
 Périphériques technologiques
IA
Le secret du « shell » domestique ChatGPT a maintenant été découvert
Périphériques technologiques
IA
Le secret du « shell » domestique ChatGPT a maintenant été découvert
Le secret du « shell » domestique ChatGPT a maintenant été découvert


"iFlytek couvre ChatGPT!" "Baidu Wenxin utilise un mot pour dissimuler Stable Diffusion!" "Le grand modèle de SenseTime est en fait plagié!"...
Ce n'est pas une ou deux fois que le monde extérieur remet en question la production nationale. grands modèles.
L'explication de ce phénomène par les initiés de l'industrie est qu'il existe une réelle pénurie d'ensembles de données chinois de haute qualité. Lors de la formation des modèles, ne peut utiliser que les ensembles de données annotés en langue étrangère achetés pour « agir comme une aide étrangère » . . Si l’ensemble de données utilisé pour la formation tombe en panne, des résultats similaires seront générés, conduisant à un propre incident.
Entre autres méthodes, l'utilisation de grands modèles existants pour aider à générer des données de formation est sujette à un nettoyage insuffisant des données. Seule la formation de grands modèles clairsemés n'est pas une solution à long terme.
Un consensus se forme progressivement dans l'industrie :
La route vers l'AGI continuera d'imposer des exigences extrêmement élevées en matière de quantité et de qualité des données.
La situation actuelle exige qu'au cours des 2 derniers mois, de nombreuses équipes nationales aient successivement publié des ensembles de données chinois open source En plus des ensembles de données généraux, il existe également des ensembles de données chinois open source spéciaux publiés pour des domaines verticaux tels que. programmation et soins médicaux.
Des ensembles de données de haute qualité sont disponibles, mais peu nombreux.
Les nouvelles avancées dans les grands modèles reposent fortement sur des ensembles de données riches et de haute qualité.
Selon les « Lois de mise à l'échelle pour les modèles de langage neuronal » d'OpenAI, la loi de mise à l'échelle (loi de mise à l'échelle) proposée par les grands modèlesOn peut voir qu'une augmentation indépendante de la quantité de données d'entraînement peut améliorer l'effet du modèle pré-entraîné.
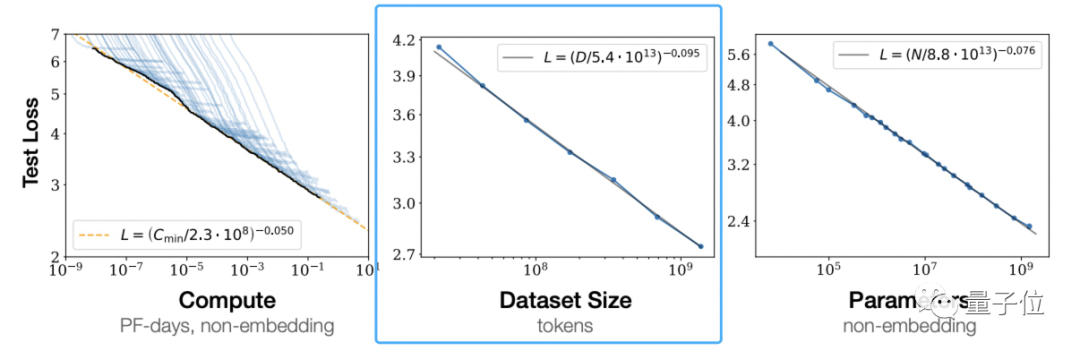
Ce n'est pas l'avis d'OpenAI.
DeepMind a également souligné dans le document sur le modèle Chinchilla que la plupart des grands modèles précédents n'étaient pas suffisamment formés, et a également proposé la formule de formation optimale, qui est devenue une norme reconnue dans l'industrie.
