
 base de données
tutoriel mysql
Comment configurer Mysql plusieurs maîtres et un esclave dans Centos7
base de données
tutoriel mysql
Comment configurer Mysql plusieurs maîtres et un esclave dans Centos7
Comment configurer Mysql plusieurs maîtres et un esclave dans Centos7

Scénario commercial :
Plusieurs activités principales de l'entreprise ont été indépendantes et placées sur différents serveurs de bases de données, mais une entreprise doit être associée à plusieurs bibliothèques commerciales pour des statistiques de requêtes communes. À ce stade, il est nécessaire de synchroniser les différentes données de la base de données métier avec une base de données esclave pour les statistiques. Selon le principe de synchronisation maître-esclave MySQL, la solution de plusieurs esclaves et d'un maître est utilisée. La bibliothèque principale utilise le moteur innodb et la bibliothèque esclave utilise le moteur myisam pour ouvrir plusieurs instances et synchroniser les données de plusieurs instances dans le même répertoire, et accéder aux données des autres instances dans une instance via des tables de vidage.
Idées de solutions :
1. Utilisez le moteur innodb pour la base de données principale et définissez sql_mode sur no_auto_create_user
2 Activez plusieurs instances de la bibliothèque esclave et synchronisez les données de plusieurs bibliothèques principales avec le même répertoire de données via. réplication maître-esclave. Chaque instance de la bibliothèque esclave correspond à une bibliothèque maître. Plusieurs instances utilisent le même répertoire de données.
3. Utilisez le moteur myisam depuis la base de données et fermez le moteur innodb par défaut depuis la base de données. Le moteur myisam peut accéder aux tables d'autres instances dans le même répertoire de données.
4. Chaque instance de la bibliothèque esclave doit exécuter des tables de vidage pour voir les modifications de données des autres tables d'instance. Vous pouvez définir la planification des tâches crontab pour actualiser la table sur la première instance toutes les minutes afin que l'instance par défaut soit connectée au programme. peut voir les données en temps réel du tableau changer.
5. Définissez le sql_mode de la bibliothèque principale et de la bibliothèque esclave sur no_auto_create_user. Ce n'est qu'ainsi que le SQL du moteur innodb de la bibliothèque principale peut être synchronisé avec la bibliothèque esclave pour être exécuté avec succès.
Schéma de l'architecture du projet :
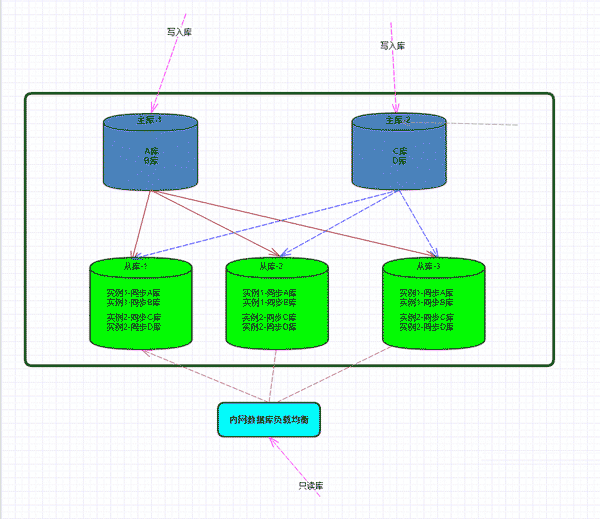
Description de l'environnement :
Bibliothèque principale-1 : 192.168.1.1
Bibliothèque principale-2 : 192.168.1.2
Bibliothèque esclave-3 : .168.1.3
Depuis le bibliothèque -3 : 192.168.1.4
Bibliothèque esclave -3 : 192.168.1.5
Étapes de mise en œuvre : (les étapes d'installation de MySQL ne sont pas décrites ici)
1. Fichier de configuration de la base de données principale, plusieurs fichiers de configuration de la base de données principale ne peuvent pas être à l'exception du serveur. -id Tout le reste est pareil.
