
 Périphériques technologiques
IA
Une interprétation approfondie de l'algorithme de perception visuelle 3D pour la conduite autonome
Périphériques technologiques
IA
Une interprétation approfondie de l'algorithme de perception visuelle 3D pour la conduite autonome
Une interprétation approfondie de l'algorithme de perception visuelle 3D pour la conduite autonome

Pour les applications de conduite autonome, il est finalement nécessaire de percevoir des scènes 3D. La raison est simple : un véhicule ne peut pas conduire sur la base des résultats de perception obtenus à partir d’une image. Même un conducteur humain ne peut pas conduire sur la base d’une image. Étant donné que la distance de l'objet et les informations sur la profondeur de la scène ne peuvent pas être reflétées dans les résultats de perception 2D, ces informations sont la clé permettant au système de conduite autonome de porter des jugements corrects sur l'environnement.
De manière générale, les capteurs visuels (comme les caméras) des véhicules autonomes sont installés au-dessus de la carrosserie du véhicule ou sur le rétroviseur intérieur. Peu importe où elle se trouve, la caméra obtient la projection du monde réel dans la vue en perspective (du système de coordonnées mondiales au système de coordonnées de l'image). Cette vue est similaire au système visuel humain et est donc facilement comprise par les conducteurs humains. Mais un problème fatal avec les vues en perspective est que l’échelle des objets change avec la distance. Par conséquent, lorsque le système de perception détecte un obstacle devant l'image, il ne connaît pas la distance de l'obstacle au véhicule, ni la forme tridimensionnelle et la taille réelles de l'obstacle.
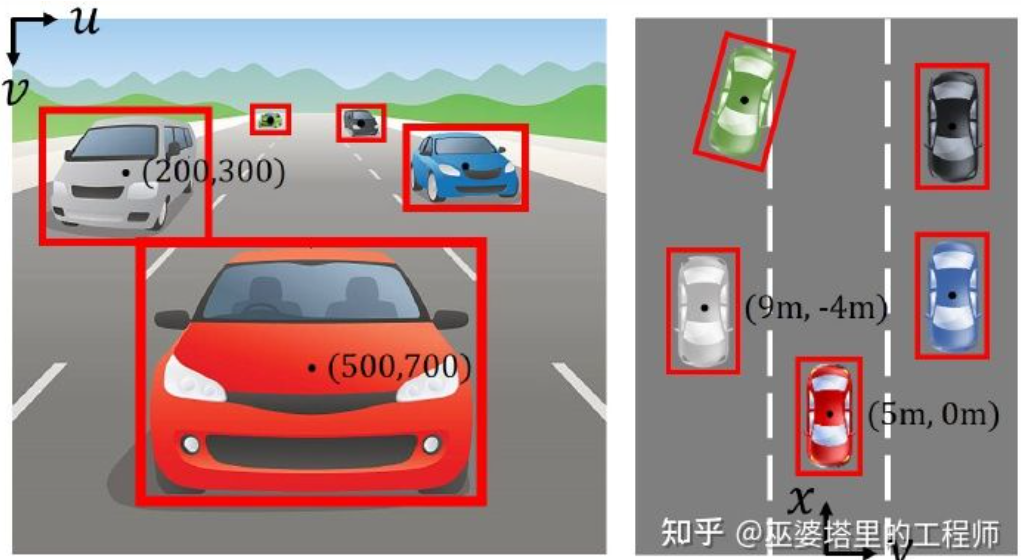
Système de coordonnées d'image (vue en perspective) vs système de coordonnées mondiale (vue à vol d'oiseau) [IPM-BEV]
Si vous souhaitez obtenir des informations sur l'espace 3D, l'un des la méthode la plus directe consiste à utiliser LiDAR. D'une part, le nuage de points 3D issu du LiDAR peut être directement utilisé pour obtenir la distance et la taille des obstacles (détection d'objets 3D), ainsi que la profondeur de la scène (segmentation sémantique 3D). D'un autre côté, les nuages de points 3D peuvent également être fusionnés avec des images 2D pour exploiter pleinement les différentes informations fournies par les deux : l'avantage des nuages de points est une perception précise de la distance et de la profondeur, tandis que l'avantage des images est une information sémantique plus riche.
Cependant, le LiDAR présente également des inconvénients, tels qu'un coût plus élevé, des difficultés de production en série de produits de qualité automobile, un impact plus important des conditions météorologiques, etc. Par conséquent, la perception 3D basée uniquement sur des caméras reste une direction de recherche très significative et précieuse. Les sections suivantes de cet article présenteront en détail les algorithmes de perception 3D basés sur des caméras simples et doubles.
01
Perception 3D monoculaire
Percevoir l'environnement 3D basé sur des images de caméra unique est un problème mal posé, mais certaines contraintes géométriques et connaissances préalables peuvent être utilisées pour aider à accomplir cette tâche, et des connaissances neuronales profondes les réseaux peuvent également être utilisés pour apprendre de bout en bout à prédire les informations 3D à partir des caractéristiques de l'image.
Détection d'objets

Détection d'objets 3D avec une seule caméra (image de M3D-RPN)
Transformation inverse d'image
Comme mentionné précédemment, l'image vient du réel de le monde La projection de coordonnées 3D sur des coordonnées planes 2D, donc une idée très directe pour la détection d'objets 3D à partir d'images est de transformer inversement l'image 2D en coordonnées mondiales 3D, puis d'effectuer une détection d'objets dans le système de coordonnées mondiales. En théorie, il s'agit d'un problème mal posé, mais il peut être résolu avec quelques informations supplémentaires (telles que l'estimation de la profondeur) ou des hypothèses géométriques (telles que les pixels situés au sol).
BEV-IPM [1] propose de convertir les images de la vue perspective en vue plongeante (BEV). Il y a ici deux hypothèses : l'une est que la surface de la route est parallèle au système de coordonnées mondial et que la hauteur est nulle, et l'autre est que le système de coordonnées du véhicule est parallèle au système de coordonnées mondial. Le premier n'est pas satisfait lorsque la surface de la route n'est pas plate, tandis que le second peut être corrigé via les paramètres d'attitude du véhicule (Pitch and Roll), qui sont en fait l'étalonnage du système de coordonnées du véhicule et du système de coordonnées mondial. En supposant que tous les pixels de l'image ont une hauteur nulle dans le monde réel, la transformation homographique peut être utilisée pour convertir l'image en vue BEV. Dans la vue BEV, une méthode basée sur le réseau YOLO est utilisée pour détecter la case inférieure de la cible, qui est le rectangle en contact avec la surface de la route. La hauteur de la Bottom Box est nulle, elle peut donc être projetée avec précision sur la vue BEV en tant que GroudTruth pour entraîner le réseau neuronal. En même temps, la Box prédite par le réseau neuronal peut également estimer avec précision sa distance. L'hypothèse ici est que la cible doit être en contact avec la surface de la route, ce qui est généralement suffisant pour les cibles de véhicules et de piétons.
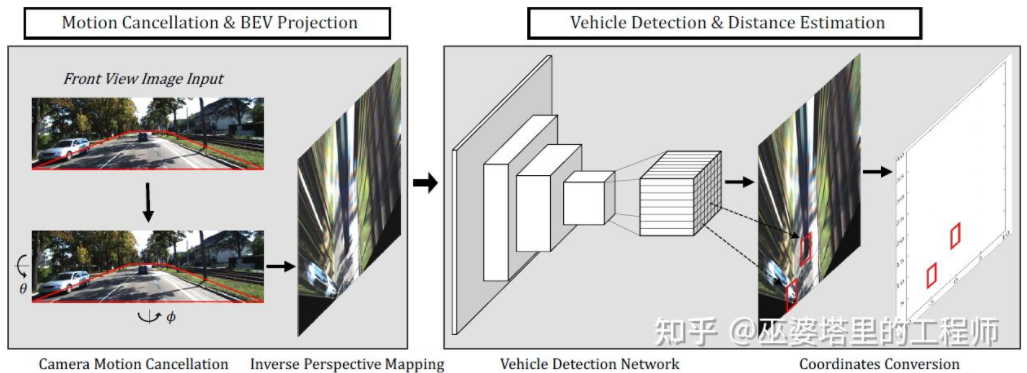
BEV-IPM
Une autre méthode de transformation inverse utilise la transformation de caractéristiques orthographiques (OFT) [2]. L'idée est d'utiliser CNN pour extraire des caractéristiques d'image multi-échelles, puis de transformer ces caractéristiques d'image en vues BEV, et enfin d'effectuer une détection d'objets 3D sur les caractéristiques BEV. Tout d’abord, il est nécessaire de construire une grille 3D du point de vue BEV (la portée de la grille de l’expérience dans cet article est de 80 mètres x 80 mètres x 4 mètres et la taille de la grille est de 0,5 m). Chaque grille correspond à une zone de l'image (définie comme une zone rectangulaire pour plus de simplicité) par transformation de perspective, et la valeur moyenne des caractéristiques de l'image dans cette zone est utilisée comme caractéristique de la grille, obtenant ainsi les caractéristiques de la grille 3D. Afin de réduire la quantité de calcul, les entités de grille 3D sont compressées (moyenne pondérée) dans la dimension de hauteur pour obtenir les entités de grille 2D. La détection finale des objets est effectuée sur les entités de maillage 2D. La projection des grilles 3D sur les pixels de l'image 2D ne correspond pas une à une. Plusieurs grilles correspondront à des zones d'image adjacentes, ce qui entraînera une ambiguïté dans les caractéristiques de la grille. Par conséquent, il faut également supposer que les objets à détecter se trouvent tous sur la route et que la plage de hauteur est très étroite. La grille 3D utilisée dans l’expérimentation n’a donc qu’une hauteur de 4 mètres, ce qui est suffisant pour couvrir les véhicules et les piétons au sol. Mais si l’on souhaite détecter des panneaux de signalisation, cette méthode consistant à supposer que les objets sont proches du sol n’est pas applicable.
