
 base de données
tutoriel mysql
MySQL avancé DML, recherche par pagination, contraintes SQL et méthodes de fonctionnement multi-tables
base de données
tutoriel mysql
MySQL avancé DML, recherche par pagination, contraintes SQL et méthodes de fonctionnement multi-tables
MySQL avancé DML, recherche par pagination, contraintes SQL et méthodes de fonctionnement multi-tables


1. Qu'est-ce que DML, et les opérations de base de DML, l'opération de mise à jour des colonnes et des lignes du tableau
Opérations de modification pour les colonnes
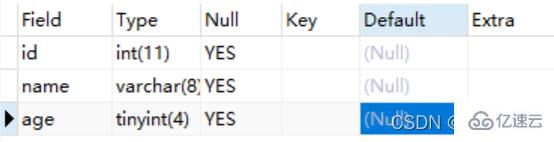
#首先简单的创建一个student表为后序操作做准备 use test; create table student ( id int, name varchar(8), age tinyint ) engine = innodb default charset = utf8mb4; desc student;

-
Ajouter une nouvelle colonne, format : modifier le nom de la table ajouter un nouveau nom de colonne, type de données (longueur) ; (longueur);
alter table student add addr varchar(20); #新增一个addr列出来
Modifier le nom de la colonne, le format : modifier le nom de la table changer le nom de la colonne nouveau nom de la colonne type de données du nouveau nom de la colonne (longueur);
alter table student modify addr varchar(15); #修改student表中addr列的数据类型 (长度修改) alter table student modify addr char(20); #修改student表中addr列的数据类型 (类型修改为char(20))
-
Supprimer. la colonne spécifiée, format : modifier le nom de la table, déposer le nom de la colonne ;
alter table student change addr stu_addr varchar(20); # change 相比 modify 而言功能更加强大可以修改列名字. # modify不可以修改列名
Il n'est pas recommandé d'utiliser les opérations de modification ci-dessus sur la structure des colonnes de la table, car les bases de données de nombreuses entreprises sont très volumineuses . Modifier une colonne de données n'est pas une mince affaire. Si la modification n'est pas bien effectuée, ce sera terrible si les données sont perdues
