
 Périphériques technologiques
IA
Pratique de déploiement de la localisation d'Alpaca-lora avec un grand modèle de langage GPT
Périphériques technologiques
IA
Pratique de déploiement de la localisation d'Alpaca-lora avec un grand modèle de langage GPT
Pratique de déploiement de la localisation d'Alpaca-lora avec un grand modèle de langage GPT

Présentation du modèle
Le modèle Alpaca est un modèle open source LLM (Large Language Model, large langage) développé par l'Université de Stanford. Il s'agit d'un modèle de 7 milliards affiné à partir du modèle LLaMA 7B (open source 7B par la société Meta). 52 000 instructions. Paramètres (plus les paramètres du modèle sont grands, plus la capacité de raisonnement du modèle est forte et, bien sûr, plus le coût de formation du modèle est élevé).
LoRA, le nom anglais complet est Low-Rank Adaptation of Large Language Models, littéralement traduit par adaptation de bas niveau de grands modèles de langage. Il s'agit d'une technologie développée par les chercheurs de Microsoft pour résoudre le réglage fin des grands modèles de langage. Si vous souhaitez qu'un grand modèle de langage pré-entraîné soit capable d'effectuer des tâches dans un domaine spécifique, vous devez généralement effectuer un réglage fin. Cependant, les dimensions actuelles des paramètres des grands modèles de langage avec de bons effets d'inférence sont très, très grandes. et certains comptent même des centaines de milliards de dimensions. Si vous effectuez directement un réglage fin sur un grand modèle de langage, cela nécessitera une très grande quantité de calculs et un coût très élevé.
La méthode de LoRA consiste à geler les paramètres du modèle pré-entraînés, puis à injecter des couches pouvant être entraînées dans chaque bloc Transformer. Puisqu'il n'est pas nécessaire de recalculer le gradient des paramètres du modèle, la quantité de calcul sera considérablement réduite.
Comme le montre la figure ci-dessous, l'idée principale est d'ajouter un contournement au modèle pré-entraîné d'origine et d'effectuer une réduction de dimensionnalité puis une opération de dimensionnalité. Pendant l'entraînement, les paramètres du modèle pré-entraîné sont fixes et seules la matrice de réduction de dimensionnalité A et la matrice d'amélioration de dimensionnalité B sont entraînées. Les dimensions d'entrée et de sortie du modèle restent inchangées, et le BA et les paramètres du modèle de langage pré-entraîné sont superposés à la sortie.
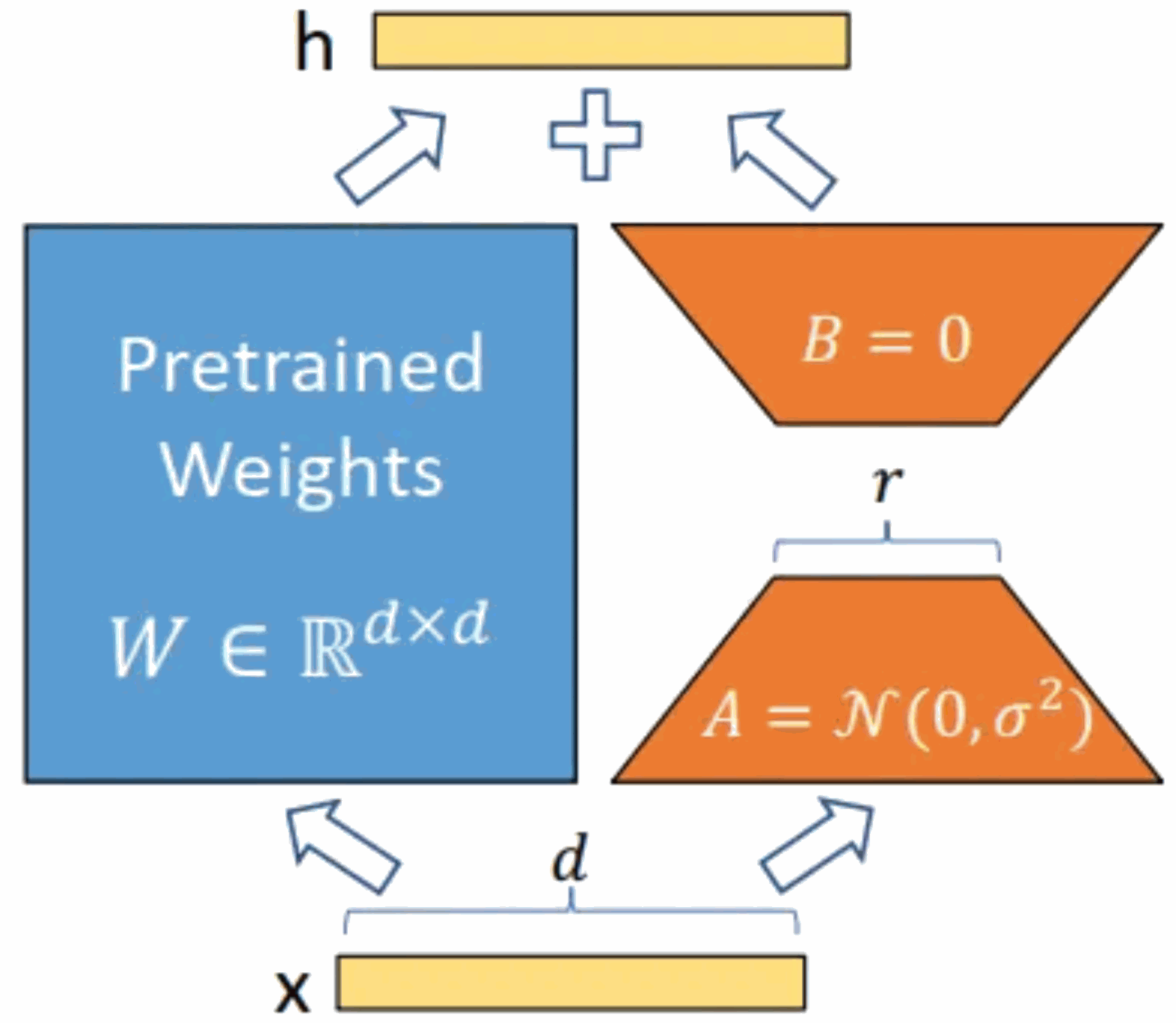
Initialisez A avec une distribution gaussienne aléatoire et initialisez B avec une matrice 0. Cela garantit que le nouveau contournement BA = 0 pendant la formation, n'ayant ainsi aucun impact sur les résultats du modèle. Pendant le raisonnement, les résultats des parties gauche et droite sont additionnés, c'est-à-dire h=Wx+BAx=(W+BA)x. Par conséquent, ajoutez simplement le produit matriciel BA après l'entraînement et la matrice de poids d'origine W comme nouvelle. poids. Les paramètres peuvent être remplacés par W du modèle de langage pré-entraîné d'origine, et aucune ressource informatique supplémentaire ne sera ajoutée. Le plus grand avantage de LoRA est qu’il s’entraîne plus rapidement et utilise moins de mémoire.