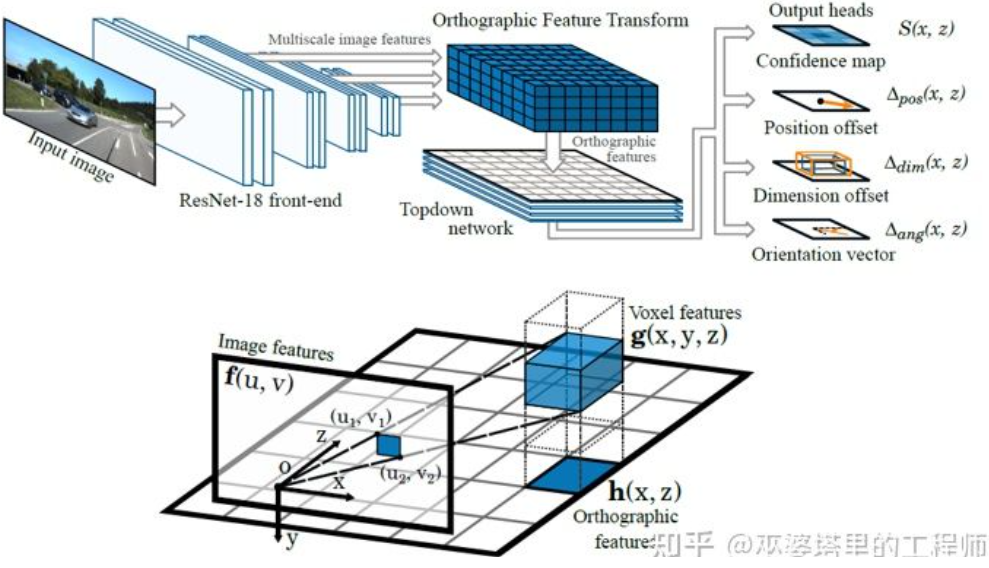
Transformation des caractéristiques orthographiques
Les deux méthodes ci-dessus sont basées sur l'hypothèse que l'objet est au sol. De plus, une autre idée consiste à utiliser les résultats de l’estimation de la profondeur pour générer des données de pseudo-nuages de points. Un travail typique est le Pseudo-LiDAR [3]. Les résultats de l'estimation de la profondeur sont généralement traités comme des canaux d'image supplémentaires (similaires aux données RVB-D), et les réseaux de détection d'objets basés sur l'image sont utilisés directement pour générer des cadres de délimitation d'objets 3D. L'auteur a souligné dans l'article que la principale raison pour laquelle la précision de la détection d'objets 3D basée sur l'estimation de la profondeur est bien pire que celle des méthodes basées sur LiDAR n'est pas que la précision de l'estimation de la profondeur est insuffisante, mais qu'il y a un problème avec la méthode de représentation des données. Premièrement, sur les données d'image, la zone des objets distants est très petite, ce qui rend la détection d'objets distants très imprécise. Deuxièmement, la différence de profondeur entre les pixels adjacents peut être très grande (comme au bord d'un objet). Dans ce cas, il y aura des problèmes lors de l'utilisation d'opérations de convolution pour extraire des caractéristiques. En tenant compte de ces deux points, l'auteur a proposé de convertir l'image d'entrée en données de nuage de points similaires à celles générées par LiDAR sur la base de la carte de profondeur, puis d'utiliser des algorithmes de fusion de nuages de points et d'images (tels que AVOD et F-PointNet) pour détecter des objets 3D. La méthode pseudo-LiDAR ne repose pas sur un algorithme d’estimation de profondeur spécifique, et toute estimation de profondeur monoculaire ou binoculaire peut être utilisée directement. Grâce à cette méthode spéciale de représentation des données, le pseudo-LiDAR peut augmenter la précision de la détection des objets de 22 % à 74 % dans une portée de 30 mètres.

Pseudo-LiDAR
Par rapport au nuage de points LiDAR réel, la méthode Pseudo-LiDAR présente encore un certain écart dans la précision de la détection d'objets 3D, qui est principalement dû à l'estimation de la profondeur. Cela est dû à une précision insuffisante (les jumelles sont meilleures que les monoculaires), en particulier l'erreur d'estimation de la profondeur autour de l'objet, qui aura un grand impact sur la détection. Par conséquent, le pseudo-LiDAR a également connu de nombreuses expansions depuis lors. Pseudo-LiDAR++ [4] utilise le LiDAR à fil bas pour améliorer les nuages de points virtuels. Le pseudo-Lidar End2End[5] utilise la segmentation d'instance pour remplacer le cadre d'objet dans F-PointNet. RefinedMPL [6] génère uniquement des nuages de points virtuels sur les points de premier plan, réduisant le nombre de nuages de points à 10 % de l'original, ce qui peut réduire efficacement le nombre de fausses détections et la quantité de calcul de l'algorithme.
Points clés et modèles 3D
Dans les applications de conduite autonome, la taille et la forme de nombreuses cibles qui doivent être détectées (telles que les véhicules et les piétons) sont relativement fixes et connues. Ces connaissances préalables peuvent être utilisées pour estimer les informations 3D de la cible.
DeepMANTA[7] est l’un des travaux pionniers dans ce sens. Premièrement, des algorithmes traditionnels de détection d'objets d'image tels que Faster RNN sont utilisés pour obtenir le cadre d'objet 2D et également détecter les points clés du véhicule. Ensuite, ces cadres d'objets 2D et points clés sont mis en correspondance avec divers modèles CAO de véhicules 3D dans la base de données, et le modèle présentant la plus grande similarité est sélectionné comme résultat de la détection d'objets 3D.
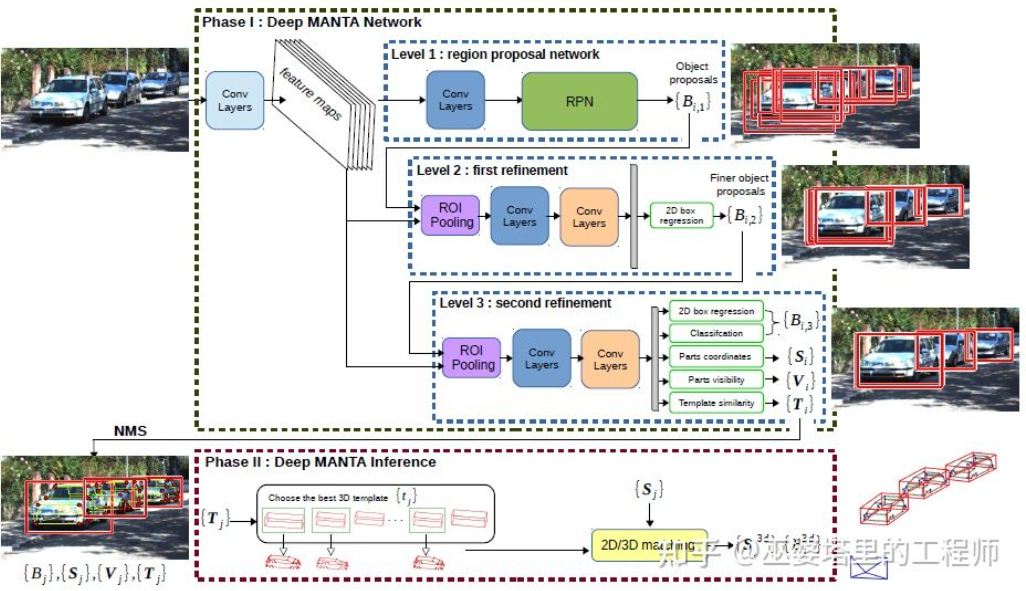
Deep MANTA
3D-RCNN [8] propose d'utiliser la méthode Inverse-Graphics pour restituer la forme 3D et la posture de chaque cible dans la scène en fonction d'images. L'idée de base est de partir du modèle 3D de la cible et de trouver le modèle qui correspond le mieux à la cible dans l'image grâce à la recherche de paramètres. Ces modèles 3D ont généralement de nombreux paramètres de contrôle et un grand espace de recherche. Par conséquent, les méthodes traditionnelles ne donnent pas de bons résultats dans la recherche de résultats optimaux dans des espaces de paramètres de grande dimension. 3D-RCNN utilise PCA pour réduire la dimensionnalité de l'espace des paramètres (10-D) et utilise un réseau neuronal profond (R-CNN) pour prédire les paramètres du modèle de faible dimension de chaque cible. Les paramètres du modèle prédits peuvent être utilisés pour générer une image bidimensionnelle ou une carte de profondeur de chaque cible, et la perte obtenue en la comparant aux données GroudTruth peut être utilisée pour guider l'apprentissage du réseau neuronal. Cette perte est appelée perte de rendu et de comparaison et est implémentée sur la base d'OpenGL. La méthode 3D-RCNN nécessite beaucoup de données d'entrée et la conception de la perte est relativement complexe, ce qui la rend difficile à mettre en œuvre en ingénierie.
