

Des cas spécifiques sont décrits en détail ci-dessous
Scénarios qui ne conviennent pas à l'indexation :
Il n'est pas recommandé de créer des index pour des tables avec de petits volumes de données
Il n'est pas recommandé de créer des index pour les champs avec une grande quantité de données en double (similaires à : Champ Sexe)
Il n'est pas recommandé de créer un index pour les tables qui doivent être mises à jour fréquemment
Les champs inutilisés après où, regrouper par, trier par sont non indexé
Ne pas définir d'index redondants
Scénario d'échec de l'index :
La condition de filtre utilisée n'est pas égale à (!=, )
La condition de filtre utilisée est not null
Utilisez des fonctions ou des calculs sur le champ d'index
Lorsque vous utilisez un index conjoint, vous devez satisfaire à la "règle du meilleur préfixe gauche", sinon il sera invalide
Lorsque la conversion de type est. utilisé, l'index sera également invalide.
Lors de l'utilisation de requêtes par plage, la partie d'index conjointe Invalidation du champ (où âge > 18)
Dans le champ similaire, s'il commence par %, l'index est invalide. (où le nom est comme ‘%abc’)
Lors de l'utilisation de ou pour une requête, des champs avant et après ou non-index apparaissent et l'index devient invalide. Les jeux de caractères de la table et de la bibliothèque sont incohérents, ce qui entraînera une incohérence. conduire à un échec de l'index. Points de connaissance :
Il n'est pas recommandé d'avoir plus de 6 index pour chaque table (cela prend de la place et réduit la vitesse de mise à jour)
En fin de compte, c'est le cas. a décidé d'utiliser l'index ou l'optimiseur
L'optimiseur comparera le coût de la requête en fonction du volume de données, de la version de la base de données et de la sélection de données lues, décidant ainsi d'utiliser l'index
Lors de la création d'un index, définissez les champs qui nécessitent une correspondance de plage à la fin de l'index pour éviter tout échec. Lors de la création de la table, définissez les champs sur non nul et définissez une valeur par défaut. Cela peut être utilisé lorsque vous devez rechercher des enregistrements sans valeurs où xxx =. valeur par défaut, l'utilisation n'est pas nulle pour provoquer un échec de l'index
Lors d'une recherche sur la page, veuillez utiliser la correspondance floue à gauche ou en texte intégral (comme '%abc')
Pour un meilleur filtrage des champs Devant l'articulation index, afin que davantage de données puissent être filtrées en premier
Il n'est pas recommandé de créer un scénario d'index
Lorsque les données sont relativement petites, l'avantage de l'index n'est pas évident , car le moteur de stockage de la base de données est également très rapide Par rapport à la nécessité d'interroger l'index avant d'effectuer l'opération de retour de table, les performances de la requête directe peuvent être plus élevées, il n'est donc pas recommandé de créer un index pour les tables avec des données relativement petites.
sont similaires aux champs de genre. Il n'y a que deux valeurs différentes "masculin" et "femelle", donc la moitié des données de l'index sont ". mâle" et la moitié des données sont "femelles", donc l'indexation ne peut pas être effectuée rapidement. Requête, etc., il n'est donc pas recommandé de créer des index sur des colonnes avec une grande quantité de données en double
Scénario 4 : Champs inutilisés (où/regrouper par/ordre). by)
Il n'est pas nécessaire de créer un index pour les champs qui ne sont pas Where/group by/order by, car l'index ne sera pas utilisé
Scénario 5 : Ne pas définir d'index restant redondant
create index username_password_address on xiao(username,password,address); -- 如果建立了第一个索引,那么就没有必要建立第二个索引 create index username on xiao (username); --第二个索引就是冗余索引,因为第一个已经是先根据username排序的索引 --也就是第二个索引的功能完全可以由第一个索引实现
Ici, car le nom d'utilisateur est le premier champ du premier index commun, l'index est trié par nom d'utilisateur. Lorsque le nom d'utilisateur est le même, il est trié par mot de passe et adresse, on réalise donc que la colonne du nom d'utilisateur seule est utilisée comme fonction d'index. c'est-à-dire que le deuxième index est redondant
Scénario d'échec de l'index
Scénario 1 : Effectuer des opérations (fonctions, etc.) sur les champs indexés, entraînant un échec de l'index
Ici, l'index est d'abord créé pour l'âge. L'index a été utilisé lors de la première requête, mais la deuxième valeur de clé était nulle (échec de l'index). La raison de l'échec de l'index était que l'âge avait été calculé après où lors de la deuxième requête, et l'ordinateur ne savait pas quel calcul était effectué. , donc age+1 sera calculé et comparé à 1, et l'index deviendra invalide. Semblable à l'utilisation de la fonction concat() sur un champ, etc., l'index deviendra invalide. à (où age != 18)
Lorsque vous utilisez des opérations équivalentes, vous pouvez effectuer une recherche dans l'index, mais s'il n'est pas égal, vous devez parcourir toutes les données, donc elles sont invalides
explain select * from xiaoyuanhao where age = 18; explain select * from xiaoyuanhao where age != 18; --这里是在age字段上建立了普通索引,第二个查询时候索引失效
Scénario 3 : L'utilisation n'est pas l'index nul n'est pas valide
Identique à non égal. Si vous utilisez n'est pas nul, alors vous devez parcourir toutes les données et l'index sera invalide. Cependant, si vous utilisez est nul, vous pouvez toujours utiliser l'index
--这里是在age字段上建立了普通索引,第二个查询时候索引失效 explain select * from xiaoyuanhao where age is null; --可以正常使用索引 explain select * from xiaoyuanhao where age is not null; --索引失效
CREATE INDEX age_classid_name ON student(age,classId,NAME); EXPLAIN SELECT * FROM student WHERE classId = 30 AND NAME = 'xiaoyuanhao'; -- 因为没有使用age字段,所以没有准许最佳左前缀原则,索引失效
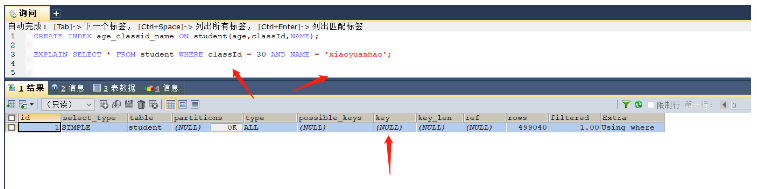
从这里可以看出是没有使用索引的(key = null),因为创建的索引是先按照age进行排序,在age相同的情况下按照classId和name排序,如果在查询的时候需要直接按照classId进行排序查找,那么就无法使用该索引,即索引失效。
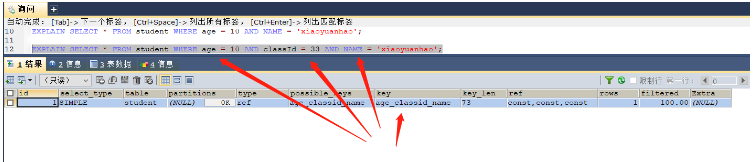
如果需要使用使用索引,那么就一定需要到联合索引的第一个字段age,案例如下
EXPLAIN SELECT * FROM student WHERE age = 10 AND NAME = 'xiaoyuanhao'; EXPLAIN SELECT * FROM student WHERE age = 10 AND classId = 33 AND NAME = 'xiaoyuanhao'; --两者都是使用age字段索引,所以索引有效

