
 base de données
tutoriel mysql
Pourquoi n'est-il pas recommandé d'utiliser SELECT * dans MySQL ?
base de données
tutoriel mysql
Pourquoi n'est-il pas recommandé d'utiliser SELECT * dans MySQL ?
Pourquoi n'est-il pas recommandé d'utiliser SELECT * dans MySQL ?

"Ne pas utiliser SELECT *" est presque devenu une règle d'or pour MySQL Même le "Alibaba Java Development Manual" indique clairement que * n'est pas autorisé. à utiliser comme requête. La liste de champs donne à cette règle une bénédiction faisant autorité. SELECT *”几乎已经成为了MySQL使用的一条金科玉律,就连《阿里Java开发手册》也明确表示不得使用*作为查询的字段列表,更是让这条规则拥有了权威的加持。

不过我在开发过程中直接使用SELECT *还是比较多的,原因有两个:
因为简单,开发效率非常高,而且如果后期频繁添加或修改字段,SQL语句也不需要改变;
我认为过早优化是个不好的习惯,除非在一开始就能确定你最终实际需要的字段是什么,并为之建立恰当的索引;否则,我选择遇到麻烦的时候再对SQL进行优化,当然前提是这个麻烦并不致命。
但是我们总得知道为什么不建议直接使用SELECT *,本文从4个方面给出理由。
1. 不必要的磁盘I/O
我们知道 MySQL 本质上是将用户记录存储在磁盘上,因此查询操作就是一种进行磁盘IO的行为(前提是要查询的记录没有缓存在内存中)。
查询的字段越多,说明要读取的内容也就越多,因此会增大磁盘 IO 开销。尤其是当某些字段是 TEXT、MEDIUMTEXT或者BLOB 等类型的时候,效果尤为明显。
那使用SELECT *会不会使MySQL占用更多的内存呢?
理论上不会,因为对于Server层而言,并非是在内存中存储完整的结果集之后一下子传给客户端,而是每从存储引擎获取到一行,就写到一个叫做net_buffer的内存空间中,这个内存的大小由系统变量net_buffer_length来控制,默认是16KB;当net_buffer写满之后再往本地网络栈的内存空间socket send buffer中写数据发送给客户端,发送成功(客户端读取完成)后清空net_buffer,然后继续读取下一行并写入。
也就是说,默认情况下,结果集占用的内存空间最大不过是net_buffer_length大小罢了,不会因为多几个字段就占用额外的内存空间。
2. 加重网络时延
承接上一点,虽然每次都是把socket send buffer中的数据发送给客户端,单次看来数据量不大,可架不住真的有人用*把TEXT、MEDIUMTEXT或者BLOB 类型的字段也查出来了,总数据量大了,这就直接导致网络传输的次数变多了。
如果MySQL和应用程序不在同一台机器,这种开销非常明显。即使MySQL服务器和客户端在同一台机器上,它们之间的通信仍然需要使用TCP协议,这也会增加额外的传输时间。
3. 无法使用覆盖索引
为了说明这个问题,我们需要建一个表
CREATE TABLE `user_innodb` ( `id` int NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `gender` tinyint(1) DEFAULT NULL, `phone` varchar(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `IDX_NAME_PHONE` (`name`,`phone`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
我们创建了一个存储引擎为InnoDB的表user_innodb,并设置id为主键,另外为name和phone创建了联合索引,最后向表中随机初始化了500W+条数据。
InnoDB会自动为主键id创建一棵名为主键索引(又叫做聚簇索引)的B+树,这个B+树的最重要的特点就是叶子节点包含了完整的用户记录,大概长这个样子。
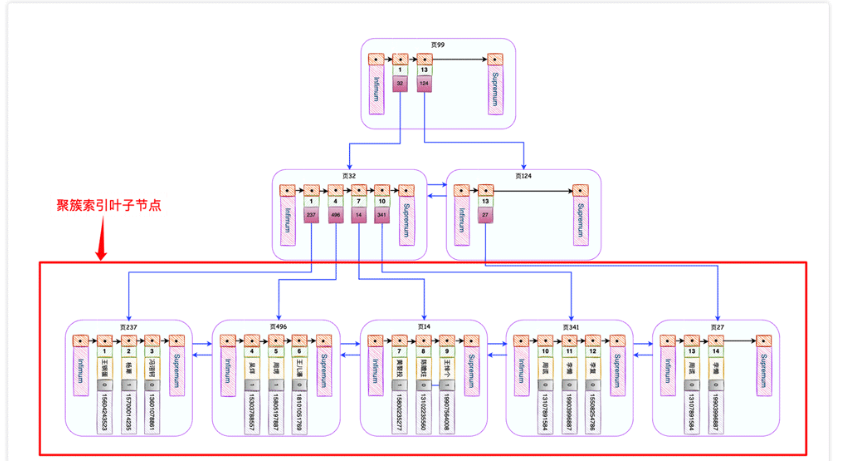
如果我们执行这个语句
SELECT * FROM user_innodb WHERE name = '蝉沐风';
使用EXPLAIN查看一下语句的执行计划:

发现这个SQL语句会使用到IDX_NAME_PHONE索引,这是一个二级索引。二级索引的叶子节点长这个样子:
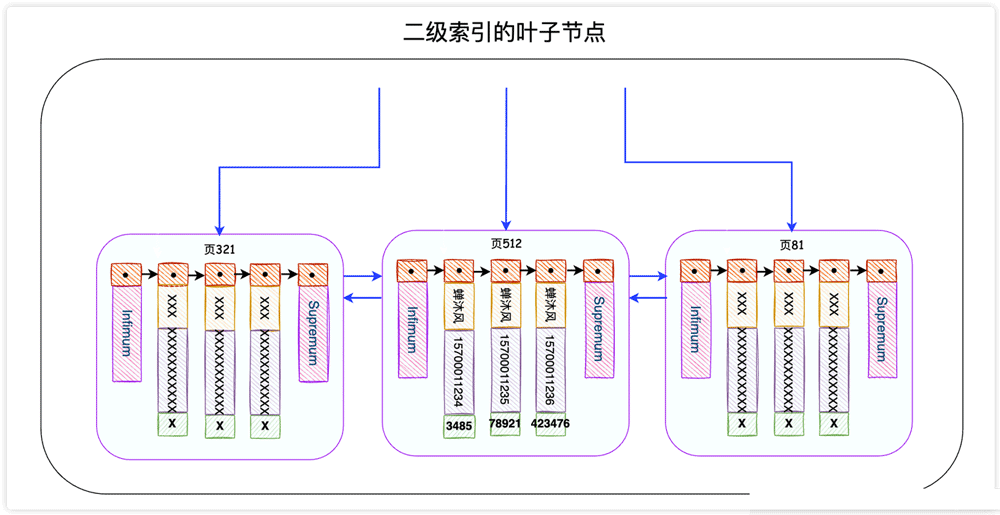