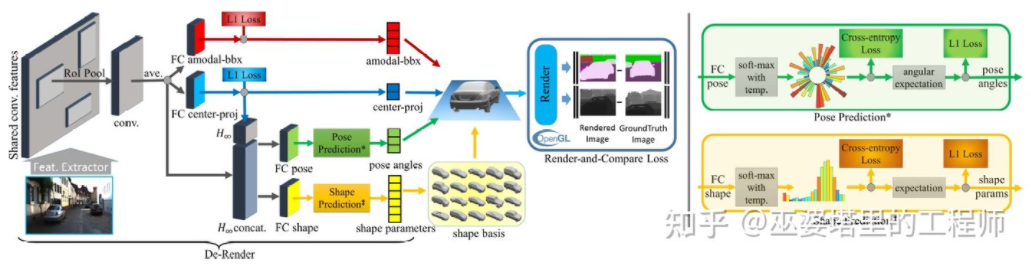
3D-RCNN
MonoGRNet [9] propose de diviser la détection d'objets 3D monoculaires en quatre étapes, qui sont utilisées pour prédire le cadre de l'objet 2D, la profondeur du centre 3D de l'objet, et l'objet 3D La position projetée 2D du centre et les positions 3D des 8 points d'angle. Premièrement, le cadre d'objet 2D prédit dans l'image est exploité par ROIAlign pour obtenir les caractéristiques visuelles de l'objet. Ces caractéristiques sont ensuite utilisées pour prédire la profondeur du centre 3D de l'objet et la position projetée en 2D du centre 3D. Avec ces deux informations, la position du point central 3D de l'objet peut être obtenue. Enfin, les positions relatives des huit points d'angle sont prédites en fonction de la position du centre 3D. MonoGRNet peut être considéré comme utilisant uniquement le centre de l'objet comme point clé, et la correspondance de la 2D et de la 3D est le calcul de la distance entre les points. MonoGRNetV2 [10] étend le point central à plusieurs points clés et utilise un modèle objet CAO 3D pour l'estimation de la profondeur, qui est très similaire au DeepMANTA et au 3D-RCNN introduits précédemment.
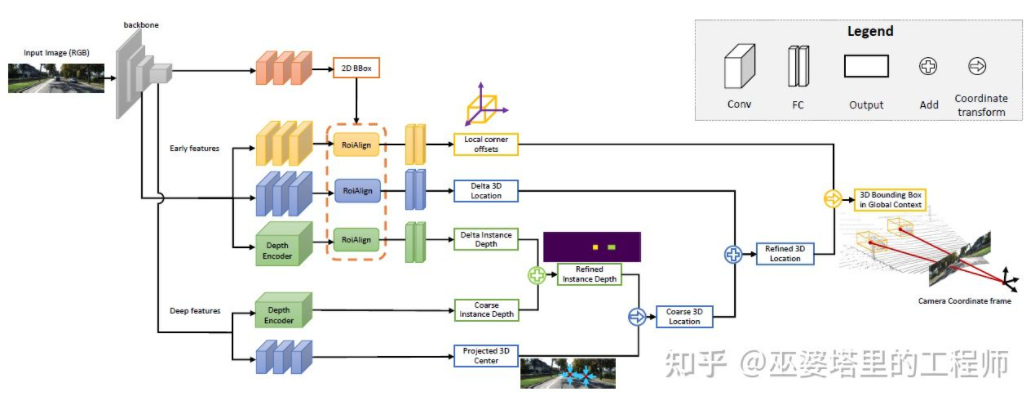
MonoGRNet
Monoloco[11] résout principalement le problème de détection 3D des piétons. Les piétons sont des objets non rigides présentant des postures et des déformations plus diverses, ce qui les rend plus difficiles à détecter que la détection de véhicules. Monoloco est également basé sur la détection de points clés, et la position relative 3D des points clés a priori peut être utilisée pour l'estimation de la profondeur. Par exemple, la distance d'un piéton est estimée sur la base de la longueur de 50 centimètres depuis l'épaule du piéton jusqu'à la hanche. La raison pour laquelle nous utilisons cette longueur comme référence est que cette partie du corps humain peut produire le moins de déformations et peut être utilisée pour estimer la profondeur avec la plus grande précision. Bien entendu, d’autres points clés peuvent également être utilisés comme auxiliaires pour mener à bien la tâche d’estimation approfondie. Monoloco utilise un réseau multicouche entièrement connecté pour prédire la distance d'un piéton à partir de l'emplacement des points clés, tout en donnant également l'incertitude de la prédiction.
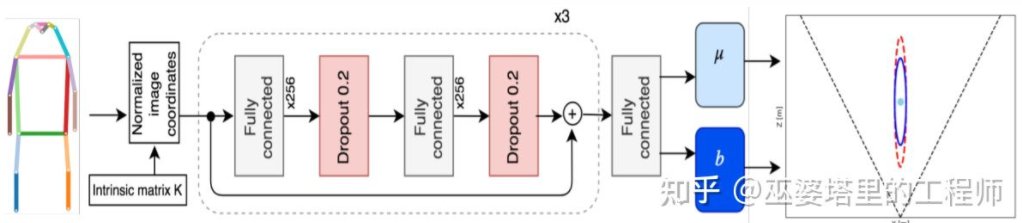
Monoloco
Pour résumer, les méthodes ci-dessus extraient les points clés des images 2D et les font correspondre avec le modèle 3D pour obtenir les informations 3D de la cible. Ce type de procédé suppose que la cible présente un modèle de forme relativement fixe, ce qui est généralement satisfaisant pour les véhicules, mais relativement difficile pour les piétons. De plus, ce type de méthode nécessite de marquer plusieurs points clés sur l’image 2D, ce qui est également très chronophage.
Contraintes géométriques 2D/3D
Deep3DBox [12] est un travail précoce et très représentatif dans cette direction. Le cadre d'objet 3D nécessite la représentation de variables à 9 dimensions, à savoir le centre, la taille et l'orientation (l'orientation 3D peut être simplifiée en Yaw, elle devient donc une variable à 7 dimensions). La détection d'objets image 2D peut fournir un cadre d'objet 2D contenant 4 variables connues (centre 2D et taille 2D), ce qui n'est pas suffisant pour résoudre des variables à 7 ou 9 degrés de liberté. Parmi ces trois ensembles de variables, la taille et l’orientation sont relativement étroitement liées aux caractéristiques visuelles. Par exemple, la taille 3D d'un objet est étroitement liée à sa catégorie (piéton, vélo, voiture, bus, camion, etc.), et la catégorie de l'objet peut être prédite grâce à des caractéristiques visuelles. Pour la position 3D du point central, il est difficile de la prédire uniquement à travers des caractéristiques visuelles en raison de l'ambiguïté provoquée par la projection en perspective. Par conséquent, Deep3DBox propose d'abord d'utiliser les caractéristiques de l'image dans la boîte d'objet 2D pour estimer la taille et l'orientation de l'objet. Ensuite, une contrainte géométrique 2D/3D est utilisée pour résoudre la position 3D du point central. Cette contrainte est que la projection du cadre d'objet 3D sur l'image est étroitement entourée par le cadre d'objet 2D, c'est-à-dire qu'au moins un point d'angle du cadre d'objet 3D peut être trouvé de chaque côté du cadre d'objet 2D. Grâce à la taille et à l'orientation prédites précédemment, combinées aux paramètres d'étalonnage de la caméra, la position 3D du point central peut être résolue. Contraintes géométriques entre les cadres d'objets 2D et 3D (Image issue de la littérature [9])
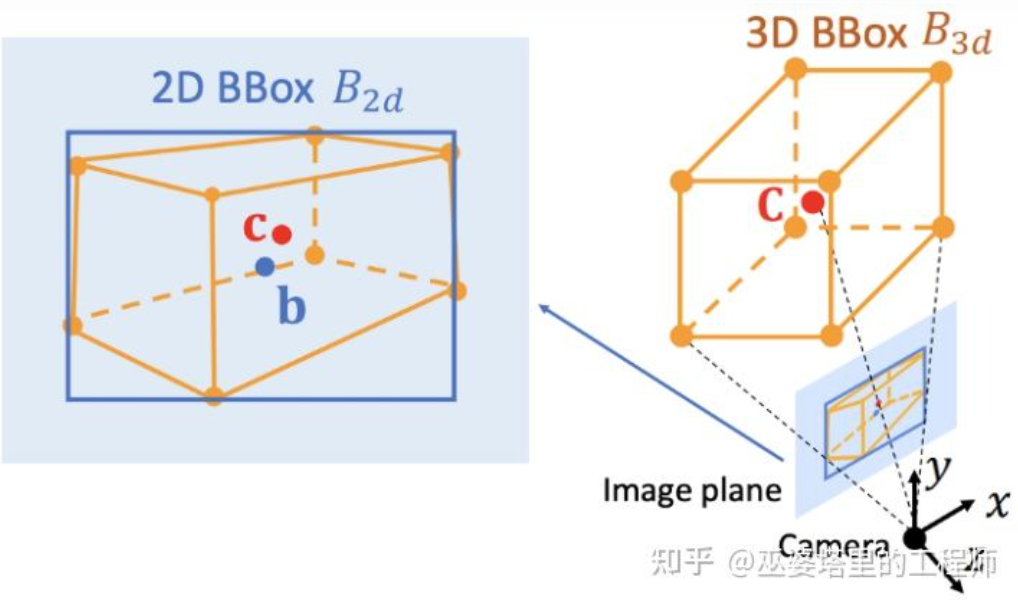 Cette méthode d'utilisation de contraintes 2D/3D nécessite un objet 2D très précis détection de trame. Dans le cadre de Deep3DBox, une petite erreur sur le cadre de l'objet 2D peut entraîner l'échec de la prédiction du cadre de l'objet 3D. Les deux premières étapes de Shift R-CNN [13] sont très similaires à Deep3DBox. Elles prédisent la taille et l'orientation 3D via des boîtes d'objets 2D et des caractéristiques visuelles, puis résolvent la position 3D via des contraintes géométriques. Cependant, Shift R-CNN ajoute une troisième étape, qui combine en entrée le cadre d'objet 2D, le cadre d'objet 3D et les paramètres de caméra obtenus au cours des deux premières étapes, et utilise un réseau entièrement connecté pour prédire une position 3D plus précise.
Cette méthode d'utilisation de contraintes 2D/3D nécessite un objet 2D très précis détection de trame. Dans le cadre de Deep3DBox, une petite erreur sur le cadre de l'objet 2D peut entraîner l'échec de la prédiction du cadre de l'objet 3D. Les deux premières étapes de Shift R-CNN [13] sont très similaires à Deep3DBox. Elles prédisent la taille et l'orientation 3D via des boîtes d'objets 2D et des caractéristiques visuelles, puis résolvent la position 3D via des contraintes géométriques. Cependant, Shift R-CNN ajoute une troisième étape, qui combine en entrée le cadre d'objet 2D, le cadre d'objet 3D et les paramètres de caméra obtenus au cours des deux premières étapes, et utilise un réseau entièrement connecté pour prédire une position 3D plus précise.