场景五:类型转换导致索引失效
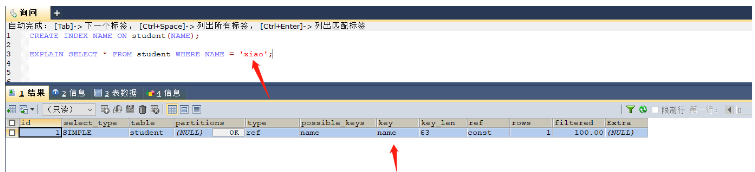
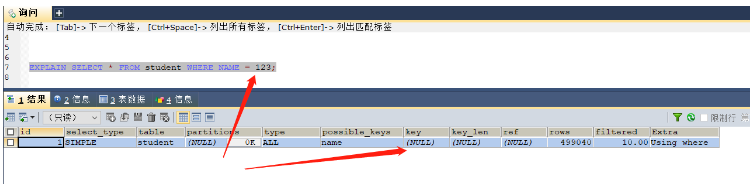
CREATE INDEX NAME ON student(NAME); -- 这里的name字段是varchar类型 EXPLAIN SELECT * FROM student WHERE NAME = 'xiao'; -- 本次查询是可以使用索引的,因为类型都是一致的,都是字符串 EXPLAIN SELECT * FROM student WHERE NAME = 123; -- 本次查询则无法使用索引,因为是将数字类型123转换为字符类型
没有发生类型转换,使用索引key = name
发生了类型转换,无法使用索引kye = null,索引失效
使用索引的时候一定需要保证数据类型是一致的,否则系统就需要进行转换,那么就无法使用索引
场景六:使用范围查询导致联合索引其他字段失效
create index age_classId_name on student (age,classId,name); EXPLAIN SELECT * FROM student WHERE age = 10 AND classId > 20 AND NAME = 'xiaoyuanhao'; -- 这里只能使用age,classId,索引的前两个字段 EXPLAIN SELECT * FROM student WHERE age = 10 AND classId = 20 AND NAME = 'xiaoyuanhao'; -- 这里可以使用完整的索引,因为都是等值连接
在classId字段上使用范围查询,导致name字段失效,有效索引长度为63

