
 base de données
Redis
Comment implémenter le cache de deuxième niveau Caffeine+Redis basé sur Spring Cache
base de données
Redis
Comment implémenter le cache de deuxième niveau Caffeine+Redis basé sur Spring Cache
Comment implémenter le cache de deuxième niveau Caffeine+Redis basé sur Spring Cache

Les détails sont les suivants :
1. Parlons de ce qu'est le cache codé en dur ?
Avant d'apprendre Spring Cache, j'utilisais souvent la mise en cache de manière codée en dur.
Prenons un exemple pratique afin d'améliorer l'efficacité des requêtes sur les informations utilisateur, nous utilisons le cache pour les informations utilisateur. L'exemple de code est le suivant :
@Autowire
private UserMapper userMapper;
@Autowire
private RedisCache redisCache;
//查询用户
public User getUserById(Long userId) {
//定义缓存key
String cacheKey = "userId_" + userId;
//先查询redis缓存
User user = redisCache.get(cacheKey);
//如果缓存中有就直接返回,不再查询数据库
if (user != null) {
return user;
}
//没有再查询数据库
user = userMapper.getUserById(userId);
//数据存入缓存,这样下次查询就能到缓存中获取
if (user != null) {
stringCommand.set(cacheKey, user);
}
return user;
}Je crois. de nombreux étudiants ont écrit du code dans un style similaire. Ce style est conforme à la pensée de programmation orientée processus et est très facile à comprendre. Mais il présente aussi quelques inconvénients :
Le code n'est pas assez élégant. La logique métier comporte quatre actions typiques : stockage, lecture, modification et suppression . Chaque opération doit définir la clé de cache et appeler l'API de la commande cache, ce qui génère du code plus invasif ; Le caractère intrusif reflète principalement les deux points suivants :
- Pendant la phase de développement et de débogage conjoint, le cache doit être supprimé et le code d'opération du cache peut ne peut être commenté ou supprimé que temporairement, ce qui est également sujet à des erreurs
;
- Dans certains scénarios, le composant de cache doit être remplacé. . Chaque composant du cache possède sa propre API et le coût de remplacement est assez élevé#🎜 🎜#.
Si c'était comme ça, ne serait-ce pas beaucoup plus élégant ?
@Mapper
public interface UserMapper {
/**
* 根据用户id获取用户信息
*
* 如果缓存中有直接返回缓存数据,如果没有那么就去数据库查询,查询完再插入缓存中,这里缓存的key前缀为cache_user_id_,+传入的用户ID
*/
@Cacheable(key = "'cache_user_id_' + #userId")
User getUserById(Long userId);
} @Autowire
private UserMapper userMapper;
//查询用户
public User getUserById(Long userId) {
return userMapper.getUserById(userId);
}Cache et CacheManager1. # 🎜🎜#Cette définition d'interface fournit des opérations spécifiques de cache, telles que le placement, la lecture et le nettoyage du cache : package org.Springframework.cache;
import java.util.concurrent.Callable;
public interface Cache {
// cacheName,缓存的名字,默认实现中一般是CacheManager创建Cache的bean时传入cacheName
String getName();
//得到底层使用的缓存,如Ehcache
Object getNativeCache();
// 通过key获取缓存值,注意返回的是ValueWrapper,为了兼容存储空值的情况,将返回值包装了一层,通过get方法获取实际值
ValueWrapper get(Object key);
// 通过key获取缓存值,返回的是实际值,即方法的返回值类型
<T> T get(Object key, Class<T> type);
// 通过key获取缓存值,可以使用valueLoader.call()来调使用@Cacheable注解的方法。当@Cacheable注解的sync属性配置为true时使用此方法。
// 因此方法内需要保证回源到数据库的同步性。避免在缓存失效时大量请求回源到数据库