- Visant diverses opérations sur les lignes et les enregistrements du tableau (ajouter, supprimer, modifier, vérifier)
- Méthode 1, insérer dans le champ spécifié, format : insérer dans le nom de la table (champ 1, champ 2, ...) valeurs ( valeur 1, valeur 2, .. .); J'appelle cette méthode l'opération d'insertion des champs spécifiés. Les champs et les affectations doivent correspondre un à un
alter table student drop stu_addr;
# 删除student表中的stu_addr列
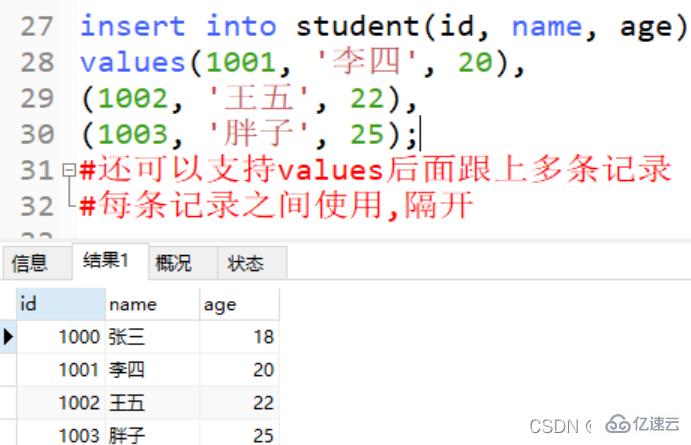
Copier après la connexioninsert into student(id, name, age) values(1000, '张三', 18);
# 向student表中插入一条id 为1000 name 为张三, age 18的记录
Copier après la connexion
alter table student drop stu_addr; # 删除student表中的stu_addr列
insert into student(id, name, age) values(1000, '张三', 18); # 向student表中插入一条id 为1000 name 为张三, age 18的记录
Méthode 2, insérer des valeurs dans tous les champs, format : insérer dans les valeurs du nom de la table (valeur 1, valeur 2, ...);
- signifie que par défaut, tous les champs sont insérés séquentiellement et vous n'avez pas besoin d'écrire le field
insert into student(id, name, age) values(1001, '李四', 20), (1002, '王五', 22), (1003, '胖子', 25); #还可以支持values后面跟上多条记录 #每条记录之间使用,隔开
Copier après la connexionRésumé des précautions de l'opération d'insertion :
 La valeur doit correspondre au champ, avec le même numéro et le même type
La valeur doit correspondre au champ, avec le même numéro et le même type
- La taille des données du la valeur doit être dans la plage de longueur spécifiée du champ
- Lors de la modification de la valeur, elle ne peut pas dépasser la plage de longueur du champ

Supprimer l'enregistrement de la table
Format de grammaire : supprimer du nom de la table où condition