Le modèle Alpaca-lora utilisé pour la pratique du déploiement localisé dans cet article est une version adaptée d'ordre inférieur du modèle Alpaca. Cet article mettra en pratique le processus de déploiement, de réglage fin et d'inférence de localisation du modèle Alpaca-lora et décrira les étapes pertinentes.
Déploiement de l'environnement du serveur GPU
Le serveur GPU déployé dans cet article dispose de 4 GPU indépendants. Le modèle est le P40. La puissance de calcul d'un seul P40 est équivalente à la puissance de calcul de 60 CPU avec la même fréquence principale.

Si vous estimez que la carte physique est trop chère juste pour les tests, vous pouvez également utiliser la "version de remplacement" - serveur cloud GPU. Par rapport aux cartes physiques, l'utilisation de serveurs cloud GPU pour créer non seulement garantit un calcul flexible hautes performances, mais présente également les avantages suivants :
- Performances à coût élevé : facturées à l'heure, seulement une douzaine de yuans par heure, et peuvent être déployées en fonction à vos besoins à tout moment ; les avantages du cloud computing tels que la gestion flexible des ressources, l'évolutivité et la mise à l'échelle élastique peuvent ajuster rapidement les ressources informatiques en fonction des besoins de formation professionnels ou personnels pour répondre aux besoins de formation et de déploiement des modèles
- Ouverture : l'ouverture du cloud computing ; permet aux utilisateurs d'être plus Il est facile de partager et de collaborer sur des ressources, offrant des opportunités de coopération plus larges pour la recherche et l'application de modèles d'IA
- API et SDK riches : les fournisseurs de cloud computing fournissent des API et des SDK riches, permettant aux utilisateurs d'accéder facilement aux cloud Développement sur mesure et intégration des différents services et fonctions de la plateforme.
L'hôte cloud GPU de JD Cloud réalise actuellement l'événement 618, ce qui est très rentable
https://www.php.cn/link/5d3145e1226fd39ee3b3039bfa90c95d
Après avoir obtenu le serveur GPU, le premier La chose que nous devons faire est d'installer le pilote de la carte graphique et le pilote CUDA (est une plate-forme informatique lancée par le fabricant de cartes graphiques NVIDIA. CUDA est une architecture informatique parallèle générale lancée par NVIDIA, qui permet au GPU de résoudre des problèmes informatiques complexes).
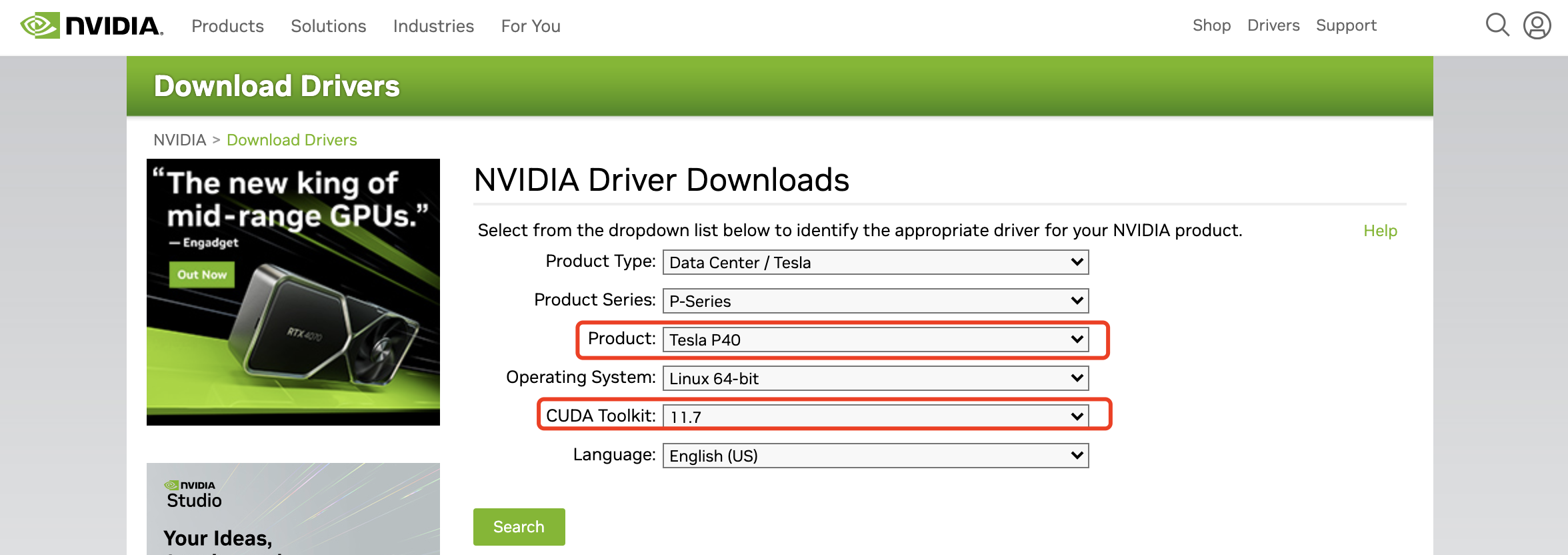
Le pilote de la carte graphique doit se rendre sur le site officiel de NVIDIA pour trouver le modèle de carte graphique correspondant et la version CUDA adaptée :
https://www.nvidia.com/Download/index.aspx et sélectionner le graphique correspondant. carte et version CUDA Vous pouvez télécharger le fichier du pilote.