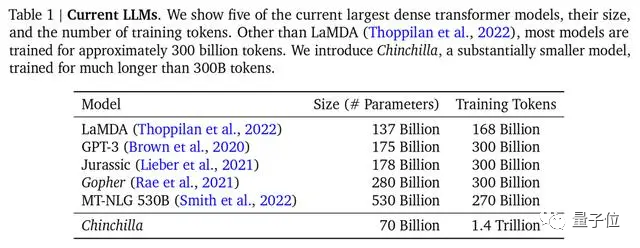
△Le grand modèle grand public, Chinchilla, a le moins de paramètres mais la formation la plus suffisante
Cependant, les ensembles de données grand public utilisés pour la formation sont principalement en anglais, telles que Common Crawl , BooksCorpus, WiKipedia, ROOT, etc., les données chinoises Common Crawl les plus populaires ne représentent que 4,8 %.
Quelle est la situation avec l’ensemble de données chinois ?
Il n'existe pas d'ensembles de données publics - ceci est confirmé par Qubits de Zhou Ming, fondateur et PDG de Lanzhou Technology et l'un des Chinois les plus accomplis dans le domaine de la PNL aujourd'hui - tels que les ensembles de données d'entités nommées MSRA-NER, Weibo- NER, etc. Il existe également CMRC2018, CMRC2019, ExpMRC2022, etc. qui peuvent être trouvés sur GitHub, mais le nombre global est une goutte d'eau dans l'océan par rapport à l'ensemble de données anglais.
Et certains d'entre eux sont anciens et ne connaissent peut-être pas les derniers concepts de recherche en PNL (les recherches liées aux nouveaux concepts n'apparaissent qu'en anglais sur arXiv).
Bien qu'il existe des ensembles de données chinoises de haute qualité, ils sont peu nombreux et difficiles à utiliser. Il s'agit d'une situation grave à laquelle toutes les équipes menant des recherches sur des modèles à grande échelle doivent faire face. Lors d'un précédent forum du Département d'électronique de l'Université Tsinghua, Tang Jie, professeur au Département d'informatique de l'Université Tsinghua, a déclaré que lors de la préparation des données pour la pré-formation du modèle ChatGLM-130B de 100 milliards de dollars, il était confronté à la situation qu'après avoir nettoyé les données chinoises, la quantité utilisable était inférieure à 2 To.
Il est urgent de remédier au manque d’ensembles de données de haute qualité dans le monde chinois.
Une des solutions efficaces consiste à utiliser directement les données anglaises pour entraîner de grands modèles.
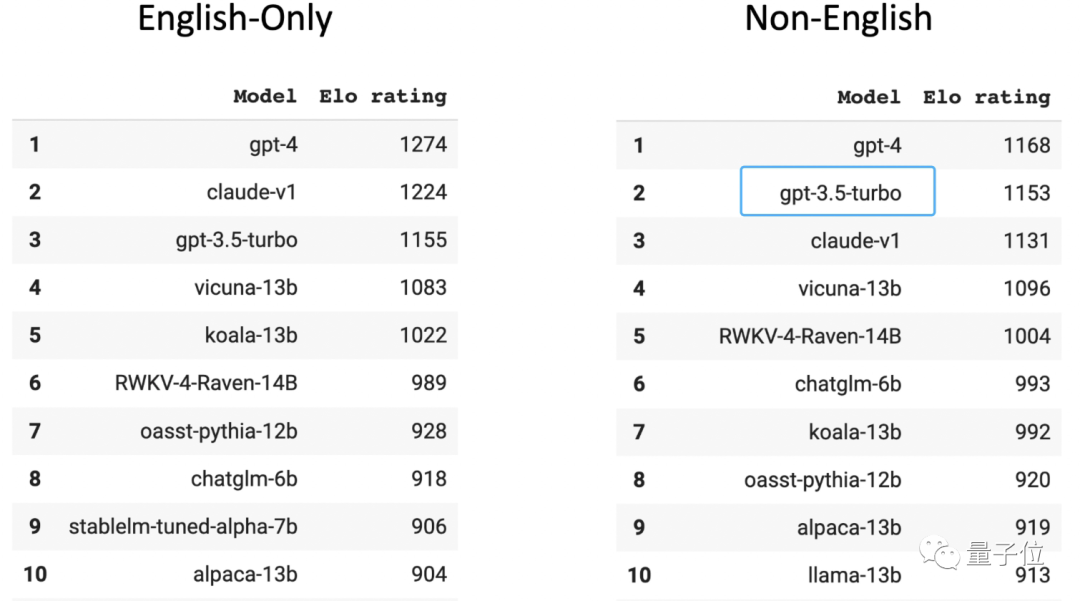
Dans la liste Chatbot Arena des arènes anonymes à grande échelle évaluées par des joueurs humains, GPT-3.5 se classe deuxième dans le classement non anglais (le premier est GPT-4). Il faut savoir que 96 % des données de formation GPT-3.5 sont en anglais, hors autres langues, la quantité de données chinoises utilisées pour la formation est si petite qu'elle peut être calculée par « n millièmes ».