Shift R-CNN
#🎜 🎜#
Lors de l'utilisation de contraintes géométriques 2D/3D, les méthodes ci-dessus obtiennent toutes la position 3D de l'objet en résolvant un ensemble d'équations de super-contraintes, et ce processus est utilisé comme étape de post-traitement et n'est pas dans le réseau neuronal. Les première et troisième étapes de Shift R-CNN sont également formées séparément. MVRA [14] a intégré le processus de résolution de cette équation super-contrainte dans un réseau et a conçu la perte IoU dans les coordonnées de l'image et la perte L2 dans les coordonnées BEV pour mesurer respectivement l'erreur du cadre de l'objet et l'estimation de la distance afin d'aider à terminer le processus de bout en bout. terminer la formation. De cette manière, la qualité de la prédiction de la position 3D de l'objet aura également un effet de rétroaction sur la prédiction précédente de la taille et de l'orientation 3D.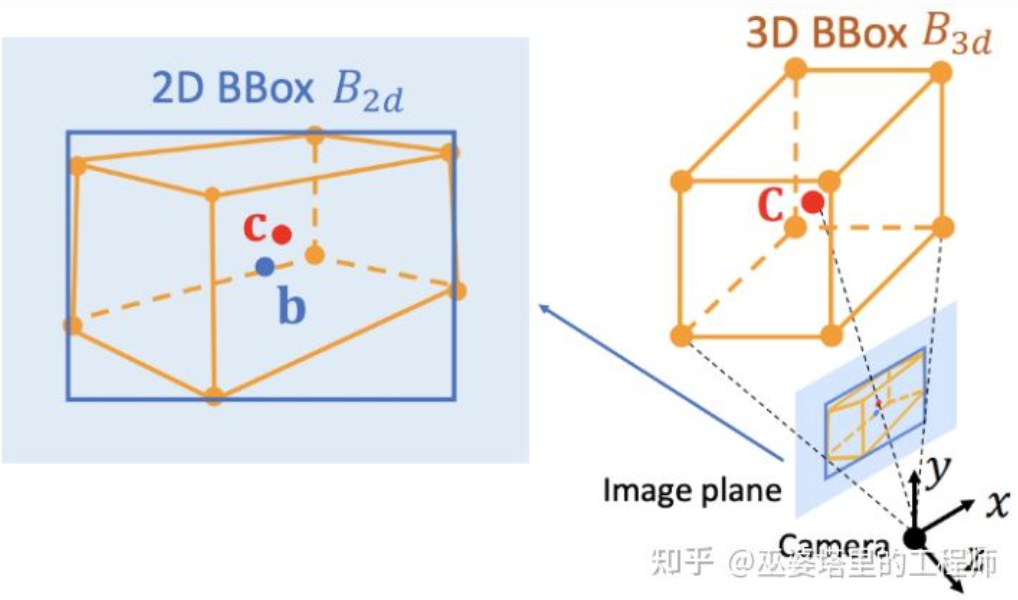
Générer directement un cadre d'objet 3DLes trois méthodes présentées avant partent toutes d'images 2D. transforment les images en vues BEV, certains détectent les points clés 2D et les font correspondre avec des modèles 3D, et certains utilisent les contraintes géométriques des cadres d'objets 2D et 3D. De plus, il existe un autre type de méthode qui part d'objets 3D candidats denses et note toutes les boîtes candidates en fonction des caractéristiques de l'image 2D. La boîte candidate avec un score élevé constitue le résultat final. Cette stratégie est quelque peu similaire à la méthode traditionnelle de fenêtre coulissante en matière de détection d'objets.
Mono3D[15] est un représentant de ce type de méthode. Tout d’abord, une boîte candidate 3D dense est générée en fonction de la position antérieure de la cible (la coordonnée z est au sol) et de sa taille. Sur l'ensemble de données KITTI, environ 40 000 (véhicules) ou 70 000 (piétons et vélos) boîtes candidates sont générées par image. Une fois que ces boîtes candidates 3D sont projetées sur les coordonnées de l'image, elles sont notées en fonction des caractéristiques de l'image 2D. Ces fonctionnalités proviennent de la segmentation sémantique, de la segmentation des instances, des informations préalables sur le contexte, la forme et l'emplacement. Toutes ces caractéristiques sont combinées pour noter les cases candidates, puis celle avec le score le plus élevé est sélectionnée comme candidate finale. Ces candidats sont ensuite transmis via CNN pour le prochain tour de notation afin d'obtenir la trame finale de l'objet 3D.
Mono3D
M3D-RPN [16] est une méthode basée sur Anchor. Cette méthode définit des ancres 2D et 3D, qui représentent respectivement des cadres d'objets 2D et 3D. L'ancre 2D est obtenue grâce à un échantillonnage dense sur l'image, tandis que les paramètres de l'ancre 3D sont déterminés sur la base de connaissances a priori obtenues à partir des données de l'ensemble d'entraînement. Plus précisément, chaque ancre 2D est mise en correspondance avec le cadre d'objet 2D marqué dans l'image en fonction de l'IoU, et la valeur moyenne du cadre d'objet 3D correspondant est utilisée pour définir les paramètres de l'ancre 3D. Il convient de mentionner que les opérations de convolution standard (avec invariance spatiale) et la convolution Depth-Aware sont utilisées dans M3D-RPN. Ce dernier divise les lignes (coordonnées Y) de l'image en plusieurs groupes. Chaque groupe correspond à une profondeur de scène différente et est traité par différents noyaux de convolution. 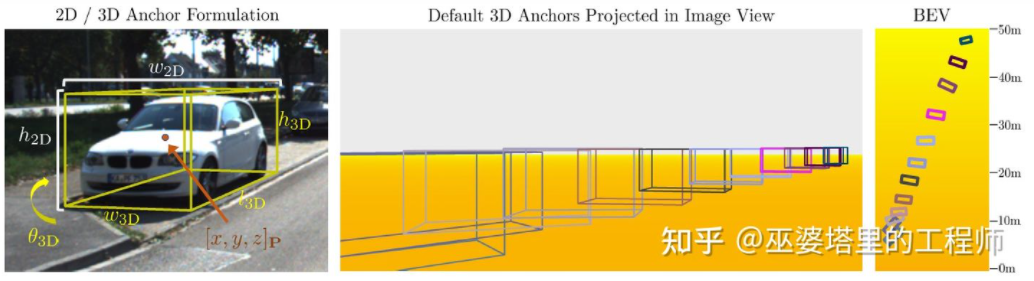
Conception d'ancres et convolution Depth-Aware dans M3D-RPN
Bien que certaines connaissances préalables soient utilisées, Mono3D et M3D-RPN est toujours basé sur un échantillonnage dense lors de la génération d'objets candidats ou d'ancres, la quantité de calcul requise est donc très importante et l'aspect pratique en est grandement affecté. Certaines méthodes ultérieures ont proposé d'utiliser les résultats de détection sur des images bidimensionnelles pour réduire davantage l'espace de recherche.
TLNet [17] place les ancres de manière dense sur le plan bidimensionnel. Les intervalles d'ancrage sont de 0,25 mètres, les orientations sont de 0 degrés et 90 degrés et la taille est la moyenne des cibles. Les résultats de détection bidimensionnelle sur l'image forment de multiples cônes de visualisation dans l'espace tridimensionnel, grâce à ces cônes de visualisation, un grand nombre d'ancres sur l'arrière-plan peuvent être filtrées, améliorant ainsi l'efficacité de l'algorithme. L'ancre filtrée est projetée sur l'image et les caractéristiques obtenues après le ROI Pooling sont utilisées pour affiner davantage les paramètres du cadre de l'objet 3D.
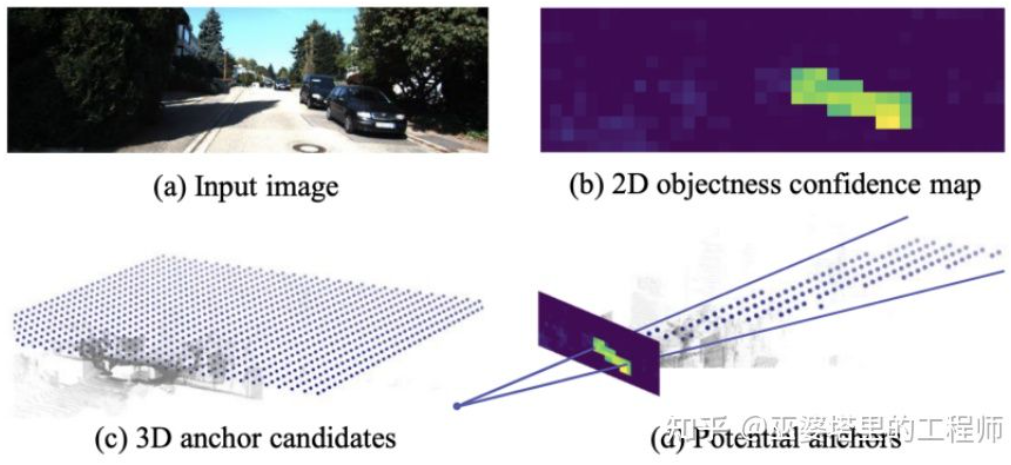
TLTNet # 🎜🎜#
SS3D [18] utilise une détection en une seule étape plus efficace, utilisant un réseau similaire à la structure CenterNet pour sortir directement une variété d'informations 2D et 3D de l'image, telles que les catégories d'objets et cadres d'objets 2D, cadres d'objets 3D. Il convient de noter que le cadre de l'objet 3D n'est pas ici une représentation générale 9D ou 7D (cette représentation est difficile à prédire directement à partir de l'image), mais une représentation 2D plus facile à prédire à partir de l'image et contenant plus de redondance, y compris la distance. . (1-d), orientation (2-d, sin et cos), taille (3-d), coordonnées d'image de 8 points d'angle (16-d). Couplé à la représentation 4D de la boîte d'objets 2D, le total est de 26D. Toutes ces fonctionnalités sont utilisées pour prédire le cadre de l'objet 3D. Le processus de prédiction consiste en fait à trouver le cadre de l'objet 3D qui correspond le mieux aux caractéristiques 26D. Un point particulier est que ce processus de solution est effectué à l'intérieur du réseau neuronal, il doit donc être différentiable. C'est également un point fort de cet article. Bénéficiant d'une structure et d'une mise en œuvre simples, SS3D peut fonctionner à une vitesse de 20FPS.