[root@masterdb01 ~]#cat /etc/my.cnf [client] port= 3306 socket= /tmp/mysql.sock [mysqld] port = 3306 basedir = /usr/local/mysql datadir = /data/mysql character-set-server = utf8mb4 default-storage-engine = innodb socket = /tmp/mysql.sock skip-name-resolv = 1 open_files_limit = 65535 back_log = 103 max_connections = 512 max_connect_errors = 100000 table_open_cache = 2048 tmp-table-size = 32m max-heap-table-size = 32m #query-cache-type = 0 query-cache-size = 0 external-locking = false max_allowed_packet = 32m sort_buffer_size = 2m join_buffer_size = 2m thread_cache_size = 51 query_cache_size = 32m tmp_table_size = 96m max_heap_table_size = 96m query_cache_type=1 log-error=/data/logs/mysqld.log slow_query_log = 1 slow_query_log_file = /data/logs/slow.log long_query_time = 0.1 # binary logging # server-id = 1 log-bin = /data/binlog/mysql-bin log-bin-index =/data/binlog/mysql-bin.index expire-logs-days = 14 sync_binlog = 1 binlog_cache_size = 4m max_binlog_cache_size = 8m max_binlog_size = 1024m log_slave_updates #binlog_format = row binlog_format = mixed //这里使用的混合模式复制 relay_log_recovery = 1 #不需要同步的表 replicate-wild-ignore-table=mydb.sp_counter #不需要同步的库 replicate-ignore-db = mysql,information_schema,performance_schema key_buffer_size = 32m read_buffer_size = 1m read_rnd_buffer_size = 16m bulk_insert_buffer_size = 64m myisam_sort_buffer_size = 128m myisam_max_sort_file_size = 10g myisam_repair_threads = 1 myisam_recover transaction_isolation = repeatable-read innodb_additional_mem_pool_size = 16m innodb_buffer_pool_size = 5734m innodb_buffer_pool_load_at_startup = 1 innodb_buffer_pool_dump_at_shutdown = 1 innodb_data_file_path = ibdata1:1024m:autoextend innodb_flush_log_at_trx_commit = 2 innodb_log_buffer_size = 32m innodb_log_file_size = 2g innodb_log_files_in_group = 2 innodb_io_capacity = 4000 innodb_io_capacity_max = 8000 innodb_max_dirty_pages_pct = 50 innodb_flush_method = o_direct innodb_file_format = barracuda innodb_file_format_max = barracuda innodb_lock_wait_timeout = 10 innodb_rollback_on_timeout = 1 innodb_print_all_deadlocks = 1 innodb_file_per_table = 1 innodb_locks_unsafe_for_binlog = 0 [mysqldump] quick max_allowed_packet = 32m
2. Fichier de configuration de la bibliothèque esclave. Plusieurs fichiers de configuration esclave doivent être identiques, à l'exception de l'ID du serveur.
[root@slavedb01 ~]# cat /etc/my.cnf [client] port= 3306 socket= /tmp/mysql.sock [mysqld_multi] # 指定相关命令的路径 mysqld = /usr/local/mysql/bin/mysqld_safe mysqladmin = /usr/local/mysql/bin/mysqladmin ##复制主库1的数据## [mysqld2] port = 3306 basedir = /usr/local/mysql datadir = /data/mysql character-set-server = utf8mb4 #指定实例1的sock文件和pid文件 socket = /tmp/mysql.sock pid-file=/data/mysql/mysql.pid skip-name-resolv = 1 open_files_limit = 65535 back_log = 103 max_connections = 512 max_connect_errors = 100000 table_open_cache = 2048 tmp-table-size = 32m max-heap-table-size = 32m query-cache-size = 0 external-locking = false max_allowed_packet = 32m sort_buffer_size = 2m join_buffer_size = 2m thread_cache_size = 51 query_cache_size = 32m tmp_table_size = 96m max_heap_table_size = 96m query_cache_type=1 #指定第一个实例的错误日志和慢查询日志路径 log-error=/data/logs/mysqld.log slow_query_log = 1 slow_query_log_file = /data/logs/slow.log long_query_time = 0.1 # binary logging# # 指定实例1的binlog和relaylog路径为/data/binlog目录 # 每个从库和每个实例的server_id不能一样。 server-id = 2 log-bin = /data/binlog/mysql-bin log-bin-index =/data/binlog/mysql-bin.index relay_log = /data/binlog/mysql-relay-bin relay_log_index = /data/binlog/mysql-relay.index master-info-file = /data/mysql/master.info relay_log_info_file = /data/mysql/relay-log.info read_only = 1 expire-logs-days = 14 sync_binlog = 1 #需要同步的库,如果不设置,默认同步所有库。 #replicate-do-db = xxx #不需要同步的表 replicate-wild-ignore-table=mydb.sp_counter #不需要同步的库 replicate-ignore-db = mysql,information_schema,performance_schema binlog_cache_size = 4m max_binlog_cache_size = 8m max_binlog_size = 1024m log_slave_updates =1 #binlog_format = row binlog_format = mixed relay_log_recovery = 1 key_buffer_size = 32m read_buffer_size = 1m read_rnd_buffer_size = 16m bulk_insert_buffer_size = 64m myisam_sort_buffer_size = 128m myisam_max_sort_file_size = 10g myisam_repair_threads = 1 myisam_recover #设置默认引擎为myisam,下面这些参数一定要加上。 