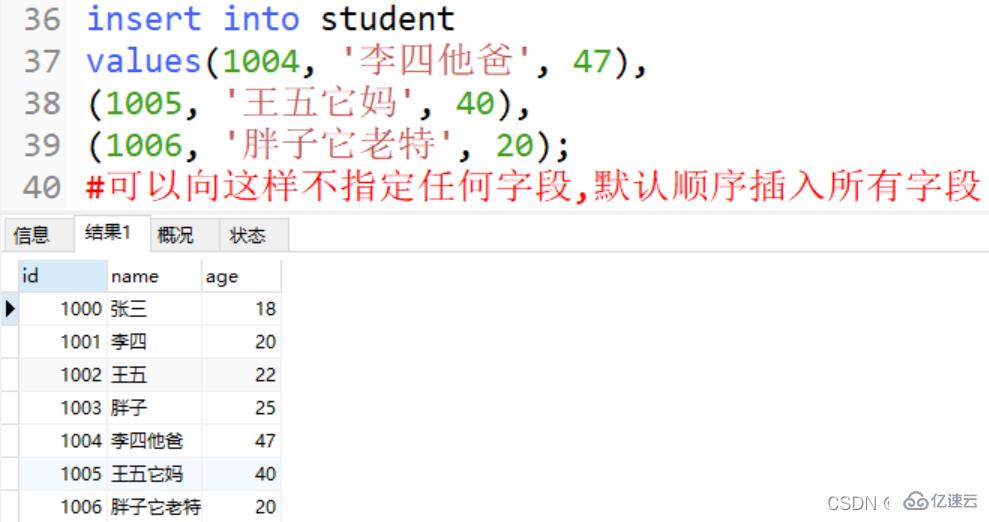
insert into student values(1004, '李四他爸', 47), (1005, '王五它妈', 40), (1006, '胖子它老特', 20); #可以向这样不指定任何字段,默认顺序插入所有字段
Copier après la connexionupdate student set name = '胖子他爹' where id = 1005; # 跟新student表中id = 1005这条记录的name为胖子他爹
Copier après la connexionCe qu'il faut bien pratiquer, c'est l'addition ; , opérations de suppression, de modification et d'interrogation des enregistrements, car il y a des modifications, des suppressions et des ajouts d'enregistrements spécifiques dans la base de données. Les opérations d'attente sont très courantes
- Résoudre le problème de la recherche par pagination
Qu'est-ce que ce qui précède ? Je crois que tous ceux qui aiment rechercher des enregistrements ou faire des achats le connaissent. Cette façon d'afficher les enregistrements consiste à afficher les enregistrements par pagination)
Le format des requêtes de pagination est : SELECT *. FROM table_name LIMIT start_row, page_size;
update student set name = '我是你爸', age = 100 where id = 1005; # 跟新student表中id = 1005这条记录的name为我是你爸, age为100
pose un problème, à ce stade, nous connaissons tous les données de chaque page. Le nombre d'éléments et la taille de la page sont fixes. La question est de savoir si nous déterminons startRow en fonction. sur le nombre de pages que nous devons interroger ?-- 后台计算出页码、页数(页大小)
-- 分页需要的相关数据结果分析如下,
-- 注意:下列是伪代码不用于执行
int curPage = 2; -- 当前页数
int pageSize = 5; -- 每页显示数量
int startRow = (curPage - 1) * pageSize; -- 当前页, 记录开始的位置(行数)计算
Copier après la connexion其实我们仅仅只是需要知道当前页数 (页数 - 1) * pageSize; 即可获知startRow
三. SQL约束详解
约束的定义
竟然需要学一下约束,首先我们先搞定啥叫约束,其实还蛮简单的,约束就是⼀种限制条件, 让你不能超出这个控制范围
而在数据库中的约束, 就是指 表中的数据内容 不能胡乱填写, 必须按照要求填写. 好保证数据的完整性与 安全性
主键约束 PRIMARY KEY 约束
啥是主键约束:不为空的唯一约束. 主键约束不为NULL, 且唯一标识一条记录, 每一个表几乎都必须存在这样一个约束条件
