

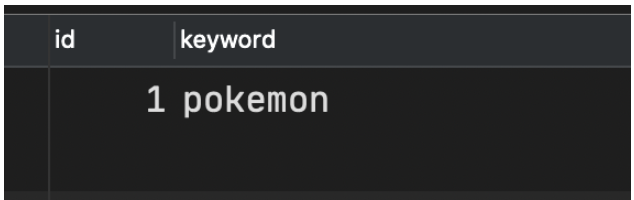
Préparez un mot-clé d'importation par lots Excel, qui contient 2 mots-clés
1.pokemon
2.pokémon
Remarque : l'un de ces deux mots-clés est un e ordinaire et l'autre est une syllabeé
Préparer le script SQL de la table de base de données#🎜🎜 #
-- 导入关键词表
CREATE TABLE `keyword_lexicon` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`keyword` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '搜索关键词',
PRIMARY KEY ("id"),
UNIQUE KEY "idx_keyword" ("keyword") USING BTREE COMMENT '关键词'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='导入关键词表';INSERT IGNORE INTO keyword_lexicon (`keyword`) VALUES ('pokemon'),('pokémon')
#🎜🎜 #
utf8mb4_general_ciutf8mb4_general_ci
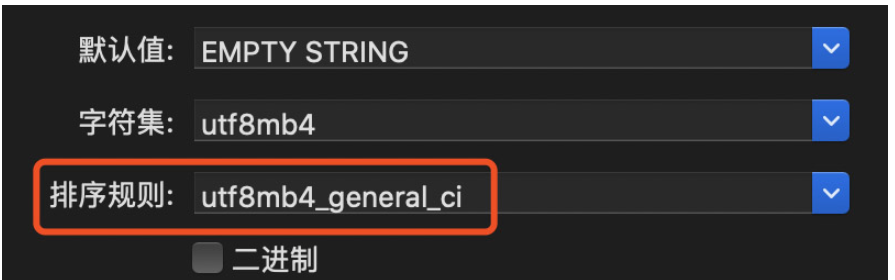
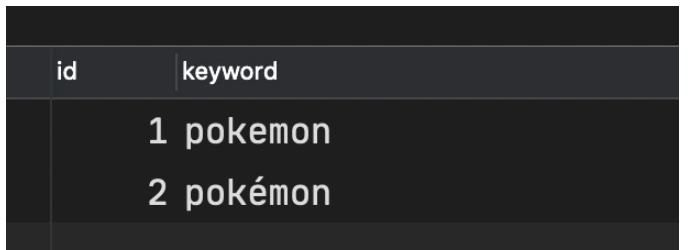
这种排序规则在识别é这种带有音节的字符时,会识别为e,导致2个关键词在通过INSERT IGNORE INTO导入后只会有一条记录,只要将排序规则改为
utf8mb4_bin
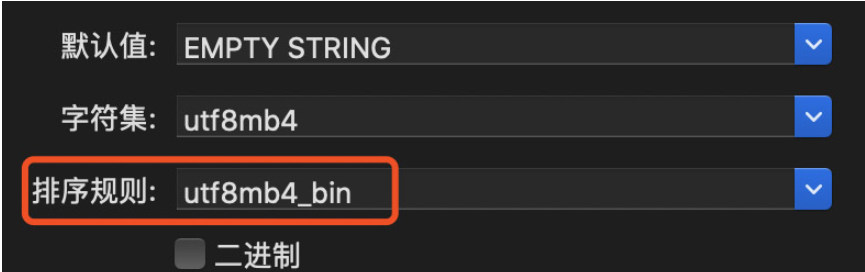
.
utf8mb4_bin
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