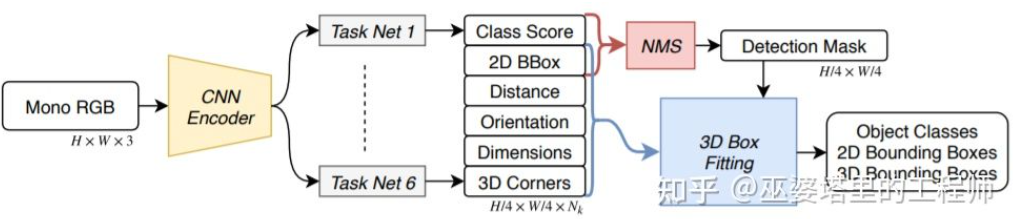
SS3D#🎜🎜 # # 🎜🎜#FCOS3D[19] est également une méthode de détection en une seule étape, mais plus concise que SS3D. Le centre du cadre de l'objet 3D est projeté sur l'image 2D pour obtenir le centre 2,5D (X, Y, Profondeur), qui est utilisé comme l'un des objectifs de la régression. De plus, les cibles de régression incluent également la taille et l'orientation 3D. L'orientation ici est représentée par la combinaison angle (0-pi) + cap.
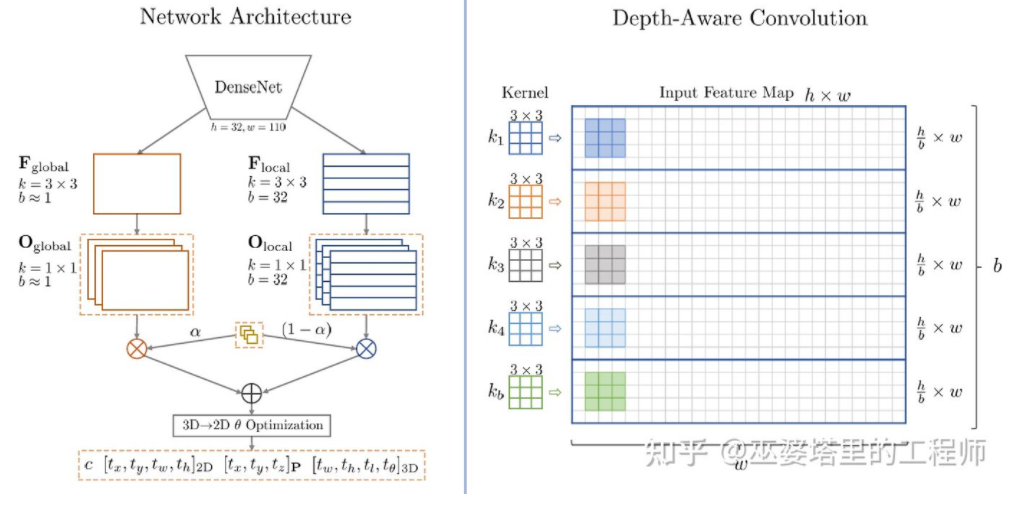
SMOKE [20] a également proposé une idée similaire, prédisant directement les informations 2D et 3D à partir d'images via une structure de type CenterNet. Les informations 2D incluent la position de projection des points clés de l'objet (point central et point d'angle) sur l'image, et les informations 3D incluent la profondeur, la taille et l'orientation du point central. Grâce à la position de l'image et à la profondeur du point central, la position 3D de l'objet peut être récupérée. La position 3D de chaque point d'angle peut ensuite être restaurée grâce à la taille et à l'orientation 3D. L'idée des réseaux à une étape présentés ci-dessus est de renvoyer directement des informations 3D à partir d'images, sans avoir besoin de pré-traitements complexes (comme la transformation inverse d'image) et de post-traitement (comme la correspondance de modèles 3D), ni de contraintes géométriques précises (par exemple, au moins un point d'angle du cadre de l'objet 3D peut être trouvé de chaque côté du cadre de l'objet 2D). Ces méthodes n'utilisent qu'une petite quantité de connaissances préalables, telles que la moyenne des tailles réelles de différents types d'objets et la correspondance qui en résulte entre la taille et la profondeur des objets 2D. Ces connaissances préalables définissent les valeurs initiales des paramètres 3D de l'objet, et le réseau de neurones n'a qu'à régresser l'écart par rapport à la valeur réelle, ce qui réduit considérablement l'espace de recherche et réduit donc la difficulté d'apprentissage du réseau. La section précédente a présenté les méthodes représentatives de détection d'objets 3D monoculaires. Les idées vont de la transformation précoce d'images, de la correspondance de modèles 3D et des contraintes géométriques 2D/3D aux informations 3D de prédiction directe récentes. Ce changement de pensée découle en grande partie des progrès des réseaux de neurones convolutifs dans l'estimation de la profondeur. La plupart des réseaux de détection d'objets 3D à une étape introduits auparavant incluent une branche d'estimation de la profondeur. L'estimation de la profondeur ici se fait uniquement au niveau de la cible clairsemée plutôt qu'au niveau des pixels denses, mais elle est suffisante pour la détection d'objets. En plus de la détection d'objets, la perception de la conduite autonome a également une autre tâche importante, qui est la segmentation sémantique. Le moyen le plus direct d’étendre la segmentation sémantique de la 2D à la 3D consiste à utiliser des cartes de profondeur denses, afin que les informations sémantiques et de profondeur de chaque pixel soient disponibles. Sur la base des deux points ci-dessus, l'estimation de la profondeur monoculaire joue un rôle très important dans les tâches de perception 3D. Par analogie avec l'introduction des méthodes de détection d'objets 3D dans la section précédente, les réseaux de neurones entièrement convolutifs peuvent également être utilisés pour l'estimation de la profondeur dense. Nous présenterons ci-dessous l’état actuel du développement de cette direction. L'entrée de l'estimation de la profondeur monoculaire est une image, et la sortie est également une image (généralement de la même taille que l'entrée), et chaque valeur de pixel correspond à la profondeur de la scène de l'image d'entrée. Cette tâche est quelque peu similaire à la segmentation sémantique d'image, sauf que la segmentation sémantique génère la classification sémantique de chaque pixel. Bien entendu, l’entrée peut également être une séquence vidéo, utilisant des informations supplémentaires apportées par le mouvement de la caméra ou de l’objet pour améliorer la précision de l’estimation de la profondeur (correspondant à la segmentation sémantique vidéo). Comme mentionné précédemment, prédire des informations 3D à partir d'images 2D est un problème mal posé, c'est pourquoi les méthodes traditionnelles utiliseront des informations géométriques, des informations de mouvement et d'autres indices pour prédire la profondeur des pixels grâce à des fonctionnalités conçues à la main. Semblable à la segmentation sémantique, deux méthodes, le superpixel (SuperPixel) et le champ aléatoire conditionnel (CRF), sont souvent utilisées pour améliorer la précision de l'estimation. Ces dernières années, les réseaux de neurones profonds ont fait des progrès décisifs dans diverses tâches de perception d’images, et l’estimation de la profondeur ne fait certainement pas exception. De nombreux travaux ont montré que les réseaux neuronaux profonds peuvent acquérir des fonctionnalités supérieures grâce aux données d'entraînement par rapport aux fonctionnalités conçues à la main. Cette section présente principalement cette méthode basée sur l'apprentissage supervisé. D'autres idées d'apprentissage non supervisé, telles que l'utilisation d'informations sur la disparité binoculaire, d'informations sur la différence monoculaire à double pixel (Dual Pixel), d'informations sur le mouvement vidéo, etc., seront présentées ultérieurement. Un des premiers travaux représentatifs dans cette direction est la méthode basée sur la fusion d'indices globaux et locaux proposée par Eigen et al.[21]. L’ambiguïté de l’estimation monoculaire de la profondeur vient principalement de l’échelle globale. Par exemple, l'article mentionne qu'une pièce réelle et une salle de jouets peuvent sembler très différentes sur l'image, mais que la profondeur de champ réelle est très différente. Bien qu’il s’agisse d’un exemple extrême, des variations dans les dimensions des pièces et des meubles existent toujours dans les ensembles de données réels. Par conséquent, cette méthode propose d'effectuer une convolution multicouche et un sous-échantillonnage sur l'image pour obtenir les caractéristiques de description de la scène entière, et de les utiliser pour prédire la profondeur globale. Ensuite, une autre branche locale (résolution relativement plus élevée) est utilisée pour prédire la profondeur de l’image locale. Ici, la profondeur globale sera utilisée comme entrée dans la branche locale pour aider à la prédiction de la profondeur locale. Estimation de la profondeur
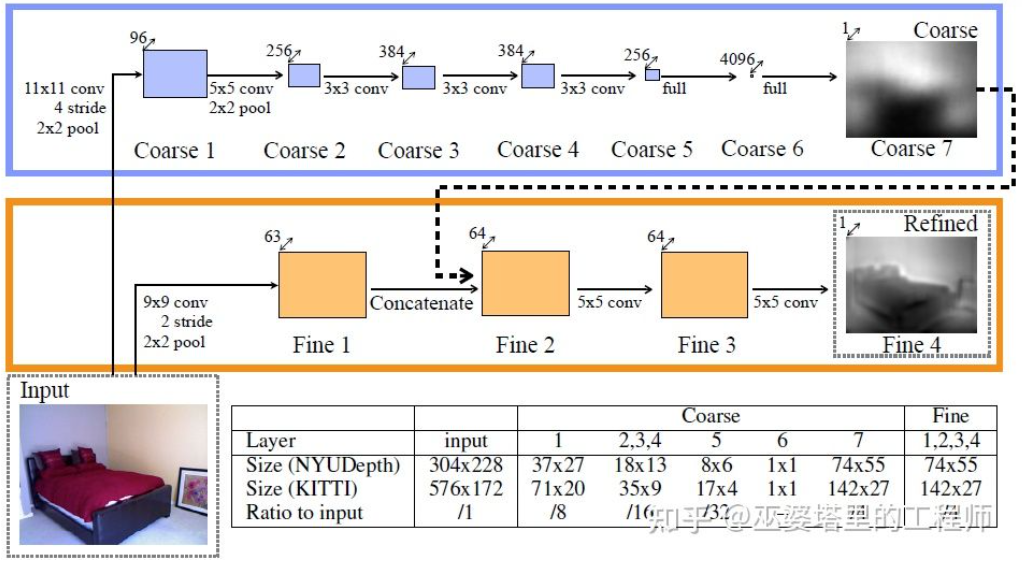
Fusion d'informations mondiales et locales [21]
La littérature [22] a en outre proposé d'utiliser des cartes de caractéristiques multi-échelles produites par des réseaux de neurones convolutifs pour prédire des cartes de profondeur de différentes résolutions (là il n'y a que deux résolutions dans [21]). Ces cartes de caractéristiques de différentes résolutions sont fusionnées via MRF continu pour obtenir une carte de profondeur correspondant à l'image d'entrée.