<T> T get(Object key, Callable<T> valueLoader);
// 将@Cacheable注解方法返回的数据放入缓存中
void put(Object key, Object value);
// 当缓存中不存在key时才放入缓存。返回值是当key存在时原有的数据
ValueWrapper putIfAbsent(Object key, Object value);
// 删除缓存
void evict(Object key);
// 清空缓存
void clear();
// 缓存返回值的包装
interface ValueWrapper {
// 返回实际缓存的对象
Object get();
}
}Copier après la connexion2 Interface CacheManager
package org.Springframework.cache;
import java.util.concurrent.Callable;
public interface Cache {
// cacheName,缓存的名字,默认实现中一般是CacheManager创建Cache的bean时传入cacheName
String getName();
//得到底层使用的缓存,如Ehcache
Object getNativeCache();
// 通过key获取缓存值,注意返回的是ValueWrapper,为了兼容存储空值的情况,将返回值包装了一层,通过get方法获取实际值
ValueWrapper get(Object key);
// 通过key获取缓存值,返回的是实际值,即方法的返回值类型
<T> T get(Object key, Class<T> type);
// 通过key获取缓存值,可以使用valueLoader.call()来调使用@Cacheable注解的方法。当@Cacheable注解的sync属性配置为true时使用此方法。
// 因此方法内需要保证回源到数据库的同步性。避免在缓存失效时大量请求回源到数据库
<T> T get(Object key, Callable<T> valueLoader);
// 将@Cacheable注解方法返回的数据放入缓存中
void put(Object key, Object value);
// 当缓存中不存在key时才放入缓存。返回值是当key存在时原有的数据
ValueWrapper putIfAbsent(Object key, Object value);
// 删除缓存
void evict(Object key);
// 清空缓存
void clear();
// 缓存返回值的包装
interface ValueWrapper {
// 返回实际缓存的对象
Object get();
}
}Fournit principalement la création de l'implémentation du cache. beans , chaque application peut isoler le cache via cacheName, et chaque cacheName correspond à une implémentation de Cache. Cache和CacheManager
1、Cache接口
该接口定义提供缓存的具体操作,比如缓存的放入、读取、清理:
package org.Springframework.cache;
import java.util.Collection;
public interface CacheManager {
// 通过cacheName创建Cache的实现bean,具体实现中需要存储已创建的Cache实现bean,避免重复创建,也避免内存缓存
//对象(如Caffeine)重新创建后原来缓存内容丢失的情况
Cache getCache(String name);
// 返回所有的cacheName
Collection<String> getCacheNames();
}2、CacheManager接口
主要提供Cache实现bean的创建,每个应用里可以通过cacheName来对Cache进行隔离,每个cacheName对应一个Cache实现。
public @interface Cacheable {
// cacheNames,CacheManager就是通过这个名称创建对应的Cache实现bean
@AliasFor("cacheNames")
String[] value() default {};
@AliasFor("value")
String[] cacheNames() default {};
// 缓存的key,支持SpEL表达式。默认是使用所有参数及其计算的hashCode包装后的对象(SimpleKey)
String key() default "";
// 缓存key生成器,默认实现是SimpleKeyGenerator
String keyGenerator() default "";
// 指定使用哪个CacheManager,如果只有一个可以不用指定
String cacheManager() default "";
// 缓存解析器
String cacheResolver() default "";
// 缓存的条件,支持SpEL表达式,当达到满足的条件时才缓存数据。在调用方法前后都会判断
String condition() default "";
// 满足条件时不更新缓存,支持SpEL表达式,只在调用方法后判断
String unless() default "";
// 回源到实际方法获取数据时,是否要保持同步,如果为false,调用的是Cache.get(key)方法;如果为true,调用的是Cache.get(key, Callable)方法
boolean sync() default false;
}3、常用注解说明
@Cacheable:主要应用到查询数据的方法上。
public @interface CacheEvict {
// ...相同属性说明请参考@Cacheable中的说明
// 是否要清除所有缓存的数据,为false时调用的是Cache.evict(key)方法;为true时调用的是Cache.clear()方法
boolean allEntries() default false;
// 调用方法之前或之后清除缓存
boolean beforeInvocation() default false;
}@CacheEvict:清除缓存,主要应用到删除数据的方法上。相比Cacheable多了两个属性
FIFO:先进先出。选择最先进入的数据优先淘汰。 LRU:最近最少使用。选择最近最少使用的数据优先淘汰。 LFU:最不经常使用。选择在一段时间内被使用次数最少的数据优先淘汰。
@CachePut:放入缓存,主要用到对数据有更新的方法上。属性说明参考@Cacheable
@Caching:用于在一个方法上配置多种注解
@EnableCaching:启用Spring cache缓存,作为总的开关,在SpringBoot的启动类或配置类上需要加上此注解才会生效
三、使用二级缓存需要思考的一些问题?