Le fichier que j'ai téléchargé est
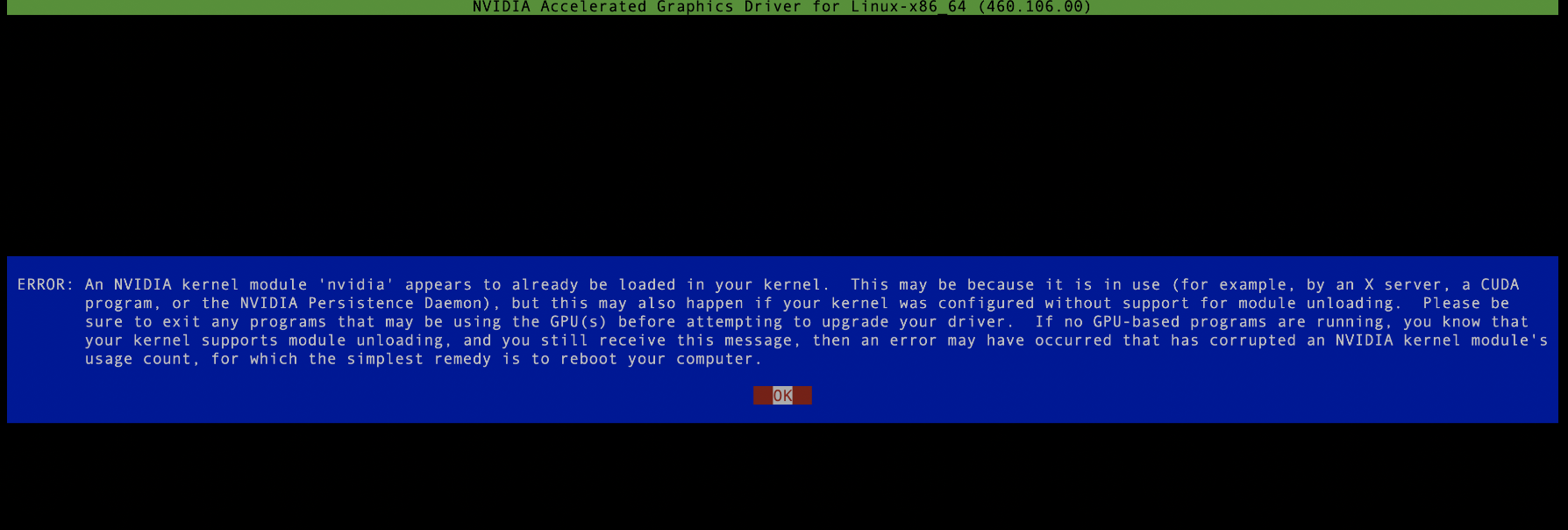
NVIDIA-Linux-x86_64-515.105.01.run, il s'agit d'un fichier exécutable, vous pouvez l'exécuter avec les autorisations root. Notez qu'il ne peut pas y avoir de processus nvidia en cours d'exécution pendant le processus d'installation du pilote. Si nécessaire, supprimez-les tous, sinon le processus n'est pas exécuté. l'installation échouera. , comme le montre l'image ci-dessous :
Passez ensuite à l'étape suivante. Si aucune erreur n'est signalée, l'installation réussira. Afin de vérifier les ressources de la carte graphique ultérieurement, il est préférable d'installer un autre outil de surveillance de la carte graphique, tel que nvitop, utilisez simplement pip install nvitop. Notez ici que puisque les versions python des différents serveurs sont différentes, il est préférable d'installer anaconda. pour déployer votre propre espace python privé pour éviter que diverses erreurs étranges ne se produisent lors de l'exécution. Les étapes spécifiques sont les suivantes :
1 Installez la méthode de téléchargement : wget
https://repo.anaconda.com/archive/Anaconda3-5.3. .0-Linux-x86_64.sh. Commande d'installation : sh Anaconda3-5.3.0-Linux-x86_64.sh Entrez "oui" pour chaque étape d'installation, et terminez enfin l'installation après conda init, de sorte qu'à chaque fois que vous entrez dans la session de l'utilisateur d'installation, vous entrez directement la vôtre environnement python. Si vous sélectionnez non lors de la dernière étape de l'installation, c'est-à-dire que conda init n'est pas effectué, vous pourrez ultérieurement accéder à l'environnement python privé via la source /home/jd_ad_sfxn/anaconda3/bin/activate.
2. Installer setuptools Ensuite, vous devez installer les outils de configuration de l'outil d'empaquetage et de distribution, adresse de téléchargement : wget
https://files.pythonhosted.org/packages/26/e5/9897eee1100b166a61f91b68528cb692e8887300d9cbdaa1a349f6304b79/setuptools-4. Installation de 0.5.0.zip commande : décompressez setuptools-40.5.0.zip cd setuptools-40.5.0/ python setup.py install
3. Installez pip Adresse de téléchargement : wget
https://files.pythonhosted.org/packages/45/ae/8a0ad77defb7cc903f09e551d88b443304a9bd6e6f124e75 c0fbbf 6de8f7/pip- 18.1.tar.gz commande d'installation : tar -xzf pip-18.1.tar.gz cd pip-18.1 python setup.py install
À ce stade, le long processus d'installation est enfin terminé. créez un espace python privé et exécutez
conda create -n alpaca pythnotallow=3.9conda activate alpaca
Ensuite, vérifiez-le, comme le montre l'image ci-dessous, il a été créé avec succès.

Formation du modèle
L'environnement de base du serveur GPU a été installé ci-dessus. Nous allons maintenant commencer la formation passionnante du modèle (passionnant). Avant la formation, nous devons d'abord télécharger le fichier modèle, l'adresse de téléchargement :
https. ://github.com/tloen/alpaca-lora, l'intégralité du modèle est open source, ce qui est génial ! Tout d'abord, téléchargez le fichier modèle localement et exécutez git clone https://github.com/tloen/alpaca-lora.git.
Il y aura un dossier alpaca-lora localement, puis cd alpaca-lora à exécuter dans le dossier
pip install -r requirements.txt
Ce processus peut être lent et nécessite le téléchargement d'un grand nombre de packages dépendants depuis Internet. Divers conflits de packages peuvent également survenir. signalé au cours du processus, il n'y a aucun problème avec les dépendances, vous pouvez donc seulement essayer de découvrir ce qui manque (la résolution des dépendances des packages et des conflits de versions est en effet un casse-tête, mais si vous ne faites pas bien cette étape, le modèle ne le fera pas exécuter, vous ne pouvez donc être patient. Résolvez-le petit à petit), je n'entrerai pas dans les détails du processus douloureux ici, car différentes machines peuvent rencontrer des problèmes différents et la signification de la référence n'est pas très grande.
Si le processus d'installation est terminé et qu'il n'y a plus de messages d'erreur ni d'invite Réussite terminé, alors félicitations, vous êtes à mi-chemin de la longue marche. Vous êtes très proche du succès. Si vous persistez un peu plus longtemps, vous y parviendrez probablement. réussir. La :).
Puisque notre objectif est d'affiner le modèle, nous devons avoir un objectif de réglage précis. Puisque le modèle original ne prend pas bien en charge le chinois, notre objectif est d'utiliser le corpus chinois pour améliorer le modèle. . Cette communauté l'a également préparé pour moi. Nous pouvons simplement télécharger le corpus chinois directement et exécuter wget localement
https://github.com/LC1332/Chinese-alpaca-lora/blob/main/data/ trans_chinese_alpaca_data.json?raw. =true, téléchargez le corpus utilisé pour la formation ultérieure du modèle dans le répertoire racine d'alpaca-lora (pour une utilisation ultérieure).
Le contenu du corpus est constitué de nombreux triplets (instruction, entrée, sortie, comme le montre la figure ci-dessous). L'instruction est l'instruction permettant au modèle de faire quelque chose, l'entrée est l'entrée et la sortie est la sortie du corpus. modèle Selon les instructions et les entrées, formation Quelles informations le modèle doit-il produire pour que le modèle puisse mieux s'adapter au chinois.

