

Analyse d'exemple d'utilisation de fonction MYSQL

Fonction MYSQL
1 : Fonction d'agrégation
Les fonctions d'agrégation sont principalement composées de : count,sum,min,max,avg,group_count()
#🎜 🎜# Concentrons-nous sur la fonction group_count(). Tout d'abord, regroupez en fonction de la colonne spécifiée par group by, et séparez-la par des délimiteurs.Connectez ensuite les valeurs du même groupe et renvoyez un résultat de chaîne #. 🎜🎜#Format : group_count([distinct]nom du champ[ordre par champ de tri asc/desc] [séparateur 'séparateur'])
Description :#🎜 🎜# 1 : Utilisez distinct pour exclure les valeurs en double
2 : Si vous devez trier les valeurs des résultats, vous pouvez utiliser la clause order by
3 : le séparateur est une chaîne. valeur, la valeur par défaut est la virgule.# 🎜🎜#2 : Fonction mathématique
2:CEIL( x) renvoie la plus petite valeur supérieure ou égale à x Entier (arrondi à l'inférieur)
3:FLOOR(x) Renvoie le plus grand entier inférieur ou égal à x (arrondi à l'inférieur)4:GREATEST(expr1 ,expr2...) Renvoie la valeur maximale de la liste7 :ltrim(s) supprime les espaces au début de la chaîne s et supprime les espaces à gauche rtrim() supprime les espaces à droite. espaces des deux côtés.5:LEAST(expr1,expr2....) renvoie la valeur minimale de la liste
6:length() renvoie le nombre d'octets L'encodage utf-8 dans. mysql fait trois octets pour un caractère chinois
6:MAX(x) renvoie la valeur maximale du champ x
7:MIN(x) renvoie le champ Valeur minimale de x
8:MOD(x,y) Renvoie le reste après avoir divisé x par y
9:PI() renvoie pi ( 3.141593)
10:POW(x,y) Renvoie x élevé à la puissance y
11:RAND() Renvoie un nombre aléatoire de 0 à 1
12:ROUND(x) Renvoie l'entier le plus proche de x (après arrondi)
13:ROUND( x,y) Renvoie le nombre de décimales spécifié (après arrondi)
14: TRUNCATE(x,y) Renvoie la valeur x retenue pour y places après la virgule décimale, (la plus grande différence avec ROUND est qu'il ne sera pas arrondi) :char_length(s) Renvoie le nombre de caractères dans la chaîne s
2:character_length Renvoie le nombre de caractères dans la chaîne s
3:concat(s1,s2,s3) Les chaînes s1, s2 et autres chaînes sont combiné en une seule chaîne
4:concat_ws(x,s1,s2. .) Identique à la fonction concat(s1,s2,s3), mais x est ajouté entre chaque chaîne, x peut être un séparateur
5 :field(s,s1,s2) renvoie la première chaîne La position de s dans la liste de chaînes (s1, s2..)
