

Pourquoi Redis est-il si rapide ?

Redis est une base de données NoSQL basée sur des paires clé-valeur. La valeur de Redis peut être composée de diverses structures de données et algorithmes tels que String, hash, list, set, zset, Bitmaps, HyperLogLog, etc. Redis a de nombreuses fonctions, telles que l'expiration des clés, la publication et l'abonnement, les transactions, les scripts Lua, les sentinelles, le cluster, etc.
Selon les données de performances officielles, Redis peut exécuter des commandes à une vitesse très rapide et son QPS peut atteindre plus de 100 000. Cet article présente donc principalement où Redis est rapide. Les points principaux sont les suivants :
1. Langage de développement
Maintenant, nous utilisons tous high. langages de niveau Pour programmer, comme Java, python, etc. Vous pensez peut-être que le langage C est très ancien, mais il est vraiment utile. Après tout, le système Unix est implémenté en C, le langage C est donc un langage très proche du système d'exploitation. Redis est développé en langage C, l'exécution sera donc plus rapide.
Pour ajouter, les étudiants devraient se concentrer sur l'apprentissage du langage C car il aide à une meilleure compréhension des systèmes d'exploitation informatiques. Ne pensez pas qu'après avoir appris une langue de haut niveau, vous n'avez pas à faire attention à la couche inférieure. La dette que vous devez devra toujours être remboursée. Voici un livre plus difficile à recommander, "Compréhension approfondie des systèmes informatiques".
2. Accès à la mémoire pure
Redis utilise la mémoire pour stocker toutes les données, il n'est donc pas nécessaire de lire les données du disque pendant le fonctionnement normal . La synchronisation des non-données est effectuée, le nombre d'E/S est donc 0. Le temps de réponse de la mémoire est d'environ 100 nanosecondes, ce qui constitue une base importante pour la vitesse rapide de Redis. Regardez d'abord la vitesse du CPU :
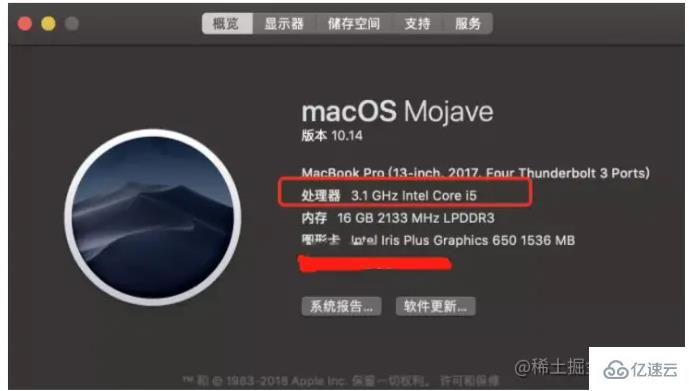
En prenant mon ordinateur comme exemple, sa fréquence principale est de 3,1G, ce qui signifie qu'il peut exécuter 31 opérations par seconde Des milliards d'instructions. La vitesse de traitement de la vision du monde du processeur est très lente. En comparaison, la mémoire est 100 fois plus lente et le disque est 1 000 000 fois plus lent. Pensez-vous que c'est rapide ?
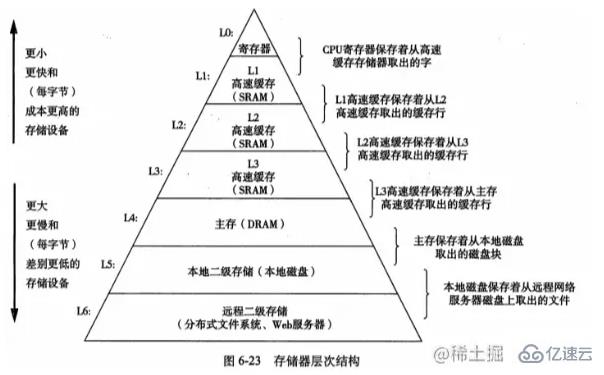
J'ai emprunté une image de "Compréhension approfondie des systèmes informatiques", qui montre une hiérarchie de mémoire typique au niveau de la couche L0, le CPU peut y accéder en un cycle d'horloge, et la SRAM. Le printemps du cache continue. Au début, ils étaient accessibles en quelques cycles d'horloge du processeur, puis dans la mémoire principale basée sur la DRAM, ils étaient accessibles en dizaines, voire centaines de cycles d'horloge.