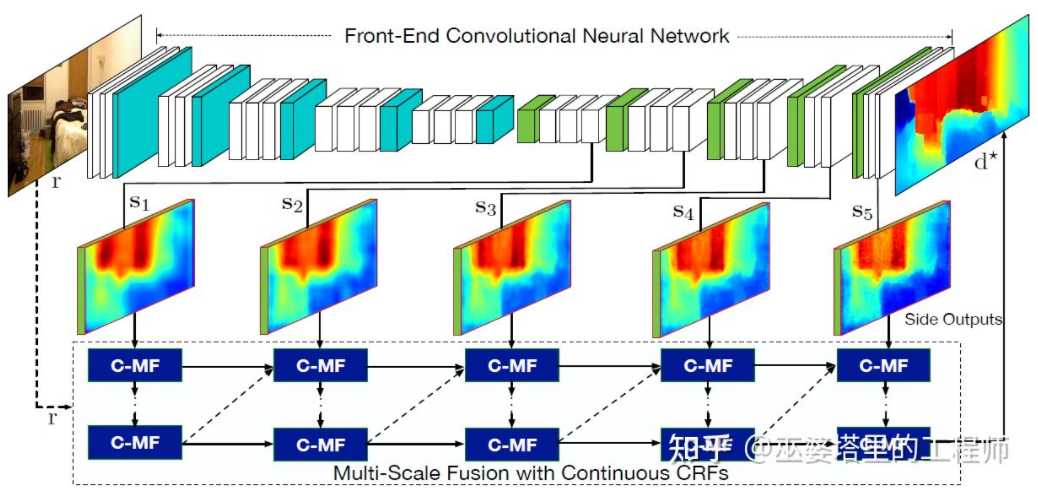
Fusion d'informations multi-échelles [22] #🎜 🎜 #
Les deux articles ci-dessus utilisent des réseaux de neurones convolutifs pour renvoyer la carte de profondeur. Une autre idée est de convertir le problème de régression en un problème de classification, c'est-à-dire de diviser les valeurs de profondeur continues. en intervalles discrets. Chaque intervalle est traité comme une catégorie. Le travail représentatif dans cette direction est DORN [23]. Le réseau neuronal du cadre DORN est également une structure de codage et de décodage, mais il existe quelques différences dans les détails, telles que l'utilisation d'un décodage de couche entièrement connecté, une convolution dilatée pour l'extraction de caractéristiques, etc. # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # Dorn Classification profonde # 🎜🎜 ## 🎜🎜 #
Comme mentionné précédemment, l'estimation de la profondeur présente des similitudes avec les tâches de segmentation sémantique, de sorte que la taille du champ récepteur est également très importante pour l'estimation de la profondeur. En plus des nœuds pyramidaux et des circonvolutions dilatées mentionnés ci-dessus, la structure Transformer, récemment populaire, possède un champ de réception global et est donc très adaptée à de telles tâches. Dans la littérature [24], il est proposé d'utiliser un transformateur et une structure multi-échelle pour assurer simultanément la précision locale et la cohérence globale de la prédiction. #🎜🎜 ##### 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#Transformateur pour prédictif dense#🎜🎜 ## 🎜 Bien que les connaissances préalables et le la précision de la perception 3D monoculaire basée sur les informations contextuelles contenues dans les images n'est pas entièrement satisfaisante. En particulier lors de l’utilisation de stratégies d’apprentissage profond, la précision de l’algorithme dépend fortement de la taille et de la qualité de l’ensemble de données. Pour les scènes qui ne sont pas apparues dans l'ensemble de données, l'algorithme présentera de grands écarts dans l'estimation de la profondeur et la détection des objets.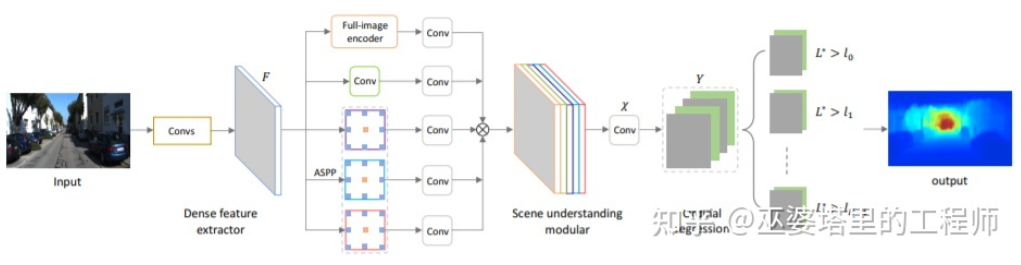
De manière générale, par rapport à la perception visuelle monoculaire, il existe relativement peu de travaux sur la perception visuelle binoculaire. Plusieurs articles typiques seront sélectionnés pour introduction ci-dessous. En outre, il existe certains travaux basés sur la polyvalence, mais orientés vers le niveau d'application du système, comme le système de perception à 360° présenté par Tesla lors de l'AI Day. 3DOP [25] utilise d'abord des images de deux caméras pour générer des cartes de profondeur. La carte de profondeur est convertie en un nuage de points puis quantifiée en une structure de données maillée, qui est utilisée comme entrée pour générer des objets candidats 3D. Une certaine intuition et connaissances préalables sont utilisées lors de la génération des candidats. Par exemple, la densité du nuage de points dans la boîte candidate est suffisamment grande, la hauteur est cohérente avec l'objet réel et la différence de hauteur par rapport au nuage de points à l'extérieur de la boîte est suffisamment grande. , et le chevauchement entre la zone candidate et l'espace libre est suffisant. Grâce à ces conditions, environ 2K objets 3D candidats sont finalement échantillonnés dans l'espace 3D. Ces candidats sont mappés sur des images 2D et l'extraction des caractéristiques est effectuée via ROI Pooling pour prédire la catégorie d'objet et affiner le cadre de l'objet. L'image entrée ici peut être une image RVB provenant d'une caméra ou une carte de profondeur.
En général, il s'agit d'une méthode de détection en deux étapes. La première étape utilise les informations de profondeur (nuage de points) pour générer des objets candidats, et la deuxième étape utilise les informations d'image (ou profondeur) pour un affinement supplémentaire. Théoriquement, la première étape de génération du nuage de points peut également être remplacée par LiDAR, c'est pourquoi l'auteur a effectué des comparaisons expérimentales. L’avantage du LiDAR est que la mesure de distance est précise, elle fonctionne donc mieux pour les petits objets, les objets partiellement obscurcis et les objets distants. L’avantage de la vision binoculaire est que la densité du nuage de points est élevée, elle fonctionne donc mieux lorsqu’il y a moins d’obstruction à courte distance et que l’objet est relativement grand. Bien entendu, sans tenir compte du coût et de la complexité informatique, les meilleurs résultats seront obtenus en intégrant les deux.
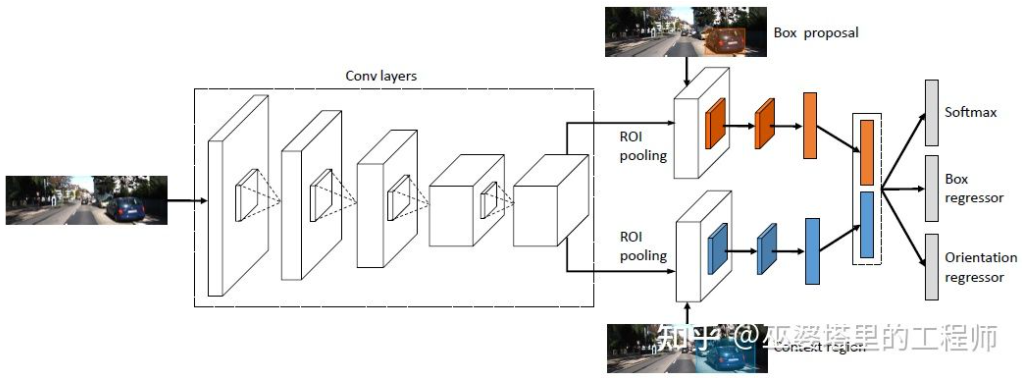
3DOP
3DOP a une idée similaire au pseudo-LiDAR[3] introduit dans la section précédente, qui combine des cartes de profondeur denses (de LiDAR monoculaire, binoculaire et même à ligne basse) est converti en nuage de points, puis des algorithmes dans le domaine de la détection d'objets de nuages de points sont appliqués.