InnoDB存储引擎会根据搜索条件在该二级索引的叶子节点中找到name为蝉沐风的记录,但是二级索引中只记录了name、phone和主键id字段(谁让我们用的是SELECT *呢),因此InnoDB需要拿着主键id去主键索引中查找这一条完整的记录,这个过程叫做回表。
想一下,如果二级索引的叶子节点上有我们想要的所有数据,是不是就不需要回表了呢?是的,这就是覆盖索引。
举个例子,我们恰好只想搜索name、phone
#🎜🎜##🎜🎜#Cependant, j'utilise toujours SELECT * directement pendant le processus de développement pour deux raisons : #🎜🎜#- #🎜🎜#Parce que c'est simple, l'efficacité du développement est très élevée, et si des champs sont fréquemment ajoutés ou modifiés ultérieurement, l'instruction SQL n'a pas besoin d'être modifiée ; #🎜🎜# < li>#🎜🎜 #Je pense qu'une optimisation prématurée est une mauvaise habitude, à moins que vous ne puissiez déterminer au début de quels champs vous avez réellement besoin et créer des index appropriés pour eux, sinon je choisis d'optimiser SQL lorsque je rencontre des problèmes, bien sûr à condition. que ce trouble n'est pas fatal. #🎜🎜#
SELECT * Cet article donne des raisons sous 4 aspects. #🎜🎜#1. E/S disque inutiles
#🎜🎜#Nous savons que MySQL stocke essentiellement les enregistrements utilisateur sur le disque, donc l'opération de requête est un comportement d'exécution d'E/S disque (le principe est que les enregistrements à interroger ne sont pas mis en cache en mémoire). #🎜🎜##🎜🎜#Plus il y a de champs interrogés, plus de contenu doit être lu, ce qui augmentera la surcharge des E/S du disque. Surtout lorsque certains champs sont de typeTEXT, MEDIUMTEXT ou BLOB, l'effet est particulièrement évident. #🎜🎜##🎜🎜#L'utilisation de SELECT * entraînera-t-elle une utilisation de plus de mémoire par MySQL ? #🎜🎜##🎜🎜#Théoriquement non, car pour la couche Serveur, l'ensemble de résultats complet n'est pas stocké en mémoire puis transmis au client en une seule fois, mais est obtenu du moteur de stockage à chaque fois . Une ligne est écrite dans un espace mémoire appelé net_buffer. La taille de cette mémoire est contrôlée par la variable système net_buffer_length. La valeur par défaut est de 16 Ko lorsque net_buffer<. /code> >Une fois qu'il est plein, écrivez les données dans l'espace mémoire de la pile du réseau local <code>socket send buffer et envoyez-les au client une fois l'envoi réussi (le client le lit terminé). , le