
Ensuite, l'équipe a conçu une tâche d'écriture créative.
Parmi eux, l'entrée est constituée de quatre phrases aléatoires, et la sortie doit être un paragraphe cohérent, chaque paragraphe se terminant respectivement par quatre phrases d'entrée. Ces tâches sont ouvertes et exploratoires, mettant au défi la pensée créative et la planification avancée.
Il convient de noter que l'équipe utilise également une méthode d'optimisation itérative (k≤5) sur des échantillons d'E/S aléatoires de chaque tâche, dans laquelle LLM détermine si le paragraphe est "complètement cohérent" en fonction des restrictions d'entrée et de la dernier paragraphe généré, sinon, générez-en un optimisé.
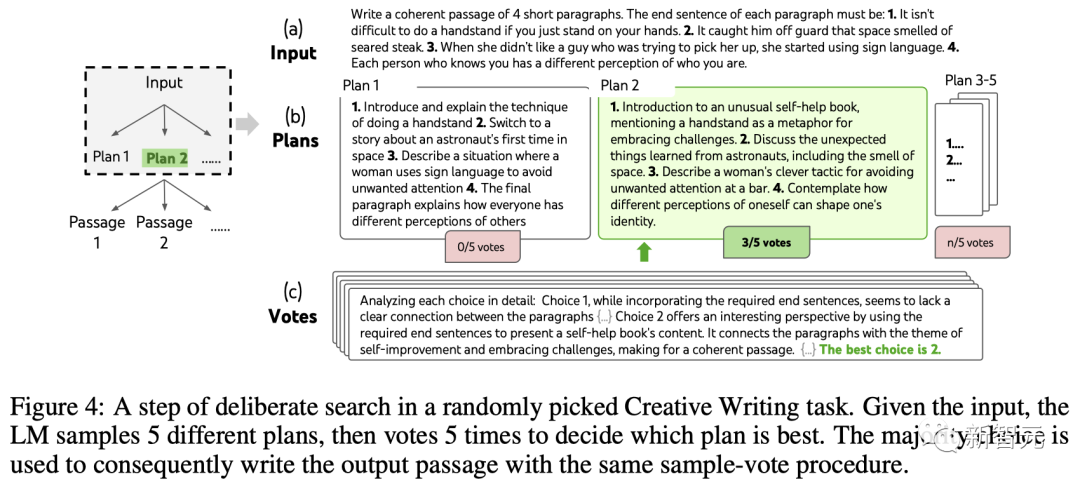
Configuration ToT
L'équipe a construit une ToT avec une profondeur de 2 (seulement 1 étape de réflexion intermédiaire).
LLM génère d'abord k=5 plans et vote pour choisir le meilleur (Figure 4), puis génère k=5 paragraphes basés sur le meilleur plan, puis vote pour choisir le meilleur.
Une simple invite de vote zéro (« analysez les choix suivants et décidez lequel est le plus susceptible de mettre en œuvre la directive ») a été utilisée pour tirer 5 votes en deux étapes.
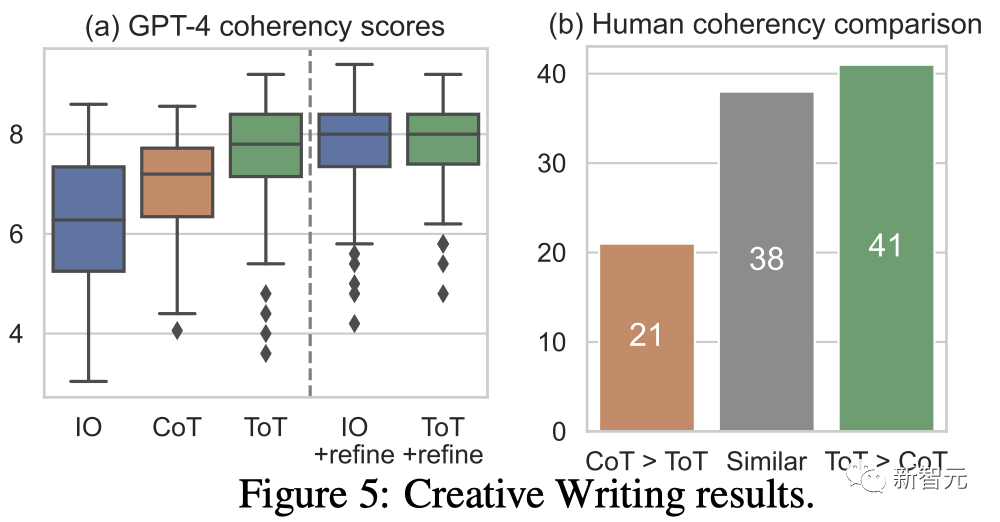
result
# 🎜🎜# La figure 5(a) montre le score GPT-4 moyen sur 100 tâches, où ToT (7,56) est considéré comme générant en moyenne des paragraphes plus cohérents que IO (6,19) et CoT (6,93).