3. Un seul fil
Un seul fil peut simplifier la mise en œuvre de l'algorithme, mais la mise en œuvre des structures de données concurrentes est non seulement difficile mais aussi lourde à tester. Dans le développement côté serveur, les verrous et la commutation de threads nuisent généralement aux performances, et l'utilisation d'un seul thread peut éviter la consommation qu'ils entraînent. Bien entendu, le single threading aura aussi ses défauts, ce qui est aussi le cauchemar de Redis : le blocage. Si l'exécution d'une commande est trop longue, d'autres commandes seront bloquées, ce qui est très fatal pour Redis, Redis est donc une base de données pour des scénarios d'exécution rapides.
En plus de Redis, Node.js est également monothread, et Nginx est également monothread, mais ce sont tous deux des modèles de serveurs hautes performances.
4. Mécanisme de multiplexage d'E/S multicanal non bloquant
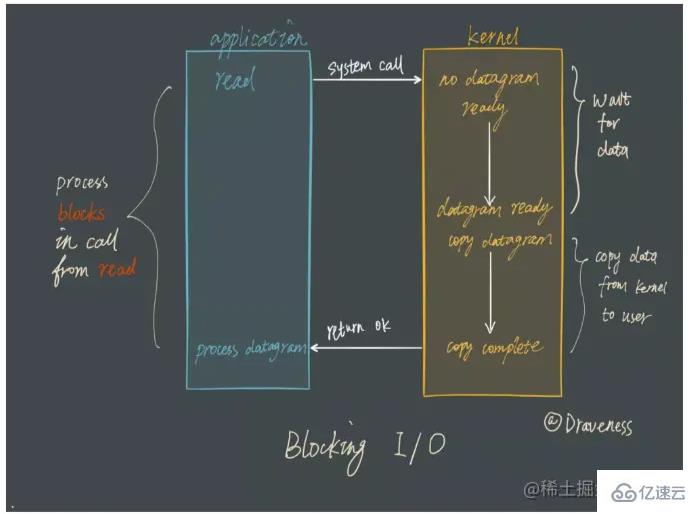
Avant cela, parlons du blocage traditionnel des E/S. Comment ça fonctionne : lors de l'utilisation de read ou write pour lire ou écrire un descripteur de fichier (File Descriptor FD), si les données ne sont pas reçues, le thread sera suspendu jusqu'à ce que les données soient reçues.
Bien que le modèle de blocage soit facile à comprendre, il ne sera pas utilisé lorsque plusieurs tâches client doivent être traitées.
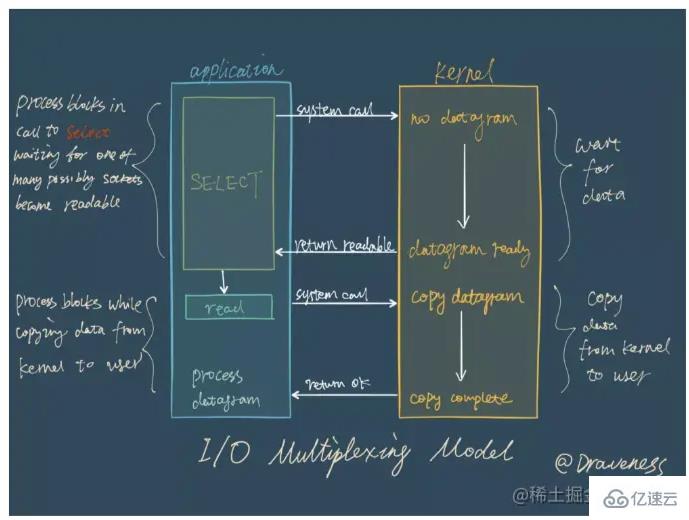
Le multiplexage d'E/S signifie en réalité que la gestion de plusieurs connexions peut se faire dans le même processus. Le multicanal fait référence aux connexions réseau, le multiplexage n'est que le même fil. Dans les services réseau, le rôle du multiplexage d'E/S est de notifier simultanément le code métier de plusieurs événements de connexion. La méthode de traitement est déterminée par le code métier.