8:mid(s,n,len) de la chaîne s Intercepter une sous-chaîne de longueur len à la position n est la même chose que la sous-chaîne(s,n,len)
9:position (s1,in,s) Obtenez la position de départ de s1 à partir de la chaîne s10:replcae (s,s1,s2) Remplacez la chaîne s2 par la chaîne s1 dans la chaîne s9:date_format(d,f) affiche la date d selon les exigences de l'expression f11:reverse(s) Inverse l'ordre de la chaîne s
7:datediff(d1,d2) Calcule le nombre de jours entre les dates d1>d2 par exemple:datediff( '2022-01-01','2022-02-01')#🎜 🎜#8:currtime() renvoie l'heure actuelle
12:right(s,n) Renvoie les n derniers caractères de la chaîne s (n caractères pris à partir de la droite)
13:strcmp(s1,s2) Compare les chaînes s1 et s2 , renvoie 0 si s1 et s2 sont égaux, renvoie 1 si s1>s2 Si s1 est inférieur à s2, renvoie -1
14:substr(s,start,length) Intercepte la sous-chaîne de longueur à partir de la position de départ de string s
15:ucase(s) upper(s) Convertit la chaîne en majuscule
16:lcase(s) lower(s) Convertit la chaîne en minuscule
#🎜 🎜#3:Fonction Date
1:unix_timestamp() renvoie le 01/01/1970 00:00:00 à la valeur actuelle en millisecondes
2:unix_timestamp(date_string) Convertit la date spécifiée en un horodatage de valeur en milliseconde
3:from_unixtime (bigint unixtime, format de chaîne) Convertit l'horodatage de valeur en milliseconde au format de date spécifié
4:curdate() Renvoie la date actuelle
5:current_date() Renvoie la date actuelle
6:current_timestamp() Renvoie la date et l'heure actuelles
4 : Fonction de flux de contrôle#🎜🎜 #La nouvelle fonction de fenêtre ajoutée dans mysql8.0 Elle est appelée fonction de fenêtrage. Les fonctions de fenêtre de non-agrégation sont relatives. pour agréger les fonctions. Les fonctions d'agrégation renvoient une valeur unique (c'est-à-dire le regroupement) après le calcul d'un ensemble de données. Les fonctions de non-agrégation ne traiteront qu'une seule ligne de données à la fois. Fonctions d'agrégation de fenêtres en lignes lors du calcul du résultat d'un certain champ. sur un enregistrement, les données dans la plage de la fenêtre peuvent être saisies dans la fonction d'agrégation sans changer le nombre de lignes