default-storage-engine=myisam default-tmp-storage-engine=myisam #关闭innodb引擎 skip-innodb innodb = off disable-innodb #设置sql_mode模式为no_auto_create_user sql_mode = no_auto_create_user #关闭innodb引擎 loose-skip-innodb loose-innodb-trx=0 loose-innodb-locks=0 loose-innodb-lock-waits=0 loose-innodb-cmp=0 loose-innodb-cmp-per-index=0 loose-innodb-cmp-per-index-reset=0 loose-innodb-cmp-reset=0 loose-innodb-cmpmem=0 loose-innodb-cmpmem-reset=0 loose-innodb-buffer-page=0 loose-innodb-buffer-page-lru=0 loose-innodb-buffer-pool-stats=0 loose-innodb-metrics=0 loose-innodb-ft-default-stopword=0 loose-innodb-ft-inserted=0 loose-innodb-ft-deleted=0 loose-innodb-ft-being-deleted=0 loose-innodb-ft-config=0 loose-innodb-ft-index-cache=0 loose-innodb-ft-index-table=0 loose-innodb-sys-tables=0 loose-innodb-sys-tablestats=0 loose-innodb-sys-indexes=0 loose-innodb-sys-columns=0 loose-innodb-sys-fields=0 loose-innodb-sys-foreign=0 loose-innodb-sys-foreign-cols=0 ##复制主库2的数据## [mysqld3] port = 3307 basedir = /usr/local/mysql datadir = /data/mysql character-set-server = utf8mb4 #指定实例2的sock文件和pid文件 socket = /tmp/mysql3.sock pid-file=/data/mysql/mysql3.pid skip-name-resolv = 1 open_files_limit = 65535 back_log = 103 max_connections = 512 max_connect_errors = 100000 table_open_cache = 2048 tmp-table-size = 32m max-heap-table-size = 32m query-cache-size = 0 external-locking = false max_allowed_packet = 32m sort_buffer_size = 2m join_buffer_size = 2m thread_cache_size = 51 query_cache_size = 32m tmp_table_size = 96m max_heap_table_size = 96m query_cache_type=1 log-error=/data/logs/mysqld3.log slow_query_log = 1 slow_query_log_file = /data/logs/slow3.log long_query_time = 0.1 # binary logging # # 这里一定要注意,不能把两个实例的binlog和relaylog放到同一个目录, # 这里指定实例2的binlog日志为/data/binlog2目录 # 每个从库和每个实例的server_id不能一样。 server-id = 22 log-bin = /data/binlog2/mysql-bin log-bin-index =/data/binlog2/mysql-bin.index relay_log = /data/binlog2/mysql-relay-bin relay_log_index = /data/binlog2/mysql-relay.index master-info-file = /data/mysql/master3.info relay_log_info_file = /data/mysql/relay-log3.info read_only = 1 expire-logs-days = 14 sync_binlog = 1 #不需要复制的库 replicate-ignore-db = mysql,information_schema,performance_schema binlog_cache_size = 4m max_binlog_cache_size = 8m max_binlog_size = 1024m log_slave_updates =1 #binlog_format = row binlog_format = mixed relay_log_recovery = 1 key_buffer_size = 32m read_buffer_size = 1m read_rnd_buffer_size = 16m bulk_insert_buffer_size = 64m myisam_sort_buffer_size = 128m myisam_max_sort_file_size = 10g myisam_repair_threads = 1 myisam_recover #设置默认引擎为myisam default-storage-engine=myisam default-tmp-storage-engine=myisam #关闭innodb引擎 skip-innodb innodb = off disable-innodb #设置sql_mode模式为no_auto_create_user sql_mode = no_auto_create_user #关闭innodb引擎,下面这些参数一定要加上。 loose-skip-innodb loose-innodb-trx=0 loose-innodb-locks=0 loose-innodb-lock-waits=0 loose-innodb-cmp=0 loose-innodb-cmp-per-index=0 loose-innodb-cmp-per-index-reset=0 loose-innodb-cmp-reset=0 loose-innodb-cmpmem=0 loose-innodb-cmpmem-reset=0 loose-innodb-buffer-page=0 loose-innodb-buffer-page-lru=0 loose-innodb-buffer-pool-stats=0 loose-innodb-metrics=0 loose-innodb-ft-default-stopword=0 loose-innodb-ft-inserted=0 loose-innodb-ft-deleted=0 loose-innodb-ft-being-deleted=0 loose-innodb-ft-config=0 loose-innodb-ft-index-cache=0 loose-innodb-ft-index-table=0 loose-innodb-sys-tables=0 loose-innodb-sys-tablestats=0 loose-innodb-sys-indexes=0 loose-innodb-sys-columns=0 loose-innodb-sys-fields=0 loose-innodb-sys-foreign=0 loose-innodb-sys-foreign-cols=0 [mysqldump] quick max_allowed_packet = 32m ```
3. Définissez la bibliothèque principale sql_mode Par défaut, mysql5.6 doit définir sql_mode dans le fichier de démarrage pour prendre effet.