Dans le modèle de multiplexage d'E/S, l'appel de fonction le plus important est la fonction de multiplexage d'E/S. Cette méthode peut surveiller la lecture et l'écriture de plusieurs descripteurs de fichiers (fd) en même temps. dans ce cas, lorsque certains fds peuvent être lus/écrits, cette méthode renverra le nombre de fds lisibles/inscriptibles.
Redis utilise epoll comme implémentation de la technologie de multiplexage d'E/S, et le propre modèle de traitement d'événements de Redis combine la lecture et l'écriture d'epoll, la fermeture, etc. le tout converti en événements, afin de ne pas perdre trop de temps en E/S réseau. Réalisez la surveillance de plusieurs lectures et écritures FD pour améliorer les performances.
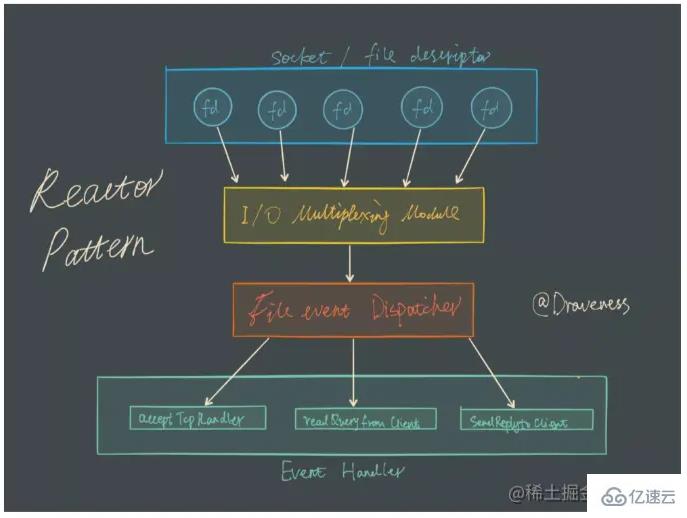
Donnons un exemple frappant. Par exemple, un serveur TCP gère 20 sockets clients.
Un plan : Traitement séquentiel. Si la première socket est lente à lire les données à cause de la carte réseau, une fois bloquée, tout le reste sera chamboulé.
Plan B : Créez un sous-processus de clonage pour chaque demande de socket. Sans oublier que chaque processus consomme beaucoup de ressources système. Un simple changement de processus suffit à fatiguer le système d'exploitation.
Schéma C (modèle de réutilisation des E/S, epoll) : Enregistrez le fd correspondant au socket utilisateur dans epoll (en fait, ce qui est transmis entre le serveur et le système d'exploitation n'est pas le fd du socket mais la structure de données de fd_set), puis epoll indique uniquement que pour les sockets qui doivent être lues/écrites, seuls les fds de socket actifs et changeants doivent être traités.
De cette façon, l'ensemble du processus ne sera bloqué que lorsque epoll est appelé, et l'envoi et la réception de messages clients ne seront pas bloqués.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Utilisez l'outil de ligne de commande redis (Redis-CLI) pour gérer et utiliser Redis via les étapes suivantes: Connectez-vous au serveur, spécifiez l'adresse et le port. Envoyez des commandes au serveur à l'aide du nom et des paramètres de commande. Utilisez la commande d'aide pour afficher les informations d'aide pour une commande spécifique. Utilisez la commande QUIT pour quitter l'outil de ligne de commande.
 Comment configurer le temps d'exécution du script LUA dans Centos Redis
Apr 14, 2025 pm 02:12 PM
Comment configurer le temps d'exécution du script LUA dans Centos Redis
Apr 14, 2025 pm 02:12 PM
Sur CentOS Systems, vous pouvez limiter le temps d'exécution des scripts LUA en modifiant les fichiers de configuration Redis ou en utilisant des commandes Redis pour empêcher les scripts malveillants de consommer trop de ressources. Méthode 1: Modifiez le fichier de configuration Redis et localisez le fichier de configuration Redis: le fichier de configuration redis est généralement situé dans /etc/redis/redis.conf. Edit Fichier de configuration: Ouvrez le fichier de configuration à l'aide d'un éditeur de texte (tel que VI ou NANO): Sudovi / etc / redis / redis.conf Définissez le délai d'exécution du script LUA: Ajouter ou modifier les lignes suivantes dans le fichier de configuration pour définir le temps d'exécution maximal du script LUA (unité: millisecondes)