我们知道关系数据库(Mysql)数据最终存储在磁盘上,如果每次都从数据库里去读取,会因为磁盘本身的IO影响读取速度,所以就有了
像redis这种的内存缓存。
通过内存缓存确实能够很大程度的提高查询速度,但如果同一查询并发量非常的大,频繁的查询redis,也会有明显的网络IO上的消耗,
那我们针对这种查询非常频繁的数据(热点key),我们是不是可以考虑存到应用内缓存,如:caffeine。
当应用内缓存有符合条件的数据时,就可以直接使用,而不用通过网络到redis中去获取,这样就形成了两级缓存。
应用内缓存叫做一级缓存,远程缓存(如redis)叫做二级缓存。
整个流程如下
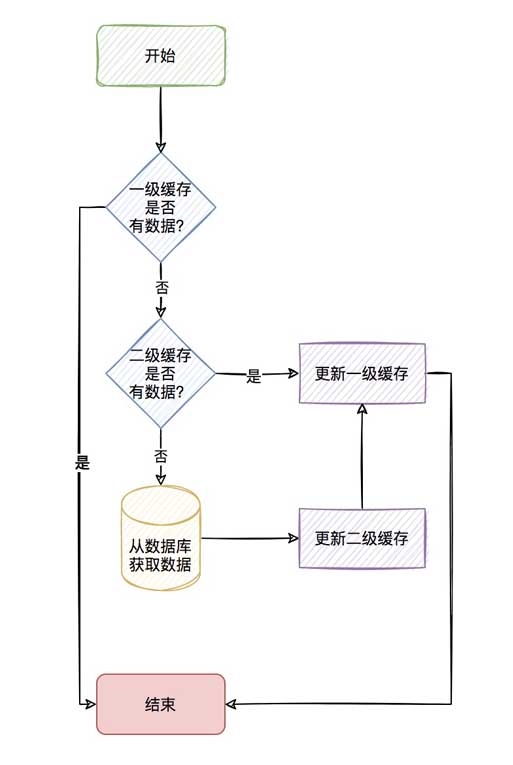
流程看着是很清新,但其实二级缓存需要考虑的点还很多。
1.如何保证分布式节点一级缓存的一致性?
我们说一级缓存是应用内缓存,那么当你的项目部署在多个节点的时候,如何保证当你对某个key进行修改删除操作时,使其它节点
的一级缓存一致呢?
2.是否允许存储空值?
这个确实是需要考虑的点。因为如果某个查询缓存和数据库中都没有,那么就会导致频繁查询数据库,导致数据库Down,这也是我们
常说的缓存穿透。
但如果存储空值呢,因为可能会存储大量的空值,导致缓存变大,所以这个最好是可配置,按照业务来决定是否开启。
3.是否需要缓存预热?
<dependency>
<groupId>com.jincou</groupId>
<artifactId>redis-caffeine-cache-starter</artifactId>
<version>1.0.0</version>
</dependency>3. Annotations couramment utilisées
@Cacheable : principalement appliquées aux méthodes d'interrogation de données. #🎜🎜## 二级缓存配置
# 注:caffeine 不适用于数据量大,并且缓存命中率极低的业务场景,如用户维度的缓存。请慎重选择。
l2cache:
config:
# 是否存储空值,默认true,防止缓存穿透
allowNullValues: true
# 组合缓存配置
composite:
# 是否全部启用一级缓存,默认false
l1AllOpen: false
# 是否手动启用一级缓存,默认false
l1Manual: true
# 手动配置走一级缓存的缓存key集合,针对单个key维度
l1ManualKeySet:
- userCache:user01
- userCache:user02
- userCache:user03
# 手动配置走一级缓存的缓存名字集合,针对cacheName维度
l1ManualCacheNameSet:
- userCache
- goodsCache
# 一级缓存
caffeine:
# 是否自动刷新过期缓存 true 是 false 否
autoRefreshExpireCache: false
# 缓存刷新调度线程池的大小
refreshPoolSize: 2
# 缓存刷新的频率(秒)
refreshPeriod: 10
# 写入后过期时间(秒)
expireAfterWrite: 180
# 访问后过期时间(秒)
expireAfterAccess: 180
# 初始化大小
initialCapacity: 1000
# 最大缓存对象个数,超过此数量时之前放入的缓存将失效
maximumSize: 3000
# 二级缓存
redis:
# 全局过期时间,单位毫秒,默认不过期
defaultExpiration: 300000
# 每个cacheName的过期时间,单位毫秒,优先级比defaultExpiration高
expires: {userCache: 300000,goodsCache: 50000}
# 缓存更新时通知其他节点的topic名称 默认 cache:redis:caffeine:topic
topic: cache:redis:caffeine:topic@CacheEvict : Vider le cache, principalement utilisé pour supprimer des données. Par rapport à Cacheable, il possède deux attributs supplémentaires #🎜🎜#/**
* 启动类
*/
@EnableCaching
@SpringBootApplication
public class CacheApplication {
public static void main(String[] args) {
SpringApplication.run(CacheApplication.class, args);
}
}@CachePut : mis en cache, principalement utilisé pour mettre à jour les données. Pour la description de l'attribut, veuillez vous référer à @Cacheable#🎜🎜##🎜🎜#@Caching : utilisé pour configurer plusieurs annotations sur une seule méthode #🎜🎜##🎜🎜#@EnableCaching</ code> : Activer le cache de cache Spring En tant que commutateur général, cette annotation doit être ajoutée à la classe de démarrage ou à la classe de configuration SpringBoot pour qu'elle prenne effet #🎜🎜##🎜🎜# 3. Certains problèmes à prendre en compte lorsque. utiliser