net_buffer est effacé. Continuez ensuite à lire la ligne suivante et à écrire. #🎜🎜##🎜🎜#En d'autres termes, par défaut, l'espace mémoire maximum occupé par le jeu de résultats est la taille de net_buffer_length Il n'occupera pas d'espace mémoire supplémentaire simplement à cause de quelques autres. champs. #🎜🎜#2. Augmenter le délai réseau
#🎜🎜# Suite au point précédent, bien que les données dusocket send buffer soient envoyées au client à chaque fois, un seul It Il semble que la quantité de données ne soit pas importante au début, mais je ne peux pas le supporter. Quelqu'un a en fait utilisé * pour connaître les champs de type TEXT, MEDIUMTEXT ou <. code>BLOB. La quantité totale de données augmente, ce qui entraîne directement une augmentation du nombre de transmissions réseau. #🎜🎜##🎜🎜#Si MySQL et l'application ne sont pas sur la même machine, cette surcharge est très évidente. Même si le serveur MySQL et le client se trouvent sur la même machine, la communication entre eux doit toujours utiliser le protocole TCP, ce qui ajoute également un temps de transmission supplémentaire. #🎜🎜#3. L'index de couverture ne peut pas être utilisé
#🎜🎜#Pour illustrer ce problème, nous devons construire une table #🎜🎜#SELECT id, name, phone FROM user_innodb WHERE name = "蝉沐风";
user_innodb, et définissez id comme clé primaire, et créez un index commun pour name et phone, et Enfin, ajoutez-le au tableau. Plus de 500 W de données ont été initialisées de manière aléatoire. #🎜🎜##🎜🎜#InnoDB créera automatiquement un arbre B+ nommé index de clé primaire (également appelé index clusterisé) pour la clé primaire id. La caractéristique la plus importante de cet arbre B+ est le nœud feuille. Contient un enregistrement utilisateur complet, qui ressemble probablement à ceci. #🎜🎜##🎜🎜##🎜🎜##🎜🎜#Si nous exécutons cette instruction#🎜🎜#CREATE TABLE `t1` ( `id` int NOT NULL, `m` int DEFAULT NULL, `n` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT; CREATE TABLE `t2` ( `id` int NOT NULL, `m` int DEFAULT NULL, `n` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT;