# cat /etc/init.d/mysqld
#other_args="$*" # uncommon, but needed when called from an rpm upgrade action
# expected: "--skip-networking --skip-grant-tables"
# they are not checked here, intentionally, as it is the resposibility
# of the "spec" file author to give correct arguments only.
#将上面默认的#other_args开启后改为
other_args="--sql-mode=no_auto_create_user"4. Activez les bases de données maître et esclave
#主库 service mysqld start #开启从库的二个实例 /usr/local/mysql/bin/mysqld_multi start 2 /usr/local/mysql/bin/mysqld_multi start 3
5 Autorisez les comptes de copie sur les deux bases de données maîtres respectivement
#需要授权三个从库的ip可以同步 mysql> grant replication slave on *.* to rep@'192.168.1.3' identified by 'rep123'; mysql> grant replication slave on *.* to rep@'192.168.1.4' identified by 'rep123'; mysql> grant replication slave on *.* to rep@'192.168.1.5' identified by 'rep123'; mysql> flush privileges;
6.
#进入第一个实例执行 $ mysql -s /tmp/mysql.sock mysql> change master to master_host='192.168.1.1',master_user='rep',master_password='rep123',master_log_file='mysql-bin.000001',master_log_pos=112; #进入第二个实例执行 $ mysql -s /tmp/mysql3.sock mysql> change master to master_host='192.168.1.2',master_user='rep',master_password='rep123',master_log_file='mysql-bin.000001',master_log_pos=112;
7. Testez la synchronisation des données
Créez des tables et insérez des données dans les deux bases de données maître respectivement. Lorsque vous vérifiez la base de données esclave, vous pouvez voir que les deux bases de données maîtres sont synchronisées avec toutes les données de la même base de données esclave.
8. Définissez un calendrier de tâches sur chaque serveur esclave pour actualiser la table de la première instance toutes les minutes
# crontab -l */1 * * * * mysql -s /tmp/mysql.sock -e 'flush tables;'
Les pièges de plusieurs maîtres et un esclave dans mysql5.6
1. 6 est innodb Par défaut, le paramètre no_engine_substitution en mode sql_mode du maître et de l'esclave doit être désactivé lors de la synchronisation. Si vous ne désactivez pas la synchronisation innodb avec SQL sur la base de données esclave, le moteur innodb ne sera pas trouvé et la synchronisation échouera.
2. Lorsque vous ouvrez plusieurs instances de mysql5.6, le fichier de configuration my.cnf sera généré dans le répertoire d'installation de votre base de données (/usr/local/mysql/) lorsque vous la démarrerez pour la première fois. , l'installation de la base de données sera lue en premier dans le répertoire. Par conséquent, plusieurs instances ne prennent pas effet.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL: Concepts simples pour l'apprentissage facile
Apr 10, 2025 am 09:29 AM
MySQL est un système de gestion de base de données relationnel open source. 1) Créez une base de données et des tables: utilisez les commandes CreateDatabase et CreateTable. 2) Opérations de base: insérer, mettre à jour, supprimer et sélectionner. 3) Opérations avancées: jointure, sous-requête et traitement des transactions. 4) Compétences de débogage: vérifiez la syntaxe, le type de données et les autorisations. 5) Suggestions d'optimisation: utilisez des index, évitez de sélectionner * et utilisez les transactions.
 Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Comment ouvrir phpmyadmin
Apr 10, 2025 pm 10:51 PM
Vous pouvez ouvrir PHPMYADMIN via les étapes suivantes: 1. Connectez-vous au panneau de configuration du site Web; 2. Trouvez et cliquez sur l'icône PHPMYADMIN; 3. Entrez les informations d'identification MySQL; 4. Cliquez sur "Connexion".
 MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL: une introduction à la base de données la plus populaire au monde
Apr 12, 2025 am 12:18 AM
MySQL est un système de gestion de la base de données relationnel open source, principalement utilisé pour stocker et récupérer les données rapidement et de manière fiable. Son principe de travail comprend les demandes des clients, la résolution de requête, l'exécution des requêtes et les résultats de retour. Des exemples d'utilisation comprennent la création de tables, l'insertion et la question des données et les fonctionnalités avancées telles que les opérations de jointure. Les erreurs communes impliquent la syntaxe SQL, les types de données et les autorisations, et les suggestions d'optimisation incluent l'utilisation d'index, les requêtes optimisées et la partition de tables.
 Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
Pourquoi utiliser MySQL? Avantages et avantages
Apr 12, 2025 am 12:17 AM
MySQL est choisi pour ses performances, sa fiabilité, sa facilité d'utilisation et son soutien communautaire. 1.MySQL fournit des fonctions de stockage et de récupération de données efficaces, prenant en charge plusieurs types de données et opérations de requête avancées. 2. Adoptez l'architecture client-serveur et plusieurs moteurs de stockage pour prendre en charge l'optimisation des transactions et des requêtes. 3. Facile à utiliser, prend en charge une variété de systèmes d'exploitation et de langages de programmation. 4. Avoir un solide soutien communautaire et fournir des ressources et des solutions riches.
 Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Comment utiliser un seul fileté redis
Apr 10, 2025 pm 07:12 PM
Redis utilise une architecture filetée unique pour fournir des performances élevées, une simplicité et une cohérence. Il utilise le multiplexage d'E / S, les boucles d'événements, les E / S non bloquantes et la mémoire partagée pour améliorer la concurrence, mais avec des limites de limitations de concurrence, un point d'échec unique et inadapté aux charges de travail à forte intensité d'écriture.
 MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL: Compétences essentielles pour les développeurs
Apr 10, 2025 am 09:30 AM
MySQL et SQL sont des compétences essentielles pour les développeurs. 1.MySQL est un système de gestion de base de données relationnel open source, et SQL est le langage standard utilisé pour gérer et exploiter des bases de données. 2.MySQL prend en charge plusieurs moteurs de stockage via des fonctions de stockage et de récupération de données efficaces, et SQL termine des opérations de données complexes via des instructions simples. 3. Les exemples d'utilisation comprennent les requêtes de base et les requêtes avancées, telles que le filtrage et le tri par condition. 4. Les erreurs courantes incluent les erreurs de syntaxe et les problèmes de performances, qui peuvent être optimisées en vérifiant les instructions SQL et en utilisant des commandes Explication. 5. Les techniques d'optimisation des performances incluent l'utilisation d'index, d'éviter la numérisation complète de la table, d'optimiser les opérations de jointure et d'améliorer la lisibilité du code.
 Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
Place de MySQL: bases de données et programmation
Apr 13, 2025 am 12:18 AM
La position de MySQL dans les bases de données et la programmation est très importante. Il s'agit d'un système de gestion de base de données relationnel open source qui est largement utilisé dans divers scénarios d'application. 1) MySQL fournit des fonctions efficaces de stockage de données, d'organisation et de récupération, en prenant en charge les systèmes Web, mobiles et de niveau d'entreprise. 2) Il utilise une architecture client-serveur, prend en charge plusieurs moteurs de stockage et optimisation d'index. 3) Les usages de base incluent la création de tables et l'insertion de données, et les usages avancés impliquent des jointures multiples et des requêtes complexes. 4) Des questions fréquemment posées telles que les erreurs de syntaxe SQL et les problèmes de performances peuvent être déboguées via la commande Explication et le journal de requête lente. 5) Les méthodes d'optimisation des performances comprennent l'utilisation rationnelle des indices, la requête optimisée et l'utilisation des caches. Les meilleures pratiques incluent l'utilisation des transactions et des acteurs préparés
 Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
Comment construire une base de données SQL
Apr 09, 2025 pm 04:24 PM
La construction d'une base de données SQL comprend 10 étapes: sélectionner des SGBD; Installation de SGBD; créer une base de données; créer une table; insérer des données; récupération de données; Mise à jour des données; supprimer des données; gérer les utilisateurs; sauvegarde de la base de données.