好的,到现在为止,万里长征已经走完2/3了,别着急训练模型,我们现在验证一下GPU环境和CUDA版本信息,还记得之前我们安装的nvitop嘛,现在就用上了,在本地直接执行nvitop,我们就可以看到GPU环境和CUDA版本信息了,如下图:
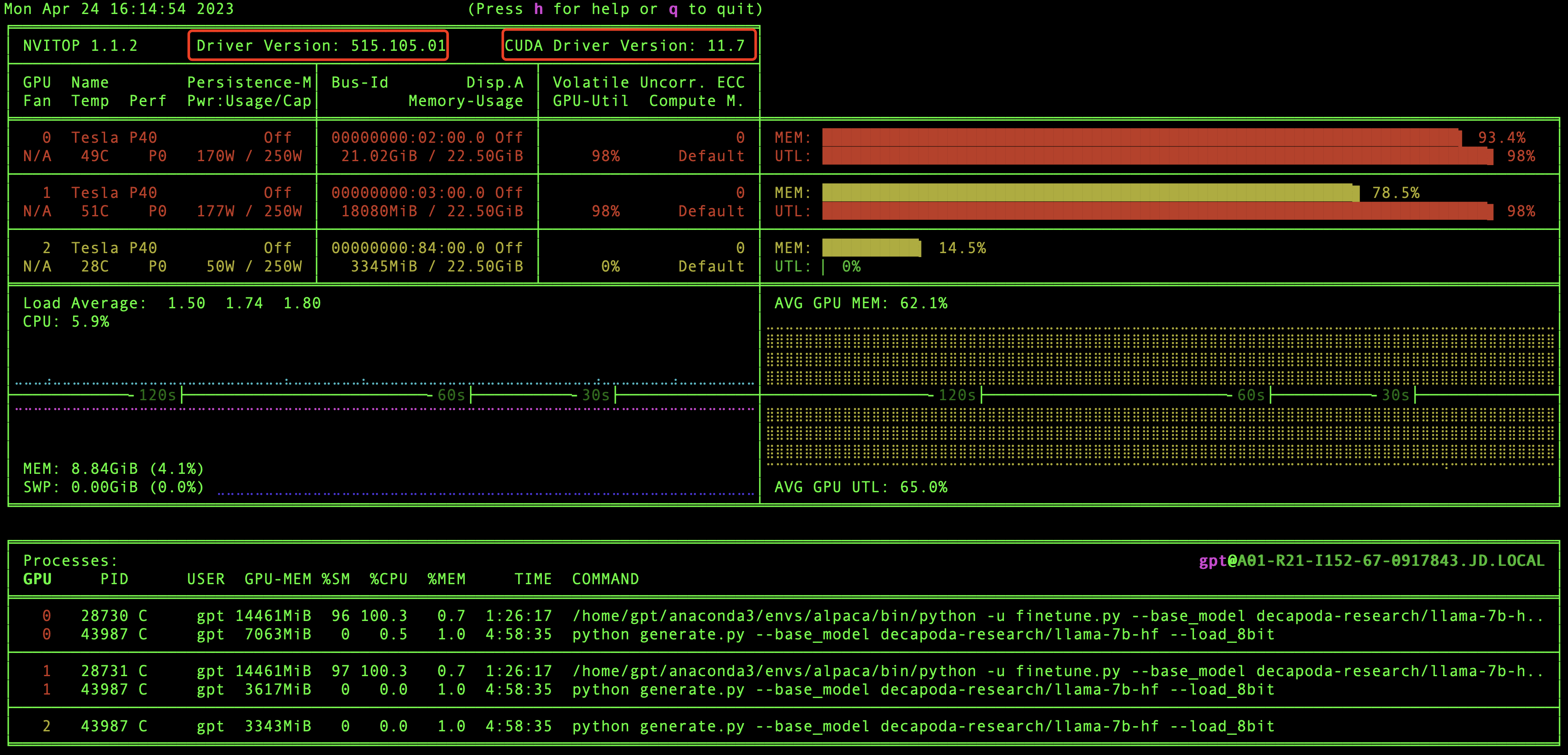
在这里我们能够看到有几块显卡,驱动版本和CUDA版本等信息,当然最重要的我们还能看到GPU资源的实时使用情况。
怎么还没到模型训练呢,别着急呀,这就来啦。
我们先到根目录下然后执行训练模型命令:
如果是单个GPU,那么执行命令即可:
python finetune.py \--base_model 'decapoda-research/llama-7b-hf' \--data_path 'trans_chinese_alpaca_data.json' \--output_dir './lora-alpaca-zh'
如果是多个GPU,则执行:
WORLD_SIZE=2 CUDA_VISIBLE_DEVICES=0,1 torchrun \--nproc_per_node=2 \--master_port=1234 \finetune.py \--base_model 'decapoda-research/llama-7b-hf' \--data_path 'trans_chinese_alpaca_data.json' \--output_dir './lora-alpaca-zh'
如果可以看到进度条在走,说明模型已经启动成功啦。