EXPLAIN pour afficher le plan d'exécution de l'instruction : #🎜🎜## 🎜🎜# #🎜🎜# #🎜🎜# Nous avons constaté que cette instruction SQL utiliserait l'index IDX_NAME_PHONE, qui est un index secondaire. Les nœuds feuilles de l'index secondaire ressemblent à ceci : #🎜🎜##🎜🎜##🎜🎜##🎜🎜#Le moteur de stockage InnoDB trouvera name dans le nœud feuille de l'index secondaire en fonction du conditions de recherche sous forme d'enregistrements Cicada Mufeng, mais seuls les champs nom, téléphone et clé primaire id sont enregistrés dans le index secondaire (qui nous a permis d'utiliser SELECT *), donc InnoDB doit utiliser la clé primaire id pour trouver cet enregistrement complet dans l'index de clé primaire. Ce processus est appelé. retour de table. #🎜🎜##🎜🎜#Réfléchissez-y, si les nœuds feuilles de l'index secondaire ont toutes les données souhaitées, n'est-il pas nécessaire de renvoyer la table ? Oui, il s'agit d'un indice couvert. #🎜🎜##🎜🎜#Par exemple, nous souhaitons uniquement rechercher nom, téléphone et les champs de clé primaire. #🎜🎜#SELECT id, name, phone FROM user_innodb WHERE name = "蝉沐风";
使用EXPLAIN查看一下语句的执行计划:

可以看到Extra一列显示Using index,表示我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是使用了覆盖索引,能够直接摒弃回表操作,大幅度提高查询效率。
4. 可能拖慢JOIN连接查询
我们创建两张表t1,t2进行连接操作来说明接下来的问题,并向t1表中插入了100条数据,向t2中插入了1000条数据。
CREATE TABLE `t1` ( `id` int NOT NULL, `m` int DEFAULT NULL, `n` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT; CREATE TABLE `t2` ( `id` int NOT NULL, `m` int DEFAULT NULL, `n` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT;
如果我们执行下面这条语句
SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.m = t2.m;
这里我使用了STRAIGHT_JOIN强制令
t1表作为驱动表,t2表作为被驱动表
对于连接查询而言,驱动表只会被访问一遍,而被驱动表却要被访问好多遍,具体的访问次数取决于驱动表中符合查询记录的记录条数。现在,我们来讲一下两个表连接的本质,因为驱动表和被驱动表已经被强制确定
t1作为驱动表,针对驱动表的过滤条件,执行对t1表的查询。因为没有过滤条件,也就是获取t1表的所有数据;对上一步中获取到的结果集中的每一条记录,都分别到被驱动表中,根据连接过滤条件查找匹配记录
用伪代码表示的话整个过程是这样的:
// t1Res是针对驱动表t1过滤之后的结果集
for (t1Row : t1Res){
// t2是完整的被驱动表
for(t2Row : t2){
if (满足join条件 && 满足t2的过滤条件){
发送给客户端
}
}
}这种方法最简单,但同时性能也是最差,这种方式叫做嵌套循环连接(Nested-LoopJoin,NLJ)。怎么加快连接速度呢?
其中一个办法就是创建索引,最好是在被驱动表(t2)连接条件涉及到的字段上创建索引,毕竟被驱动表需要被查询好多次,而且对被驱动表的访问本质上就是个单表查询而已(因为t1结果集定了,每次连接t2的查询条件也就定死了)。
既然使用了索引,为了避免重蹈无法使用覆盖索引的覆辙,我们也应该尽量不要直接SELECT *,而是将真正用到的字段作为查询列,并为其建立适当的索引。
但是如果我们不使用索引,MySQL就真的按照嵌套循环查询的方式进行连接查询吗?当然不是,毕竟这种嵌套循环查询实在是太慢了!