Un doctorant dans une grande équipe liée aux modèles dans l'une des 3 meilleures universités de Chine a révélé que si cette méthode est adoptée et qu'elle n'est pas trop gênante, on peut même connecter un logiciel de traduction au modèle pour convertir toutes les langues en anglais, puis affichez le modèle Convertir en chinois et retournez à l'utilisateur.
Cependant, le grand modèle alimenté de cette manière pense toujours en anglais. Lorsqu'il est confronté à du contenu présentant des caractéristiques de la langue chinoise telles que la réécriture d'idiomes, la compréhension familière et la réécriture d'articles, il n'est souvent pas bien géré, ce qui entraîne des erreurs de traduction ou des erreurs culturelles potentielles. déviations.
Une autre solution consiste à collecter, nettoyer et étiqueter le corpus chinois, créer un nouvel ensemble de données chinoises de haute qualité et à le fournir à de grands modèles.
Les ensembles de données open source récoltent du bois de chauffage
Après avoir remarqué la situation actuelle, de nombreuses grandes équipes de modèles nationaux ont décidé d'emprunter la deuxième voie et ont commencé à utiliser des bases de données privées pour créer des ensembles de données.
Baidu dispose de données écologiques de contenu, Tencent de données de comptes publics, Zhihu de données de questions-réponses et Alibaba de données de commerce électronique et de logistique.
Avec différentes données privées accumulées, il est possible d'établir des barrières d'avantages de base dans des scénarios et des domaines spécifiques. Une collecte, un tri, un filtrage, un nettoyage et un étiquetage stricts de ces données peuvent garantir l'efficacité et l'exactitude du modèle formé.
Et ces grandes équipes modèles dont les avantages en matière de données privées ne sont pas si évidents ont commencé à explorer les données sur l'ensemble du réseau (il est prévisible que la quantité de données d'exploration sera très importante).
Afin de créer le grand modèle Pangu, Huawei a exploré 80 To de texte sur Internet et l'a finalement nettoyé dans un ensemble de données chinoises de 1 To ; l'ensemble de données chinoises utilisé pour la formation Inspur Source 1.0 a atteint 5 000 Go (par rapport aux données de formation du modèle GPT3). ensemble de 570 Go); récemment, le grand modèle Tianhe Tianyuan publié est également le résultat de la collecte et de l'organisation de données Web mondiales par le Tianjin Supercomputing Center, ainsi que de l'inclusion de diverses données de formation open source et d'ensembles de données de terrain professionnelles.
Dans le même temps, au cours des 2 derniers mois, il y a eu un phénomène de personnes ramassant du bois de chauffage pour les ensembles de données chinois -
De nombreuses équipes ont successivement publié des ensembles de données chinoises open source pour compenser les lacunes ou les déséquilibres de l'actuel. Ensembles de données open source chinois.
Certains d'entre eux sont organisés comme suit :
- CodeGPT : ensemble de données de conversation liées au code généré par GPT et GPT ; l'institution derrière cela est l'Université de Fudan.