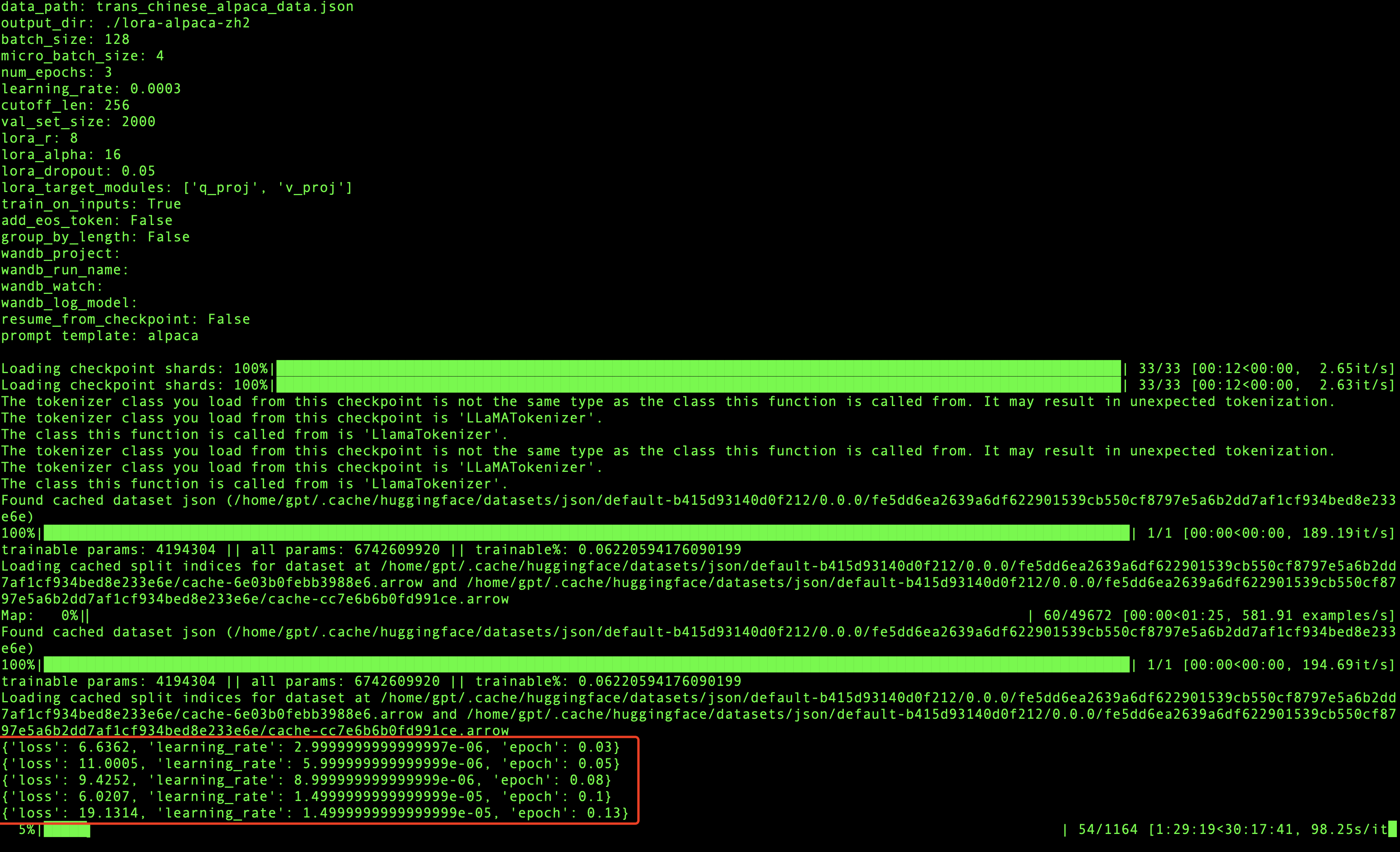
在模型训练过程中,每迭代一定数量的数据就会打印相关的信息,会输出损失率,学习率和代信息,如上图所示,当loss波动较小时,模型就会收敛,最终训练完成。
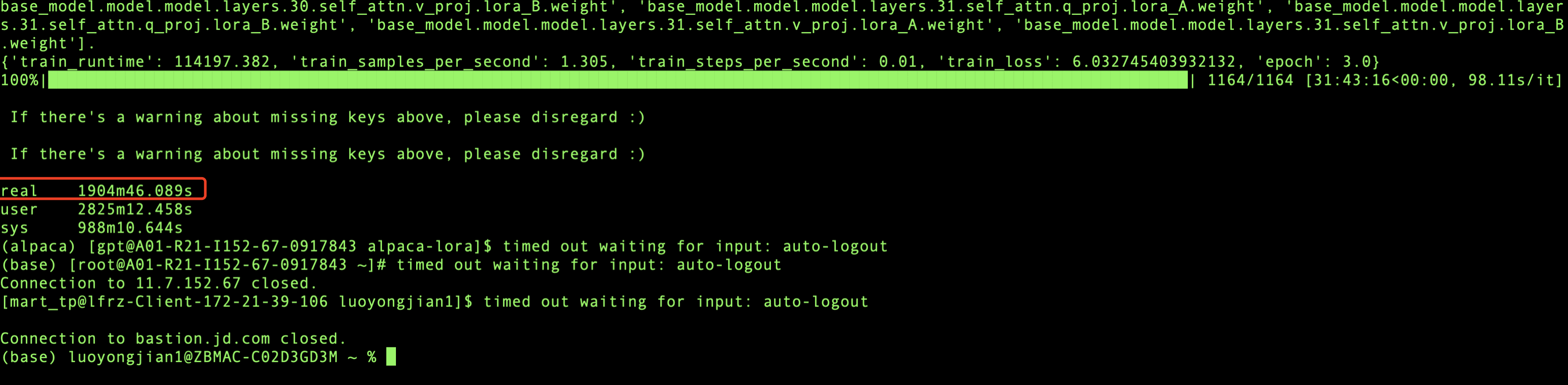
我用的是2块GPU显卡进行训练,总共训练了1904分钟,也就是31.73个小时,模型就收敛了,模型训练是个漫长的过程,所以在训练的时候我们可以适当的放松一下,做点其他的事情:)。
模型推理
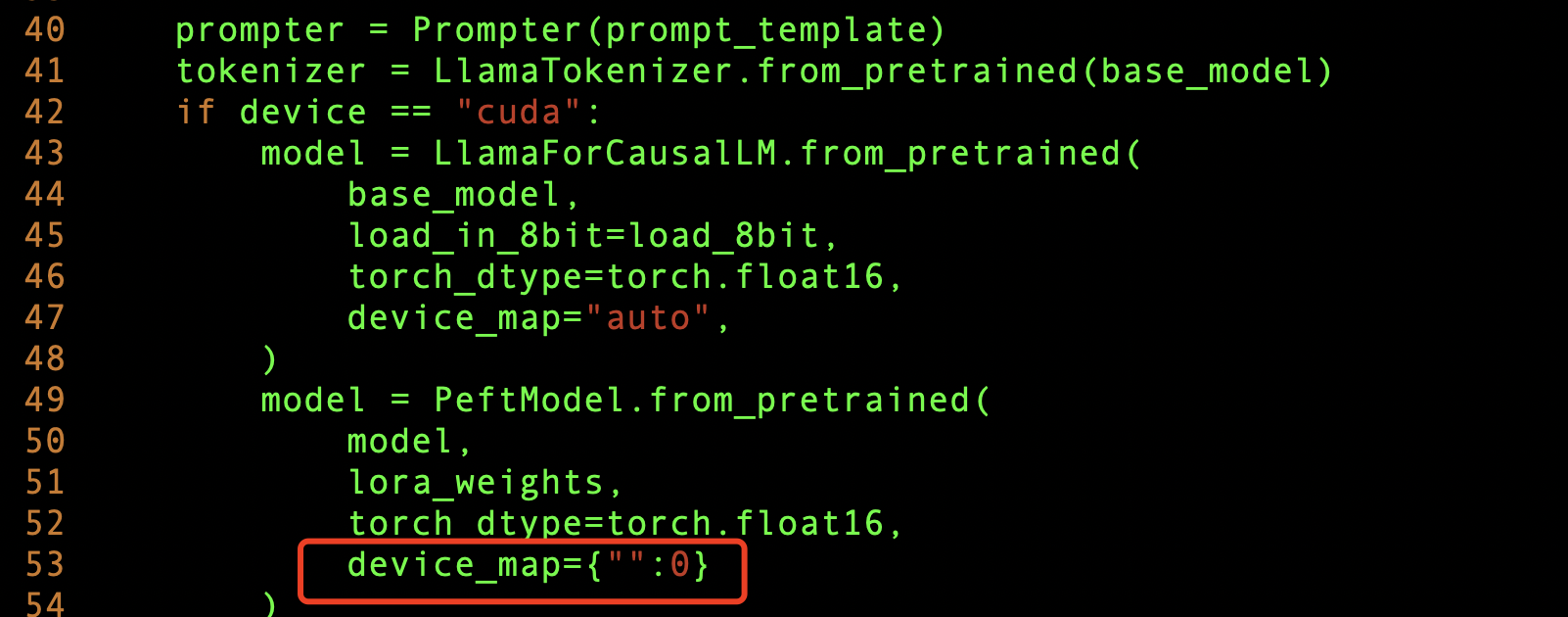
模型训练好后,我们就可以测试一下模型的训练效果了,由于我们是多个GPU显卡,所以想把模型参数加载到多个GPU上,这样会使模型推理的更快,需要修改
generate.py 文件,添加下面这样即可。
然后我们把服务启起来,看看效果,根目录执行:
python generate.py --base_model "decapoda-research/llama-7b-hf" \--lora_weights './lora-alpaca-zh' \--load_8bit
其中./lora-alpaca-zh目录下的文件,就是我们刚刚fine tuning模型训练的参数所在位置,启动服务的时候把它加载到内存(这个内存指的是GPU内存)里面。
如果成功,那么最终会输出相应的IP和Port信息,如下图所示:

我们可以用浏览器访问一下看看,如果能看到页面,就说明服务已经启动成功啦。
激动ing,费了九牛二虎之力,终于成功啦!!