在MySQL8.0之前,MySQL提供了基于块的嵌套循环连接(Block Nested-Loop Join,BLJ)方法,MySQL8.0又推出了hash join方法,这两种方法都是为了解决一个问题而提出的,那就是尽量减少被驱动表的访问次数。
这两种方法都用到了一个叫做join buffer的固定大小的内存区域,其中存储着若干条驱动表结果集中的记录(这两种方法的区别就是存储的形式不同而已),如此一来,把被驱动表的记录加载到内存的时候,一次性和join buffer中多条驱动表中的记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O代价,大大减少了重复从磁盘上加载被驱动表的代价。使用join buffer的过程如下图所示:
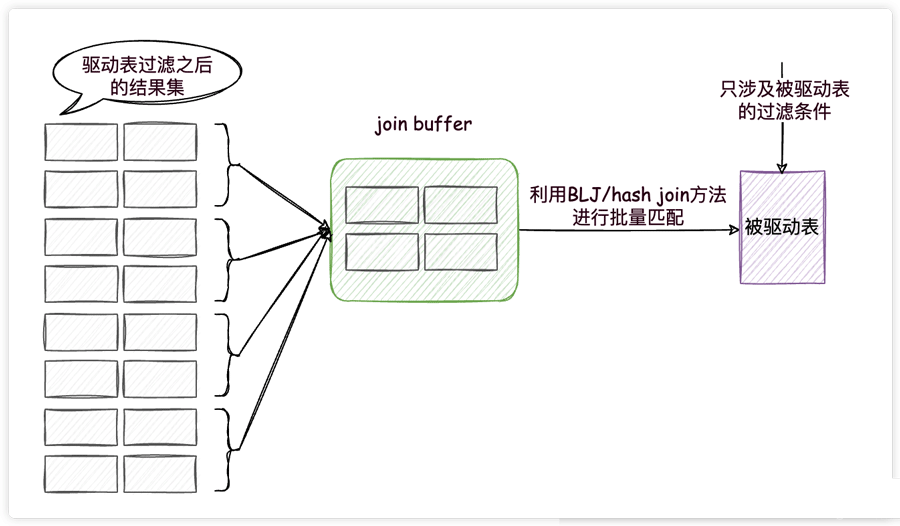
我们看一下上面的连接查询的执行计划,发现确实使用到了hash join(前提是没有为t2表的连接查询字段创建索引,否则就会使用索引,不会使用join buffer)。

最好的情况是join buffer足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完成连接操作了。我们可以使用join_buffer_size这个系统变量进行配置,默认大小为256KB。如果还装不下,就得分批把驱动表的结果集放到join buffer中了,在内存中对比完成之后,清空join buffer再装入下一批结果集,直到连接完成为止。
重点来了!并不是驱动表记录的所有列都会被放到join buffer中,只有查询列表中的列和过滤条件中的列才会被放到join buffer中,所以再次提醒我们,最好不要把*作为查询列表,只需要把我们关心的列放到查询列表就好了,这样还可以在join buffer中放置更多的记录,减少分批的次数,也就自然减少了对被驱动表的访问次数
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Impossible de se connecter à MySQL en tant que racine
Apr 08, 2025 pm 04:54 PM
Impossible de se connecter à MySQL en tant que racine
Apr 08, 2025 pm 04:54 PM
Les principales raisons pour lesquelles vous ne pouvez pas vous connecter à MySQL en tant que racines sont des problèmes d'autorisation, des erreurs de fichier de configuration, des problèmes de mot de passe incohérents, des problèmes de fichiers de socket ou une interception de pare-feu. La solution comprend: vérifiez si le paramètre Bind-Address dans le fichier de configuration est configuré correctement. Vérifiez si les autorisations de l'utilisateur racine ont été modifiées ou supprimées et réinitialisées. Vérifiez que le mot de passe est précis, y compris les cas et les caractères spéciaux. Vérifiez les paramètres et les chemins d'autorisation du fichier de socket. Vérifiez que le pare-feu bloque les connexions au serveur MySQL.