Bien que de telles évaluations automatisées puissent être bruyantes, la figure 5(b) le démontre en montrant que les humains préfèrent ToT dans 41 paires de paragraphes sur 100 alors que seulement 21 One préféraient CoT (les 38 autres paires ont été considérées comme « tout aussi cohérentes ») pour confirmer ce constat.
Enfin, l'optimisation itérative est plus efficace sur cette tâche en langage naturel - améliorant le score de cohérence IO de 6,19 à 7,67 et le score de cohérence ToT de 7,56 à 7,91.
L'équipe estime qu'elle peut être considérée comme la troisième méthode de génération de réflexion dans le cadre ToT. Une nouvelle réflexion peut être générée en optimisant l'ancienne pensée au lieu de l'i.i.d. génération.
mini mots croisés
ToT est relativement superficiel dans les jeux à 24 points et l'écriture créative— —Il prend jusqu'à 3 étapes de réflexion pour terminer le résultat.
Finalement, l'équipe a décidé de poser une question plus difficile à travers un mini jeu de mots croisés 5×5.
Encore une fois, l'objectif n'est pas seulement de résoudre la tâche, mais d'étudier les limites du LLM en tant que solutionneur général de problèmes. Guidez votre exploration en scrutant votre propre esprit et en vous inspirant d’un raisonnement ciblé. # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # # TOT Paramètres # 🎜🎜 ## 🎜🎜 # #
L'équipe utilise d'abord une recherche approfondie pour continuer à explorer les indices de mots suivants qui sont les plus susceptibles de réussir jusqu'à ce que l'état ne soit plus prometteur, puis revient à l'état parent pour explorer des pensées alternatives.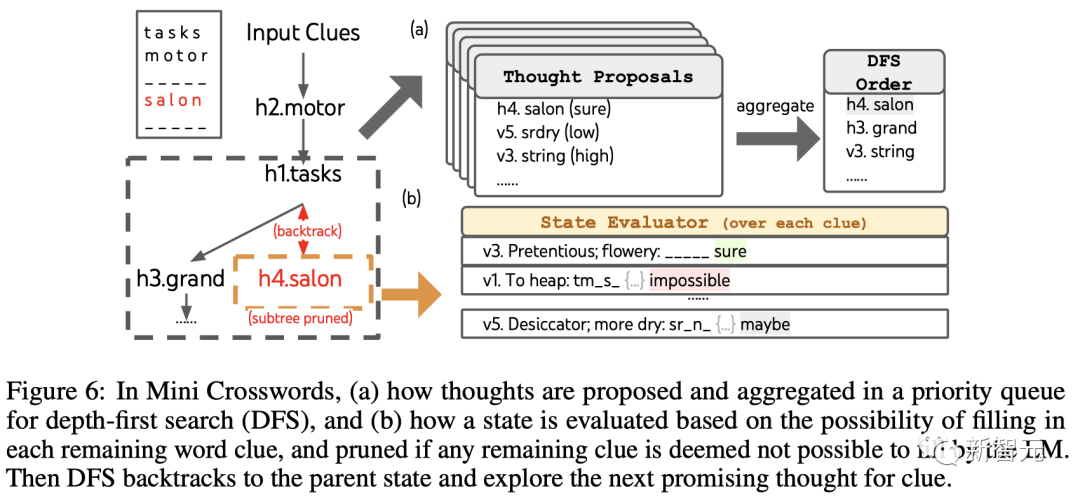
Pour la génération de pensées, l'équipe combine toutes les pensées existantes dans chaque état (par exemple, "h2.motor; h1.tasks" pour la figure 6(a) L'état in ) est converti en la limite de lettres des indices restants (par exemple, "v1.To heap: tm___;..."), obtenant ainsi des candidats pour remplir la position et le contenu du mot suivant.
Il est important que l'équipe invite également le LLM à donner des niveaux de confiance pour différentes idées et les regroupe dans la proposition pour obtenir une liste classée d'idées à explorer ensuite (Figure 6 (un)).
Pour l'évaluation du statut, l'équipe convertit de la même manière chaque statut en une limite de lettres pour les indices restants, puis évalue si chaque indice est susceptible d'être rempli dans la limite donnée. .
Si des indices restants sont jugés "impossibles" (par exemple, "v1. To tas: tm_s_"), alors l'exploration du sous-arbre de cet état est élaguée, et DFS revient à son nœud parent pour explorer le prochain candidat possible.
result
# 🎜🎜#Comme le montre le tableau 3, les méthodes d'incitation d'IO et de CoT ont donné de mauvais résultats en termes de taux de réussite au niveau des mots, inférieur à 16 %, tandis que ToT a considérablement amélioré toutes les mesures, atteignant 60 % au niveau des mots. taux de réussite et résolu 4 jeux sur 20.