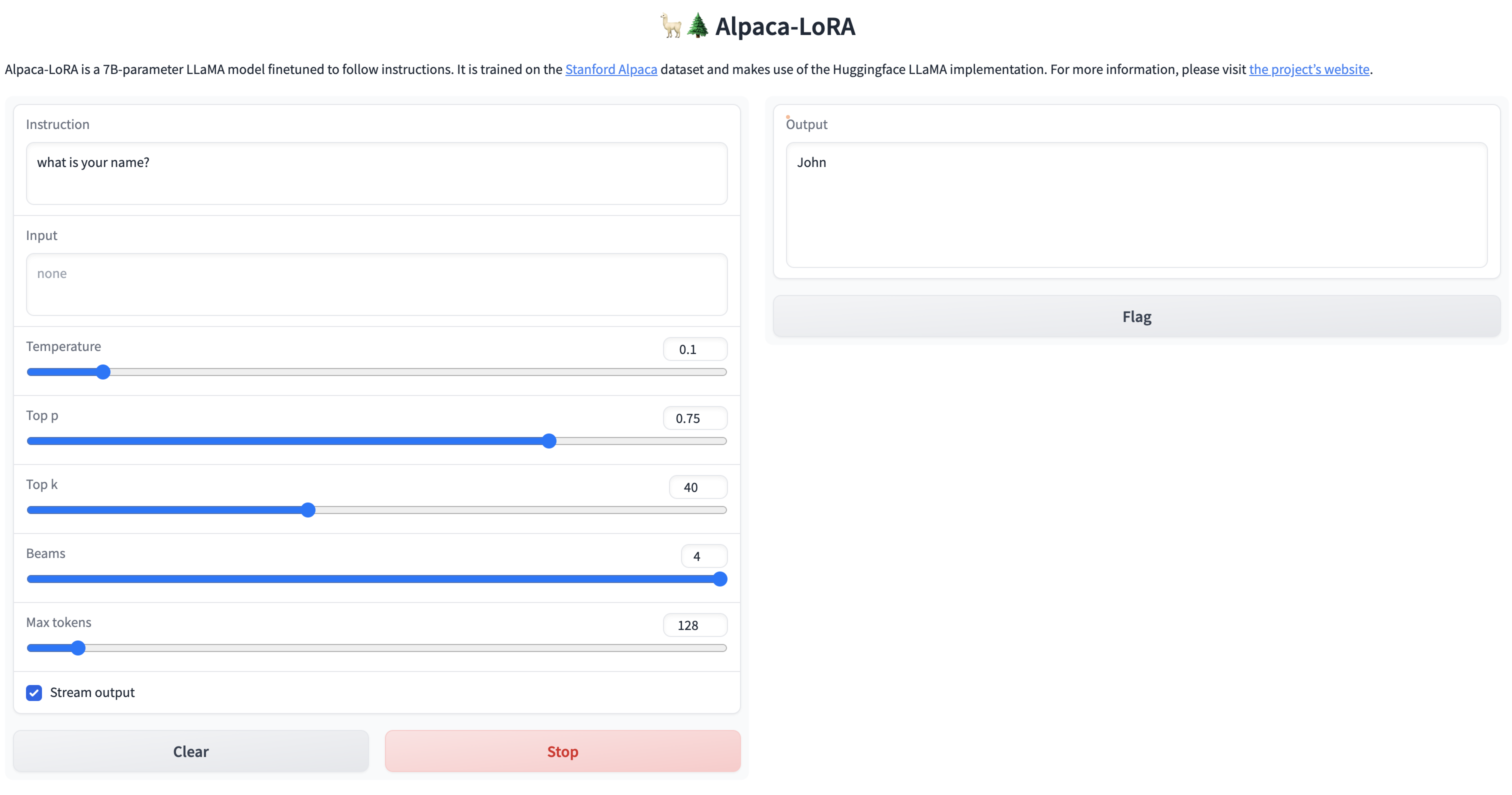
因为我们目标是让模型说中文,所以我们测试一下对中文的理解,看看效果怎么样?