使用的都是等值匹配,整个索引皆可用,有效索引长度为73

也就是在对于联合索引来说,如果在使用的时候是等值匹配,那么就可以重复的利用索引,如果不是等值匹配,那么该字段也是可以使用索引的,但是该字段右边的字段就将失效
建议在建立索引的时候将需要范围匹配的字段建立在索引的最后面
场景七:在使用like的时候,如果以%开头导致索引失效
EXPLAIN SELECT * FROM student WHERE NAME LIKE 'abc%'; -- 可以正常使用索引 EXPLAIN SELECT * FROM student WHERE NAME LIKE '%abc'; -- 这里在like中,%在前面无法使用索引
key = name,使用了该索引,索引有效
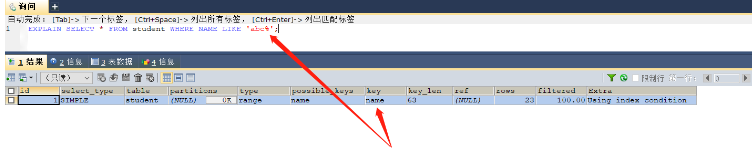
key = null,索引失效

因为建立的索引实际上是按照整个字符串的从第一个开始进行比较排序的,所以在使用like的时候,也只能够重现进行比较,如果使用的是’%abc’,那么查询的就是以abc结尾的数据,无法使用索引
场景八:or前后出现非索引字段,索引失效
-- 该表中只有name字段上的索引 CREATE INDEX NAME ON student(NAME); EXPLAIN SELECT * FROM student WHERE NAME = 'xiao'; -- 这里是可以使用name索引的 EXPLAIN SELECT * FROM student WHERE NAME = 'xiao' OR classId = 1001; -- 这个则无法使用索引,进行的是全表扫描
key = null,无法使用索引,or条件中出现非索引字段
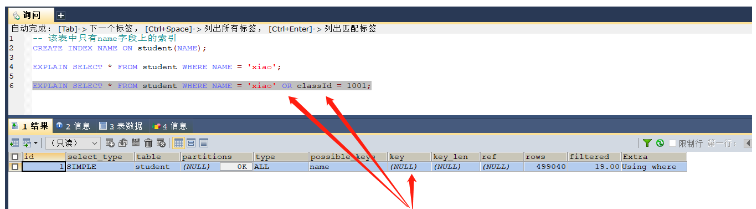
因为如果name不等于’xiao’的时候那么就会继续判断classId是否等于1001,那么实际上还是会进行全表扫描,所以索引失效(也就是进行name判断的时候可以使用索引,但是在判断classId的时候又要全表扫描,那么优化器就直接进行全表扫描),但是如果or前后的字段都有索引了,那么就就会使用索引
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