le cache de deuxième niveau ? #🎜🎜##🎜🎜#Nous savons que les données de la base de données relationnelle (Mysql) sont finalement stockées sur le disque si elles sont lues à partir de la base de données à chaque fois, la vitesse de lecture sera affectée par les E/S du disque lui-même, donc là. c'est #🎜 🎜##🎜🎜#Le cache mémoire comme Redis. #🎜🎜##🎜🎜# La mise en cache de la mémoire peut en effet grandement améliorer la vitesse des requêtes, mais si la même requête a une très grande concurrence et des requêtes Redis fréquentes, il y aura également une consommation évidente d'E/S réseau, #🎜🎜 ##🎜🎜# Alors pour ce type de données (hot key) très fréquemment interrogées, peut-on envisager de les stocker dans le cache in-application, comme la caféine. #🎜🎜##🎜🎜#Lorsque le cache in-app contient des données qualifiées, il peut être utilisé directement sans avoir à les obtenir depuis Redis via le réseau, formant ainsi un cache à deux niveaux. #🎜🎜##🎜🎜##🎜🎜#Le cache intégré à l'application est appelé cache de premier niveau, et le cache distant (tel que Redis) est appelé cache de deuxième niveau#🎜🎜#. #🎜🎜##🎜🎜#L'ensemble du processus est le suivant#🎜🎜##🎜🎜#<img src="https://img.php.cn/upload/article/000/887/227/168558562818491.jpg " alt= "Comment implémenter le cache de deuxième niveau Caffeine+Redis basé sur Spring Cache" />#🎜🎜##🎜🎜#Le processus semble très rafraîchissant, mais en fait il y a de nombreux points à considérer dans le cache de deuxième niveau . #🎜🎜##🎜🎜#1.<code>Comment assurer la cohérence du cache de premier niveau des nœuds distribués ? #🎜🎜##🎜🎜#Nous disons que le cache de premier niveau est un cache intégré à l'application, donc lorsque votre projet est déployé sur plusieurs nœuds, comment vous assurer que lorsque vous modifiez ou supprimez une clé, utilisez Les caches de premier niveau des autres nœuds #🎜🎜##🎜🎜# sont-ils cohérents ? #🎜🎜##🎜🎜#2.Est-il autorisé de stocker des valeurs nulles ? #🎜🎜##🎜🎜#C'est effectivement un point à considérer. Parce que si une certaine requête n'est pas dans le cache ou dans la base de données, cela entraînera des requêtes fréquentes vers la base de données, provoquant une panne de la base de données. C'est aussi ce que nous #🎜🎜##🎜🎜# appelons souvent la pénétration du cache. #🎜🎜##🎜🎜#Mais si vous stockez des valeurs nulles, un grand nombre de valeurs nulles peuvent être stockées, ce qui entraînera une augmentation de la taille du cache, il est donc préférable de rendre cela configurable et de décider s'il faut l'activer en fonction l'entreprise. #🎜🎜##🎜🎜#3.Le préchauffage du cache est-il requis ? #🎜🎜#也就是说,我们会觉得某些key一开始就会非常的热,也就是热点数据,那么我们是否可以一开始就先存储到缓存中,避免缓存击穿。
4.一级缓存存储数量上限的考虑?