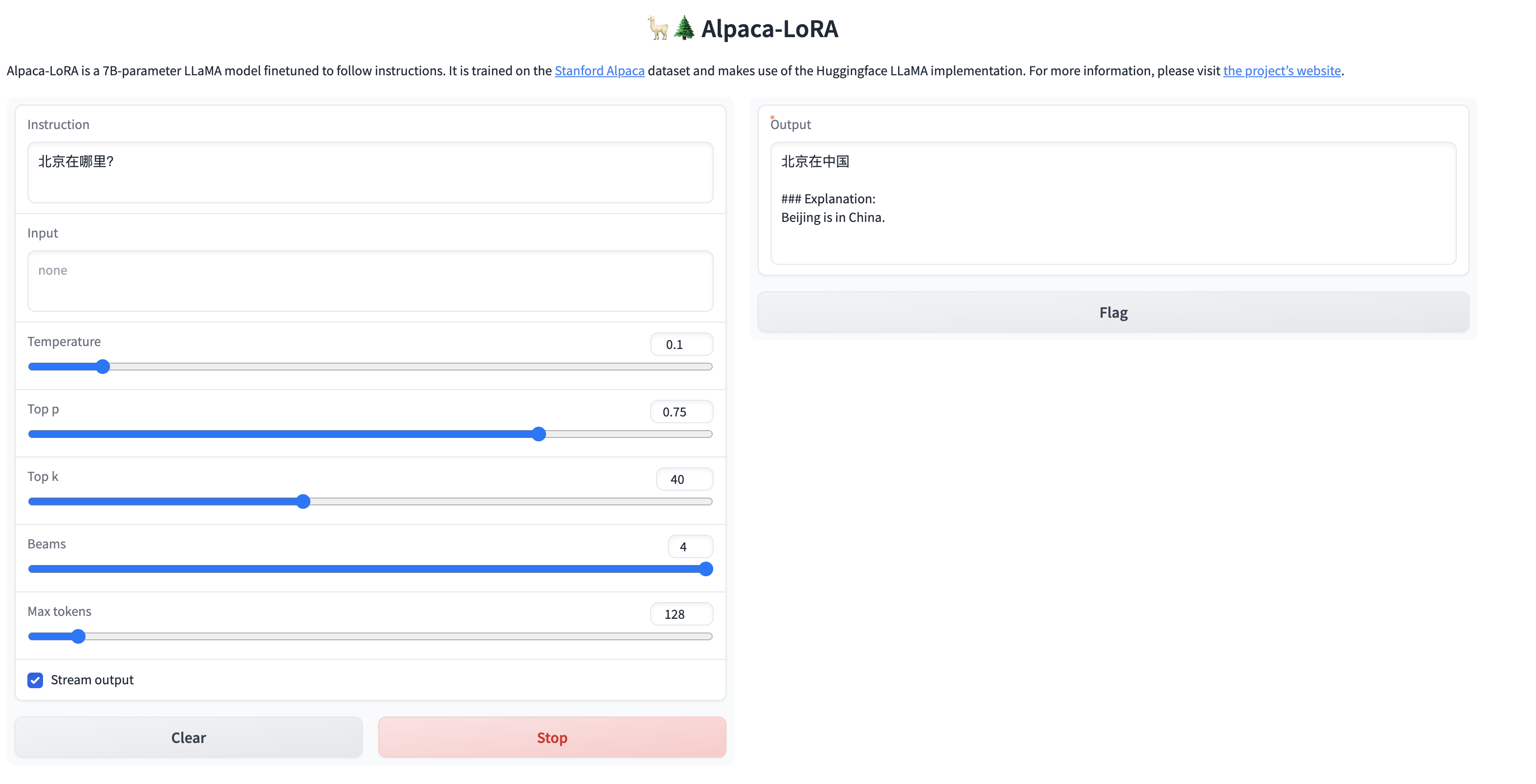
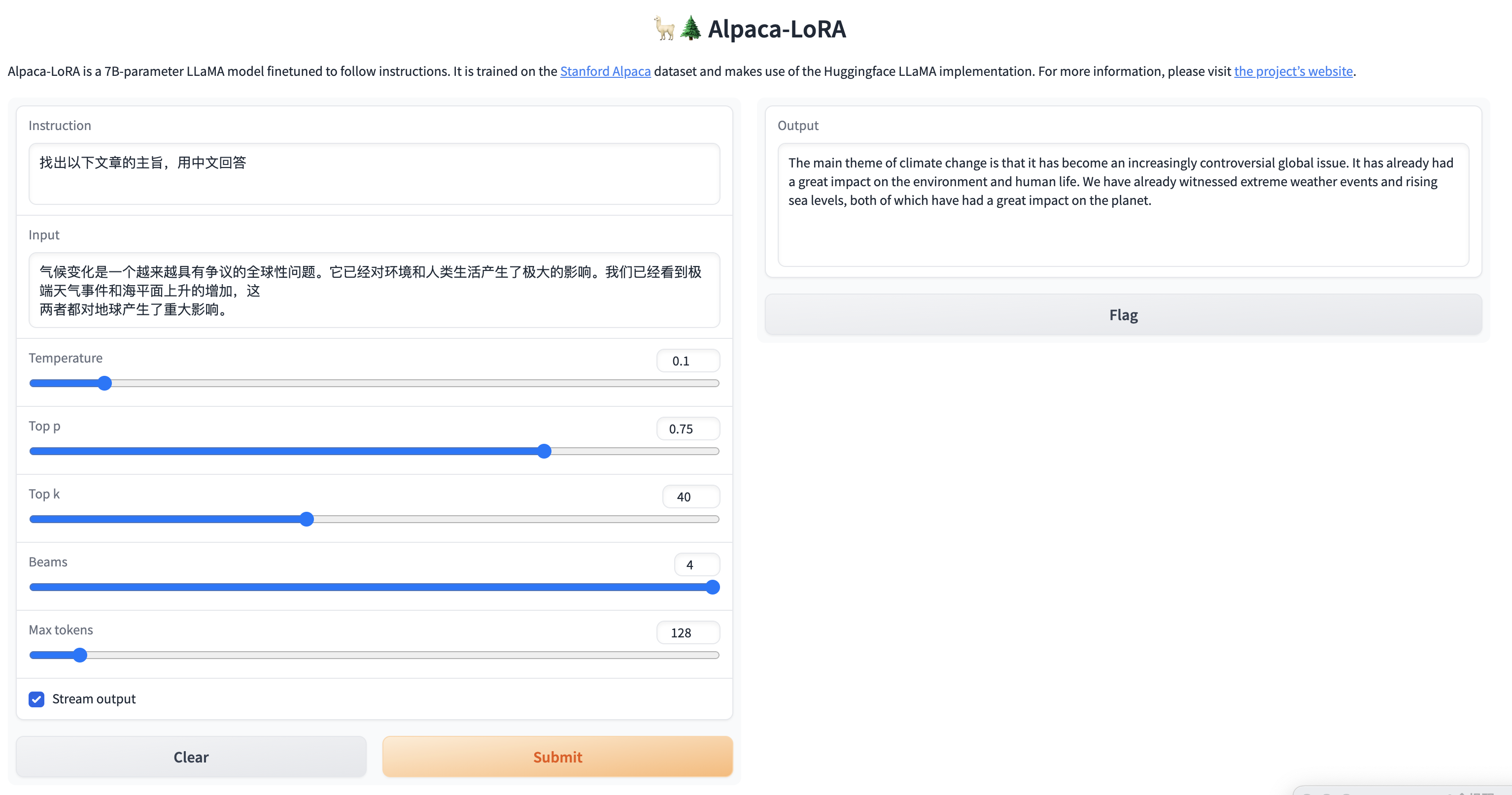
简单的问题,还是能给出答案的,但是针对稍微复杂一点的问题,虽然能够理解中文,但是并没有用中文进行回答,训练后的模型还是不太稳定啊。
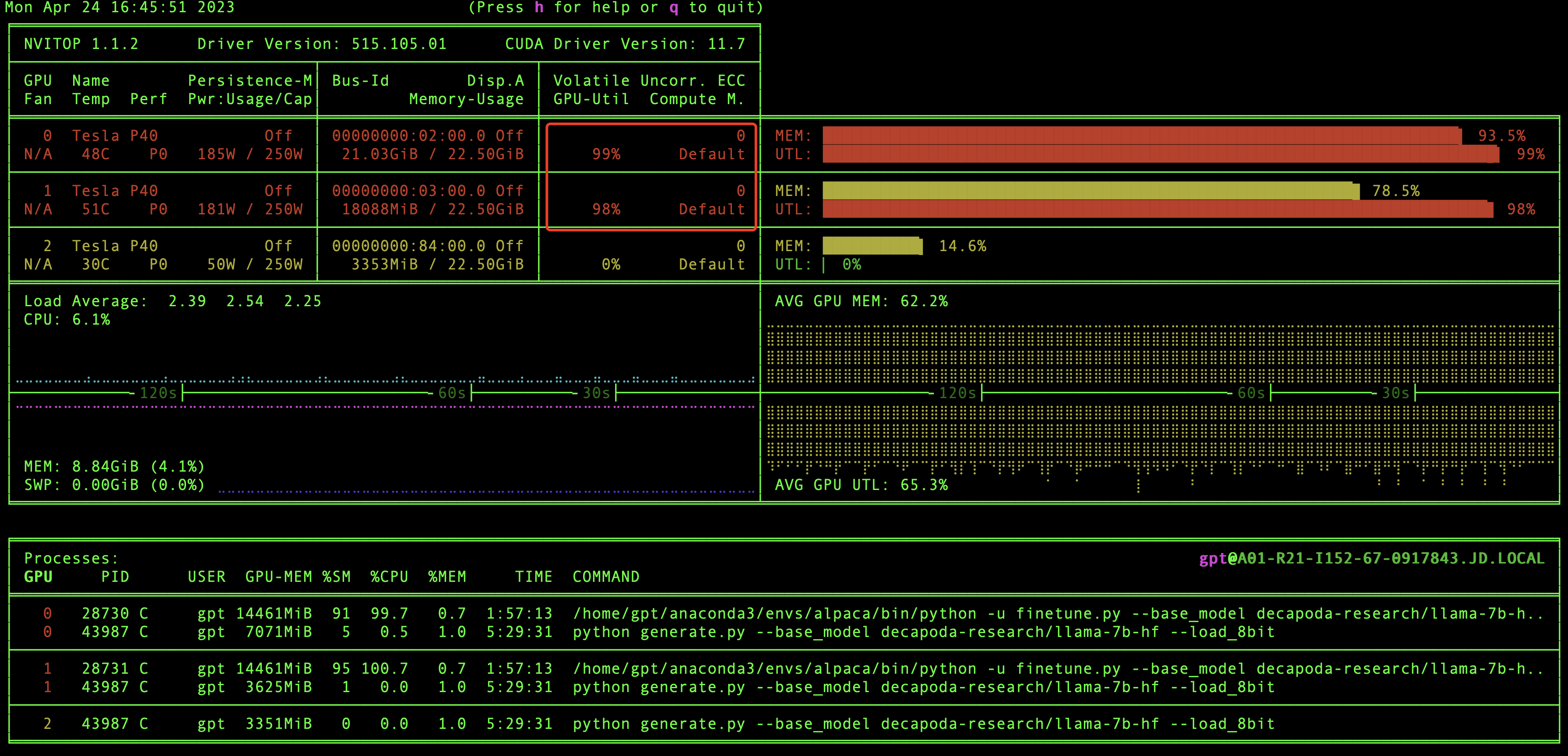
在推理的时候我们也可以监控一下GPU的变化,可以看到GPU负载是比较高的,说明GPU在进行大量的计算来完成推理。
总结
1.效果问题:由于语料库不够丰富,所以目前用社区提供的语料库训练的效果并不是很好,对中文的理解力有限,如果想训练出能够执行特定领域的任务,则需要大量的语料支持,同时训练时间也会更长;
2. Problème de temps d'inférence : étant donné que le serveur GPU actuellement déployé dispose de 4 GPU, 3 d'entre eux peuvent être exécutés sur la base de 3 GPU, l'inférence est encore assez difficile pour exécuter une interaction si elle atteint le réel. Le retour en temps comme chatGPT nécessite beaucoup de puissance de calcul pour être pris en charge. On peut en déduire que le backend de chatGPT doit être pris en charge par un grand cluster de puissance de calcul, donc si vous souhaitez en faire un service, l'investissement en termes de coûts est un problème qui doit être pris en compte ;
3. Problème de code chinois tronqué : lorsque l'entrée est en chinois, le résultat renvoyé sera parfois tronqué. Il est soupçonné d'être lié à la segmentation des mots. En raison de problèmes d'encodage chinois, le chinois n'est pas distingué par des espaces. comme l'anglais, il peut donc y avoir une certaine quantité de code tronqué. Les API d'IA seront également dans cette situation, et nous verrons plus tard si la communauté a des solutions correspondantes.