- CBook-150k : Une collection de livres de corpus chinois, comprenant des méthodes de téléchargement et d'extraction de 150 000 livres chinois, couvrant de nombreux domaines tels que les sciences humaines, l'éducation, la technologie, l'armée, la politique, etc. L'organisation derrière cela est l'Université de Fudan.
- RefGPT : Afin d'éviter le coût coûteux de l'annotation manuelle, nous proposons une méthode pour générer automatiquement des dialogues basés sur des faits et divulguer une partie de nos données, dont 50 000 dialogues multi-tours chinois derrière cela se trouvent des experts de ; Praticiens de la PNL à l'Université Jiao Tong de Shanghai et à Hong Kong dans des institutions telles que les universités polytechniques.
- COIG : Le nom complet est « Ensemble de données d'instructions ouvertes communes de Chine ». Il s'agit d'un corpus de réglage d'instructions plus vaste et plus diversifié, et sa qualité est assurée par une vérification manuelle, notamment l'Institut d'artificiel de Pékin ; Intelligence, Université de Sheffield, Université du Michigan, Dartmouth College, Université du Zhejiang, Université Beihang, Université Carnegie Mellon.
- Awesome Chinese Legal Resources : ressources de données juridiques chinoises, collectées et organisées par l'Université Jiao Tong de Shanghai.
- Huatuo : Un ensemble de données d'instructions médicales chinoises construit via le graphique des connaissances médicales et l'API GPT3.5. Sur cette base, les instructions de LLaMA ont été affinées pour améliorer l'effet questions et réponses de LLaMA dans le domaine médical. domaine ; la partie open source du projet est le Harbin Institute of Technology.
- Baize : utilisez un petit nombre de « questions de départ » pour permettre à ChatGPT de discuter avec lui-même et de les collecter automatiquement dans un ensemble de données de conversation à plusieurs tours de haute qualité ; coopère avec l'Université Sun Yat-sen et l'équipe MSRA. Rendre l'ensemble de données collecté à l'aide de cette méthode open source. Lorsque de plus en plus d'ensembles de données chinois sont open source et mis sous les projecteurs, l'attitude de l'industrie est celle de l'accueil et de la joie. Par exemple, l'attitude exprimée par Zhang Peng, fondateur et PDG de Zhipu AI :
En bref, ça évolue dans le bon sens, n’est-ce pas ?Il est à noter qu'en plus des données de pré-formation, les données de feedback humain sont également indispensables à ce stade.
Des exemples prêts à l'emploi sont devant vous :
Par rapport à GPT-3, le buff important de la superposition ChatGPT est d'utiliser le RLHF
(Human Feedback Reinforcement Learning)pour générer des données étiquetées de haute qualité pour un réglage fin, réaliser de grands modèles Vers un alignement avec l'intention humaine. Le moyen le plus direct de fournir un feedback humain est de dire à l'assistant IA "votre réponse est fausse", ou d'aimer ou de ne pas aimer directement à côté de la réponse générée par l'assistant IA.
 Vous pouvez d'abord collecter une vague de commentaires des utilisateurs et laisser la boule de neige commencer. C'est l'une des raisons pour lesquelles tout le monde se précipite pour sortir de grands modèles.
Vous pouvez d'abord collecter une vague de commentaires des utilisateurs et laisser la boule de neige commencer. C'est l'une des raisons pour lesquelles tout le monde se précipite pour sortir de grands modèles.
Désormais, les produits nationaux de type ChatGPT, de Baidu Wenxinyiyan, Fudan MOSS à Zhipu ChatGLM, offrent tous des options de commentaires.
Mais aux yeux de la plupart des utilisateurs expérimentés, l'attribut le plus important de ces produits grand modèle est le « jouet ».
Lorsque vous rencontrez une réponse incorrecte ou insatisfaisante, vous choisirez de fermer directement l'interface de dialogue, ce qui n'est pas propice à la collecte de retours humains par le grand modèle derrière elle.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 J'ai essayé le codage d'ambiance avec Cursor Ai et c'est incroyable!