添加主键约束
方式1:创建表时,在字段描述处,声明指定字段为主键:
格式: 字段名 数据类型[长度] primary key;
create table user_table(
id int primary key, #添加主键约束
name varchar(10),
age tinyint
) engine = innodb charset = utf8mb4;
Copier après la connexion主键约束唯一标识记录, 且不可以为空
insert into user_table
values(1001, '翠花', 18);
#插入第一条记录翠花是没有问题的
insert into user_table
values(1001, '王五', 20);
#插入这条记录应当是报错, 重复插入主键了
# [Err] 1062 - Duplicate entry '1001' for key 'PRIMARY'
# 重复加入1001 作为主键
Copier après la connexion
-- 后台计算出页码、页数(页大小) -- 分页需要的相关数据结果分析如下, -- 注意:下列是伪代码不用于执行 int curPage = 2; -- 当前页数 int pageSize = 5; -- 每页显示数量 int startRow = (curPage - 1) * pageSize; -- 当前页, 记录开始的位置(行数)计算
其实我们仅仅只是需要知道当前页数 (页数 - 1) * pageSize; 即可获知startRow
约束的定义
竟然需要学一下约束,首先我们先搞定啥叫约束,其实还蛮简单的,约束就是⼀种限制条件, 让你不能超出这个控制范围
而在数据库中的约束, 就是指 表中的数据内容 不能胡乱填写, 必须按照要求填写. 好保证数据的完整性与 安全性
主键约束 PRIMARY KEY 约束
啥是主键约束:不为空的唯一约束. 主键约束不为NULL, 且唯一标识一条记录, 每一个表几乎都必须存在这样一个约束条件
方式1:创建表时,在字段描述处,声明指定字段为主键:
格式: 字段名 数据类型[长度] primary key;
create table user_table( id int primary key, #添加主键约束 name varchar(10), age tinyint ) engine = innodb charset = utf8mb4;
主键约束唯一标识记录, 且不可以为空
insert into user_table values(1001, '翠花', 18); #插入第一条记录翠花是没有问题的 insert into user_table values(1001, '王五', 20); #插入这条记录应当是报错, 重复插入主键了 # [Err] 1062 - Duplicate entry '1001' for key 'PRIMARY' # 重复加入1001 作为主键
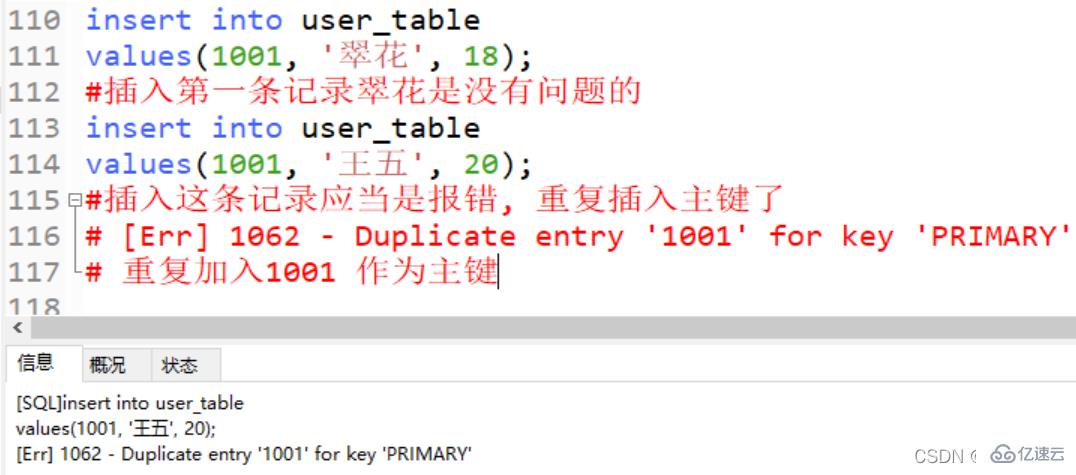
主键约束不可以为空 (区别unique 主键)
insert into user_table values(null, '大胖', 30); # 区别唯一约束, 主键约束不可以为null #[Err] 1048 - Column 'id' cannot be null
方式2:创建表时,在constraint约束区域,声明指定字段为主键
语法形式: [constraint 名称] primary key (字段列表)
出现的必要是什么? 这种方式出现的必要就是可以添加联合主键, 具体联合主键的使用回在下文中的中间表处应用, 此处我们先获悉如何创建
create table persons ( pid int, lastname varchar(255), firstname varchar(255), address varchar(255), constraint persons_pk primary key(lastname, firstname) #通过constraint 增添联合主键 ) engine = innodb default charset = utf8mb4;