4. Actuellement relativement actif, la génération et les changements de modèles changent également chaque jour qui passe. En raison du manque de temps, nous étudions actuellement uniquement. Avec le déploiement localisé du modèle alpaga-lora, il devrait y avoir une mise en œuvre meilleure et moins coûteuse. des solutions pour des applications réelles dans le futur. Il est nécessaire de continuer à suivre le développement de la communauté et de choisir des solutions open source appropriées.
La pratique [Modèle de langage ChatGLM] du modèle GPU JD Cloud P40 est détaillée sur : https://www.php.cn/link/f044bd02e4fe1aa3315ace7645f8597a
Auteur : JD Retail Luo Yongjian
Source de contenu : Développeur JD Cloud Communauté
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
Cet article explore le problème de la détection précise d'objets sous différents angles de vue (tels que la perspective et la vue à vol d'oiseau) dans la conduite autonome, en particulier comment transformer efficacement les caractéristiques de l'espace en perspective (PV) en vue à vol d'oiseau (BEV). implémenté via le module Visual Transformation (VT). Les méthodes existantes sont globalement divisées en deux stratégies : la conversion 2D en 3D et la conversion 3D en 2D. Les méthodes 2D vers 3D améliorent les caractéristiques 2D denses en prédisant les probabilités de profondeur, mais l'incertitude inhérente aux prévisions de profondeur, en particulier dans les régions éloignées, peut introduire des inexactitudes. Alors que les méthodes 3D vers 2D utilisent généralement des requêtes 3D pour échantillonner des fonctionnalités 2D et apprendre les poids d'attention de la correspondance entre les fonctionnalités 3D et 2D via un transformateur, ce qui augmente le temps de calcul et de déploiement.