1:if(expr,v1,v2) Si l'expression expr est vraie, renvoie le résultat v1 , sinon renvoie le résultat v2
2:ifnull(v1,v2) Si la valeur de v1 est Si nulle, renvoie v1, sinon renvoie v2
3:isnull(expression) Détermine si l'expression est nulle # 🎜🎜#4:nullif(expr1,expr2) Comparez deux chaînes et retournez null si les chaînes expr1 et expr2 sont égales Sinon renvoie expr1
5:expression de cas quand condition1 puis résultat1 quand condition2 puis résultat2 sinon la fin du résultat signifie le début de la fonction case, end signifie la fin de la fonction, si condition1 est vraie, renvoie result1, si condition2 est vraie, renvoie result2, quand tous ne sont pas vrais, alors renvoie le résultat, et quand un est établi, ce qui suit ne sera pas être exécuté.
5 : Fonction de fenêtre
5.1 La fonction de numéro de série
peut réaliser un regroupement Trier et ajouter le numéro de série#🎜 🎜#
1 : row_number()
2 :rank()
3 : dense_rank()
Écriture : sélectionnez l'identifiant,...,dense_rank() over(partition par ordre de nom par description de salaire) comme rn de l'employé ;
Remarque : Aucune partition par moyen global tri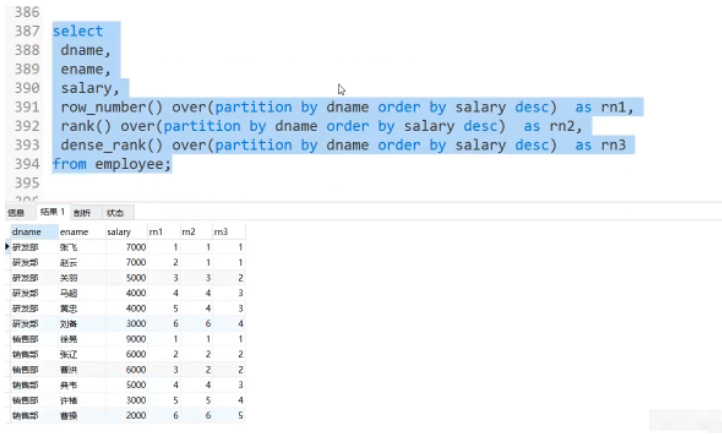
5.2 Fonction de distribution
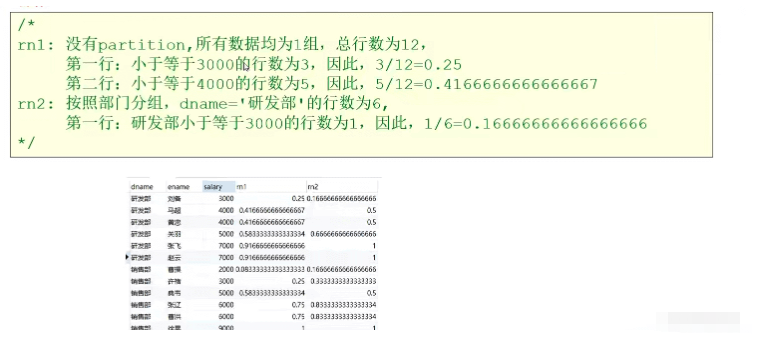
1 : percent_rank()
用途:每行按照公式(rank-1)/(row-1)进行计算.其中rank为rank()函数产生的序号,row为当前窗口的记录总行数
2: cume_dist()
Objectif : Le nombre de lignes dans le groupe qui est inférieur à ou égal à la valeur de classement actuelle /Nombre total de lignes dans le groupe
Scénario d'application : Interroger la proportion qui est inférieure ou égale au salaire actuel
#🎜 🎜#Méthode d'écriture : sélectionnez dname,ename,salary,cume_dist() sur (ordre par salaire) comme rn1,