 Intégration RDS MySQL avec Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Intégration RDS MySQL avec Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Simplification de l'intégration des données: AmazonrDSMysQL et l'intégration Zero ETL de Redshift, l'intégration des données est au cœur d'une organisation basée sur les données. Les processus traditionnels ETL (extrait, converti, charge) sont complexes et prennent du temps, en particulier lors de l'intégration de bases de données (telles que AmazonrDSMysQL) avec des entrepôts de données (tels que Redshift). Cependant, AWS fournit des solutions d'intégration ETL Zero qui ont complètement changé cette situation, fournissant une solution simplifiée et à temps proche pour la migration des données de RDSMySQL à Redshift. Cet article plongera dans l'intégration RDSMYSQL ZERO ETL avec Redshift, expliquant comment il fonctionne et les avantages qu'il apporte aux ingénieurs de données et aux développeurs.
 mysql s'il faut changer la table de verrouillage de table
Apr 08, 2025 pm 05:06 PM
mysql s'il faut changer la table de verrouillage de table
Apr 08, 2025 pm 05:06 PM
Lorsque MySQL modifie la structure du tableau, les verrous de métadonnées sont généralement utilisés, ce qui peut entraîner le verrouillage du tableau. Pour réduire l'impact des serrures, les mesures suivantes peuvent être prises: 1. Gardez les tables disponibles avec le DDL en ligne; 2. Effectuer des modifications complexes en lots; 3. Opérez pendant les périodes petites ou hors pointe; 4. Utilisez des outils PT-OSC pour obtenir un contrôle plus fin.
 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
L'optimisation des requêtes dans MySQL est essentielle pour améliorer les performances de la base de données, en particulier lorsqu'elle traite avec de grands ensembles de données
Apr 08, 2025 pm 07:12 PM
1. Utilisez l'index correct pour accélérer la récupération des données en réduisant la quantité de données numérisées SELECT * FROMMLOYEESEESHWHERELAST_NAME = 'SMITH'; Si vous recherchez plusieurs fois une colonne d'une table, créez un index pour cette colonne. If you or your app needs data from multiple columns according to the criteria, create a composite index 2. Avoid select * only those required columns, if you select all unwanted columns, this will only consume more server memory and cause the server to slow down at high load or frequency times For example, your table contains columns such as created_at and updated_at and timestamps, and then avoid selecting * because they do not require inefficient query se
 La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
La relation entre l'utilisateur de MySQL et la base de données
Apr 08, 2025 pm 07:15 PM
Dans la base de données MySQL, la relation entre l'utilisateur et la base de données est définie par les autorisations et les tables. L'utilisateur a un nom d'utilisateur et un mot de passe pour accéder à la base de données. Les autorisations sont accordées par la commande Grant, tandis que le tableau est créé par la commande Create Table. Pour établir une relation entre un utilisateur et une base de données, vous devez créer une base de données, créer un utilisateur, puis accorder des autorisations.
 MySQL peut-il fonctionner sur Android
Apr 08, 2025 pm 05:03 PM
MySQL peut-il fonctionner sur Android
Apr 08, 2025 pm 05:03 PM
MySQL ne peut pas fonctionner directement sur Android, mais il peut être implémenté indirectement en utilisant les méthodes suivantes: à l'aide de la base de données légère SQLite, qui est construite sur le système Android, ne nécessite pas de serveur distinct et a une petite utilisation des ressources, qui est très adaptée aux applications de périphériques mobiles. Connectez-vous à distance au serveur MySQL et connectez-vous à la base de données MySQL sur le serveur distant via le réseau pour la lecture et l'écriture de données, mais il existe des inconvénients tels que des dépendances de réseau solides, des problèmes de sécurité et des coûts de serveur.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