既然一级缓存是应用内缓存,那你是否考虑一级缓存存储的数据给个限定最大值,避免存储太多的一级缓存导致OOM。
5.一级缓存过期策略的考虑?
我们说redis作为二级缓存,redis是淘汰策略来管理的。具体可参考redis的8种淘汰策略。那你的一级缓存策略呢?就好比你设置一级缓存
数量最大为5000个,那当第5001个进来的时候,你是怎么处理呢?是直接不保存,还是说自定义LRU或者LFU算法去淘汰之前的数据?
6.一级缓存过期了如何清除?
我们说redis作为二级缓存,我们有它的缓存过期策略(定时、定期、惰性),那你的一级缓存呢,过期如何清除呢?
这里4、5、6小点如果说用我们传统的Map显然实现是很费劲的,但现在有更好用的一级缓存库那就是Caffeine。
四、Caffeine 简介
Caffeine,一个用于Java的高性能缓存库。
缓存和Map之间的一个根本区别是缓存会清理存储的项目。
1、写入缓存策略
Caffeine有三种缓存写入策略:手动、同步加载和异步加载。
2、缓存值的清理策略
Caffeine有三种缓存值的清理策略:基于大小、基于时间和基于引用。
基于容量:当缓存大小超过配置的大小限制时会发生回收。
基于时间:
写入后到期策略。
访问后过期策略。
到期时间由 Expiry 实现独自计算。
基于引用:启用基于缓存键值的垃圾回收。
Caffeine可以将值封装为弱引用或软引用,并且Java中还有强引用和虚引用这两种引用类型。
软引用:如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。
弱引用:在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会
回收它的内存。
3、统计
Caffeine提供了一种记录缓存使用统计信息的方法,可以实时监控缓存当前的状态,以评估缓存的健康程度以及缓存命中率等,方便后
续调整参数。
4、高效的缓存淘汰算法
缓存淘汰算法的目的是利用有限的资源,尽量预测哪些数据将会在短期内被频繁使用,以此来提高缓存的命中率。常用的缓存淘汰算法有
LRU、LFU、FIFO等。
FIFO:先进先出。选择最先进入的数据优先淘汰。 LRU:最近最少使用。选择最近最少使用的数据优先淘汰。 LFU:最不经常使用。选择在一段时间内被使用次数最少的数据优先淘汰。
LRU(Least Recently Used)算法认为最近访问过的数据将来被访问的几率也更高。
LRU通常使用链表来实现,如果数据添加或者被访问到则把数据移动到链表的头部,链表的头部为热数据,链表的尾部如冷数据,当
数据满时,淘汰尾部的数据。
LFU(Least Frequently Used)算法根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问
的频率也更高”。根据LFU的思想,如果想要实现这个算法,需要额外的一套存储用来存每个元素的访问次数,会造成内存资源的浪费。
Caffeine采用了一种结合LRU、LFU优点的算法:W-TinyLFU,其特点:高命中率、低内存占用。
5、其他说明
底层数据存储使用了ConcurrentHashMap。因为Caffeine面向JDK8,在jdk8中ConcurrentHashMap增加了红黑树,在hash冲突
严重时也能有良好的读性能。
五、基于Spring Cache实现二级缓存(Caffeine+Redis)
前面说了,使用了redis缓存,也会存在一定程度的网络传输上的消耗,所以会考虑应用内缓存,但有点很重要的要记住:
应用内缓存可以理解成比redis缓存更珍惜的资源,所以,caffeine 不适用于数据量大,并且缓存命中率极低的业务场景,如用户维度的缓存。
当前项目针对应用都部署了多个节点,一级缓存是在应用内的缓存,所以当对数据更新和清除时,需要通知所有节点进行清理缓存的操作。
可以有多种方式来实现这种效果,比如:zookeeper、MQ等,但是既然用了redis缓存,redis本身是有支持订阅/发布功能的,所以就
不依赖其他组件了,直接使用redis的通道来通知其他节点进行清理缓存的操作。
只需通过发布订阅机制通知其他节点删除该key在本地一级缓存中的条目,即可在key更新或删除操作后实现同步。
具体具体项目代码这里就不再粘贴出来了,这样只粘贴如何引用这个starter包。
1、maven引入使用
<dependency>
<groupId>com.jincou</groupId>
<artifactId>redis-caffeine-cache-starter</artifactId>
<version>1.0.0</version>
</dependency>2、application.yml
添加二级缓存相关配置
# 二级缓存配置
# 注:caffeine 不适用于数据量大,并且缓存命中率极低的业务场景,如用户维度的缓存。请慎重选择。
l2cache:
config:
# 是否存储空值,默认true,防止缓存穿透
allowNullValues: true
# 组合缓存配置
composite:
# 是否全部启用一级缓存,默认false
l1AllOpen: false
# 是否手动启用一级缓存,默认false
l1Manual: true
# 手动配置走一级缓存的缓存key集合,针对单个key维度
l1ManualKeySet:
- userCache:user01
- userCache:user02
- userCache:user03
# 手动配置走一级缓存的缓存名字集合,针对cacheName维度
l1ManualCacheNameSet:
- userCache
- goodsCache
# 一级缓存
caffeine:
# 是否自动刷新过期缓存 true 是 false 否
autoRefreshExpireCache: false
# 缓存刷新调度线程池的大小
refreshPoolSize: 2
# 缓存刷新的频率(秒)
refreshPeriod: 10
# 写入后过期时间(秒)
expireAfterWrite: 180
# 访问后过期时间(秒)
expireAfterAccess: 180
# 初始化大小
initialCapacity: 1000
# 最大缓存对象个数,超过此数量时之前放入的缓存将失效
maximumSize: 3000
# 二级缓存
redis:
# 全局过期时间,单位毫秒,默认不过期
defaultExpiration: 300000
# 每个cacheName的过期时间,单位毫秒,优先级比defaultExpiration高
expires: {userCache: 300000,goodsCache: 50000}
# 缓存更新时通知其他节点的topic名称 默认 cache:redis:caffeine:topic
topic: cache:redis:caffeine:topic3、启动类上增加@EnableCaching
/**
* 启动类
*/
@EnableCaching
@SpringBootApplication
public class CacheApplication {