思索一下为何需要出现联合主键这一约束, 主键必须是标识不同的记录, 有些时候存在这样一种情况, 我们需要用 姓名 + 性别, 来辨识不同的对象一样 (不巧存在男生女生都叫王玉杰的情况, 仅姓名无法区分, 此时可以联合其他字段共同构成主键来约束标识)
方式三:创建表之后,通过修改表结构,声明指定字段为主键:
格式: altertable 表名 add [ constraint 名称] primary key (字段列表)
alter table user_table add constraint name_id_pk primary key(name, id); # 向user_table表中增加一个name + id的联合主键
删除主键约束
格式: alter table 表名 drop primary key;
alter table user_table drop primary key; # 删除user_table表中的主键约束
自动增长列 (介绍主键约束如何离得开它)
我们通常希望在每次插⼊新记录时,数据库自动生成字段的值
又特别是主键字段, 如果仅作为标记记录,完全没必要我们设置值呀
我们可以在表中使用 auto_increment(自动增长列)关键字,自动增长列类型必须是整形,自动增长 列必须为键(通常是用于主键)
格式: 字段名 整数类型[长度][约束] auto_increment
create table test( id int primary key auto_increment, # 添加一个主键约束, 设置自动增长. 默认增长为1 age tinyint, name varchar(20) ) engine = innodb default charset = utf8mb4;
insert into test values(null, 18, '小呼噜'); # 我们设置了主键自动递增可以不再需要传入主键字段 # 或者主键传入null 他会自动设置从1开始默认增量1
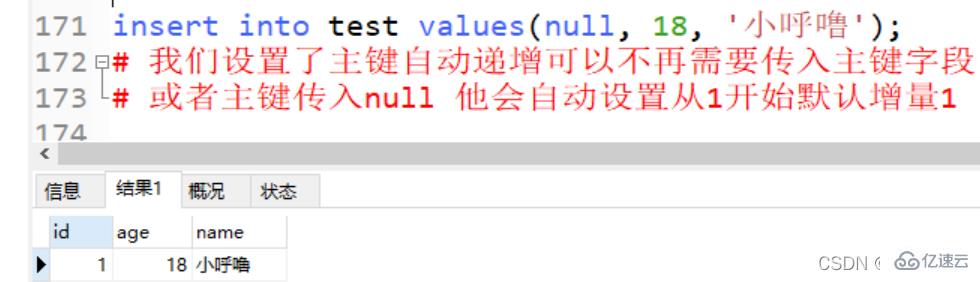
亦或是 insert into 的时候不传入任何东西都OK, null也可以不用传入
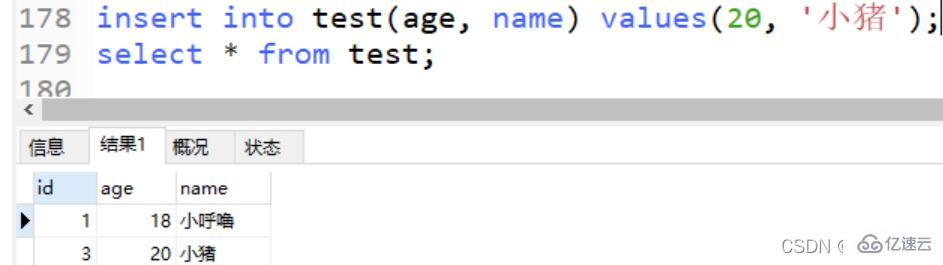
不过如果想要同上述这般使用我们必须注意的就是要指定字段插入, 不然默认是三个都要给值, 我们指定插入字段的时候可以无需指定id, 有点像默认值
非空约束
NOT NULL 约束: 列不接受 NULL 值。 要求字段始终包含值。如果没有向字段添加值,则无法插入新记录或更新记录
添加非空约束
格式: 字段名 数据类型[长度] NOT NULL
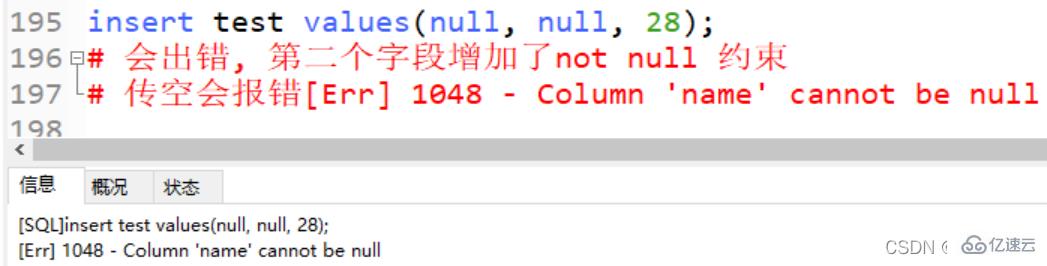
drop table test; create table test( id int primary key auto_increment, name varchar(10) not null,#设置非null 插入数据不能传入null age tinyint ) engine = innodb auto_increment = 10 default charset = utf8mb4; # 我们还可以向这般指定auto_increment的值
insert test values(null, null, 28); # 会出错, 第二个字段增加了not null 约束 # 传空会报错[Err] 1048 - Column 'name' cannot be null
删除非空约束
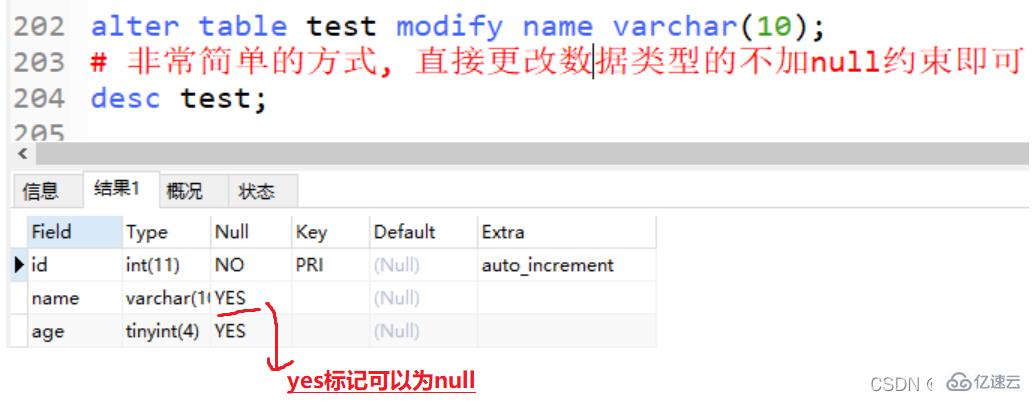
格式: alter table 表名 modify 字段名 数据类型[长度]
alter table test modify name varchar(10); # 非常简单的方式, 直接更改数据类型的不加null约束即可 desc test;
唯一约束
unique 约束: 指定列的值 不能重复.