Estimez la carte de profondeur à partir de l'image, puis générez le nuage de points à partir de la carte de profondeur, et enfin appliquez l'algorithme de détection d'objet du nuage de points. Chaque étape de ce processus est effectuée séparément et la formation de bout en bout ne l'est pas. possible. DSGN [26] a proposé un algorithme en une seule étape, partant des images gauche et droite, utilisant une représentation intermédiaire telle que Plane-Sweep Volume pour générer une représentation 3D dans la vue BEV, et effectuer simultanément une estimation de la profondeur et une détection d'objets. Toutes les étapes de ce processus sont différenciables et peuvent donc être entraînées de bout en bout.
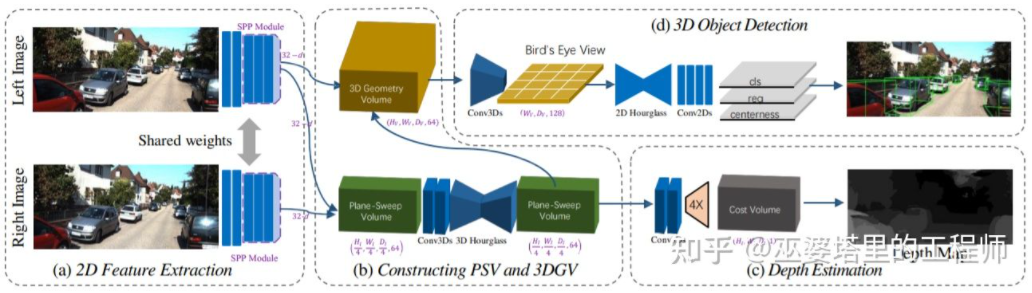
DSGN
La carte de profondeur est une représentation dense. En fait, pour l'apprentissage d'objets, il n'est pas nécessaire d'obtenir des informations de profondeur à toutes les positions de la scène, mais uniquement à la scène. points d'intérêt. Il suffit d'estimer la position de l'objet. Des idées similaires ont déjà été mentionnées lors de l’introduction de l’algorithme monoculaire. Stereo R-CNN [27] n'estime pas la carte de profondeur, mais empile les cartes de caractéristiques de deux caméras dans le cadre du RPN pour générer des objets candidats. La clé ici pour associer les informations des caméras gauche et droite est la modification des données d'annotation. Comme le montre la figure ci-dessous, en plus des cases d'étiquette gauche et droite, une Union des cases d'étiquette gauche et droite est également ajoutée. L'ancre dont l'IoU dépasse 0,7 avec la case gauche ou droite est utilisée comme échantillon positif, et l'ancre dont l'IoU est inférieure à 0,3 avec la case Union est utilisée comme échantillon négatif. L'ancre de Positive renverra la position et la taille des cases d'étiquette gauche et droite en même temps. En plus du cadre d'objet, cette méthode utilise également les points d'angle comme aide. Avec toutes ces informations, le cadre de l'objet 3D peut être restauré.
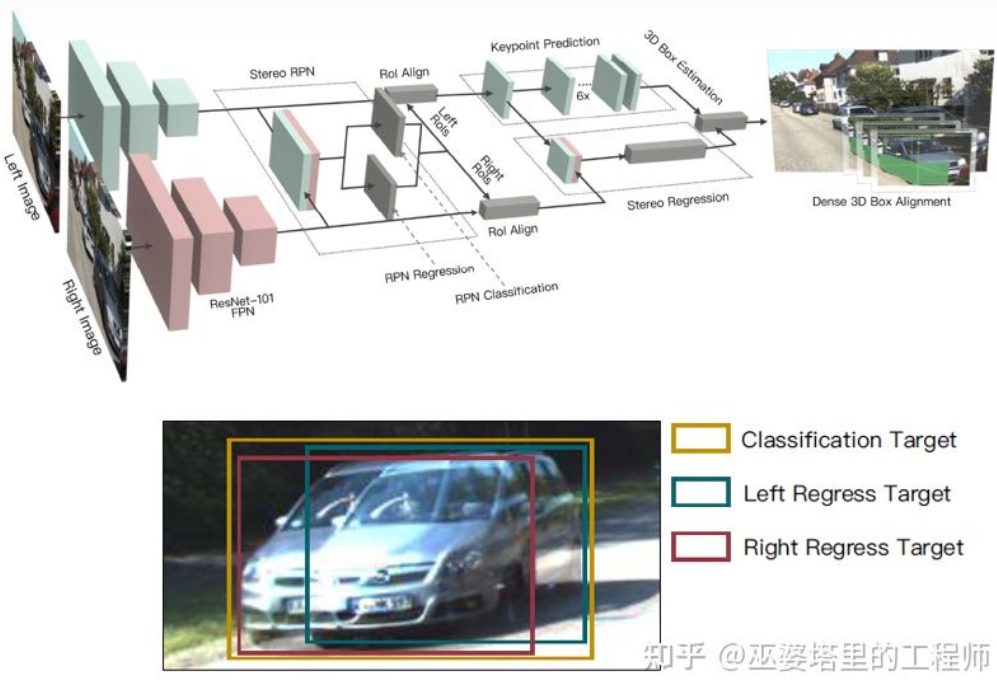
Stereo R-CNN
effectue une estimation de profondeur dense sur l'ensemble de la scène, ce qui peut même avoir un impact négatif sur la détection d'objets. Par exemple, en raison du chevauchement du bord de l'objet avec l'arrière-plan, l'écart d'estimation de la profondeur est important et la grande plage de profondeur de la scène entière affectera également la vitesse de l'algorithme. Par conséquent, similaire au Stereo RCNN, il est également proposé dans [28] d’estimer la profondeur uniquement au niveau de l’objet d’intérêt et de générer uniquement des nuages de points sur l’objet. Ces nuages de points centrés sur l’objet sont finalement utilisés pour prédire les informations 3D de l’objet. Semblable à l'algorithme de perception monoculaire, l'estimation de la profondeur est également une étape clé dans la perception binoculaire. À en juger par l’introduction à la détection d’objets binoculaires dans la section précédente, de nombreux algorithmes utilisent l’estimation de la profondeur, notamment l’estimation de la profondeur au niveau de la scène et l’estimation de la profondeur au niveau de l’objet. Ce qui suit est un bref aperçu des principes de base de l’estimation binoculaire de la profondeur et de plusieurs ouvrages représentatifs.
Le principe de l'estimation de la profondeur binoculaire est en réalité très simple, c'est-à-dire basé sur la distance d entre un même point 3D sur les images gauche et droite (en supposant que les deux caméras maintiennent la même hauteur, donc seule la distance en la direction horizontale est prise en compte), la caméra La distance focale f, et la distance B (longueur de base) entre les deux caméras, pour estimer la profondeur du point 3D. 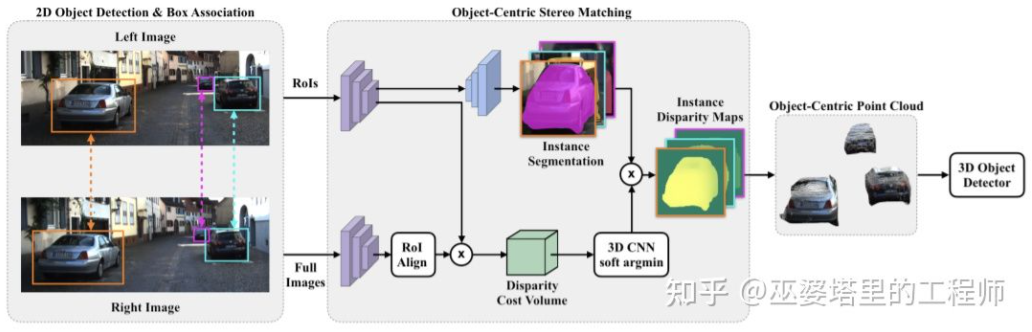
Dans le système binoculaire, f et B sont fixes, donc seule la distance d, qui est la parallaxe, doit être estimée. Pour chaque pixel, il vous suffit de trouver le point correspondant dans l’autre image. La plage de distance d est limitée, donc la plage de recherche correspondante est également limitée. Pour chaque d possible, l'erreur de correspondance au niveau de chaque pixel peut être calculée, de sorte qu'une donnée d'erreur tridimensionnelle est obtenue, appelée coût volume. Lors du calcul de l'erreur de correspondance, la zone locale proche du pixel est généralement prise en compte. L'une des méthodes les plus simples consiste à additionner les différences de toutes les valeurs de pixels correspondantes dans la zone locale : 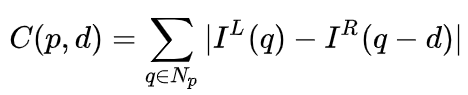

MC-CNN [29] formalise le processus de mise en correspondance en calculant la similarité de deux patchs d'image et apprend les caractéristiques des patchs d'image via un réseau neuronal. En étiquetant les données, un ensemble de formation peut être construit. Au niveau de chaque pixel, un échantillon positif et un échantillon négatif sont générés, chaque échantillon étant une paire de plages d'image. Les échantillons positifs sont deux blocs d'images provenant du même point 3D (même profondeur), et les échantillons négatifs sont des blocs d'images provenant de points 3D différents (profondeurs différentes). Il existe de nombreux choix d'échantillons négatifs. Afin de maintenir un équilibre entre les échantillons positifs et négatifs, un seul est échantillonné au hasard. Avec des échantillons positifs et négatifs, un réseau neuronal peut être entraîné pour prédire la similarité. L'idée principale ici est d'utiliser des signaux de supervision pour guider le réseau neuronal afin d'apprendre les caractéristiques de l'image adaptées aux tâches correspondantes.