Mar 20, 2025 pm 03:34 PM
J'ai essayé le codage d'ambiance avec Cursor Ai et c'est incroyable!
Mar 20, 2025 pm 03:34 PM
Le codage des ambiances est de remodeler le monde du développement de logiciels en nous permettant de créer des applications en utilisant le langage naturel au lieu de lignes de code sans fin. Inspirée par des visionnaires comme Andrej Karpathy, cette approche innovante permet de dev
 Top 5 Genai Lunets de février 2025: GPT-4.5, Grok-3 et plus!
Mar 22, 2025 am 10:58 AM
Top 5 Genai Lunets de février 2025: GPT-4.5, Grok-3 et plus!
Mar 22, 2025 am 10:58 AM
Février 2025 a été un autre mois qui change la donne pour une IA générative, nous apportant certaines des mises à niveau des modèles les plus attendues et de nouvelles fonctionnalités révolutionnaires. De Xai's Grok 3 et Anthropic's Claude 3.7 Sonnet, à Openai's G
 Comment utiliser YOLO V12 pour la détection d'objets?
Mar 22, 2025 am 11:07 AM
Comment utiliser YOLO V12 pour la détection d'objets?
Mar 22, 2025 am 11:07 AM
Yolo (vous ne regardez qu'une seule fois) a été un cadre de détection d'objets en temps réel de premier plan, chaque itération améliorant les versions précédentes. La dernière version Yolo V12 introduit des progrès qui améliorent considérablement la précision
 Chatgpt 4 o est-il disponible?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 o est-il disponible?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 est actuellement disponible et largement utilisé, démontrant des améliorations significatives dans la compréhension du contexte et la génération de réponses cohérentes par rapport à ses prédécesseurs comme Chatgpt 3.5. Les développements futurs peuvent inclure un interg plus personnalisé
 Google & # 039; s Gencast: Prévision météorologique avec Mini démo Gencast
Mar 16, 2025 pm 01:46 PM
Google & # 039; s Gencast: Prévision météorologique avec Mini démo Gencast
Mar 16, 2025 pm 01:46 PM
Gencast de Google Deepmind: une IA révolutionnaire pour les prévisions météorologiques Les prévisions météorologiques ont subi une transformation spectaculaire, passant des observations rudimentaires aux prédictions sophistiquées alimentées par l'IA. Gencast de Google Deepmind, un terreau
 Meilleurs générateurs d'art AI (gratuit & amp; payé) pour des projets créatifs
Apr 02, 2025 pm 06:10 PM
Meilleurs générateurs d'art AI (gratuit & amp; payé) pour des projets créatifs
Apr 02, 2025 pm 06:10 PM
L'article passe en revue les meilleurs générateurs d'art AI, discutant de leurs fonctionnalités, de leur aptitude aux projets créatifs et de la valeur. Il met en évidence MidJourney comme la meilleure valeur pour les professionnels et recommande Dall-E 2 pour un art personnalisable de haute qualité.
 Quelle IA est la meilleure que Chatgpt?
Mar 18, 2025 pm 06:05 PM
Quelle IA est la meilleure que Chatgpt?
Mar 18, 2025 pm 06:05 PM
L'article traite des modèles d'IA dépassant Chatgpt, comme Lamda, Llama et Grok, mettant en évidence leurs avantages en matière de précision, de compréhension et d'impact de l'industrie. (159 caractères)
 O1 vs GPT-4O: le nouveau modèle Openai est-il meilleur que GPT-4O?
Mar 16, 2025 am 11:47 AM
O1 vs GPT-4O: le nouveau modèle Openai est-il meilleur que GPT-4O?
Mar 16, 2025 am 11:47 AM
O1'S O1: Une vague de cadeaux de 12 jours commence par leur modèle le plus puissant à ce jour L'arrivée de décembre apporte un ralentissement mondial, les flocons de neige dans certaines parties du monde, mais Openai ne fait que commencer. Sam Altman et son équipe lancent un cadeau de don de 12 jours