注意:
唯一性约束和主键约束都为列提供了独一无二的保证。PRIMARY KEY 是自动定义的 UNIQUE 约束。
每个表可以有多个 UNIQUE 约束,但是每个表只能有⼀个 PRIMARY KEY 约束。
UNIQUE 不限制 null 值 出现的次数
添加唯⼀约束
与主键添加方式相同,共有3种. 我在此处举几个例子就是
drop table test; create table test ( id int unique, # 添加一个唯一约束 name varchar(20) not null, age tinyint ) engine = innodb default charset = utf8mb4; desc test;
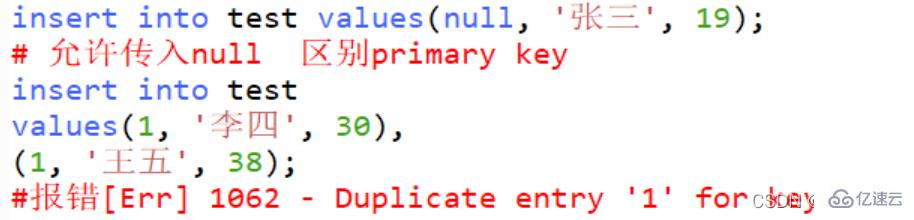
insert into test values(null, '张三', 19); # 允许传入null 区别primary key insert into test values(1, '李四', 30), (1, '王五', 38); #报错[Err] 1062 - Duplicate entry '1' for key 'id'
格式2: [constraint 名称] UNIQUE (字段) 对应primary key 方式2
格式3: ALTER TABLE 表名 ADD [CONSTRAINT 名称] UNIQUE (字段) 对比方式3
删除唯一约束, 方式一样跟刚刚删除主键约束
默认约束
default 约束: 用于指定字段默认值。如果插入记录时某些字段没有赋值,则会自动填充默认值
添加默认约束,在创建表时候添加 格式: 字段名 数据类型[长度] DEFAULT 默认值
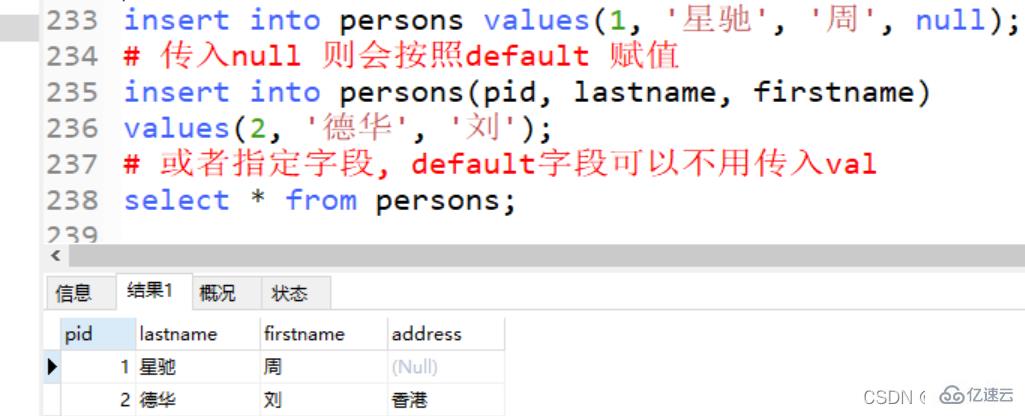
CREATE TABLE persons ( pid INT, lastname VARCHAR(255), firstname VARCHAR(255), address VARCHAR(255) DEFAULT '香港' -- 添加默认约束 )engine = innodb default charset = utf8mb4;
# 传入null 则会按照default 赋值 insert into persons(pid, lastname, firstname) values(2, '德华', '刘'); # 或者指定字段, default字段可以不用传入val
小结
关于表的列操作 (增删改查) 开头alter 关键字 后面add modify change drop
alter table 表名 add 列名 类型(长度) 新增一列
alter table 表名 modify 列名 oldtype newtype 针对一列仅仅只做类型修改
alter table 表名 change old列名 new列名 oldtype newtype 针对一列可做类型 + 列明修改
alter table 表名 drop 列名; 针对一列做删除操作
关于表的记录操作 (增删改查)
insert into 表名(指定字段) values(指定值), (指定值); 指定插入字段值 (插入记录)
insert into 表名 values(所有字段顺序写入值); 按照建表字段顺序插入字段值
update 表名 set 字段 = 值 where 条件指定记录 更改记录
delete from 表名 where 条件指定记录 从指定表中删除满足条件的记录
关于各种约束的学习
约束就是一种限制
主键约束 (相当于是 unique 约束 + 非 null约束的结合), 用来唯一标识表中的记录
unique 约束, 也是保持不可重复, 列字段值唯一, 但是允许为null
非 null 约束. 就是不允许为null 不可以传入null作为参数
默认约束, 如果传入null 就默认字段值为初始默认值
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL: la facilité de gestion des données pour les débutants
Apr 09, 2025 am 12:07 AM
MySQL convient aux débutants car il est simple à installer, puissant et facile à gérer les données. 1. Installation et configuration simples, adaptées à une variété de systèmes d'exploitation. 2. Prise en charge des opérations de base telles que la création de bases de données et de tables, d'insertion, d'interrogation, de mise à jour et de suppression de données. 3. Fournir des fonctions avancées telles que les opérations de jointure et les sous-questionnaires. 4. Les performances peuvent être améliorées par l'indexation, l'optimisation des requêtes et le partitionnement de la table. 5. Prise en charge des mesures de sauvegarde, de récupération et de sécurité pour garantir la sécurité et la cohérence des données.
 Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Puis-je récupérer le mot de passe de la base de données dans Navicat?
Apr 08, 2025 pm 09:51 PM
Navicat lui-même ne stocke pas le mot de passe de la base de données et ne peut récupérer que le mot de passe chiffré. Solution: 1. Vérifiez le gestionnaire de mots de passe; 2. Vérifiez la fonction "Remember Motway" de Navicat; 3. Réinitialisez le mot de passe de la base de données; 4. Contactez l'administrateur de la base de données.
 Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Comment créer Navicat Premium
Apr 09, 2025 am 07:09 AM
Créez une base de données à l'aide de NAVICAT Premium: Connectez-vous au serveur de base de données et entrez les paramètres de connexion. Cliquez avec le bouton droit sur le serveur et sélectionnez Créer une base de données. Entrez le nom de la nouvelle base de données et le jeu de caractères spécifié et la collation. Connectez-vous à la nouvelle base de données et créez le tableau dans le navigateur d'objet. Cliquez avec le bouton droit sur le tableau et sélectionnez Insérer des données pour insérer les données.
 Comment afficher le mot de passe de la base de données dans NAVICAT pour MARIADB?
Apr 08, 2025 pm 09:18 PM
Comment afficher le mot de passe de la base de données dans NAVICAT pour MARIADB?
Apr 08, 2025 pm 09:18 PM
NAVICAT pour MARIADB ne peut pas afficher directement le mot de passe de la base de données car le mot de passe est stocké sous forme cryptée. Pour garantir la sécurité de la base de données, il existe trois façons de réinitialiser votre mot de passe: réinitialisez votre mot de passe via Navicat et définissez un mot de passe complexe. Affichez le fichier de configuration (non recommandé, haut risque). Utilisez des outils de ligne de commande système (non recommandés, vous devez être compétent dans les outils de ligne de commande).
 Comment exécuter SQL dans Navicat
Apr 08, 2025 pm 11:42 PM
Comment exécuter SQL dans Navicat
Apr 08, 2025 pm 11:42 PM
Étapes pour effectuer SQL dans NAVICAT: Connectez-vous à la base de données. Créez une fenêtre d'éditeur SQL. Écrivez des requêtes ou des scripts SQL. Cliquez sur le bouton Exécuter pour exécuter une requête ou un script. Affichez les résultats (si la requête est exécutée).
 Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Comment créer une nouvelle connexion à MySQL dans Navicat
Apr 09, 2025 am 07:21 AM
Vous pouvez créer une nouvelle connexion MySQL dans NAVICAT en suivant les étapes: ouvrez l'application et sélectionnez une nouvelle connexion (CTRL N). Sélectionnez "MySQL" comme type de connexion. Entrez l'adresse Hostname / IP, le port, le nom d'utilisateur et le mot de passe. (Facultatif) Configurer les options avancées. Enregistrez la connexion et entrez le nom de la connexion.
 Navicat ne peut pas se connecter à MySQL / MARIADB / POSTRESQL et à d'autres bases de données
Apr 08, 2025 pm 11:00 PM
Navicat ne peut pas se connecter à MySQL / MARIADB / POSTRESQL et à d'autres bases de données
Apr 08, 2025 pm 11:00 PM
Raisons courantes pour lesquelles Navicat ne peut pas se connecter à la base de données et à ses solutions: 1. Vérifiez l'état d'exécution du serveur; 2. Vérifiez les informations de connexion; 3. Réglez les paramètres du pare-feu; 4. Configurer l'accès à distance; 5. Dépannage des problèmes de réseau; 6. Vérifier les autorisations; 7. Assurer la compatibilité de la version; 8. Dépannage d'autres possibilités.
 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