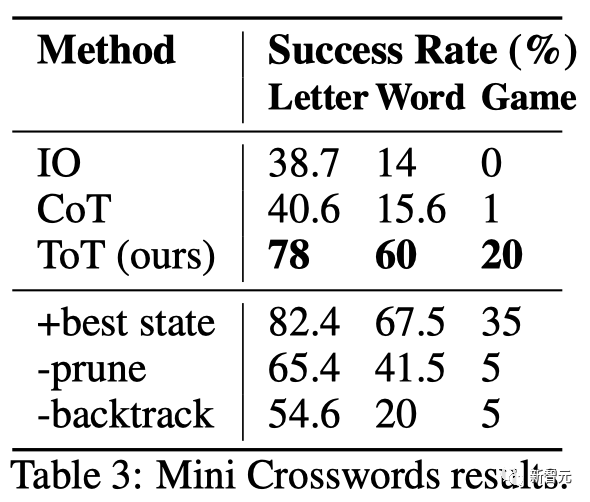 Cette amélioration n'est pas surprenante étant donné que IO et CoT manquent de mécanismes pour essayer différents indices, modifier les décisions ou revenir en arrière.
Cette amélioration n'est pas surprenante étant donné que IO et CoT manquent de mécanismes pour essayer différents indices, modifier les décisions ou revenir en arrière.
Limitations et conclusions
ToT est un cadre qui permet au LLM de prendre des décisions et de résoudre des problèmes de manière plus autonome et intelligente.
Cela améliore l'interprétabilité des décisions du modèle et les chances d'alignement avec les humains, car la table de représentation générée par ToT se présente sous la forme d'un raisonnement lisible en langage de haut niveau, plutôt que de valeurs symboliques implicites de bas niveau.
Pour les tâches pour lesquelles GPT-4 est déjà très bon, ToT n'est peut-être pas nécessaire.
De plus, les méthodes de recherche comme ToT nécessitent plus de ressources (telles que le coût de l'API GPT-4) pour améliorer les performances des tâches, mais la flexibilité modulaire de ToT permet aux utilisateurs de personnaliser cet équilibre performances-coûts.
Cependant, comme le LLM est utilisé dans des applications de prise de décision plus concrètes (telles que la programmation, l'analyse de données, la robotique, etc.), la ToT peut offrir de nouvelles opportunités pour étudier des tâches plus complexes qui émergeront.
Présentation de l'auteur
Shunyu Yao (Yao Shunyu)

Le premier auteur de l'article Shunyu Yao est un doctorant de quatrième année à l'Université de Princeton et a déjà obtenu son diplôme. de la classe Yao de l'Université Tsinghua.
Son axe de recherche est de créer des interactions entre les agents linguistiques et le monde, comme jouer à des jeux de mots (CALM), faire des achats en ligne (WebShop), parcourir Wikipédia pour raisonner (ReAct) ou, sur la base de la même idée, utiliser n'importe quel outil pour accomplir n'importe quelle tâche.
Dans la vie, il aime lire, le basket, le billard, les voyages et le rap.
Dian Yu

Dian Yu est chercheuse scientifique chez Google DeepMind. Auparavant, il a obtenu son doctorat à l'UC Davis et son BA à l'Université de New York, avec une double spécialisation en informatique et en finance (et un peu de théâtre).
Ses intérêts de recherche portent sur la représentation des attributs du langage, ainsi que sur la compréhension multilingue et multimodale, se concentrant principalement sur la recherche conversationnelle (y compris en domaine ouvert et orientée tâches).
Yuan Cao
Yuan Cao est également chercheur scientifique chez Google DeepMind. Auparavant, il a obtenu sa licence et sa maîtrise à l'Université Jiao Tong de Shanghai et son doctorat à l'Université Johns Hopkins. Il a également été l'architecte en chef de Baidu.
Jeffrey Zhao

Jeffrey Zhao est ingénieur logiciel chez Google DeepMind. Auparavant, il a obtenu son baccalauréat et sa maîtrise de l'Université Carnegie Mellon.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment effectuer une vérification de la signature numérique avec Debian OpenSSL
Apr 13, 2025 am 11:09 AM
Comment effectuer une vérification de la signature numérique avec Debian OpenSSL
Apr 13, 2025 am 11:09 AM
En utilisant OpenSSL pour la vérification de la signature numérique sur Debian System, vous pouvez suivre ces étapes: Préparation à installer OpenSSL: Assurez-vous que votre système Debian a installé OpenSSL. Si vous n'êtes pas installé, vous pouvez utiliser la commande suivante pour l'installer: SudoaptupDaSudoaptinInStallOpenssl pour obtenir la clé publique: la vérification de la signature numérique nécessite la clé publique du signataire. En règle générale, la clé publique sera fournie sous la forme d'un fichier, comme public_key.pe
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