public static void main(String[] args) {
SpringApplication.run(CacheApplication.class, args);
}
}4、在需要缓存的方法上增加@Cacheable注解
/**
* 测试
*/
@Service
public class CaffeineCacheService {
private final Logger logger = LoggerFactory.getLogger(CaffeineCacheService.class);
/**
* 用于模拟db
*/
private static Map<String, UserDTO> userMap = new HashMap<>();
{
userMap.put("user01", new UserDTO("1", "张三"));
userMap.put("user02", new UserDTO("2", "李四"));
userMap.put("user03", new UserDTO("3", "王五"));
userMap.put("user04", new UserDTO("4", "赵六"));
}
/**
* 获取或加载缓存项
*/
@Cacheable(key = "'cache_user_id_' + #userId", value = "userCache")
public UserDTO queryUser(String userId) {
UserDTO userDTO = userMap.get(userId);
try {
Thread.sleep(1000);// 模拟加载数据的耗时
} catch (InterruptedException e) {
e.printStackTrace();
}
logger.info("加载数据:{}", userDTO);
return userDTO;
}
/**
* 获取或加载缓存项
* <p>
* 注:因底层是基于caffeine来实现一级缓存,所以利用的caffeine本身的同步机制来实现
* sync=true 则表示并发场景下同步加载缓存项,
* sync=true,是通过get(Object key, Callable<T> valueLoader)来获取或加载缓存项,此时valueLoader(加载缓存项的具体逻辑)会被缓存起来,所以CaffeineCache在定时刷新过期缓存时,缓存项过期则会重新加载。
* sync=false,是通过get(Object key)来获取缓存项,由于没有valueLoader(加载缓存项的具体逻辑),所以CaffeineCache在定时刷新过期缓存时,缓存项过期则会被淘汰。
* <p>
*/
@Cacheable(value = "userCache", key = "#userId", sync = true)
public List<UserDTO> queryUserSyncList(String userId) {
UserDTO userDTO = userMap.get(userId);
List<UserDTO> list = new ArrayList();
list.add(userDTO);
logger.info("加载数据:{}", list);
return list;
}
/**
* 更新缓存
*/
@CachePut(value = "userCache", key = "#userId")
public UserDTO putUser(String userId, UserDTO userDTO) {
return userDTO;
}
/**
* 淘汰缓存
*/
@CacheEvict(value = "userCache", key = "#userId")
public String evictUserSync(String userId) {
return userId;
}
}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Comment construire le mode Cluster Redis
Apr 10, 2025 pm 10:15 PM
Le mode Redis Cluster déploie les instances Redis sur plusieurs serveurs grâce à la rupture, à l'amélioration de l'évolutivité et de la disponibilité. Les étapes de construction sont les suivantes: Créez des instances de redis étranges avec différents ports; Créer 3 instances Sentinel, Moniteur Redis Instances et basculement; Configurer les fichiers de configuration Sentinel, ajouter des informations d'instance Redis de surveillance et des paramètres de basculement; Configurer les fichiers de configuration d'instance Redis, activer le mode de cluster et spécifier le chemin du fichier d'informations de cluster; Créer un fichier nœuds.conf, contenant des informations de chaque instance redis; Démarrez le cluster, exécutez la commande CREATE pour créer un cluster et spécifiez le nombre de répliques; Connectez-vous au cluster pour exécuter la commande d'informations de cluster pour vérifier l'état du cluster; faire
 Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données redis
Apr 10, 2025 pm 10:06 PM
Comment effacer les données Redis: utilisez la commande flushall pour effacer toutes les valeurs de clé. Utilisez la commande flushdb pour effacer la valeur clé de la base de données actuellement sélectionnée. Utilisez SELECT pour commuter les bases de données, puis utilisez FlushDB pour effacer plusieurs bases de données. Utilisez la commande del pour supprimer une clé spécifique. Utilisez l'outil Redis-CLI pour effacer les données.
 Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Comment lire la file d'attente redis
Apr 10, 2025 pm 10:12 PM
Pour lire une file d'attente à partir de Redis, vous devez obtenir le nom de la file d'attente, lire les éléments à l'aide de la commande LPOP et traiter la file d'attente vide. Les étapes spécifiques sont les suivantes: Obtenez le nom de la file d'attente: Nommez-le avec le préfixe de "Fitre:" tel que "Fitre: My-Quyue". Utilisez la commande LPOP: éjectez l'élément de la tête de la file d'attente et renvoyez sa valeur, telle que la file d'attente LPOP: My-Queue. Traitement des files d'attente vides: si la file d'attente est vide, LPOP renvoie NIL et vous pouvez vérifier si la file d'attente existe avant de lire l'élément.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
 Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
Comment lire le code source de Redis
Apr 10, 2025 pm 08:27 PM
La meilleure façon de comprendre le code source redis est d'aller étape par étape: familiarisez-vous avec les bases de Redis. Sélectionnez un module ou une fonction spécifique comme point de départ. Commencez par le point d'entrée du module ou de la fonction et affichez le code ligne par ligne. Affichez le code via la chaîne d'appel de fonction. Familiez les structures de données sous-jacentes utilisées par Redis. Identifiez l'algorithme utilisé par Redis.
 Comment configurer le temps d'exécution du script LUA dans Centos Redis
Apr 14, 2025 pm 02:12 PM
Comment configurer le temps d'exécution du script LUA dans Centos Redis
Apr 14, 2025 pm 02:12 PM
Sur CentOS Systems, vous pouvez limiter le temps d'exécution des scripts LUA en modifiant les fichiers de configuration Redis ou en utilisant des commandes Redis pour empêcher les scripts malveillants de consommer trop de ressources. Méthode 1: Modifiez le fichier de configuration Redis et localisez le fichier de configuration Redis: le fichier de configuration redis est généralement situé dans /etc/redis/redis.conf. Edit Fichier de configuration: Ouvrez le fichier de configuration à l'aide d'un éditeur de texte (tel que VI ou NANO): Sudovi / etc / redis / redis.conf Définissez le délai d'exécution du script LUA: Ajouter ou modifier les lignes suivantes dans le fichier de configuration pour définir le temps d'exécution maximal du script LUA (unité: millisecondes)
 Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Comment utiliser la ligne de commande redis
Apr 10, 2025 pm 10:18 PM
Utilisez l'outil de ligne de commande redis (Redis-CLI) pour gérer et utiliser Redis via les étapes suivantes: Connectez-vous au serveur, spécifiez l'adresse et le port. Envoyez des commandes au serveur à l'aide du nom et des paramètres de commande. Utilisez la commande d'aide pour afficher les informations d'aide pour une commande spécifique. Utilisez la commande QUIT pour quitter l'outil de ligne de commande.