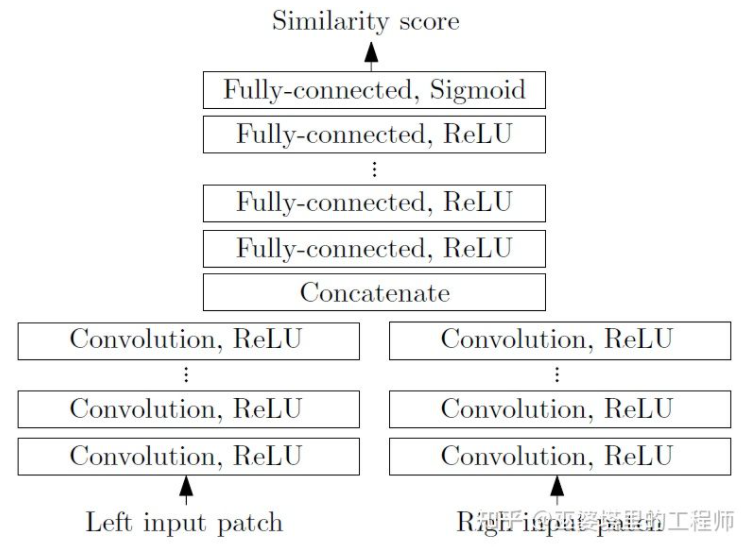
MC-CNN
MC-Net présente principalement deux défauts : 1) Le calcul du coût volume repose sur des blocs d'images locaux, qui peuvent apparaître dans certaines textures avec moins de texture ou répétées. modèles La zone entraînera de grosses erreurs ; 2) Les étapes de post-traitement reposent sur une conception manuelle, qui prend beaucoup de temps et est difficile à garantir l'optimalité. GC-Net[30] a amélioré ces deux points. Premièrement, des opérations de convolution et de sous-échantillonnage multicouches sont effectuées sur les images gauche et droite pour mieux extraire les caractéristiques sémantiques. Pour chaque niveau de disparité (en pixels), les cartes de caractéristiques gauche et droite sont alignées (décalage de pixels) puis assemblées pour obtenir la carte de caractéristiques de ce niveau de disparité. Les cartes de caractéristiques de tous les niveaux de disparité sont fusionnées pour obtenir le volume de coût 4D (hauteur, largeur, disparité, caractéristiques). Le volume de coût ne contient que les informations d’une seule image et il n’y a aucune interaction entre les images. Par conséquent, l'étape suivante consiste à utiliser la convolution 3D pour traiter le volume de coût, afin que les informations pertinentes entre les images gauche et droite et les informations entre les différents niveaux de disparité puissent être extraites simultanément. Le résultat de cette étape est le volume de coût 3D (hauteur, largeur, parallaxe). Enfin, nous devons trouver Argmin dans la dimension de disparité pour obtenir la valeur de disparité optimale, mais l'Argmin standard ne peut pas être dérivée. Soft Argmin est utilisé dans GC-Net pour résoudre le problème de dérivation, afin que l'ensemble du réseau puisse être formé de bout en bout.
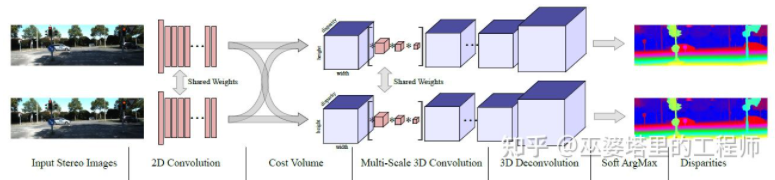
GC-Net
PSMNet [31] est très similaire à GC-Net dans sa structure, mais a été amélioré sous deux aspects : 1) Utilisation de la structure pyramidale et de la convolution atreuse pour extraire informations multi-résolution et élargir le champ de réception. Grâce à la fusion des caractéristiques globales et locales, l’estimation du Coût Volume est également plus précise. 2) Utilisez plusieurs structures Hour-Glass superposées pour améliorer la convolution 3D. L’utilisation de l’information mondiale est encore améliorée. En général, PSMNet a amélioré l'utilisation des informations globales, rendant l'estimation des disparités plus dépendante des informations contextuelles à différentes échelles plutôt que des informations locales au niveau des pixels.
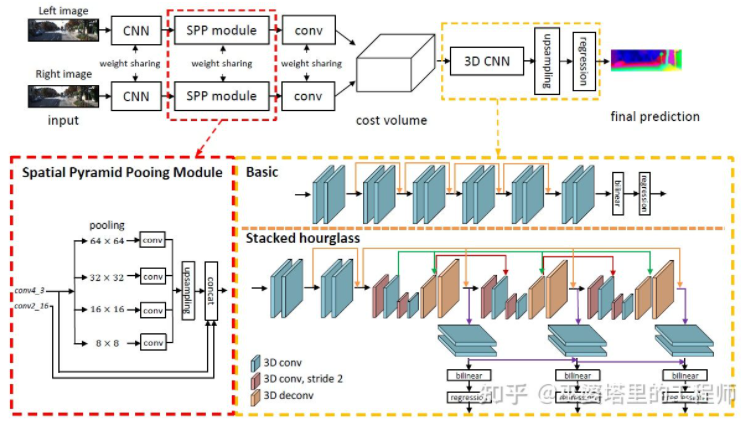
PSMNet
Dans Coût Volume, le niveau de disparité est discret (en pixels). Ce que le réseau neuronal apprend, c'est la distribution des coûts en ces points discrets, et les points extrêmes de la distribution correspondent à la valeur de disparité actuelle. du poste. Cependant, la valeur de parallaxe (profondeur) doit en réalité être continue, et l'utilisation de points discrets pour l'estimer entraînera des erreurs. Le concept d'estimation continue est proposé dans CDN [32]. En plus de la distribution des points discrets, le décalage en chaque point est également estimé. Les points discrets et les décalages forment ensemble une estimation de disparité continue.
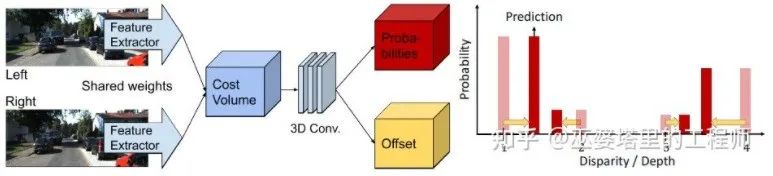
CDN# 🎜🎜#
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Lien du projet écrit devant : https://nianticlabs.github.io/mickey/ Étant donné deux images, la pose de la caméra entre elles peut être estimée en établissant la correspondance entre les images. En règle générale, ces correspondances sont 2D à 2D et nos poses estimées sont à échelle indéterminée. Certaines applications, telles que la réalité augmentée instantanée, à tout moment et en tout lieu, nécessitent une estimation de pose des métriques d'échelle, elles s'appuient donc sur des estimateurs de profondeur externes pour récupérer l'échelle. Cet article propose MicKey, un processus de correspondance de points clés capable de prédire les correspondances métriques dans l'espace d'une caméra 3D. En apprenant la correspondance des coordonnées 3D entre les images, nous sommes en mesure de déduire des métriques relatives.
 Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
La couche inférieure de la fonction de tri C++ utilise le tri par fusion, sa complexité est O(nlogn) et propose différents choix d'algorithmes de tri, notamment le tri rapide, le tri par tas et le tri stable.
 L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
La convergence de l’intelligence artificielle (IA) et des forces de l’ordre ouvre de nouvelles possibilités en matière de prévention et de détection de la criminalité. Les capacités prédictives de l’intelligence artificielle sont largement utilisées dans des systèmes tels que CrimeGPT (Crime Prediction Technology) pour prédire les activités criminelles. Cet article explore le potentiel de l’intelligence artificielle dans la prédiction de la criminalité, ses applications actuelles, les défis auxquels elle est confrontée et les éventuelles implications éthiques de cette technologie. Intelligence artificielle et prédiction de la criminalité : les bases CrimeGPT utilise des algorithmes d'apprentissage automatique pour analyser de grands ensembles de données, identifiant des modèles qui peuvent prédire où et quand les crimes sont susceptibles de se produire. Ces ensembles de données comprennent des statistiques historiques sur la criminalité, des informations démographiques, des indicateurs économiques, des tendances météorologiques, etc. En identifiant les tendances qui pourraient échapper aux analystes humains, l'intelligence artificielle peut donner du pouvoir aux forces de l'ordre.
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
 Le LLM est terminé ! OmniDrive : Intégration de la perception 3D et de la planification du raisonnement (la dernière version de NVIDIA)
May 09, 2024 pm 04:55 PM
Le LLM est terminé ! OmniDrive : Intégration de la perception 3D et de la planification du raisonnement (la dernière version de NVIDIA)
May 09, 2024 pm 04:55 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : cet article est dédié à la résolution des principaux défis des grands modèles de langage multimodaux (MLLM) actuels dans les applications de conduite autonome, c'est-à-dire le problème de l'extension des MLLM de la compréhension 2D à l'espace 3D. Cette expansion est particulièrement importante car les véhicules autonomes (VA) doivent prendre des décisions précises concernant les environnements 3D. La compréhension spatiale 3D est essentielle pour les véhicules utilitaires car elle a un impact direct sur la capacité du véhicule à prendre des décisions éclairées, à prédire les états futurs et à interagir en toute sécurité avec l’environnement. Les modèles de langage multimodaux actuels (tels que LLaVA-1.5) ne peuvent souvent gérer que des entrées d'images de résolution inférieure (par exemple) en raison des limitations de résolution de l'encodeur visuel et des limitations de la longueur de la séquence LLM. Cependant, les applications de conduite autonome nécessitent