cume_dist() sur (partition par dname ordre par salaire) comme rn2 de l'employeur ;
1 : lag(expr,n)Objectif : Renvoie la ligne actuelle La valeur de expr dans les n premières lignes (lag(exor,n)) ou les n lignes suivantes (lead(expr,n))# 🎜🎜#2 : lead(expr,n )
Scénario d'application : interroger les scores du premier étudiant et les scores des étudiants actuels La différence (il peut y avoir une certaine valeur de champ de la ligne de données précédente dans la ligne actuelle) 5.4 Fonctions de tête et de queue
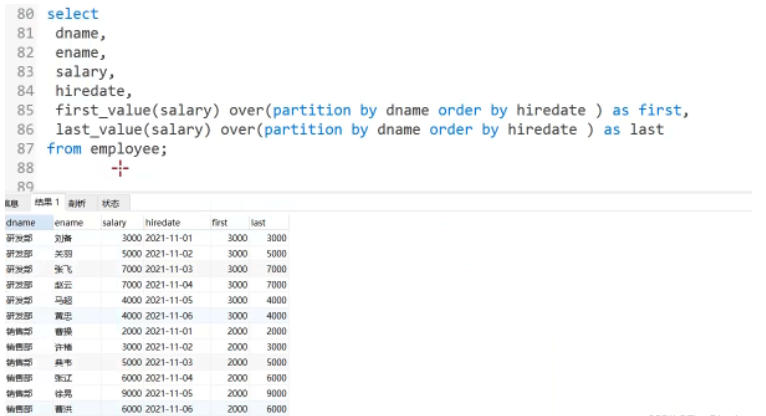
1 : first_value(expr)2 : last_value(expr)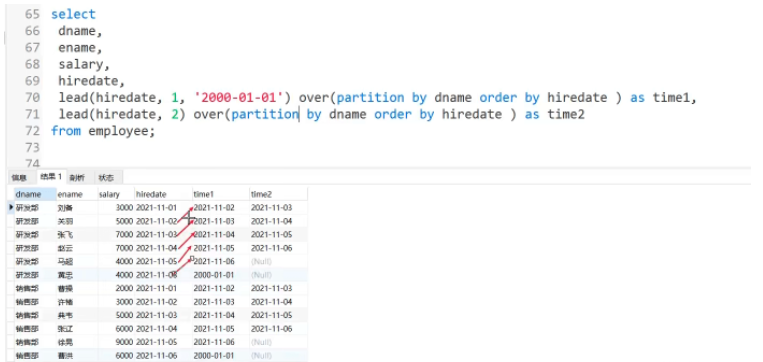
Utilisation : Renvoie la première (first_value(expr )) ou last (last_value(expr)) La valeur de expr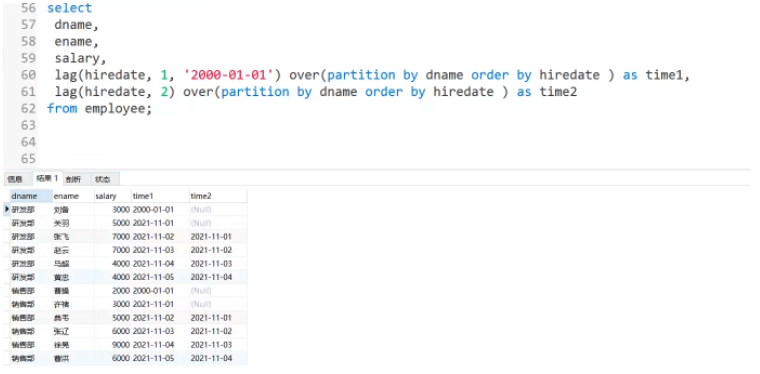 Scénario d'application : Dès à présent, interrogez le salaire du premier et du dernier employé dans l'ordre par date
Scénario d'application : Dès à présent, interrogez le salaire du premier et du dernier employé dans l'ordre par date
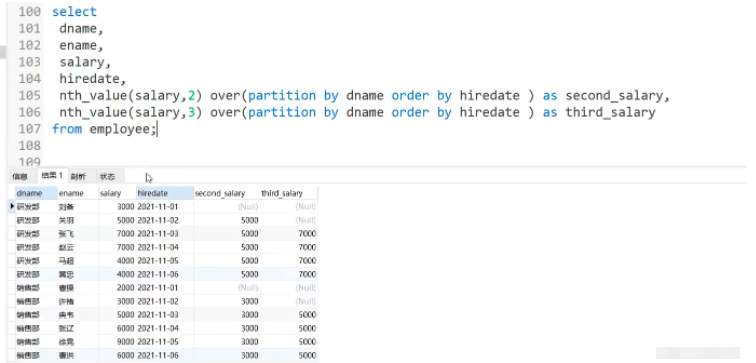
5.5 Autres fonctions2 : ntile(n)#🎜🎜 #1 : nth_value(expr,n)
# 🎜🎜#Objectif : Renvoyez la valeur de la nième expr dans la fenêtre expr peut être une expression ou un nom de colonne
Scénario d'application : A partir du salaire actuel, afficher le salaire de chaque employé Le deuxième ou le troisième salaire dans
1 : sum()5.6 Fonction d'agrégation de fenêtrage
2: avg()
3: min()
 #🎜 🎜#
#🎜 🎜#
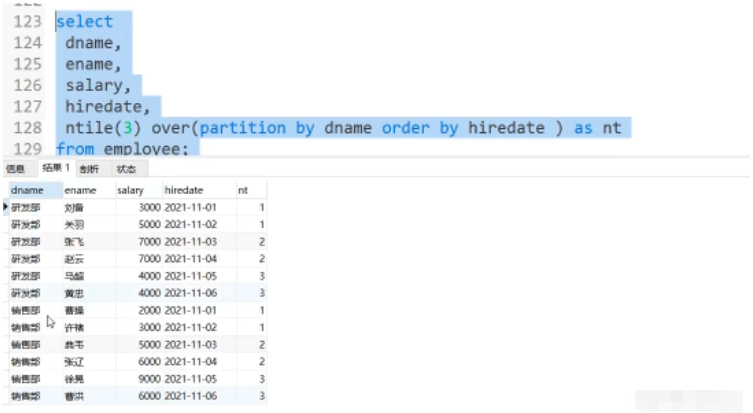
S'il n'y a pas d'ordre par instruction de tri, toutes les données du groupe seront additionnées par défaut
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
La construction d'une base de données SQL comprend 10 étapes: sélectionner des SGBD; Installation de SGBD; créer une base de données; créer une table; insérer des données; récupération de données; Mise à jour des données; supprimer des données; gérer les utilisateurs; sauvegarde de la base de données.
